Minikube Nvidia GPU 구축하고 파이프라인에 GPU를 활용해보자!
그동안 k8s 구축 관련하여 글을 여러개 올렸는데, 이게 아마 k8s, kubeflow, gpu 구축에 관련해서는 마지막이 아닐까 싶네요 ㅎㅎ.. 아마.. 또 다른 환경이 필요하지 않다면 마지막일겁니다🥳
지금까지는 minikube를 구축할 때 cpu 기반으로 돌아가도록 설정을 해왔습니다.
모델을 gpu로 학습시키고 싶어서 방법을 알아보다, minikube를 구축할 때 간단한 gpu 옵션만 넣어주면 될 줄 알았는데 생각보다 복잡한 부분이 있어서 작성합니다.
이번 포스팅에서는 End to End로 Minikube GPU k8s 구축부터 Kubeflow Pipeline에 GPU 자원을 활용하는 것을 확인하는 부분까지 진행할 예정입니다.
다만 로컬에 GPU, CUDA 세팅은 완료되어 있으신 분들을 대상으로 합니다. 아래 세팅이 되어있지 않은 경우 링크를 달아놨으니 참고바랍니다.
minikube CPU->GPU 재구축 과정
기존 Minikube profile 확인 및 삭제
기존에 사용하고 있던 CPU 기반 Minikube k8s 서버를 확인해보니, 추가로 GPU 기반의 k8s를 설치할 용량이 없습니다.
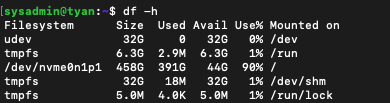
현재 Profile은 miku라는 이름으로 사용하고 있는데, 용량을 아마 200Gi로 잡았던 것으로 기억합니다.
다시 처음부터 네트워크 설정 등을 진행하는 것이 불편하긴 하지만 GPU를 사용해야 하는 상황이니 어쩔 수 없죠.
기존의 Profile을 날려봅시다.
Profile list 확인
minikube profile list

2개의 profile(클러스터)가 생성되어 있군요. 모두 날려서 초기화해줍니다.
Profile 삭제
minikube delete --all
minikube delete -p miku
minikube delete -p mk
다행히 사용중이라고 에러가 나는 부분은 없었네요. 다시 프로필 리스트를 확인해보고 모두 삭제되었는지 확인합니다.
프로필을 삭제하면 k8s 클러스터 내부의 모든 노드 그룹(마스터+워커)이 삭제되는 것을 확인하실 수 있습니다.
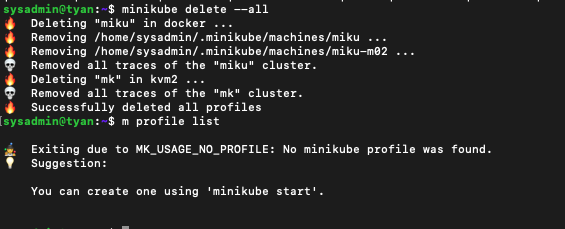
용량 확인
df -h
아까 44G 밖에 남지 않았던 서버 용량이 236G의 여유를 가지게 된 것을 볼 수 있습니다. CPU로 구축할 때 용량을 200Gi로 준 것이 맞는 것 같네요.
다만 앞으로 NFS로 서버에 모델을 지속적으로 저장할 예정인데 200Gi로 버틸 수 있을지 모르겠네요.
None 드라이버 활용(host 설정 활용)
안타깝게도 kvm2 와 none 를 제외한 driver 옵션들은 GPU passthrouh 를 지원하지 않기 때문에 macOS 와 Windows 에서는 minikube 로 gpu 사용은 할 수 없습니다.
none 드라이버는 기존의 docker 드라이브를 사용했던 것과 달리 몇가지 문제점이 있습니다.
- p(프로필)이 지원되지 않음: 둘 이상의 --driver=none인스턴스 를 실행할 수 없습니다.
- 다음과 같은 많은 minikube명령이 지원되지 않습니다. dashboard, mount,ssh
- 드라이버가 있는 minikube는 none일부 명령을 루트("시작")로 실행해야 하고 다른 명령은 일반 사용자("대시보드")로 실행해야 하기 때문에 혼란스러운 권한 모델을 가지고 있습니다.
- CoreDNS는 리졸버 루프를 감지하고 CrashLoopBackOff로 이동합니다. - 일부 Linux 버전에는 Kubernetes가 예상하는 것보다 최신 버전의 docker가 있습니다. 이것을 덮어쓰려면 다음 매개변수로 minikube를 실행하십시오.sudo -E minikube start --driver=none --kubernetes-version v1.11.8 --extra-config kubeadm.ignore-preflight-errors=SystemVerification
- 기존에 사용하던 memory, cpus, nodes(다중 노드 설정), profile 등의 플래그를 사용할 수 없습니다.
이미 호스트에서 GPU를 설정하고 사용하시는 분을 기준으로 설명하겠습니다.
(사용하시는 GPU에 맞는 NVIDIA Driver 와 CUDA 는 이미 로컬에 잘 설치되었다고 가정)
설정되어 있지 않다면 다음 링크를 참고해서 설치해주세요.
Prerequisites
- OS : Ubuntu 18.04
- minikube : v1.12.3
- docker-ce : 20.10.12
- GPU : NVIDIA RTX A5000 D6 24GB * 2
- nvidia graphics driver :
- NVIDIA-SMI : 430.64
- Driver Version: 430.64
- CUDA Version: 11.4
- nvidia-docker
- nvidia-container-runtime
- nvidia-container-toolkit
- kustomize : v3.2.3
쿠버네티스 GPU 스케쥴링, 요구사항, 제약사항은 여기를 참고하세요!
