오늘은 AI 허브에서 제공되는 공공데이터를, Nvidia TAO에서 Yolo v4의 훈련데이터로 활용하기 위한 전처리 과정을 기록해볼까 합니다.
몇 달전에 관련 프로젝트로 데이터를 활용한 적이 있어서 코드가 드문드문 기록되어 있었는데, 이 기회에 한번 정리해보겠습니다.
대략적으로 설명드리면 해당 데이터를 다운로드 받아, annotation을 COCO 형식으로 변환한 뒤에 yolo에서 사용 가능한 KITTI 형식으로 재변환 하는 형식으로 진행됩니다.
해당 데이터셋은 용량이 아주 큰 편에 속하지만, 1/3 정도의 데이터셋을 검토하고 이를 총 데이터셋 용량 1/50 정도인 아주 Task Specific한 데이터셋을 만들어보도록 하겠습니다.
데이터 다운로드
- 시작하기에 앞서 충분한 디스크 사이즈를 확보해주세요. 저는 잔여 용량이 80GB정도 밖에 남지 않아서 두 개의 데이터셋에 대해서만 진행합니다.(총 1.03TB, 이번에 전처리할 데이터셋은 250GB 정도)
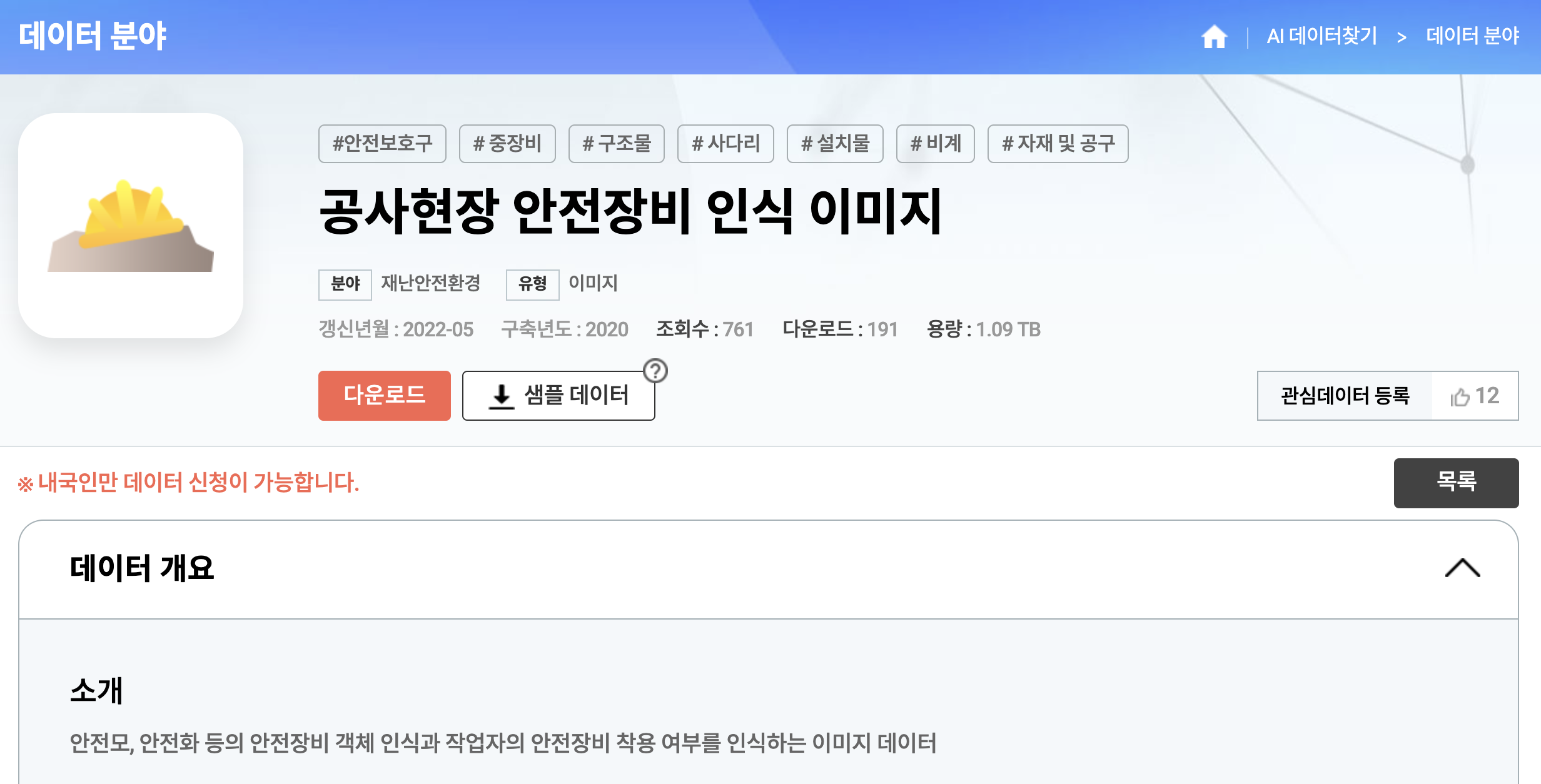
위 이미지에서 다운로드 버튼을 누르면 innorixet라는 툴을 활용해서 데이터를 다운로드 받게 됩니다.
innorixet는 대용량 파일 전송을 위한 툴으로 초당 2~300Mbps의 전송 속도를 보여주네요. (stfp 프로토콜을 이용하네요)
이번 포스팅에서는 [원천]1.공동주택_송도호반.zip, [원천]1.공동주택_하남감일 A-7BL 11공구 아파트 신축공사.zip 데이터와 [라벨]1.공동주택.zip을 활용해보겠습니다.
