안녕하세요! 오늘부터는 쿠베플로우에 대해서 이야기해보고자 합니다.
쿠베플로우를 시작하기 전에 알아야 할 두 가지 개념이 있습니다.
바로 ML 워크플로우와 쿠버네티스입니다.
이번 포스팅에서는 그 두 가지에 대해 간단히 알아보고(쿠버네티스는 이전 포스팅들에서 다양하게 다루어봤기 때문에 간단히 진행합니다.)
쿠버플로우에 대한 간단한 소개 및 설치 과정을 진행합니다.
ML 워크플로우와 쿠버네티스에 대한 기본지식이 있으신 분들은 바로 쿠베플로우 포스팅으로 이동하셔도 좋습니다.(추후 포스팅 예정)
ML 워크플로우
ML 워크플로우란
문제 해결을 위한 데이터 분석/가공(정제), 학습과 모델 최적화, 서버에 배포시켜 예측하는 등 이 일련의 과정들을 ML workflow라고 합니다.
ML 워크플로우는 크게 모델 실험 단계(Experiment Phase)와 모델 생산 단계(Production Phase)로 나뉩니다.
모델 실험 단계
모델 실험 단계는 주어진 문제를 해결하기 위해 사용될 모델을 실험하는 단계입니다.
- 현 문제가 ML로 풀 수 있는가? -> 풀 수 있다면 어떤 모델을 사용해야 하는가
- 선택한 모델의 학습에 필요한 데이터를 분석/수집합니다.
- 모델을 작성하기 위해 적합한 ML framework를 선택합니다.(pytorch, keras, nvidia tao 등)
- 최초의 모델 코드를 작성합니다.
- 수집된 데이터를 모델로 실험/학습합니다.
- 최적/최고의 성능을 내는 모델을 만들기 위해 하이퍼파라미터를 튜닝합니다.
이 과정은 최고수준(SOTA, State-Of-The-Art)이 나오기 전까지 반복됩니다.
모델 생산 단계
모델 생산 단계는 실험된 모델을 학습/배포하는 단계입니다.
- 학습시스템에 맞게 실제 데이터를 재가공합니다. 이 과정은 실험 단계 및 예측시에도 동일하게 적용되어야 합니다.(데이터 가공의 자동화)
- 실제 데이터를 가지고 모델을 학습합니다.
- 서버에 모델을 배포합니다.
- 모델의 성능을 모니터하며, 그 결과에 따라 튜닝/재학습 여부를 결정합니다.
모델 실험 단계와 마찬가지로 SOTA를 얻기 위해 계속 반복합니다.
ML 워크플로우 툴
보통 ML 워크플로우 툴들은 파이프라인 툴(Pipeline tool)이란 형태로 구성됩니다.
파이프라인이란 하나의 테스크 결과가 다음 테스크로 이어지는 연결 구조입니다.
이 연결 구조는 각각의 단계가 독립적이며 연결 구조에 따라 병렬적 수행도 가능하기 때문에 효율적인 구성을 만들 수 있습니다.
각각의 워크플로우 단계들은 하나의 테스크로 정의할 수 있습니다.
즉, 각각의 테스크를 순서대로 연결하여 수행하는 것이 하나의 Workflow가 되는 것입니다.
이것은 테스크의 수행결과에 따라 재처리나 분기 등이 가능하다면
수동으로 작업하는 것보다 후러씬 효율적입니다.
이러한 오픈소스로는 Apache의 Airflow가 대표적입니다.
Airflow는 덱(DAG), 트리(Tree), 간트(Gantt), 그래프(Graph) 등 다양한 컴포넌트들을 지원하며
ML 개발자들에게 친숙한 파이썬을 통해 워크플로우를 작성할 수 있게 합니다.
REST API나 쿠버네티스 지원 등 확장성도 좋기 때문에 워크플로우를 구성하기엔 부족함이 없습니다.
또 다른 워크플로우 오픈소스로는 나중에 설명할 쿠베플로우 파이프라인의 전신인 argo workflow가 있습니다.
argoproj라는 프로젝트로 쿠버네티스 위에서 실행되는 오픈소스입니다.