NVIDIA driver, NVIDIA docker 설치 및 설정
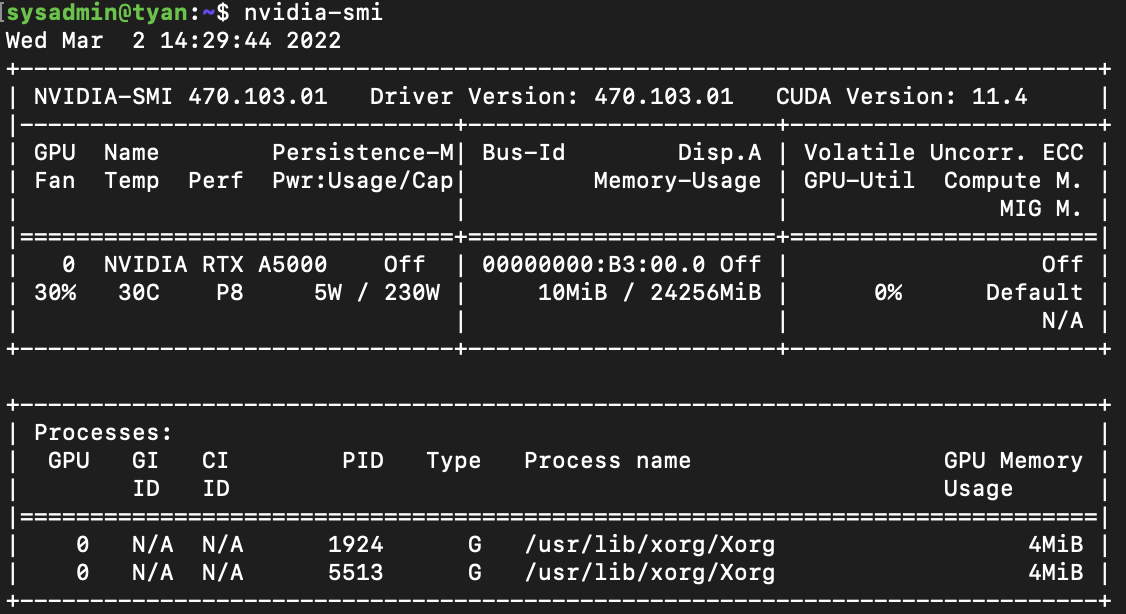
NVIDIA Driver 설치
정상적으로 설치되었다면 다음 명령을 통해 아래와 같이 GPU 상태를 확인할 수 있습니다.
- nvidia-smi
NVIDIA-docker 설치
- 다음 명령어를 실행하여 설치합니다.
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit nvidia-container-runtime
sudo systemctl restart docker-
정상설치 확인을 위해 다음 명령을 실행합니다. 자신의 cuda 버전에 따라 tag를 x.0-base로 변경해주세요.
docker run -it --rm --gpus all nvidia/cuda:11.0-base nvidia-smi

현재 GPU 를 사용하고 있는 Process 가 하나도 없다고 나오는 것이 이상하게 생각되실 수 있지만, docker 입장에서는 독립된 자기 자신의 내부 프로세스만 확인할 수 있기 때문에 이는 정상적인 상황입니다.
docker default-runtime 변경
Minikube 는 docker default-runtime 을 Docker-CE 로 사용하지만, docker container 내에서 NVIDIA GPU 를 사용하기 위해서는 nvidia-docker 라는 docker-runtime 으로 docker container 를 생성해야 합니다.
- nvidia-docker : 간단히 말하면 Docker-CE 의 확장판
따라서 Minikube 가 nvidia-docker 로 pod 내부의 container 를 생성할 수 있도록 호스트의 default-runtime 설정을 변경해주어야 합니다.
docker daemon config file 을 다음과 같이 수정합니다.
1. vim /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}- 수정 후 docker 를 재시작합니다.
sudo systemctl daemon-reload
sudo service docker restart
Minikube 시작
minikube 를 생성합니다. kubernetes-version 은 v1.15 이상이어야 합니다.
None 드라이버는 CPU k8s에서 설정했던 것과 다르게 VM을 생성하지 않고, 호스트(서버)의 정보를 이용합니다.(VM을 통하지 않고 진행합니다. 기존엔 docker driver를 이용했죠.)
그래서 memory, cpus, profile등의 플래그를 지원하지 않습니다.(서버에서 일정 리소스를 떼내어 k8s 클러스터를 위한 VM을 생성하지 않는다는 의미입니다.)
$ minikube start --driver=none --kubernetes-version=v1.20.11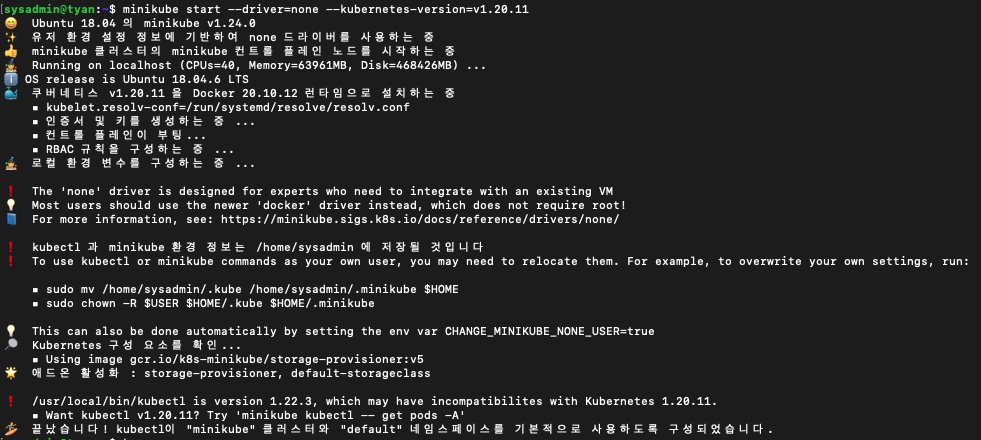
Minikube 구성 확인
기본적인 namespaces와 동작중인 pods는 아래와 같이 구성되어 있습니다.