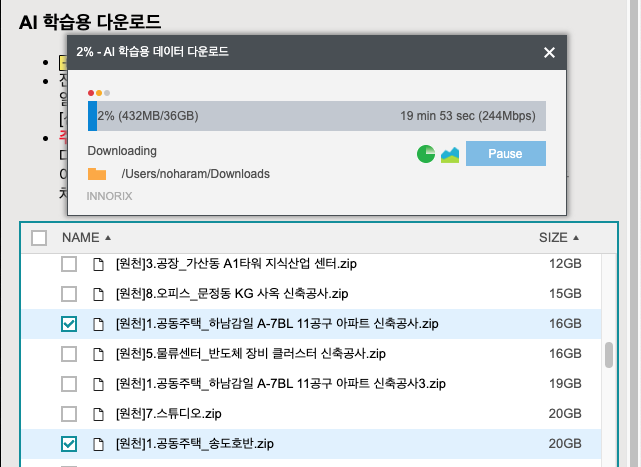

이번 모델은 안전보호구만 탐지하는 모델이기 때문에 레이블에 안전보호구만 들어있는 공동주택 데이터셋 내에 송도호반과 하남강일 데이터셋을 선택하였습니다.
해당 라벨에서 5개의 레이블셋 중에 1.안전보호구만 데이터셋만 사용할 예정입니다.
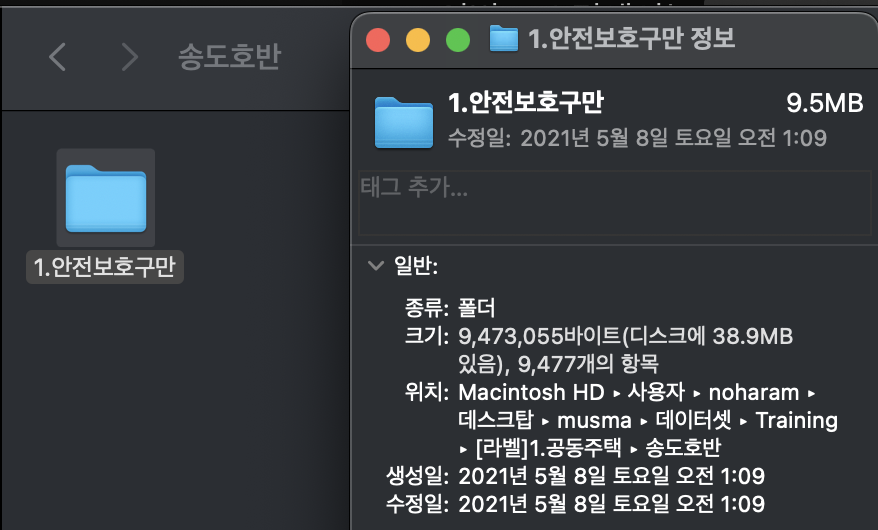
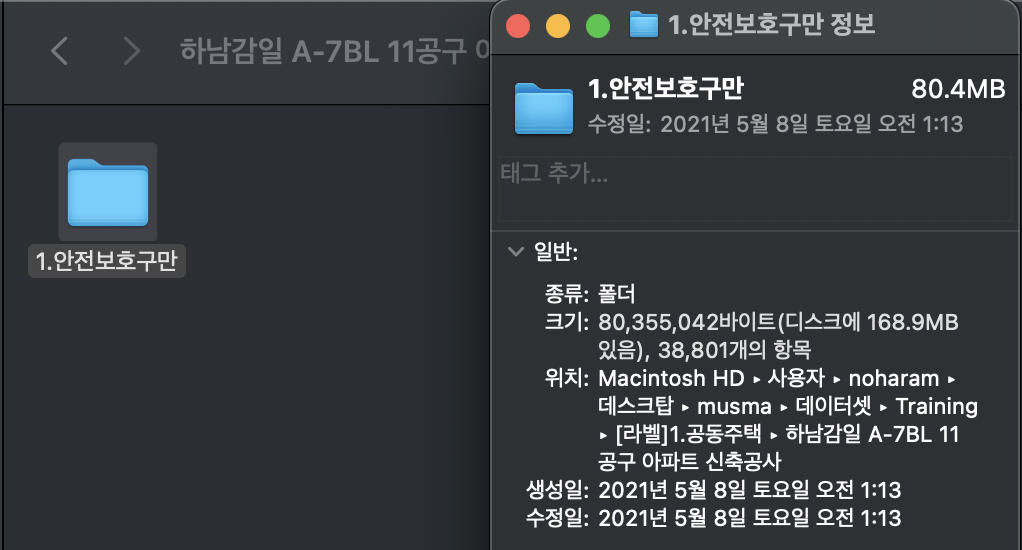
- 두 데이터셋의 안전보호구만 항목을 합치면(9,477 + 38,801) 48,278개의 json 파일이 생깁니다.
