
Project 환경 구성
개발 툴: intelij
빌드 : maven
java 1.8+
hadoop 3.3.0
pom.xml 설정
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sk.hadoop</groupId>
<artifactId>hadoop_edu</artifactId>
<version>1.0-SNAPSHOT</version>
<name>wordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- dependancy 추가 -->
</dependencies>
</project>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.0</version>
</dependency>WordCountMapper구현
package com.sk.hadoop;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value,
Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line," ");
while(st.hasMoreTokens()){
word.set(st.nextToken());
context.write(word,one);
}
}
}WordCountReducer 구현
package com.sk.hadoop;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException
{
int sum = 0;
Iterator<IntWritable> valuesIt = values.iterator();
while(valuesIt.hasNext()){
sum = sum + valuesIt.next().get();
}
context.write(key, new IntWritable(sum));
}
}WordCount 구현
package com.sk.hadoop;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new WordCount(), args);
System.exit(exitCode);
}
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input><output>\n",getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new org.apache.hadoop.mapreduce.Job();
job.setJarByClass(WordCount.class);
job.setJobName("WordCounter");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
int returnValue = job.waitForCompletion(true) ? 0:1;
System.out.println("job.isSuccessful " + job.isSuccessful());
return returnValue;
}
}
install로 jar파일 생성
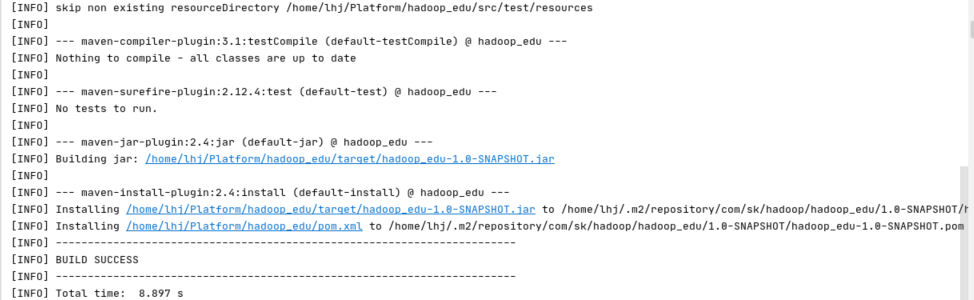
생성확인
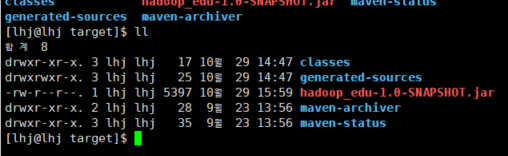
터미널에서 jar파일 생성된거 확인 ㅎㅎ
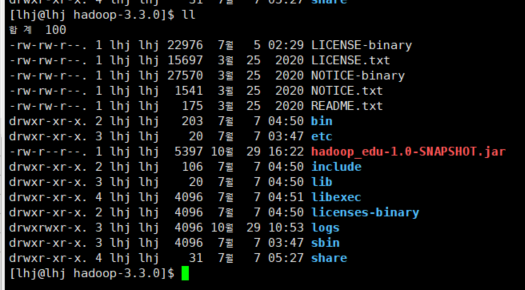
hadoop home으로 복사해서 jar 파일 가져온다.
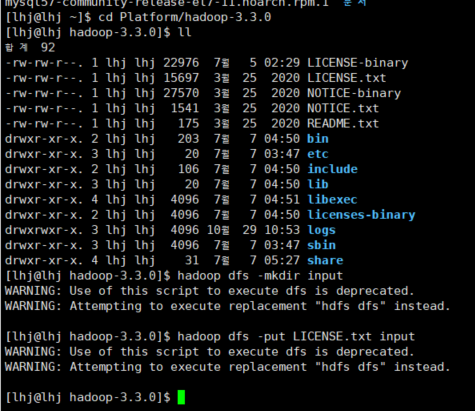
HADOOP HOME 의 LICENSE.txt 파일을 하둡으로 복사
hadoop dfs -mkdir input
hadoop dfs -put LICENSE.txt input
hadoop jar hadoop_edu-1.0-SNAPSHOT.jar com.sk.hadoop.WordCount input/LICENSE.txt output
명령어를 이용해 실행
.
.
.