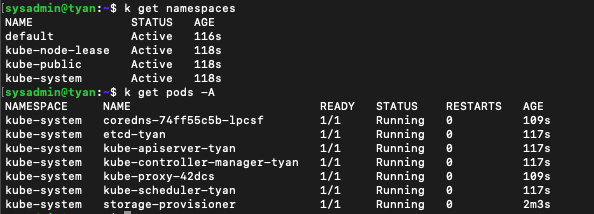
혹시 coredns가 CrushLoopBackOff 상태에 빠져계시다면 아래를 참고하시길 바랍니다.

출처 : https://anencore94.github.io/2020/08/19/minikube-gpu.html
NVIDIA의 장치 플러그인 설치
nvidia 에서 DevicePlugin Framework 에 맞춰 gpu 사용을 위해 개발한 nvidia-device-plugin 을 배포합니다.
nvidia-device-plugin 은 daemonset 으로 생성되지만, minikube 를 1 node 로 생성했으므로 1 개의 pod 이 RUNNING 상태로 생성되었는지 확인합니다.
node 정보에 gpu 가 사용가능하도록 설정되었는지 확인합니다.
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/master/nvidia-device-plugin.yml
kubectl get pod -A | grep nvidia
kubectl get nodes "-o=custom-columns=NAME:.metadata.name,GPU:.status.allocatable.nvidia\.com/gpu"이제 Minikube의 k8s환경에 nvidia gpu setting 을 끝났습니다.
이제 gpu를 pod이 사용할 수 있는지를 테스트해봅니다.
pod의 GPU 사용 확인
다음과 같이 cuda lib 를 포함하고 있는 nvidia/cuda:11.0-runtime 이미지로 pod 을 생성합니다.
- 로컬의 GPU 에 맞는 cuda version 이미지로 생성해야 하는 것에 주의 바랍니다.(전 11.4라서 nvidia/cuda:11.0-runtime을 사용합니다)
- 적합한 cuda 를 포함한 이미지라면 어떤 이미지든 사용 가능합니다.
- 예) tensorflow/tensorflow:2.2.0rc2-gpu-py3 등 - cuda 를 포함하지 않은 일반 nginx 등의 이미지로 생성된 pod 의 경우에는 gpu 를 정상적으로 사용하지 못함에 주의 바랍니다.
spec.resources.requests와spec.resources.limits에nvidia.com/gpu를 포함해야 pod 내에서 GPU 사용이 가능합니다.(중요)
gpu-container.yaml을 생성해줍니다.
kubectl logs를 통해 GPU가 인식되었는지 확인합니다.
apiVersion: v1
kind: Pod
metadata:
name: gpu
spec:
containers:
- name: gpu-container
image: nvidia/cuda:11.0-runtime
command:
- "/bin/sh"
- "-c"
args:
- nvidia-smi && tail -f /dev/null
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1cd Desktop/minikube/gpu (폴더는 임의로 생성해서 파일을 저장하시면 됩니다.)
vim gpu-container.yaml (파일을 열고 해당 내용을 저장합니다.)
kubectl create -f gpu-contianer.yaml (yaml에 따라 pod을 생성합니다. default namespace에 생성됩니다.)
kubectl logs gpu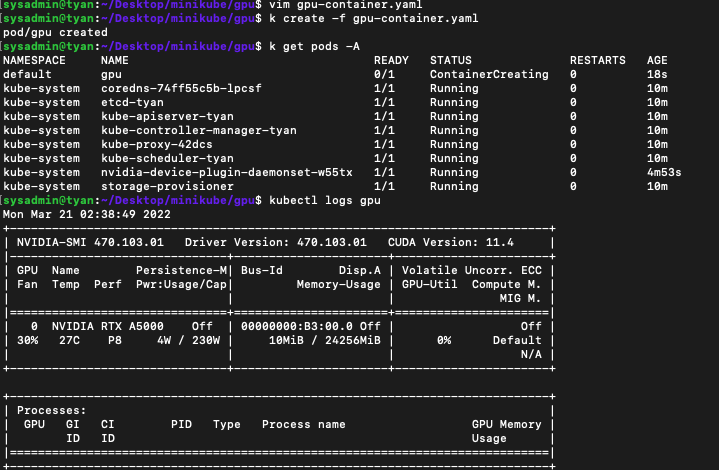
kubeflow 설치 및 서비스
저번 포스팅과 동일한 부분이지만, 이 포스팅만 읽고 Kubeflow Pipeline을 GPU로 모두 구동하고자 하시는 분들을 위해 End to End로 포스팅을 진행하겠습니다.
install kustomize
- 3.2 버전을 설치합니다. 4.x 버전은 호환성에 문제가 있습니다.
