aws EKS 백업하기
왜 쿠버네티스를 백업해야 할까요 ?
Kubernetes Cluster를위한 백업 및 복구 메커니즘이 필요한 여러 가지 이유가 있습니다.
- 다음과 같은 재해로부터 복구하려면 필요합니다.
- 누군가 실수로 네임 스페이스를 삭제했습니다.
- Kubernetes API 업그레이드에 실패했으며 되돌려 가야합니다.
- 네트워크가 다운되었습니다.
- 클러스터가 복구 불가능한 상태가 됐습니다.
- 최신 응용 프로그램 push는 영구적인 볼륨을 지우고 데이터를 잃어버리거나, 중요한 버그를 발생시켰습니다.
- 드문 경우, 자연 재해가 일어나 클러스터에 액세스 할 수 없습니다.
-
디버깅, 개발, 준비 또는 주요 업그레이드 전에 환경을 복제합니다.(저는 이 경우입니다!)
-
한 환경에서 다른 환경으로 Kubernetes 클러스터 마이그레이션.
그럼 백업을 시작해봅시다!
무엇을 백업해야 하나요?
우리는 Why를 살펴보았고 이제 What에 대한 다음 질문이 나옵니다.
백업에 필요한 두 가지:
-
Kubernetes는 상태를 etcd에 저장하므로 마스터를 복원하려면 etcd 및 관련 인증서를 백업해야 합니다. 이 게시물은 여기에 문서화되어 있으므로 etcd 백업에 대해 이야기하지 않습니다.
-
애플리케이션 데이터, 즉 영구 볼륨(PV, persistent volumes)은 클러스터에서 실행 중인 상태 저장 애플리케이션을 갖게 될 것이기 때문입니다.
1. etcd 백업
etcd 클러스터 백업
모든 Kubernetes 객체는 etcd에 저장됩니다.
etcd 클러스터 데이터를 주기적으로 백업하는 것은
모든 컨트롤 플레인 노드 손실과 같은 재해 시나리오에서 Kubernetes 클러스터를 복구하는 데 중요합니다.
스냅샷 파일에는 모든 Kubernetes 상태와 중요한 정보가 포함되어 있습니다.
민감한 Kubernetes 데이터를 안전하게 유지하려면 스냅샷 파일을 암호화하십시오.
etcd 클러스터 백업은 etcd 내장 스냅샷과 볼륨 스냅샷의 두 가지 방법으로 수행할 수 있습니다.
etcd 내장 스냅샷
- etcdctl utility이 준비되지 않았다면 먼저 설치를 진행합니다! etcd 다운로드
- 리눅스의 경우 아래와 같이 다운로드하면 됩니다.
ETCD_VER=v3.4.17
# choose either URL
GOOGLE_URL=https://storage.googleapis.com/etcd
GITHUB_URL=https://github.com/etcd-io/etcd/releases/download
DOWNLOAD_URL=${GOOGLE_URL}
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test
curl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
/tmp/etcd-download-test/etcd --version
/tmp/etcd-download-test/etcdctl version
sudo mv /tmp/etcd-download-test/etcd /usr/bin
sudo mv /tmp/etcd-download-test/etcdctl /usr/binetcd는 내장 스냅샷을 지원합니다.
etcdctl snapshot save 명령을 사용하여 활성 멤버에서 스냅샷을 가져오거나
현재 etcd 프로세스에서 사용하지 않는 etcd 데이터 디렉토리에서 member/snap/db 파일을 복사하여 스냅샷을 만들 수 있습니다.
스냅샷을 찍어도 멤버의 성능에는 영향을 미치지 않습니다.
다음은 $ENDPOINT에서 제공하는 키스페이스의 스냅샷을 파일 snapshotdb로 가져오는 예입니다.
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb스냅샷을 확인합니다.
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb볼륨 스냅샷
etcd가 Amazon Elastic Block Store와 같이 백업을 지원하는 스토리지 볼륨에서 실행 중인 경우 스토리지 볼륨의 스냅샷을 만들어 etcd 데이터를 백업합니다.
etcdctl 옵션을 사용한 스냅샷
etcdctl에서 제공하는 다양한 옵션을 사용하여 스냅샷을 찍을 수도 있습니다. 예를 들어
ETCDCTL_API=3 etcdctl -h etcdctl에서 사용할 수 있는 다양한 옵션을 나열합니다. 예를 들어 아래와 같이 끝점, 인증서 등을 지정하여 스냅샷을 찍을 수 있습니다.