- 마찬가지로 img도 송도호반, 하남강일 데이터셋을 다운로드 받아 합쳐준 뒤 img와 json의 파일명을 기준으로 짝을 맞추어 레이블셋에 없는 img 파일은 전부 삭제할 예정입니다.(하남강일 데이터셋은 1~11까지 있어서 총 250GB정도 됩니다. 용량이 없다면 하나만 다운받고 계속 진행해주세요. 이미지/레이블 쌍을 걸러낼 때 추후에 하나씩 다운로드, 제거를 반복해도 됩니다.)- 이후 객체 탐지 모델에서 탐지하기를 원하는 5개의 클래스만을 이용해 리샘플링을 진행합니다. 리샘플링 이후에 해당 클래스의 정보를 가지고 있지 않은 레이블과 이미지를 삭제합니다.(그래서 데이터의 총 개수는 줄어들 예정입니다)
- 48,277개(폴더 합치니까 48,277개로 나오네요)에서 전처리, 리샘플링 이후 데이터셋이 얼마나 줄어드는지 한번 확인해봅시다.
압축 해제 및 디렉터리 구조 정리
전부 다운로드 받아 압축을 해제하고 1.안전보호구 관련 데이터만 남기도록 하겠습니다.
그리고 송도호반 데이터셋과 하남강일 데이터셋을 합쳐줍니다.(img는 img끼리, json은 json끼리)
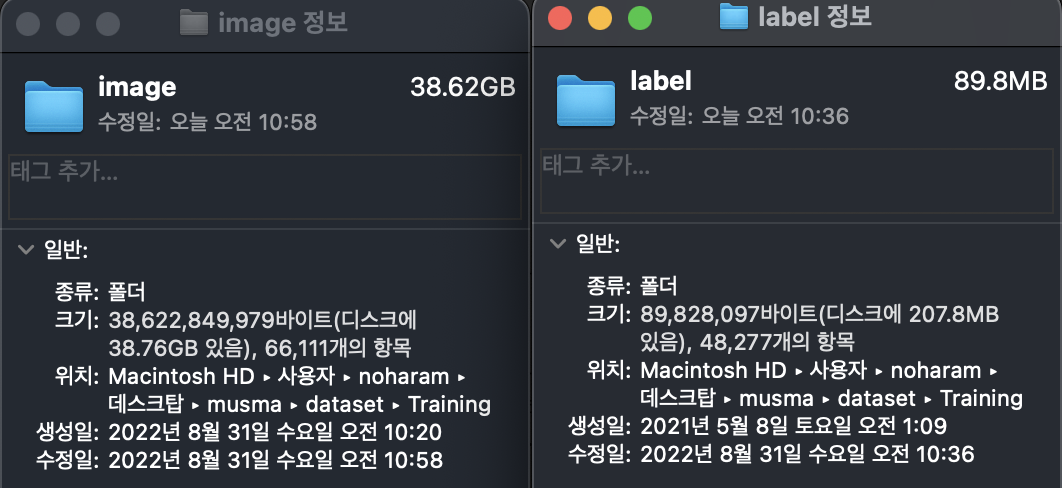
합쳐서 image, label 폴더로 정리하니 image(~~), label(48,277)로 개수가 다릅니다. label에는 image에 포함되지 않은 공동주택_하남감일 A-7BL 11공구 아파트 신축공사 2~11 항목이 추가로 들어가있고, 반대로 기존에 존재했던 레이블 중에서 안전보호구만 빼왔기 때문입니다.
리샘플링하면서 짝(pair)이 누락된 파일을 삭제하도록 하겠습니다.
데이터 리샘플링
리샘플링 작업에선 크게 두 가지 작업을 진행할 예정입니다.
- 해당 데이터셋에는 Class Imbalance(클래스 불균형)이 존재합니다. 클래스 불균형은 학습 시 일부 클래스에 과대적합을 유발하기 때문에 해결합니다.
일부 데이터셋의 Ground Truth Ratio를 살펴보면 아래와 같습니다.

그래서 이번엔 Ground Truth의 개수인 20000개를 기준으로 최대 클래스 개수가 20000개를 넘어가면 저장되지 않도록 할 예정입니다.
- 오히려 최대 클래스 개수를 너무 낮게 설정하면 학습되어야 할 데이터가 학습되지 않아 성능이 악형양을 끼칠까봐
- 또한 저는 이미 동일한 테스크로 학습시킨 모델을 이용해 전이학습을 할 예정이기 때문에 yolo의 class_weight를 활용할 예정입니다.
5class resampling
ipynb 파일로 진행하였습니다.
