CUDA.. 지겹다 너란 놈.
이제 서버에 CUDA 세팅하는 건 마스터했다고 생각했는데
TensorRT를 깔던 도중 CUDA 버전이 이상하는 것을 깨달았다.
오늘 포스팅은 이전에 포스팅한 워크스테이션에 쿠다 설치와 비슷하다.
평소에 nvidia-smi를 활용해 CUDA 버전을 확인하고 있었는데, 이게 실제 서버의 쿠다버전이 아닌, 현재 설치되어 있는 nvidia-driver에서 호환되는 최상위 cuda 버전을 표시하는 것이라고 한다.
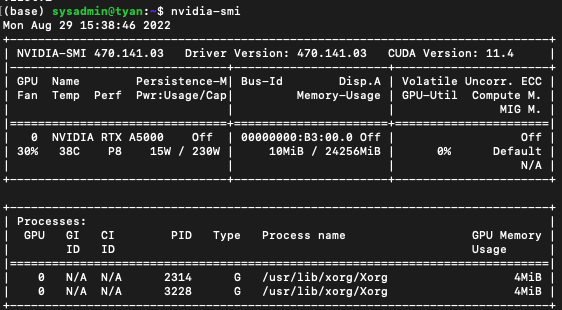
따라서, nvidia-smi에 나온 쿠다 버전은 실제 11.4 버전이 아닌 nvcc --version을 통해서 나오는 릴리즈 버전을 확인해야 한다.

이럴수가, 서버의 쿠다 버전이 9.1 이라니? 대체 언제적 버전이란 말인가.
당장 쿠다를 11.6으로 업데이트하기 위해 설치를 진행해보자.
11.6 버전 사용하는 이유는, latest인 11.7 버전을 설치하자니 계속 이용해야 할 텐서플로, 파이토치, 쿠버플로 등 이런 저전 프레임워크들이 최신 버전을 지원하지 않을 수도 있어서 이전 버전을 이용하기로 하였다.
지금까진 11.4 버전 기준으로 진행했었는데, 11.4보다 11.6이 주로 쓰이는 것 같다.
도커 세팅
혹시 도커가 설치되어 있지 않다면 진행합니다.
Install
-
저장소 설정
$ sudo apt-get update $ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg \ lsb-release -
Docker의 공식 GPG 키 추가
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo -H gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg -
안정적인 저장소를 설정합니다.
설치하기 전에 Architecture 버전을 확인합니다!
$ dpkg -s libc6 | grep Arch
-
Architecture: amd64
-
Multi-Arch: same
echo \ "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null -
x86_64 / amd64
echo \ "deb [arch=arm64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
-
도커 엔진 설치 : 도커 ce 등이 모두 최신 버전으로 설치됩니다. 특정 버전을 설치하려면 상단의 docker 홈페이지를 참고해주세요!
$ sudo apt-get update $ sudo apt-get install docker-ce docker-ce-cli containerd.io
권한 변경
-
일반 사용자계정으로 docker 명령어를 사용하기 위해서는 아래의 명령어로 그룹을 추가
$ sudo usermod -aG docker $USER
NVIDIA-docker 설치
- 다음 명령어를 실행하여 설치합니다.
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit nvidia-container-runtime
sudo systemctl restart docker-
정상설치 확인을 위해 다음 명령을 실행합니다. 자신의 cuda 버전에 따라 tag를 x.0-base로 변경해주세요.
docker run -it --rm --gpus all nvidia/cuda:11.0-base nvidia-smi

현재 GPU 를 사용하고 있는 Process 가 하나도 없다고 나오는 것이 이상하게 생각되실 수 있지만, docker 입장에서는 독립된 자기 자신의 내부 프로세스만 확인할 수 있기 때문에 이는 정상적인 상황입니다.
기존 쿠다 삭제
sudo apt-get --purge -y remove 'cuda*'
sudo apt-get --purge -y remove 'nvidia*'
sudo apt-get --purge -y remove "*nvidia*"
sudo apt-get autoremove --purge cuda
# 실행가능하면 실행
sudo rm -rf /usr/local/cuda*
sudo /usr/local/cuda-xx.x/bin
sudo /usr/bin/nvidia-uninstall
# 패키지 삭제 후 재부팅을 해줘야 재설치 시 오류가 발생하지 않습니다.
sudo reboot쿠다 11.6 설치, 엔비디아 드라이버 업데이트
쿠다 설치 시 엔비디아 드라이버도 호환 버전이 자동으로 설치됩니다.