https://github.com/kubernetes-sigs/kustomize/releases/tag/v3.2.0
$ curl --silent --location --remote-name \
"https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize/v3.2.3/kustomize_kustomize.v3.2.3_linux_amd64" && \
chmod a+x kustomize_kustomize.v3.2.3_linux_amd64 && \
sudo mv kustomize_kustomize.v3.2.3_linux_amd64 /usr/local/bin/kustomize
$ kustomize version
install kubeflow
$ cd Desktop/minikube
$ git clone https://github.com/kubeflow/manifests.git
$ cd manifests/
$ while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done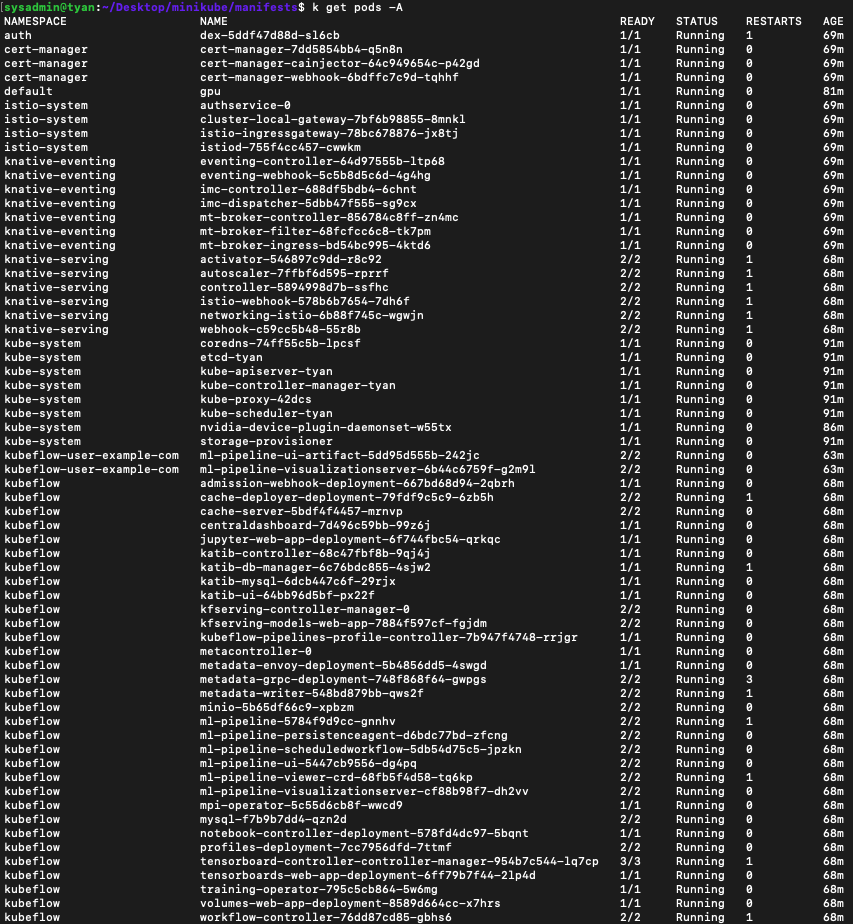
- 설치 후 모든 pod이 성공적으로 running 되려면 2~30분 이상의 시간이 소요될 수도 있습니다. 아무리 기다려도 pending 상태 등이 지속된다면, 컴퓨터의 리소스가(memory 등) 부족하지 않는지 검토해주세요. 관련 내용은 이전 포스팅에 있습니다.
서비스 동작 확인
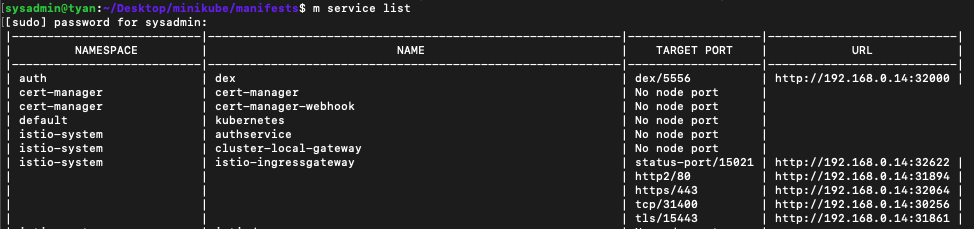
minikube service list -n istio-system
- 서버에 구축했으니 아직 service URL은 서버에서만 접속 가능합니다. 클라이언트에서 서버로 ssh 접속해서 작업하고 계시면 아직 접속 불가능한게 당연합니다.
- 서버에선 해당 istio-ingressgateway의 http2/80포트의 URL인 http://192.169.0.14:31894로 kubeflow UI에 접속이 가능합니다.
- 접속하면 DEX 인증 페이지가 뜨실텐데 ID/PW는
user@example.com / 12341234입니다.
서비스에 외부에서 로컬 포트포워딩으로 접속
이제 서버에 k8s kubeflow gpu세팅이 끝났으니 클라이언트에서 서버에 구축된 Kubeflow UI에 접속할 수 있는 방법을 확인해보겠습니다.
- istio-ingressgateway의 serviceType을 nodeport에서 loadBalancer로 변경합니다.
kubectl patch service -n istio-system istio-ingressgateway -p '{"spec": {"type": "LoadBalancer"}}'

- 아직 External-IP는
<pending>상태입니다.

-
MetalLB를 활성화합니다.
minikube addons list: 에드온에 metalLB를 확인합니다.
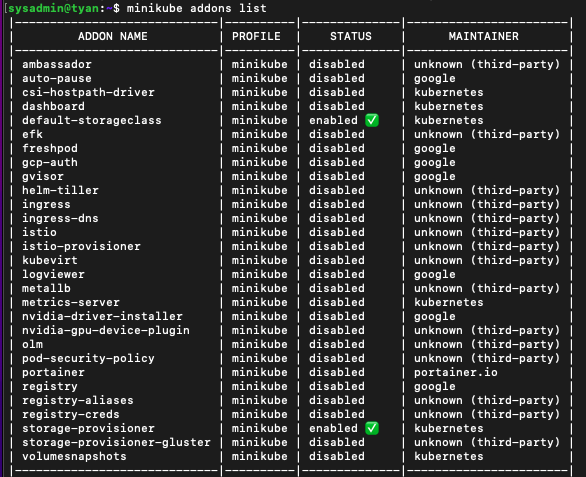
minikube addons enable metallb: metallb를 활성화합니다.

minikube addons configure metallb: kubeflow의 서비스에 배정할 IP범위를 설정합니다. (istio-ingressgateway, promethues, grafana 등 설정할 게 많으면 범위를 늘려야하는데, VM IP주소가 아닌 호스트 IP주소를 쓰려니 기존에 공유기에서 사설 IP를 받아 쓰던 내부망 클라이언트들과 충돌이 있을 우려가 생겨버렸습니다.)
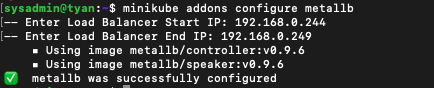
- 여기까지 완료하면 설정한 IP범위 내에서 정상적으로 EXTERNAL-IP가 생성된 것을 확인하실 수 있습니다.