-
annotation 폴더 내 파일 리스트업
# coding:utf-8 import os import shutil import json import skimage import numpy as np import pandas as pd from collections import OrderedDict # 원본 annotation 파일들이 있는 경로 annoResampleDir = "/Users/noharam/Desktop/musma/dataset/Training/label/" # anno_dir 내 annotation 파일 이름 리스트업 annoResampleList = os.listdir(annoResampleDir) print(len(annoResampleList)) print(annoResampleList[:10])
-
데이터 프레임 정의
원본의 클래스 개수에 맞게 데이터프레임을 정의합니다.# DF 정의하기 anno_dict_resample = {"01":0,"02":0,"03":0,"04":0,"05":0,"06":0,"07":0,"08":0,"09":0,"10":0, "10":0,"11":0,"12":0,"13":0,"14":0,"15":0,"16":0,"17":0,"18":0,"19":0, "20":0,"21":0,"22":0,"23":0,"24":0,"25":0,"26":0,"27":0,"28":0,"29":0, "30":0,"31":0,"32":0,"33":0,"34":0,"35":0,"36":0,"37":0,"38":0,"39":0, "40":0,"41":0,"42":0,"43":0,"44":0,"45":0} -
탐지할 클래스를 제외한 다른 클래스를 annotation에서 제거합니다.
동시에 오브젝트 개수도 어느정도 제한합니다.
- 이전엔 오브젝트 개수를 10000개로 제한시켜 훈련하였는데, 이런 경우 이미지는 정상인데 학습해야할 정상 객체들이 누락되는(안전모는 오브젝트가 엄청 많아서 오히려 훈련해야할 안전모 정보가 누락되는) 경우가 발생할까봐 30000개로 설정해서 진행합니다.
- 정확히 설명드리면, 해당 코드는 해당 클래스 오브젝트 개수가 30000개가 넘지 않는 것까지 이미지의 리스트를 저장합니다.
- 나중에 해당 이미지 리스트들에서 다시 실제 오브젝트들의 개수를 세어보면 당연히 30000개가 넘습니다.(다른 오브젝트들도 30000개까지 이미지 리스트를 저장하기 때문에)- 그래서 최대한 클래스 개수의 불균형이 적어지게 일단 한번 맞춰주는 개념이라고 생각하시면 되겠습니다.
# 안전보호구 5클래스(1,2,5,7,8)만 남기고 나머지 다 삭제하기
# 수정 후 json 파일 변경
# .DS_Store 파일이 간혹 생길때가 있습니다. 폴더 내에 해당 파일이 존재하면 오류가 발생합니다. 반드시 찾아서 삭제 후 진행하세요.
f = open("/Users/noharam/Desktop/musma/dataset/Training/5class_resampling.txt", 'w')
remove_list = ["03","04","06","09","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25",
"26","27","28","29","30","31","32","33","34","35","36","37","38","39","40","41","42","43","44","45"]
for anno in annoResampleList:
try :
with open(annoResampleDir + anno, encoding="utf-8-sig", errors="ignore") as json_file:
jsonData = json.load(json_file)
except : # .DS_Store가 있는지 확인하기 위해 작성, 일반적으로 mac Finder에는 해당 파일이 보이지 않으나 SFTP 시스템 등으로 보면 해당 파일이 있으니 삭제합니다.
print(anno)
imgPath = anno.replace(".json", ".jpg")
df = pd.json_normalize(jsonData)
filename = df["image.filename"][0]
annoList = df["annotations"][0]
# print(filename)
for i in annoList[:]:
if i["class"] in remove_list:
annoList.remove(i)
if annoList :
for j in range(len(annoList)) :
item = annoList[j]["class"]
# class imblance를 조정하기 위해서 현재는 Tao yolo에서 class_weight를 지원하지만, 애초에 전처리 과정에서 개수를 제한해 적당한 비율 맞추기
# 해당 레이블 개수가 10000개를 이하이면
if anno_dict_resample[item] < 30000 :
anno_dict_resample[item] += 1
# 레이블이 10000개를 넘기지 않을 때만 이미지명을 저장한다. 중복이 생기지만 추후에 제거한다.
f.write(filename+'\n')
with open(annoResampleDir + anno, 'w', encoding="utf-8-sig", errors="ignore") as outfile:
json.dump(jsonData, outfile)
f.close()- 결과 확인
결과를 확인해보니 1,2,5,7번 클래스는 오브젝트가 각각 30000개를 달성했지만, 8번 클래스는 5667개밖에 되지 않습니다.
나중에 yolo를 학습시킬 때 class_weight를 8번 클래스에 차등부여하도록 하겠습니다.
print(anno_dict_resample)
# 값(value)를 기준으로 정렬한 OrderedDict
ordered_dict = OrderedDict(sorted(anno_dict_resample.items(), key=lambda t:t[1], reverse=True))
print(ordered_dict)
리샘플링 결과 확인
- 터미널에서 결과를 확인하고, 후처리를 진행합니다.
-
위 과정 진행 후 텍스트 파일(이미지 리스트) 의 줄 수 확인 : 125667
wc -l 5class_resampling.txt

-
중복제거는 리눅스 쉘 명령어를 활용해서 진행합니다. : 29598
cat 5class_resampling.txt| sort -u >> 5class_resampling_unique.txt wc -l 5class_resampling_unique.txt
-
텍스트 파일 내에서 확장자 문자열(.jpg) 삭제
sed 's/.jpg//' 5class_resampling_unique.txt >> 5class_resampling_nojpg.txt -
중복제거 후 나온 리스트를 통해(이미지리스트) 해당 레이블 파일만 뽑아내고복사합니다.