혹시 모르니 conda deactivate를 통해 콘다 환경위에 있다면, 밖으로 나와주세요.
runfile을 다운받아 실행하는게 가장 간편합니다!
wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run
sudo sh cuda_11.6.2_510.47.03_linux.run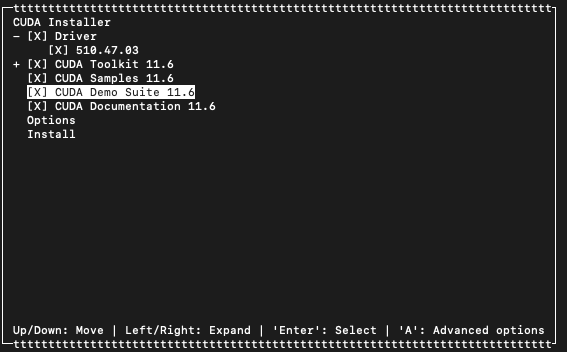
관련 패키지를 모두 설치해주도록 하겠습니다.
smaples, demo suite, docs는 없어도 됩니다.
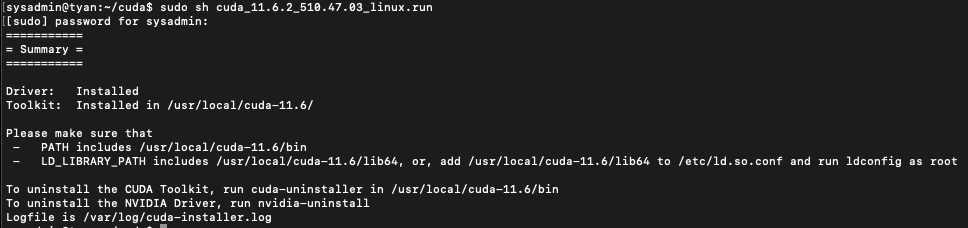
이제 CUDA가 설치되었습니다만, nvcc --version을 실행해보면 쿠다를 찾지 못하는 것을 볼 수 있습니다.
vim ~/.bashrc의 맨 밑 줄에 두 개의 구문을 추가합니다.
export PATH="/usr/local/cuda-11.6/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-11.6/lib64:$LD_LIBRARY_PATH"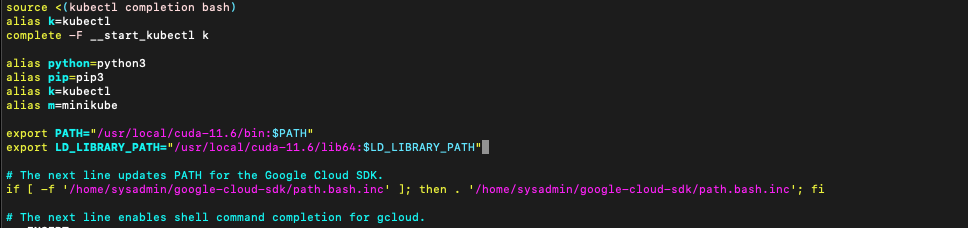
cuDNN 설치
OS, CUDA 버전에 맞는 cuDNN을 선택해 설치파일을 다운로드 받고 설치합니다.
# 다운로드 후
sudo dpkg -i cudnn-local-repo-ubuntu1804-8.5.0.96_1.0-1_amd64.deb
# 설치 후 아래 나오는 CUDA GPG key 등록 커맨드 실행
sudo cp /var/cudnn-local-repo-ubuntu1804-8.5.0.96/cudnn-local-7B49EDBC-keyring.gpg /usr/share/keyrings/버전 확인
nvcc --version
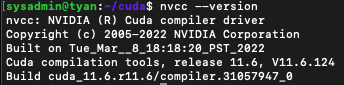
nvidia-smi
TensorRT 설치
- OS와 버전이 적합한 deb 파일을 다운로드합니다.
- 아래 내용의 버전을 변경하고 수행합니다.
os="ubuntu1804"
tag="cuda11.6-trt8.4.2.4-ga-20220720"
sudo dpkg -i nv-tensorrt-repo-${os}-${tag}_1-1_amd64.deb
sudo apt-key add /var/nv-tensorrt-repo-${os}-${tag}/*.pub
sudo apt-get update
sudo apt-get install tensorrt
python3 -m pip install numpy
sudo apt-get install python3-libnvinfer-dev
python3 -m pip install protobuf
sudo apt-get install uff-converter-tf
python3 -m pip install numpy onnx
sudo apt-get install onnx-graphsurgeon- 설치상태를 확인합니다.