-
공유기 포트포워딩을 설정합시다.
- iptime 공유기를 사용중이라면
192.168.0.1(공유기 관리자 페이지)로 접속합니다. - 공유기에 따라 관리자 페이지 접속 주소가 다릅니다. 맞춰서 진행해주시면 되겠습니다.
- 로그인 후
관리도구 - 왼쪽 네비게이션의 고급 설정 - NAT/라우터 관리 - 포트포워드 설정으로 들어갑니다.
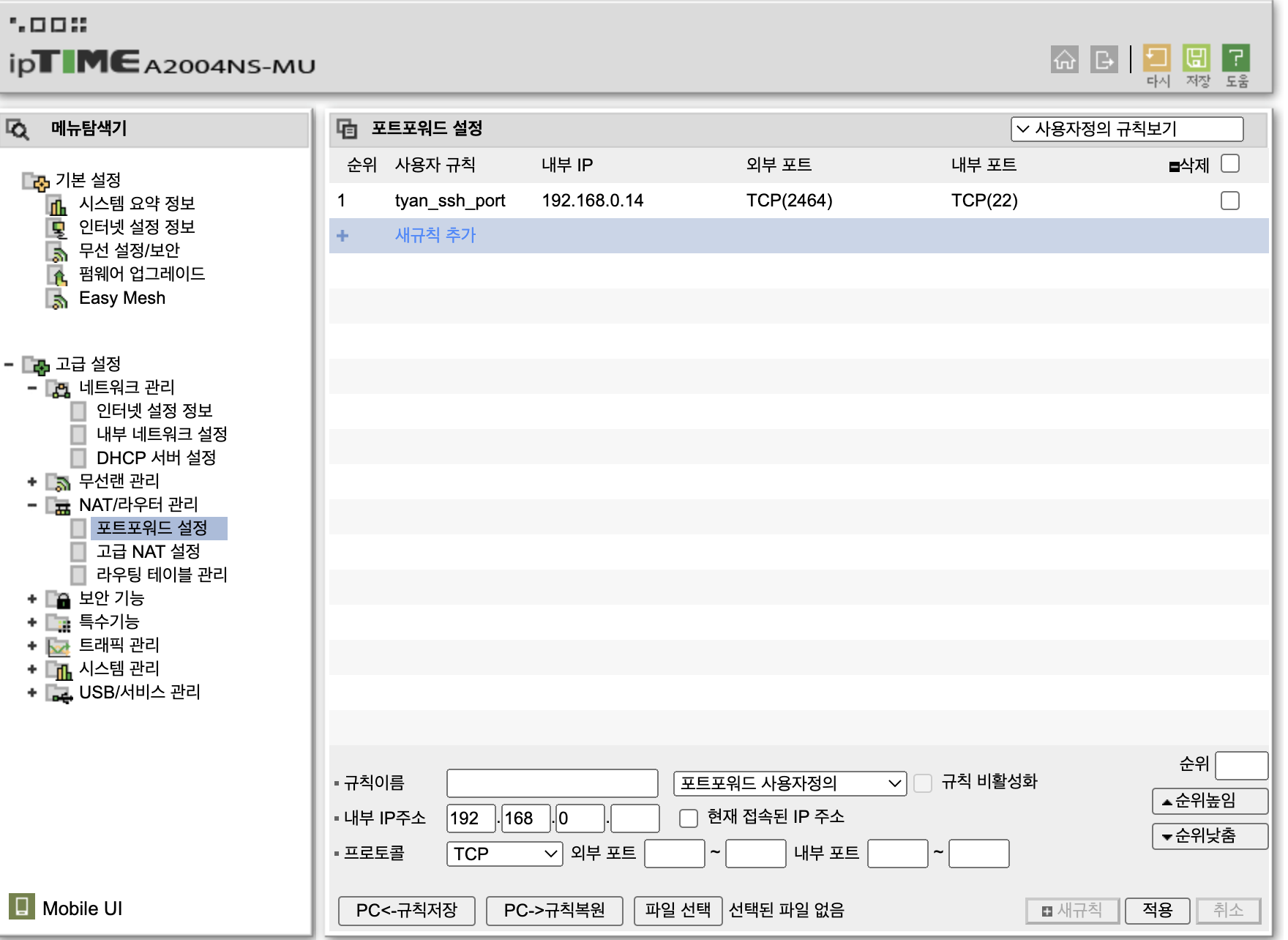
- 새규칙을 추가합니다. 서버의 사설 IP를 기억하시나요? 저는 서버 사설 IP가 192.168.0.14입니다. 그래서 접속하고자 하는 내부 IP를
192.168.0.14로 설정하고, 외부 IP(공유기의 진짜 IP입니다.)의 외부포트(2464)로 접속하면 사설 IP의 내부 포트(22)로 접속이 되게 설정한 모습입니다. - 이후 클라이언트 터미널에서
ssh -L 2464:<istio-ingressgateway EXTERNAL-IP>:80 <서버계정명>@<외부IP> -p 2464로 접속 후 비밀번호를 입력하시면 아래처럼 서버에 접속된 모습을 확인할 수 있습니다. 예시를 보여드리고 싶은데 외부IP를 공개하면 안되기 때문에 생략합니다.ssh -L 2464:192.168.0.244:80 sysadmin@<외부IP> -p 2464
- iptime 공유기를 사용중이라면
-
이제 로컬 포트포워딩으로 서버에 접속해봅니다.
- 이제까지의 포트포워딩 관련 자세한 내용은 여기를 참고해주세요.
- 저렇게 서버에 접속한 후 부터는 클라이언트에서
local:2464로 접속하시면 서버의 Kubeflow를 바로 이용하실 수 있습니다.