- 전체 레이블 폴더에서 진행해야합니다.mkdir resampling_label cd label cat /Users/noharam/Desktop/musma/dataset/Training/5class_resampling_nojpg.txt | xargs -t -n1 -I{} cp -r {}.json ../resampling_label/ -
레이블 파일 잘 분류되었는지 폴더 내 파일개수 확인 : 29598
find . -type f | wc -l

리샘플링 후 클래스 분포 재확인
('05', 57701), ('01', 56497), ('07', 53839), ('02', 30238), ('08', 5667)
아직 8번 클래스가 05/01/07번 클래스에 비해 1/10정도 밖에 안되네요.
이전엔 위에서 오브젝트 개수를 10,000개로 제한해서 샘플링을 진행했고, 각 클래스별 오브젝트 개수가 비슷한 데이터셋을 얻을 수 있었습니다.
하지만 이번 데이터셋 전처리 목표는 정체되어 있는 훈련에 추가 데이터를 주입하기 위해서라, 너무 큰 불균형을 초래하지 않되 최대한 많은 오브젝트를 담아보려고 했어요.
그래서 08번 클래스와 02번 클래스만 class_weight를 조금 높게 주고 전이학습을 진행해보려고 합니다!
# coding:utf-8
import os
import shutil
import json
import skimage
import numpy as np
import pandas as pd
from collections import OrderedDict
# 중복을 제거하고 남은 이미지에서 다시 한번 클래스의 분포를 확인한다
annoResampleDir = "/Users/noharam/Desktop/musma/dataset/Training/resampling_label/"
# anno_dir 내 annotation 파일 이름 리스트업
annoResampleList = os.listdir(annoResampleDir)
print(len(annoResampleList))
print(annoResampleList[:10])
anno_dict_resample = {"01":0,"02":0,"03":0,"04":0,"05":0,"06":0,"07":0,"08":0,"09":0,"10":0,
"10":0,"11":0,"12":0,"13":0,"14":0,"15":0,"16":0,"17":0,"18":0,"19":0,
"20":0,"21":0,"22":0,"23":0,"24":0,"25":0,"26":0,"27":0,"28":0,"29":0,
"30":0,"31":0,"32":0,"33":0,"34":0,"35":0,"36":0,"37":0,"38":0,"39":0,
"40":0,"41":0,"42":0,"43":0,"44":0,"45":0}
for anno in annoResampleList:
with open(annoResampleDir + anno, encoding="utf-8-sig", errors="ignore") as json_file:
jsonData = json.load(json_file)
imgPath = anno.replace(".json", ".jpg")
df = pd.json_normalize(jsonData)
filename = df["image.filename"][0]
#print(df["image.filename"][0])
for i in range(len(df["annotations"][0])):
item = df["annotations"][0][i]["class"]
anno_dict_resample[item] += 1
# 값(value)를 기준으로 정렬한 OrderedDict
ordered_dict = OrderedDict(sorted(anno_dict_resample.items(), key=lambda t:t[1], reverse=True))
print(ordered_dict)
디렉터리 이동 및 백업

훈련에 사용할 이미지와 레이블을 image 디렉터리와 resampling_label 디렉터리입니다.
계속 처리를 진행해봅시다.
전 이미지와 레이블 디렉터리를 옮겨주었습니다. 앞으로 image_3과 label_3 디렉터리로 사용하고자합니다.
mkdir -p /Users/noharam/Desktop/musma/dataset/safety/data/train
mv /Users/noharam/Desktop/musma/dataset/Training/image /Users/noharam/Desktop/musma/dataset/safety/data/train/image_3
mv /Users/noharam/Desktop/musma/dataset/Training/resampling_label /Users/noharam/Desktop/musma/dataset/safety/data/train/label_3- 추후로 진행할 과정에서 혹시 데이터가 누락될지 모르니 백업본을 만들어두겠습니다.
cp -r /Users/noharam/Desktop/musma/dataset/safety/data/train /Users/noharam/Desktop/musma/dataset/safety/data/train_backup데이터/레이블 Pair Check
리샘플링이 끝난 후 혹시나 데이터와 레이블의 짝이 맞지 않는 경우가 생깁니다.
짝이 있는지 검사 후 없으면 삭제합니다.
위에서 리샘플링한 레이블 데이터와 마찬가지로 이미지 데이터도 같은 짝을 가진(이미지 파일명이 레이블 데이터와 동일한) 이미지만 남기는 것이 목표입니다.
옮겨놓은 데이터셋 폴더 내에 쉘 파일을 만들고 실행해주세요.
bash clean_dataset_image.sh ./image_3 ./label_3
#!/bin/bash
# 일단 레이블과 쌍이 안맞는 이미지만 체크해서 제거 (전체 이미지 데이터셋에 대해 수행해야함)
for img in $1/*.jpg
do
kitti_name=$2/$(basename $img .jpg).json
if [ ! -f $kitti_name ]; then
echo "$kitti_name not exist, will remove that image pair."
rm $img
fi
done
echo "$1: $(ls $1|wc -l)"
echo "$2: $(ls $2|wc -l)"
echo Done!- 앞서 데이터셋을 다운로드 받을 때 레이블은 하남강일 전체에 대한 레이블이였습니다. 따라서 원천 이미지도 하남강일 1번 데이터셋부터 11번 데이터셋까지 전부 다운로드 받고 레이블과 매칭되는 짝이 있는지 살펴봐야합니다.
- 용량관계상 이미지 폴더를 한번에 다운받고 거르는게 불가능해서 아래와 같이 제거합니다.