각 테스크가 컨테이너 기반이기 때문에 컨테이너가 가지는 장점과 쿠버네티스 리소스 관리의 장점을 가진 워크플로우 툴입니다.
앞서 소개한 2개의 워크플로우 툴은 ML용으로 개발된 것은 아닙니다.
하지만 ML 워크플로우도 일반적인 워크플로우와 크게 다르지 않기 때문에 부족함이 없습니다.
수동화되어 있는 작업들을 구조화된 테스크로 묶어서 관리할 수 있는 것만으로 충분히 좋은 개선이기 때문입니다.
퍼플릭 클라우드 서비스에서도 AI, 머신러닝에 관련 툴들을 제공하고 있습니다.
AWS의 SageMaker, GCP의 AI Platform, Azure의 Automated ML 등 앞서 설명한 ML 워크플로우 단계들을 사용자 친화적인 UI로 제공해주고 있습니다.
ML 기법에 해당하는 알고리즘들을 데이터에 맞게 제공해주기도 합고,
ML 모델 개발환경도 제공해 주며, 하이퍼파라미터를 튜닝해주기도 하고, 개발된 모델을 자동으로 배포/서빙해주기도 합니다.
완전 관리형 ML 서비스도 제공합니다.
이런 서비스들과 자사들이 구축한 서비스에 접목하여 ML 워크플로우를 완성하기도 합니다.
이는 서비스 비용에 대한 부담이 적은 회사들에게 유용하게 사용됩니다.
텐서플로우나 파이토치, SKLearn 같은 ML 프레임워크에서도 모델 개발에서 배포 단계까지 패키지 레벨에서 제공해주고 있습니다.
텐서플로우는 TensorFlow Extended(TFX)라는 플랫폼을 제공합니다.
데이터 수집부터 서빙모델까지의 파이프라인을 모두 제공합니다.
이런 라이브러리들을 파이프라인으로 구성하기 위해서는 Apache Beam이라는 오픈소스 파이프라인 툴을 사용합니다.
그리고 앞서 설명한 Airflow 같은 툴을 통해 좀 더 쉽게 구성할 수 있습니다.
이렇게 ML Workflow를 구성할 수 있는 다양한 서비스 및 오픈소스가 존재합니다.
비용의 여유가 있고 서비스해야 할 모델이 퍼블릭 클라우스 서비스에서 제공이 되는 경우 퍼블릭 클라우드 서비스를 사용하여 구축 및 운영에 소비되는 자원을 줄이는 것이 맞습니다.
그렇지 못한 경우에는 자체 개발이나 오픈소를 통한 워크플로우를 구성해야 합니다.
오픈 소스로 ML 워크플로우를 구성해야 한다면 고려해야 할 것들이 있습니다.
- 하나의 플랫폼 안에서 모든 작업이 가능한가?
- 설치가 간편한가? 설치에 대한 트러블 슈팅 데이터가 많은가?
- 각각 ML 워크플로우 단계를 수행할 수 있는 SDK나 라이브러리가 있는가?
- 해당 SDK에 대한 러닝 커브(Learning Curve)가 어떤가?
- 해당 오픈 소스의 사용자 커뮤니티 활성도는 어떤가?
- 오픈 소스의 버전이 프로덕션 레벨로 사용할 정도로 성숙한가?
- 오픈 소스가 다양한 ML 프레임워크를 지원하는가? 혹은 현재 사용하고 있는 ML 프레임워크를 지원하는가?
- 리소스 관리/스케줄링을 지원하는가?
- 리소스에 대한 인증/권한(AuthN, AuthZ) 관리를 제공하는가?
- 멀티-테넌시(Multi-tenancy)를 지원하는가?
- 병렬 프로세싱(Parallel Processing)을 지원하는가?
- 모델과 데이터를 저장할 스토리지 서비스에 대한 지원이 다양한가?
- 타 인프라와의 연동이 원활한가?
- 사용자 친화적인 UI를 제공하는가?
- 파이프라인을 구성할 SDK/UI를 제공하는가?
- 하이퍼 파라미터 최적화 라이브러리를 제공하는가?
- 생성된 모델에 대한 버전 관리를 제공하는가?