파이프라인에 GPU 설정
여기부터는 코드가 없으시기 때문에 따라하시기 힘드실 수 있습니다.(파이프라인 예제 코드는 이곳저곳에 많으니까 한번 적용해보시기 바랍니다!)
기존의 파이프라인 코드를 가지고 계신 분께서는 관련된 설정을 추가하시는 것만 참고해주시면 되고,
나중에 기회가 된다면 공개할 수 없는 코드는 제외하고 파이프라인 관련 코드를 따로 깃허브에 작성하여 공유드리겠습니다.(따로 요청하지는 말아주세요)
업무를 진행하면서 기록해놀 다양한 정보를 적어두었으니, 필요한 부분만 찾아서 사용하시면 되겠습니다.
사실 전체적인 코드를 공유하지 않고 필요한 부분을 알려드리기 쉽지않아서, 대략적으로 알려드리자면 아래와 같습니다.
1. 컨테이너의 베이스 이미지가 cuda를 포함하여 GPU를 지원해야 합니다.(예를 들어, tensorflow/tensorflow:2.8.0-gpu 등입니다.
2. 클러스터(노드)가 위에서 진행한 것과 같이 nivdia-docker 기반으로 돌아가야하고 GPU를 정상 인식하고 있어야 합니다.(안되어 있다면 제일 윗 부분으로 돌아가 진행해주세요_
3. k8s 자원들을 선언할 때 리소스에 gpu에 대한 정보를 넣어주어야 합니다.
"resources": {
"limits": {
"nvidia.com/gpu": 1
}
}- 훈련 코드를 실행할 때 해당 프레임워크에 맞게 GPU 설정을 해주셔야 합니다. (TF/torch/rllib 등)
(번외)rllib GPU 설정 및 확인
저는 rllib 및 TF 모델들에 대해서 GPU를 사용할건데, 순차적으로 rllib에서 gpu를 사용하기 위한 설정을 하고 넘어가겠습니다.
-
Dockerfile의 이미지를
tensorflow/tensorflow:2.8.0에서tensorflor/tensorflow:2.8.0-gpu로 바꿔서 빌드했습니다. -
Katib(하이퍼 파라미터 튜닝)을 설정할 때 스펙 파일에 컨테이너 resources를 추가로 생성했습니다. 이미지를 참고해주세요.
- 리소스에서 limits만 설정해주면 request는 limits에 따라서 자동으로 설정되므로 request를 별도로 설정할 필요는 없습니다. 관련 정보는 여기 등을 참고해주세요.
- 참고로 아직 쿠버네티스에서 저렇게 리소스를 정의할 때 GPU를 나눠쓰는 기능이 없습니다.(여러 pod에서 동시에 1개의 GPU를 0.x개로 나누어 사용할 수 없습니다. 한 컨테이너가 사용을 종료한 뒤 다음 컨테이너에서 사용해야합니다.)
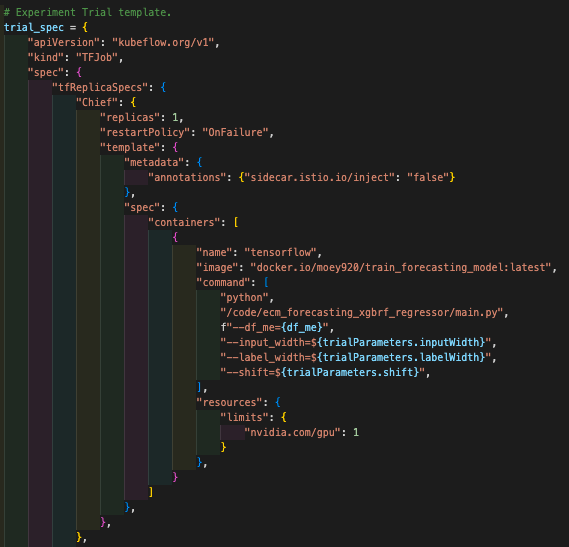
-
rllib agent config에서 GPU 개수를 설정해줍니다.

- 훈련 결과를 확인해봅시다.
- GPU가 사용되었는지 확인할 수는 없으나(확인 방법을 알아보는 중입니다.) 일단 정상적으로 훈련은 진행되는군요.

- GPU가 사용되었는지 확인할 수는 없으나(확인 방법을 알아보는 중입니다.) 일단 정상적으로 훈련은 진행되는군요.
지금까지 Minikube에 호스트의 GPU를 인식시켜서 Pipeline이 GPU 기반으로 돌아가도록 설정해보았습니다.
처음부터 다시 구축하면서 진행해봤는데 혹시 따라하시다가 안되는 부분이 있으면 댓글이나 moey920@musma.net으로 연락주시면 확인해보고 답변드리겠습니다.
고생하셨습니다!
Kubeflow 캐싱 비활성화
파이프라인을 돌리시다보면, 저장된 캐시를 가져와 컴포넌트를 재실행하지 않고 캐시를 사용하는 바람에 pod가 Running 상태에 멈춰서 계속 timeout을 기다리는 상황이 발생할 수 있습니다.
예를 들어 이전 파이프라인 작동 시 볼륨을 생성했는데, 임의로 볼륨을 삭제하고 동일한 파이프라인이 재작동되면(Recurring job이라든지)
가지고 있는 볼륨 캐시를 이용해서 볼륨 정보를 가지오지만, 실제 볼륨이 삭제되어 있기 때문에 아무것도 진행되지 않습니다.
그래서 들어오는 데이터의 특성이 변한다든지(실시간 시계열 데이터 등) 재학습이 필요한 컴포넌트 등에선 캐싱이 오히려 재학습에 방해가 될 수 있습니다.
이러한 파이프라인 및 학습의 오류를 방지하기 위해 캐싱 기능을 비활성화 해두시는 걸 추천드립니다.