-
처음에 만들어둔 하남강일(1번) + 송도호반 (현재 image_3 디렉터리)에 label_3과 짝이 맞는 이미지만 남겨두고 제거합니다.
- image는 2962개가 남았네요. 계속해서 하남강일 2~11번 데이터셋을 다운로드받고 각각 동일과정을 반복합니다.

-
하남강일 2번~11번을 순서대로 다운로드 받으면서 같은 과정을 반복합니다.
- 용량이 많다면 한번에 다운로드받아 처리하시면 되겠지만.. 용량이 별로 없으니 노가다합니다.
- 하나씩 확인해보니
하남1번+송도호반 : 2,963, 하남 2번: 5,551, 하남 3번: 2,844, 하남 10번:8,697 , 하남 11번: 6,201장으로 총 26,256장의 이미지 데이터 쌍을 확보했습니다. - 레이블은 29,599개인데 쌍 개수가 맞지 않는군요. 확인해보니 송도호반도 1~2번 데이터셋이 있습니다! 아직 처리하지 않은 2번 데이터셋도 다운로드받아 쌍이 존재하는지 확인합니다: 3,347개 존재
- 총 29,600개의 레이블명과 동일한 이미지 데이터을 확보했습니다.
-
모든 데이터셋에 대해서 짝 체크가 끝난 이미지만 한 폴더에 모아두고 전체적으로 이미지와 레이블 쌍이 맞는지 다시 한번 체크합니다.
- 쌍 존재유무 검사가 끝난 이미지를 모두 합쳤을 때 레이블과 파일 개수가 딱 맞길 기도하시면 됩니다.
- 안맞아도 다시 한번 아래서 거를테니 사실 상관없습니다.
*>_<*이렇게 전처리가 끝난 후에 날라가는 파일들은 아까워서 말이죠!
이럴수가, 이미지를 모두 모으니 레이블개수와 딱 맞는군요. 그래도 검사를 한번 더 진행해주었습니다.

#!/bin/bash
# 이번엔 레이블->이미지 뿐만 아니라, 이미지->레이블 쌍도 검사합니다!
for img in $1/*.jpg
do
kitti_name=$2/$(basename $img .jpg).json
if [ ! -f $kitti_name ]; then
echo "$kitti_name not exist, will remove that image pair."
rm $img
fi
done
for coco in $2/*.json
do
img_name=$1/$(basename $coco .json).jpg
if [ ! -f $img_name ]; then
echo "$img_name not exist, will remove that label pair."
rm $coco
fi
done
echo "$1: $(ls $1|wc -l)"
echo "$2: $(ls $2|wc -l)"
echo Done!아무 문제가 없다면, 아래처럼 이미지, 레이블 개수만 뜨고, 혹시라도 쌍이 맞지 않는 데이터가 남아있었다면 깔끔하게 제거됩니다!

COCO Dataset 으로 변환
앞선 과정을 통해 5개의 클래스를 탐지하는 이미지와 레이블 쌍(데이터셋)을 준비하였습니다.
이제 레이블 파일들(json)을 하나의 COCO annotation 파일로 만들어보겠습니다.
# coding:utf-8
import os
import shutil
import json
# 코드를 실행하기 전에 이미지-json 파일이 정확한 쌍을 이루는지 먼저 확인해주세요.
# 원본 annotation 파일들이 있는 경로
annoDir = "/Users/noharam/Desktop/musma/dataset/safety/data/train/label_3/"
# image가 있는 경로
imageDir = "/Users/noharam/Desktop/musma/dataset/safety/data/train/image_3/"
# anno_dir 내 annotation 파일 이름 리스트업
annoList = os.listdir(annoDir)
print(len(annoList))
# cocoDict에 필요한 images, annotations 정보들의 리스트
imgTmpDict = []
annoTmpDict = []
idNum = 1
annoIdNum = 60000
for anno in annoList:
with open(annoDir + anno, encoding="utf-8-sig", errors="ignore") as json_file:
jsonData = json.load(json_file)
imgPath = anno.replace(".json", ".jpg")
imgSize = 1920 * 1080
try :
images = {
"license": 1,
"file_name": jsonData["image"]["filename"],
"coco_url": "",
"height": jsonData["image"]["resolution"][1],
"width": jsonData["image"]["resolution"][0],
"date_captured": jsonData["image"]["date"],
"flickr_url": "",
"id": idNum
}
except :
images = {
"license": 1,
"file_name": jsonData["image"]["filename"],
"coco_url": "",
"width": 1920,
"height": 1080,
"date_captured": jsonData["image"]["date"],
"flickr_url": "",
"id": idNum
}
imgTmpDict.append(images)
for i in range(len(jsonData["annotations"])):
try: # bbox 정보가 존재할 경우
bbox = [
jsonData["annotations"][i]["box"][0],
jsonData["annotations"][i]["box"][1],
jsonData["annotations"][i]["box"][2]-jsonData["annotations"][i]["box"][0],
jsonData["annotations"][i]["box"][3]-jsonData["annotations"][i]["box"][1]
]
annotation = {
"segmentation": [],
"area": "",
"iscrowd": "",
"image_id": idNum,
"bbox": bbox,
"category_id": int(jsonData["annotations"][i]["class"]),
"id": annoIdNum,
"flags": jsonData["annotations"][i]["flags"],
}
except: # polygon 정보가 존재할 경우
annotation = {
"segmentation": jsonData["annotations"][i]["polygon"],
"area": "",
"iscrowd": "",
"image_id": idNum,
"bbox": [0,0,0,0],
