"None of [Index([..], dtype='object')] are in the [columns]" 에러
- 상황 : 전처리된 데이터 프레임을 결과 데이터 프레임에 저장하려고 할 때
result_df[eqp_id] = res[cols]발생
raise KeyError(f"None of [{key}] are in the [{axis_name}]")
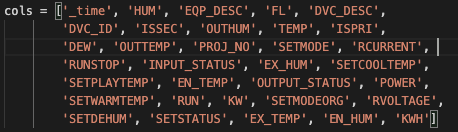
KeyError: "None of [Index(['_time', 'HUM', 'EQP_DESC', 'FL', 'DVC_DESC', 'DVC_ID', 'ISSEC',\n 'OUTHUM', 'TEMP', 'ISPRI', 'DEW', 'OUTTEMP', 'PROJ_NO', 'SETMODE',\n 'RCURRENT', 'RUNSTOP', 'INPUT_STATUS', 'EX_HUM', 'SETCOOLTEMP',\n 'SETPLAYTEMP', 'EN_TEMP', 'OUTPUT_STATUS', 'POWER', 'SETWARMTEMP',\n 'RUN', 'KW', 'SETMODEORG', 'RVOLTAGE', 'SETDEHUM', 'SETSTATUS',\n 'EX_TEMP', 'EN_HUM', 'KWH'],\n dtype='object')] are in the [columns]"- 원인 : 데이터 프레임의 열 이름에 공백이나 필요없는 문자가 들어가있기 때문입니다.
- 지금 에러를 살펴보면\n 'OUTHUM'처럼\n가 포함된 인덱스가 보입니다.- 저는 인덱스를 다음과 같이 설정했습니다.
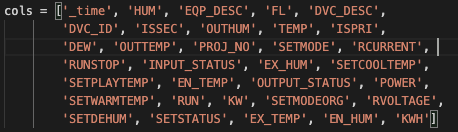
- 가독성을 위해 엔터로 인덱스를 줄을 바꾸었을 뿐이고, 심지어 그림에서처럼 DVC_DESC 다음에 엔터를 쳤지만 에러에서는 ISSEC 다음에
\n이 들어갑니다. - 이유가 뭘까요?
- 저는 인덱스를 다음과 같이 설정했습니다.
해결 시도
-
cols를 수정했음에도 엔터를 친 위치와 다르게
\n이 등장한다. -> 혹시 변수를 불러올 때 cache를 사용하나?? -> 파이썬에서 cache를 사용한다는 개념을 생각해본적이 없다!! -> 근데 항상 python 명령을 실행하면__pycache__폴더가 생기는 것이 생각났다. ->__pacache폴더를 삭제 후 다시 파이썬 파일을 실행시켜보았다. -> 역시나 해결되지 않았다. 오류가 변하지 않았다. -
map(lambda x: str.replace(x, " ", ""), cols)함수를 이용해 공백과\n을 대체시켰다. 보기엔 아무런 문제가 없어보인다. 다시 파이썬 파일을 돌려보자. -> 될 줄 알았는데 안되네요..def get_result(query_list, query_api, org, cols): result_df = dict() cols = map(lambda x: str.replace(x, " ", ""), cols) cols = map(lambda x: str.replace(x, "\n", ""), cols) for eqp_id, query in query_list: res = query_api.query_data_frame(org = org, query = query) result_df[eqp_id] = res[list(cols)] return result_df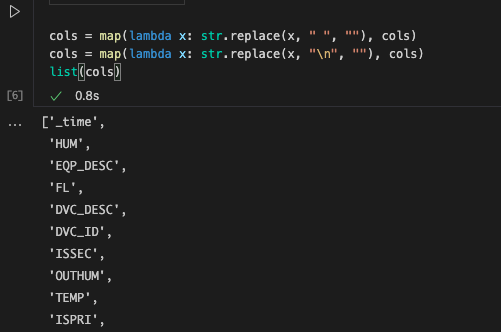
-
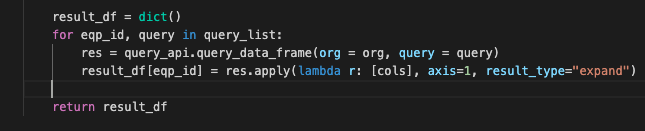
df.apply()를 이용해보자 - 에러 메세지가 달려졌습니다. 일단 처음의 None of ~ are in the column 에러는 해결한 것 같네요. 하지만 에러가 이어지니 계속 해결해봅시다.result_df[eqp_id] = res.apply(lambda r: [cols], axis=1, result_type="expand")
KeyError: "['EQP_DESC' 'FL' 'DVC_DESC' 'DVC_ID' 'ISSEC' 'ISPRI' 'PROJ_NO'\n 'INPUT_STATUS' 'SETPLAYTEMP' 'SETWARMTEMP' 'SETDEHUM' 'SETSTATUS'] not found in axis"라고 한다. 이건 받아온 결과에서 열을 없앨 때 지시한 인덱스들이니, 돌아가서 결과값으로 받아온 result_df의 모양을 살펴보자.

- 데이터프레임 자체가 완전 잘못만들어졌네요. 이건 다음 이슈로 넘어가서 살펴봅시다!
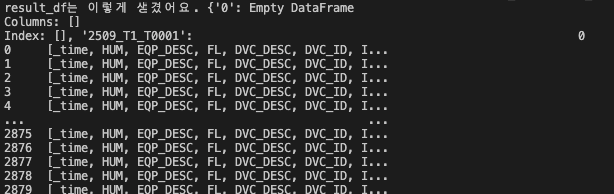
-
디버깅을 해보니 데이터프레임을 잘못 생성하고 있었다.
result_df[eqp_id] = res.apply(lambda r: res[cols], axis=1, result_type="expand")로 변경해서 실행KeyError: "['HUM', 'FL', 'DEW'] not in index"다음과 같은 에러가 발생했다.- 디버깅을 통해 데이터프레임 구조를 파악하고 변경하는게 정석이겠지만은, 이번 이슈는 전달받은 코드가 중간에 두 df가 merge되어 있어 발생하는 이슈라, 기존처럼 두 데이터 프레임을 따로 조작하고 모든 처리가 완료된 후에 merge하는 방향으로 진행해서 해결하기로했다.
- 해당 이슈의 해결 방법은
df["index"] = df["index"].apply(lambda r: [cols], axis=1, result_type="expand")이런 방식으로 해결하는게 가장 효과적으로 보인다.

MLOps, MLE 직무로 일하고 있습니다😍