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>여기서 trusted-ca-file, cert-file및 key-file는 etcd Pod의 설명에서 얻을 수 있습니다.
관련 내용을 잘 정리해 놓은 블로그를 첨부합니다!
2. Velero를 이용한 EKS 백업 및 복구 방법
EKS 복구 프로세스를 두 단계로 나누어 설명하겠습니다.
1. Velero 구성(설치) : 백업 및 복구 프로세스를 위해 수행해야 하는 준비 단계입니다.
2. 백업 및 복구 프로세스 : 데이터를 백업 및 복원하기 위해 따라야 하는 단계입니다.
aws의 velero 플러그인 설치에 대한 정보는 이 링크를 확인해주세요!
Velero 구성
-
Velero 명령을 실행해야 하는 로컬(EKS 관리 시스템)에서 실행되는 Velero CLI 클라이언트 설치
- 아래 링크에서 클라이언트 플랫폼에 대한 최신 varball을 다운로드하세요.
https://github.com/vmware-tanzu/velero/releases/latest (예: velero- v1.3.2-linux-amd64.tar.gz)- 다운로드 받은 압축파일을 풉니다.
- 추출된 Velero 바이너리를 이동시킵니다.
- 설치가 정상적으로 됐는지 확인합니다.
- 필요한 명령어들을 정리하자면 다음과 같습니다.
wget https://github.com/vmware-tanzu/velero/releases/download/v1.7.0/velero-v1.7.0-linux-amd64.tar.gz tar -xvf velero-v1.7.0-linux-amd64.tar.gz -C /tmp sudo mv /tmp/velero-v1.7.0-linux-amd64/velero /usr/bin velero version --client-only
-
클러스터 백업 파일을 저장하기 위한 S3 버킷 생성
- 이 버킷은 백업 중에 복사된 Kubernetes tarball 파일을 저장합니다.
-
IAM 사용자 생성 및 동일한 IAM 사용자에 대한 권한 설정
- IAM User 생성. 예) velero-prod
- 사용자(velero-prod)에 대한 액세서 키 세스틀 생성하고 백업을 실행하기 위해 버킷 및 EKS 클러스터에 액세스할 수 있도록 사용자 velero-pord 아래에 언급된 정책을 연결합니다.
- 사용자 자격 증명은 EKS 클러스터에 Velero를 설치하는 동안 사용됩니다!
-
저는 백업용 S3를 생성하고, IAM은 기존의 root를 사용했습니다. 아래의 설치 과정을 진행하기 위해선 S3의 정책을 변경해야하고, velero-credentials 파일을 로컬 스토리지에 생성해야 합니다.
- S3 정책 변경은 이 링크를 참고해주세요! 퍼블릭 액세스를 모두 허용하고 정책을 변경한 뒤 다시 거부해주시는게 포인트입니다.
- 자신에게 익숙한 편집기 프로그램(vim 등)을 이용해 ./velero-credentials를 만들어주세요. 형식은 아래와 같습니다. 3번에서 IAM을 새로 생성하신 분은 액세스 키와 비밀 키를 받아두셨겠죠?
[default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>
-
EKS 클러스터(프로덕션 및 DR 클러스터 모두)에 Velero 서버를 설치합니다.
- 프로덕션은 서비스를 진행할 클러스터이고, DR 클러스터는 문제가 생겼을 때 복원을 실행할 클러스터입니다. 저는 추후에 DR 클러스터를 생성해서 진행해보겠습니다.
velero install \ --provider aws \ --plugins velero/velero-plugin-for-aws:v1.3.0 \ --bucket $BUCKET \ --backup-location-config region=$REGION \ --snapshot-location-config region=$REGION \ --secret-file ./velero-credentials -
velero 설치 완료 후
kubectl logs deployment/velero -n velero명령을 통해 상태를 확인할 수 있습니다.