"category_id": int(jsonData["annotations"][i]["class"]),
"id": annoIdNum,
"flags": jsonData["annotations"][i]["flags"],
}
annoTmpDict.append(annotation)
annoIdNum += 1
idNum += 1
# COCO format annotation이 저장될 dict
cocoDict = {}
cocoDict["info"] = {
"description": "AI Hub 공사현장 안정장비 인식 데이터셋",
"url": "https://aihub.or.kr/aidata/33921",
"version": "1.0",
"year": 2021,
"contributor": "Haram roh",
"date_created": "2021/07/22",
}
cocoDict["licenses"] = [
{"url": "https://aihub.or.kr/aidata/33921", "id": 1, "name": "미디어그룹사람과숲(컨)"}
]
cocoDict["images"] = imgTmpDict
cocoDict["annotations"] = annoTmpDict
cocoDict["categories"] = [
{"supercategory": "S2", "id": 1, "name": "안전벨트 착용"},
{"supercategory": "S2", "id": 2, "name": "안전벨트 미착용"},
{"supercategory": "S2", "id": 5, "name": "안전화 착용"},
{"supercategory": "S2", "id": 7, "name": "안전모 착용"},
{"supercategory": "S2", "id": 8, "name": "안전모 미착용"},
]처리가 완료된 후 파일을 저장합니다.
with open("/Users/noharam/Desktop/musma/dataset/safety/data/train/5class_coco.json", 'w') as f :
json.dump(cocoDict, f, ensure_ascii=False)
print("완료했습니다.")COCO2KITTI
이번엔 COCO Dataset 형식을 KITTI Dataset 형식으로 변환해줍니다.
yolo_v4에서 데이터셋 포맷으로 KITTI 혹은 KITTI를 TFRecords로 변환한 데이터셋을 사용하기 때문입니다.

# -*- coding: utf-8 -*-
"""coco2kitti.py: Converts MS COCO annotation files to
Kitti format bounding box label files
__author__ = "haram roh"
"""
import os
from pycocotools.coco import COCO
def coco2kitti(catNms, annFile):
# initialize COCO api for instance annotations
coco = COCO(annFile)
# Create an index for the category names
cats = coco.loadCats(coco.getCatIds())
cat_idx = {}
for c in cats:
cat_idx[c['id']] = c['name']
for img in coco.imgs:
# Get all annotation IDs for the image
catIds = coco.getCatIds(catNms=catNms)
annIds = coco.getAnnIds(imgIds=[img], catIds=catIds) # Image id, Category id를 input으로, 그에 해당하는 annotation id를 return 하는 함수
# If there are annotations, create a label file
if len(annIds) > 0:
# Get image filename
img_fname = coco.imgs[img]['file_name']
# open text file
with open('./labels/' + img_fname.split('.')[0] + '.txt','w') as label_file:
anns = coco.loadAnns(annIds)
for a in anns:
if a['bbox'] :
bbox = a['bbox']
# Convert COCO bbox coords to Kitti ones
bbox = [bbox[0], bbox[1], bbox[2] + bbox[0], bbox[3] + bbox[1]]
bbox = [str(b) for b in bbox]
catname = cat_idx[int(a['category_id'])]
# Format line in label file
# Note: all whitespace will be removed from class names
out_str = [catname.replace(" ","")
+ ' ' + ' '.join(['0']*3)
+ ' ' + ' '.join([b for b in bbox])
+ ' ' + ' '.join(['0']*8)
+'\n']
label_file.write(out_str[0])
if __name__ == '__main__':
# These settings assume this script is in the annotations directory
dataDir = "/Users/noharam/Desktop/musma/dataset/safety/data/train"
dataType = "5class_coco"
annFile = '%s/%s.json' % (dataDir, dataType)
catNms = [
"안전벨트 착용", "안전벨트 미착용", "안전화 착용", "안전모 착용", "안전모 미착용"
]
if os.path.isdir('./labels'):
print('Labels folder already exists - exiting to prevent badness')
else:
os.mkdir('./labels')
coco2kitti(catNms, annFile)해당 과정 수행 후 코드를 실행한 폴더에 내부에 labels 디렉토리가 생성되고, 그 안에 KITTI dataset annotation인 txt 파일들이 들어가게 됩니다.

당연히 파일 개수는 원본 레이블(전처리 후)와 같게 25,599개입니다.
자, 이제 KITTI 형식으로 읽을 수 있는 이미지와 레이블 데이터셋 준비가 모두 끝났습니다.
저는 이 데이터셋을 SFTP로 사내 서버로 옮겨, NVIDIA TAO에서 yolo_v4 훈련에 활용합니다.