근데 오류
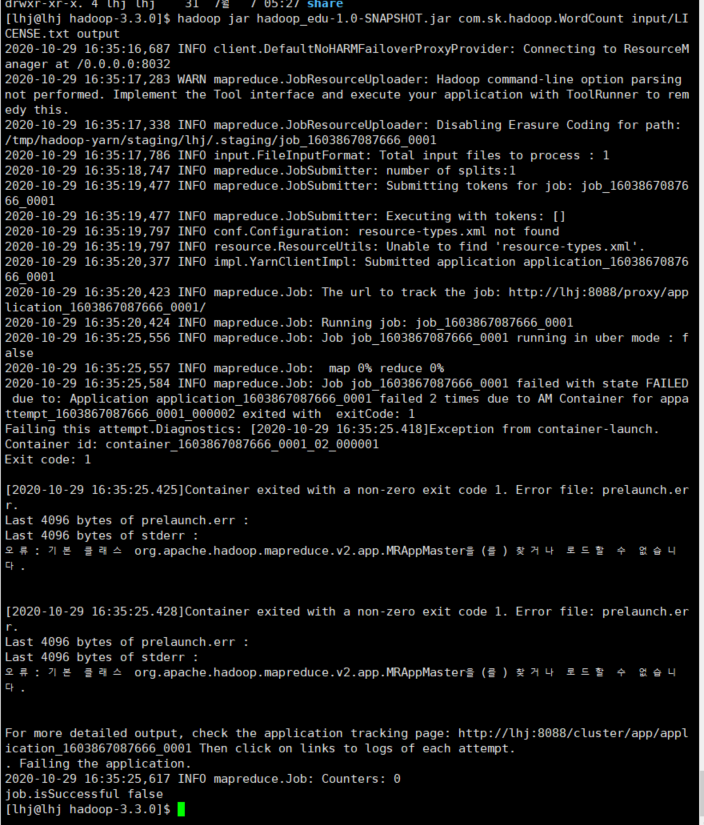
failed ..
왜 실패한건지 아직 못찾음
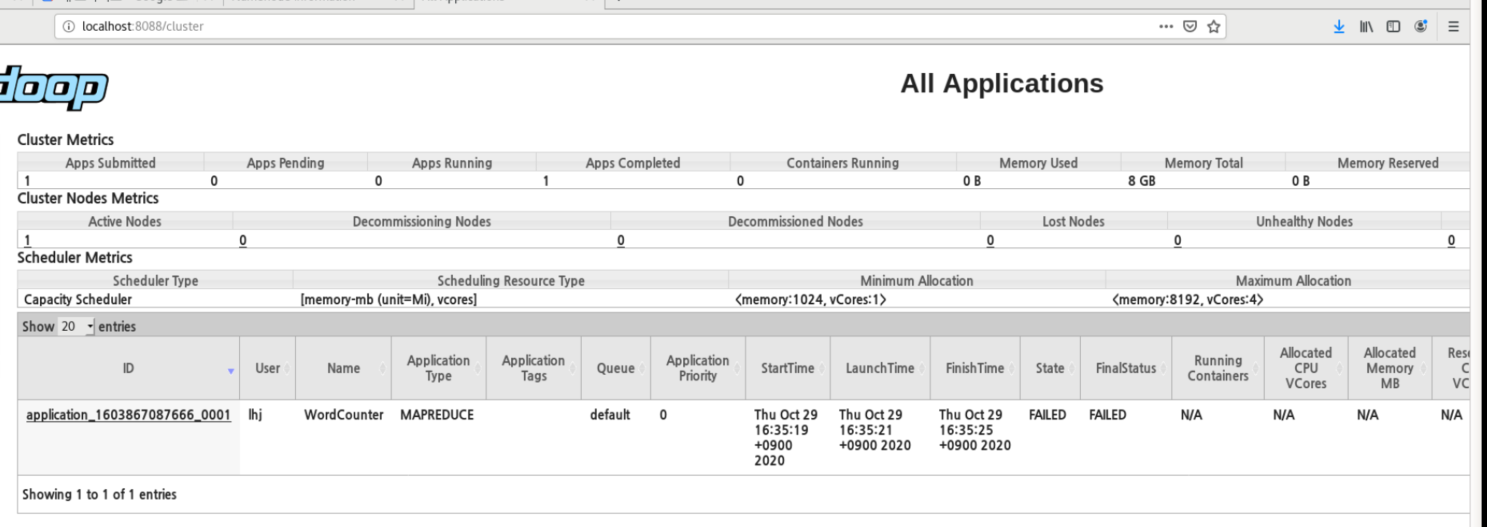
해결방법 -
Yarn-site.xml에 다음 속성을 추가했습니다.
<property>
<name>yarn.application.classpath</name>
<value> $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
</value>
</property>
공유 문화를 지향하는 개발자입니다.