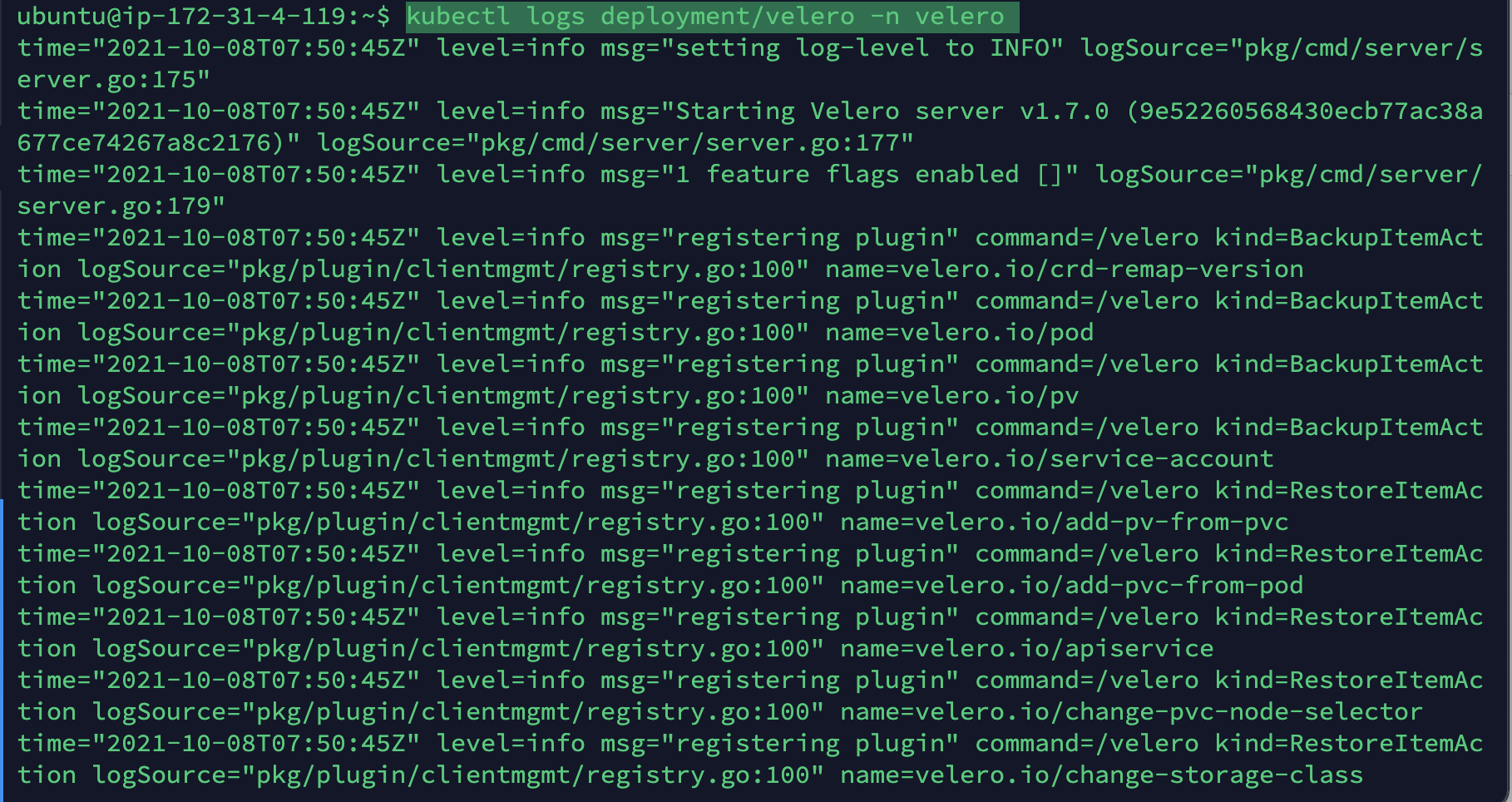
- 설치 중에 아래 메세지를 유심히 살펴봐주세요. 403(포비든) 에러가 발생했을 가능성이 있습니다. 403에러가 발생했다면 s3 버켓의 정책과 하단의 액세스 권한을 다시 확인해주세요! 액세스 키와 비밀 키도 정확히 입력했는지 확인바랍니다. 또한 진행됐던 설치를 제거하고 다시 설치해주세요.
- 제거 :kubectl delete namespace/velero clusterrolebinding/velero
- 설치 중에 아래 메세지를 유심히 살펴봐주세요. 403(포비든) 에러가 발생했을 가능성이 있습니다. 403에러가 발생했다면 s3 버켓의 정책과 하단의 액세스 권한을 다시 확인해주세요! 액세스 키와 비밀 키도 정확히 입력했는지 확인바랍니다. 또한 진행됐던 설치를 제거하고 다시 설치해주세요.
출처 :
https://blog.kubernauts.io/backup-and-restore-of-kubernetes-applications-using-heptios-velero-with-restic-and-rook-ceph-as-2e8df15b1487
https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#backing-up-an-etcd-cluster
https://blogs.halodoc.io/kubernetes-disaster-recovery-with-velero/