등 이 외에도 프로젝트마다 특정 조건들이 존재합니다.
리소스 관련 부분들은 워크플로우 툴과는 별개의 영역이라고 할 수 있습니다.
그래서 리소스를 관리/스케줄링(이를 리소스 오케스트레이션이라고 부릅니다)할 수 있는 플랫폼 위에서
나머지 항목들을 충족시킬 수 있는 툴을 사용하는 것이 좋은 접근으로 볼 수 있습니다.
이제 설명할 쿠베플로우는 리소스 오케스트레이션 플랫폼은 쿠버네티스 위에서 실행되는 ML toolkit입니다.
kubeflow
kubeflow란?
공식 소개에 따르면 쿠베플로우의 목표는 ML 워크플로우에 필요한 서비스를 만드는 것이 아닌,
각 영역에서 가장 적합한 오픈 소스 시스템들을 제공하는 것입니다.
다시 말해서 쿠베플로우는 어떤 새로운 서비스가 아닌 기존에 있던 오픈 소스들의 묶음입니다.
그것도 쿠버네티스 생태계에서 사용되는 오픈 소스만을 사용하기 때문에 쿠버네티스만 깔려있다면 쿠베플로우를 사용할 수 있습니다.
(즉, 쿠버네티스를 사용하는 ML 툴킷이라고 정의할 수 있습니다.)
kubeflow components on ML workflow
쿠베플로우는 ML 워크플로우 단계에 필요한 컴포넌트들을 제공합니다.
ML 워크플로우의 모델 실험 단게에서 쿠베플로우는 아래와 같은 컴포넌트들을 지원합니다.
1. Identify problem and collect and analyse data
2. Choose an ML algorihtm and code your model
- PyTorch
- scikit-learn
- TensorFlow
- XGBoost
3. Experiment with data and model training
- Jupyter Notebook
- Fairing
- Pipelines
4. Tune the model hyperparameters
- Katib
모델 제작 단계에서도 아래와 같은 컴포넌트들을 지원합니다.
- Transform data
- Train model
- Chainer
- MPI
- MXNet
- PyTorch
- TFJob
- Serve the model for online/batch prediction
- KFServing
- NVIDIA TensorRT
- PyTorch
- TFServing
- Seldon
- Monitor the model's performance
- Metadata
- TensorBoard
kubeflow UI
쿠베플로우에서 주로 사용되는 컴포넌트들은 각각의 GUI를 가지고 있으며 이를 통합하는 대시보드 UI도 지원합니다.
쿠베네티스의 kubectl처럼 kfctl이라는 CLI도 지원합니다.
kubectl과 마찬가지고 CLI를 통해 쿠베플로우의 컴포넌트들을 관리할 수 있으며, 쿠베플로우의 설치도 kfctl를 통해 진행합니다.
API와 SDK
쿠베플로우의 컴포넌트들은 각 컴포넌트를 관리할 수 있는 API와
컴포넌트내의 오브젝트들을 생성할 수 있는 파이썬 SDK를 제공하여
GUI 뿐만 아니라 다른 애플리케이션에서도 활용할 수 있는 확장성을 제공합니다.
kubeflow 컴포넌트들
쿠베플로우에서 제공되는 컴포넌드들은 공식 홈페이지 기준으로 총 7가지로 나눌 수 있습니다.
- 주피터 노트북
- 쿠버네티스 위에서 주피터 노트북을 사용할 수 있는 주피터 허브를 서비스합니다.
- ML 워크플로우 기준으로 모델 개발을 위한 첫 컴포넌트이며, 여기서 다른 컴포넌트들과 연동할 수 있습니다.
- 메인 대시보드
- 컴포넌트의 통합 포탈
- 하이퍼파라미터 튜닝
- Katib라는 하이퍼파라미터 최적화 오픈소스를 쿠버네티스 위에서 서비스합니다.
- 파이프라인
- 쿠베플로우의 핵심 컴포넌트라고 할 정도로 중요한데, ML 워크플로우를 구성할 파이프라인 툴을 서비스 해줍니다.