dpkg -l | grep TensorRT
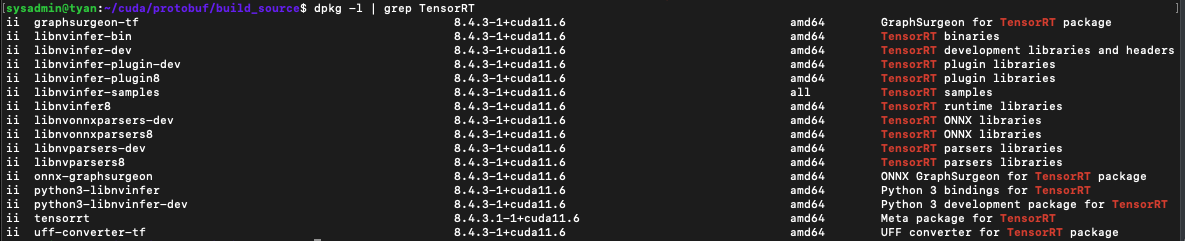
x86에서 TensorRT OSS 빌드
- 아직 필요한지 모르겠습니다. 기록만 해둡니다.
Cmake(>=3.13)를 설치
sudo apt remove --purge --auto-remove cmake
wget https://github.com/Kitware/CMake/releases/download/v3.13.5/cmake-3.13.5.tar.gz
tar xvf cmake-3.13.5.tar.gz
cd cmake-3.13.5/
./configure
make -j$(nproc)
sudo make install
sudo ln -s /usr/local/bin/cmake /usr/bin/cmakeGPU 아키텍처 확인
GPU_ARCHS값은 CUDA deviceQuery 샘플에서 검색할 수 있습니다.
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery/usr/local/cuda/samples시스템에 존재하지 않는 경우 deviceQuery.cpp 이 GitHub 리포지토리에서 다운로드할 수 있습니다. 컴파일하고 deviceQuery를 실행하세요!
git clone https://github.com/NVIDIA-AI-IOT/deepstream_tao_apps.git
cd deepstream_tao_apps/TRT-OSS/x86
nvcc deviceQuery.cpp -o deviceQuery
./deviceQuery
-> 제 GPU_ARCHS 값은 86입니다. 8.6버전은 86, 7.5버전은 75라고 생각하시면 됩니다.
TensorRT OSS 빌드
# 22.05 태그는 trt 8.2.5.1(TAO 컨테이너와 동일)하여 사용합니다.
git clone -b 22.05 https://github.com/nvidia/TensorRT
cd TensorRT/git submodule update --init --recursive
export TRT_SOURCE=`pwd`
cd $TRT_SOURCE
mkdir -p build && cd buildGPU_ARCHS가 TensorRT OSS에 CMakeLists.txt 파일에 있는지 확인합니다. GPU_ARCHS가 TensorRT OSS에 없으면 아래와 같이
-DGPU_ARCHS=<VER>를 인자로 추가합니다.
# 위 과정 모두 완료 후 실행
/usr/local/bin/cmake .. -DGPU_ARCHS=86 -DTRT_LIB_DIR=/usr/lib/x86_64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=`pwd`/out
make nvinfer_plugin -j$(nproc)
- Replace the original libnvinfer_plugin.so*
sudo mv /usr/lib/x86_64-linux-gnu/libnvinfer_plugin.so.8.4.3 ${HOME}/libnvinfer_plugin.so.8.4.3.bak
sudo cp `pwd`/libnvinfer_plugin.so.8.2.5 /usr/lib/x86_64-linux-gnu/libnvinfer_plugin.so.8.2.5
sudo ldconfig이슈 해결
설치에 실패한다면 아래의 두 로그를 확인해 원인을 파악합니다.
제가 겪어본 오류는 2가지 종류입니다.
cat /var/log/cuda-installer.log: 쿠다 설치에 문제가 있는지 파악하기 위한 로그 파일입니다.- 사용중인 그래픽 카드가 드라이버의 어떤 버전까지 지원하는지 확인해보시기 바랍니다.
- 아래의
/var/log/nvidia-installer.log확인해봅니다!
cat /var/log/nvidia-installer.log: nvidia 드라이버 설치시 문제가 발생했는지 파악하기 위한 로그파일입니다.An NVIDIA kernel module 'nvidia-drm' appears to already be loaded in your kernel.와 같은 nvidia-drm 오류가 발생했을 것입니다.- 아래와 같이 해결합니다.
systemctl isolate multi-user.target modprobe -r nvidia-drm lsof /dev/nvidia* systemctl start graphical.target- 위 방법으로 해결이 안된다면 아래를 따라합니다.
sudo vim /etc/modprobe.d/blacklist-nouveau.conf # 아래 내용을 conf파일 내에 등록 blacklist nouveau options nouveau modeset=0 # 저장하고 나오기 :wq! sudo update-initramfs -u - 위에서 재부팅을 진행하지 않았으면 재부팅을 진행합니다.
- onnx 설치 오류는 추후 포스팅 예정