$ export NAMESPACE=kubeflow
$ kubectl get mutatingwebhookconfiguration cache-webhook-${NAMESPACE}
$ kubectl patch mutatingwebhookconfiguration cache-webhook-${NAMESPACE} --type='json' -p='[{"op":"replace", "path": "/webhooks/0/rules/0/operations/0", "value": "DELETE"}]'실험(권장하지 않는 방법들)
(추가) KVM2 드라이버 활용
KVM2 드라이버 설치
KVM(Kernel-based Virtual Machine) 은 가상화 확장을 포함하는 x86 하드웨어 기반 Linux용 전체 가상화 솔루션입니다. KVM으로 작업하기 위해 minikube는 libvirt 가상화 API를 사용합니다.
링크
각 운영체제에 맞게(저는 우분투) kvm2 드라이버를 설치 후 libvirt가 오류를 보고하지 않는지 확인합니다.
-
virt-host-validate
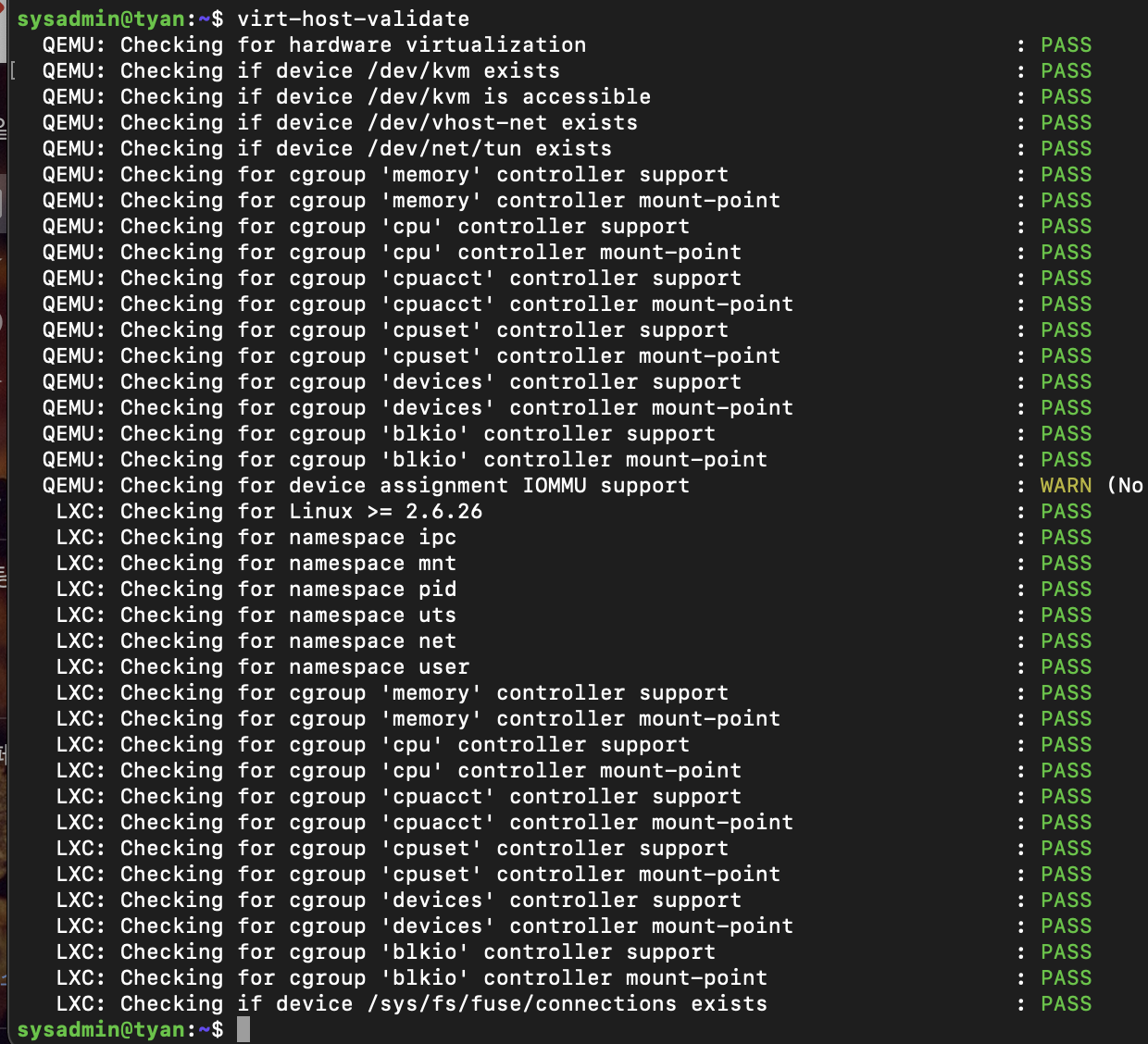
-
IOMMU 경고를 반드시 해제하고 넘어가야 진행됩니다.
Checking for device assignment IOMMU support : WARN (No ACPI DMAR table found, IOMMU either disabled in BIOS or not supported by this hardware platform)
시스템 가상화 지원 확인
VM 드라이버를 사용하려면 시스템에 가상화 지원이 활성화되어 있는지 확인하십시오.
egrep -q 'vmx|svm' /proc/cpuinfo && echo yes || echo no

PCI passthrough 설정
호스트의 GPU 자원을 VM에서 가져다 쓸 수 있도록 PCI passthrough 설정이 선행되어야 합니다.
IOMMU bios를 설정하고, 마더보드에서도 IOMMU가 지원되는지 확인해야 하며
커널에서 intel_iommu=on또는 amd_iommu=on (CPU 공급업체에 따라) 커널 명령줄에 추가합니다. 또한 iommu=pt 커널 명령줄에 추가합니다.
링크
저는 BIOS 설정에 관한 부분에서 시간이 오래 소요될 것 같아 일단 중지합니다. 올려드린 링크를 참고하시면 모두 진행가능한 부분이니 필요하신 분은 확인 바랍니다!