- 서빙
- 텐서프로우 서빙, 파이토치 서빙 등 ML 프레임워크의 서빙 모델을 쿠베플로우 위에서 사용할 수 있게 해주는 컴포넌트입니다. KFServing이라는 쿠베플로우의 서빙 모델도 포함됩니다.
- 학습
- TFJob, PyTorch, MXNetc, MPI 등의 ML 모델을 쿠베플로우 위에서 사용할 수 해주는 컴포넌트입니다.
- 그 외
- 아직 알파 머전인 각 컴포넌트들의 메타정보를 저장하고 관리하는 메타데이터
- 파이프라인에서 사용할 수 있는 Nuclio라는 서버리스 프레임워크 등이 있습니다.
kubeflow 버전 정책
쿠베플로우는 오픈 소스 프로젝트이며 각각의 컴포넌트 별로 버전이 관리됩니다.
각 애플리케이션의 버전 Status는 Stable/Beta/Alpha 버전으로 나뉘고, 각각의 버전 시리얼을 가지고 있습니다.
kubernetes
본격적으로 쿠베플로우에 들어가기 전에, 이전 포스팅들에서 배운 쿠버네티스의 용어에 대해서
다시 기억을 되살리는 차원에서 짚고 넘어가봅시다.
이미 코드를 분석하며 실습을 진행했기 때문에 코드 분석과 관련된 내용은 제외하겠습니다.
이전 포스팅과 중복되는 내용이 많아 생략된 부분이 아주 많습니다.
쿠버네티스에 대한 자세한 내용이 필요하신 분은 이전 포스팅들을 참고해주시면 감사하겠습니다.
컨테이너 개발 시대
과거 물리 서버에서 애플리케이션을 배포하는 과정에서 발생하는 비효율적인 리소스 사용을 극복하기 위해 가상화(VM) 기술이 생겼습니다.
이것은 단일 물리서버 윌에 가상의 운영체제(OS)들을 실행하여 애플리케이션을 격리시킴으로 리소스를 좀 더 효율적으로 사용할 수 있게 합니다.
하지만 호스트 운영체제 위에 또 다른 운영체제를 실행하기 때문에 실행 비용에 대한 부담이 컸습니다.
컨테이너는 실행 비용을 cgroup, namespace 등의 커널 기능으로 해결합니다.
운영체제는 공유하되 리소스만 격리하고 디스크의 변경사항을 레이어 형태로 저장하는 것입니다.
그러므로 컨테이너는 운영체제를 품지 않아도 되기 때문에 훨씬 가벼워 집니다.
경량화된 컨테이너는 인프라에 대한 의존성을 끊을 수 있게 하여 좀더 어플리케이션에 집중할 수 있게 만들어 줍니다.
그리고 개발, 테스팅, 운영환경의 일치가 가능하기 때문에 안정성 높은 개발이 가능합니다.
물론 컨테이너만으로 실제 운영환경까지 구성하기는 무리가 있어 컨테이너를 효율적으로 관리할 수 있는 컨테이너 오케스트레이션 시스템들이 개발되기 시작했습니다.(쿠버네티스)
쿠버네티스란
쿠버네티스는 선장(관리자), 항해사(사용자)의 지시에 따라 수 많은 컨테이너를 실은 배(애플리케이션을 실행하는 클러스터 노드)를 목적지까지 잘 운전(배포/운영)하는 일을 하는 것입니다.
그것 뿐만 아니라 서비스 디스커버리, 로드 밸런싱, 롤아웃, 롤백, 셀프힐링 등 운영환경에 필요한 기능들을 제공해줍니다.
쿠버네티스 구조
쿠버네티스는 클러스터 형태로 구성돼 있으며, 클러스터는 컨테이너를 실행하는 노드의 집합입니다.
클러스터는 최소 1개의 워커 노드와 최소 1개의 마스터 노드로 구성돼 이습니다.
마스터 노드는 워커 노드 및 클러스터내의 컴포넌트들을 관리하며, kube-api-server, etcd, kube-scheduler, kube-controller-manager 등을 가지고 있습니다.
각각의 컴포넌트들은 어플리케이션 실행단위인 파드를 관리합니다.
워커 노드는 파드를 호스트합니다. kubelet, kube-proxy 등을 가지고 있으며 동작중인 파드를 유지하는 일들을 합니다.