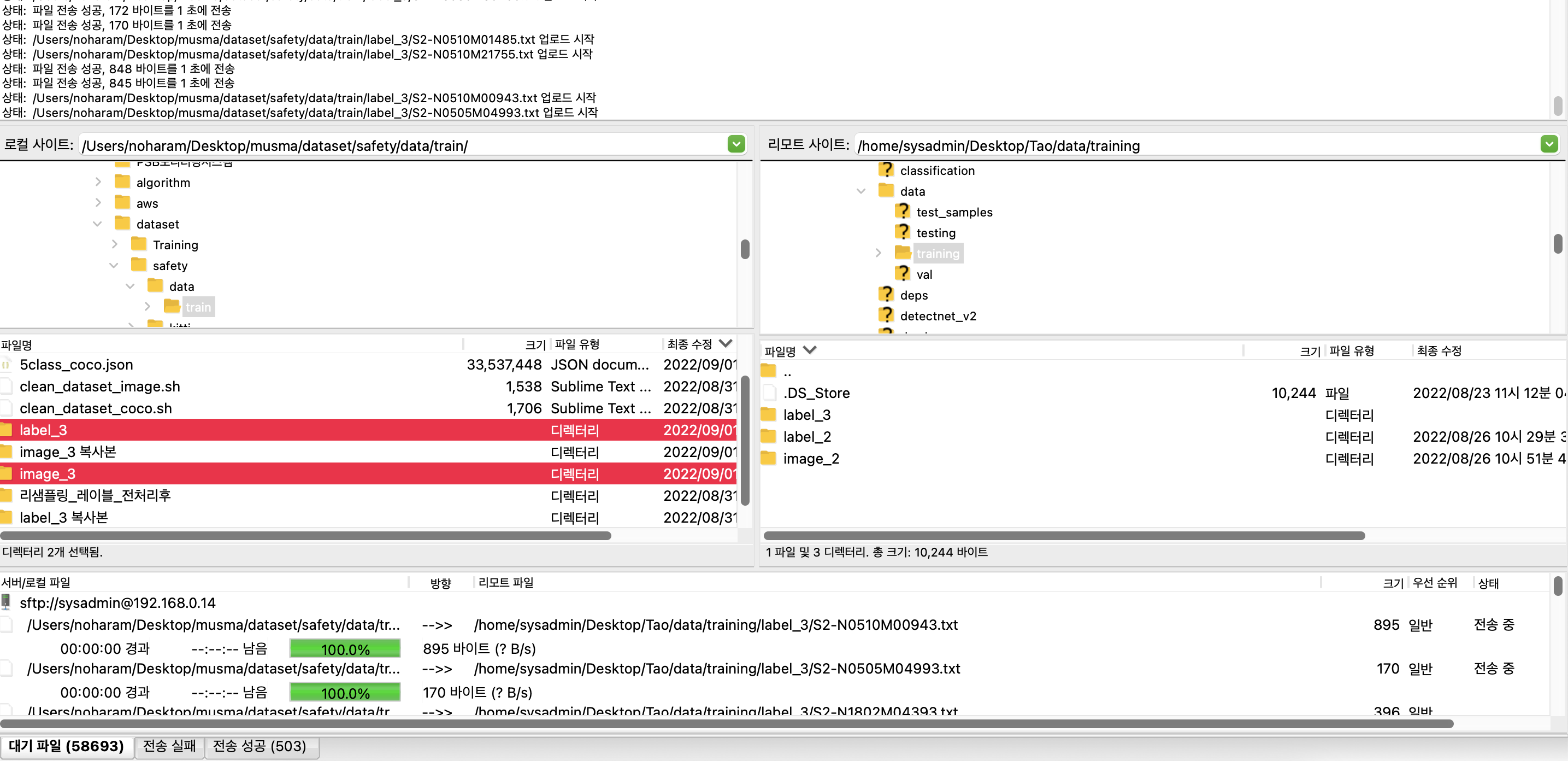
이번 포스팅은 TAO 관련 Object Detection과 이를 AIoT 기기에서 활용하기 위한 주제가 아니라, 모델 훈련을 위한 공공데이터 전처리에 대한 내용이기 때문에 여기서 포스팅을 마무리합니다.
고생하셨습니다!
추가 정보
-
해당 데이터셋을 활용하시는 분을 위한 추가정보입니다.
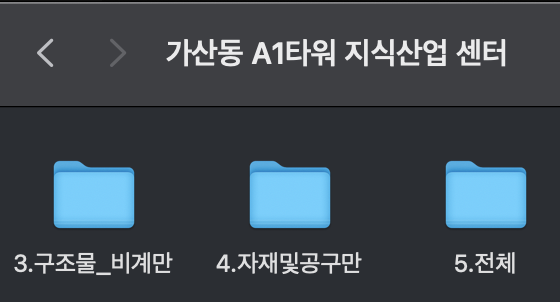
[원천]3.공장_가산동 A1타워 지식산업 센터2.zip과 같은 데이터셋의 레이블에는 아래처럼 전체 레이블이 아닌구조물_비계만, 자재및공구만, 전체등이 저장되어 있습니다.
위에서 활용하려는 일부 레이블이 없는 데이터셋이 존재하기 때문에 사용하려는 레이블이 있는 데이터셋인지 라벨 파일 먼저 다운로드 후 체크해보시기 바랍니다.
-
Tao를 이용한 Yolo_v4 전이학습, Pruning, Retrain, 양자화, TensorRT 등의 NVIDIA TAO 관련 내용은 추후에 포스팅 할 계획입니다.