(추가) Minikube 시작(Sudo로 진행, 오류 발생)
- 권장하지 않는 방법입니다. 참고만 하세요.
root user 로 변경한 뒤, minikube 를 생성합니다. kubernetes-version 은 v1.15 이상이어야 합니다.
저는 현재 서버에서 memory와 cpu를 모두 동원하여 진행할 것이기 때문에 argument를 max로 주었습니다.
각자 상황에 맞게 조절해주시기 바랍니다.
$ sudo su
$ sudo sysctl fs.protected_regular=0
$ sudo -E minikube start --driver=none --kubernetes-version=v1.20.11아래는 진행하며 겪었던 이슈 리스트입니다.
에러 (1) : conntrack 오류
Exiting due to GUEST_MISSING_CONNTRACK: Sorry, Kubernetes 1.20.11 requires conntrack to be installed in root's path
sudo apt-get install -y conntracksudo -E minikube start --driver=none --kubernetes-version=v1.20.11
에러 (2) : 권한 오류
Exiting due to HOST_JUJU_LOCK_PERMISSION: Failed kubeconfig update: unable to acquire lock for {Name:mkadf8508dcf53c4fdfaf2f27e4fe4e8ed447767 Clock:{} Delay:500ms Timeout:1m0s Cancel:<nil>}: unable to open /tmp/juju-mkadf8508dcf53c4fdfaf2f27e4fe4e8ed447767: permission denied

관련 이슈
- 원래는 sudo로 minikube를 실행하는 것이 권장되지 않습니다. 일반 사용자로 minikube gpu 구축을 진행해보진 않았지만, 여러 자료에서 gpu 사용시 sudo를 붙이고 있어서 동일하게 진행합니다. 오류 해결을 위해선 아래와 같이 진행합니다.
sudo su
sudo sysctl fs.protected_regular=0
sudo -E minikube start --driver=none --kubernetes-version=v1.20.11에러 (3) : storage-provisioner addon 오류
설치 중 storage-provisioner에 관한 오류가 발생합니다. 앞으로 addon을 사용할 때도 동일한 오류가 발생할 수 있을 것 같아 해결하고 넘어갑니다.
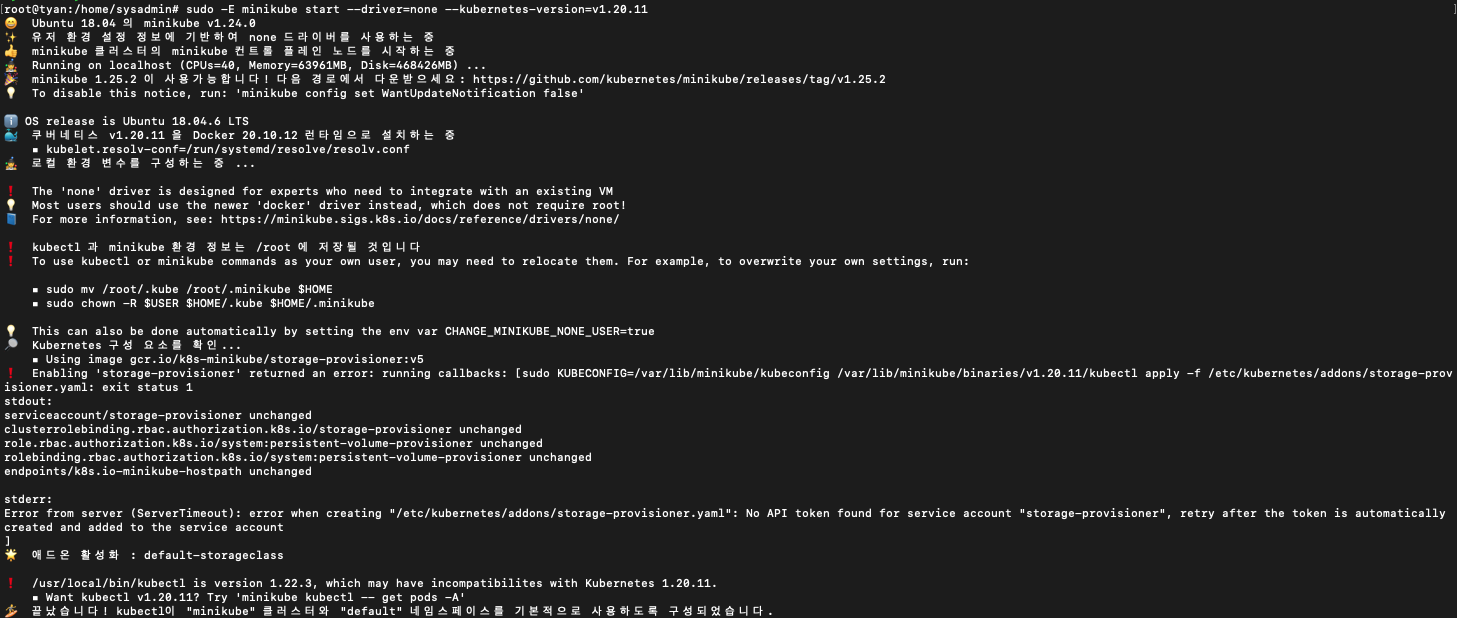
위에서 프로필을 정리할 때 minikube delete --all 플래그를 사용했더니 프로필에 대한 데이터가 남아있어서 발생한 문제 같습니다.
모든 프로필을 삭제하고, 클러스터를 삭제한 뒤 rm rf ~/.minikube 폴더도 삭제해서 초기화 시켜준 뒤 다시 설치해보겠습니다.
minikube delete -p miku
minikube delete -p mk
minikube delete -p minikube
rm -rf ~/.minikube- 해당 방법으로 해결이 되지 않습니다. sudo를 사용하지 않고 그냥 Nvidia Docker 설정 완료 후 일반 사용자에서
minikube start ~를 하면 정상 진행됩니다.

좋은 자료 감사합니다!