오브젝트와 컨트롤러
쿠버네티스 오브젝트들은 대표적으로 파드, 볼륨, 서비스, 네임스페이스 등이 있으며,
파드 상태 관리 및 부가 기능 및 편의 기능을 제공하는 컨트롤러인 데몬셋, 스테이트풀셋, 잡 등이 있습니다.
파드는 쿠버네티스의 기본 실행/배포 단위입니다.
노드에서 실행되는 프로세스라고 볼 수 있습니다.
최소 하나 이상의 어플리케이션 컨테이너로 구성되어 있으며, 저장소 리소스(Volumes), 특정 네트워크 IP, 실행을 위한 옵션 등을 포함하고 있습니다.
파드 안의 컨테이너들은 파드의 리소스를 공유합니다.
그리고 컨테이너 각자의 포트를 통해 통신을 할 수 있습니다.
컨테이너 런타임으로는 도커가 주로 사용됩니다.
파드는 여러 단계를 가지는 라이프 사이클을 가지고 있으며, 각 노드마다 실행되고 있는 kubelet에 의해 관리됩니다.
파드 단독으로 실행되는 경우는 드물며 운영/배포 의도에 맞게 파드의 상태를 관리하는 컨트롤러와 함꼐 실행됩니다.
도커의 볼륨과 비슷한 컨셉의 볼륨(Volume)은 파드가 실행될 떄 사용되는 스토리지를 말하는데
각 컨테이너들의 외장디스크라고 생각해도 무방합니다.
컨테이너는 Stateless 상태로 실행됩니다.
Stateless 상태란 컨테이너가 내려가거나 비정상적인 종료시 재실행될 경우 이전의 상태를 유지하지 않는다는 의미입니다.
즉, 이전의 데이터도 유지하지 않습니다.
그렇기 떄문에 데이터를 보존해야 할 경우 볼륨을 생성하여 파드에 마운트하여 사용합니다. 물론 파드가 사라지더라도 볼륨은 존재합니다.
쿠버네티스의 볼륨은 다양한 타입을 지원합니다.
NFS, iSCI 같은 스토리지 형태도 지원하며 Cephfs, StorageOS, Glusterfs 뿐만 아니라
Azure, S3, 구글 스토리지 등 퍼블릭 클라우드의 스토리지도 사용 가능합니다.
물론 호스트의 디스크도 사용 가능합니다.
불륨은 크게 PV와 PVC로 나윕니다.
PV는 볼륨 자체를 의미하며 PVC는 사용자가 요청하는 볼륨입니다.
PV는 직접적으로 컨테이너와 연결되지 않습니다.
PVC 조건에 맞는 PV가 존재하면 PVC는 조건에 맞게 특정 PV에 그 영역을 연결합니다.(바인딩)
그리고 피드는 해당 PVCD를 볼륨으로 인식하여 사용합니다.
PV를 만드는 것을 프로비저닝(Provisioning)이라고 하는데 정작(static) 방법과 동적(dynamic) 방법으로 나뉩니다.
전자는 PV를 먼저 말들어 놓는 방법이고 후자는 요청이 올 때 자동으로 만드는 방법입니다.
쿼터 형태의 관리가 필요하다고 한다면 정적 방법이 적합합니다.
전체 물리 용량을 사용하는 것이 아닌 정한 용량대로 PV를 만들어서
사용자는 그 PV 용량이 자신의 사용가능한 용량이 되기 때문입니다.
만약 사용자가 요청한 PVC의 조건이 현재 PV들의 조건이 맞지 않는다면
PVC는 적합한 PV가 나올 때까지 대기상태(pending)가 됩니다.
그러다가 적합한 PV를 찾으면 바로 바인딩 됩니다.
예를 들어 관리자가 100Gi를 PV로 잡았을 때 사용자가 100Gi 가 넘는 PVC를 요청한다면 바인딩되지 않고 대기상태가 됩니다.
1Gi를 요청할 경우에도 100Gi PV가 바인딩 됩니다.
단 PV와 PVC는 1:1 매핑이기 때문에 다른 사용자의 PVC는 다른 PV가 없다면 대기 상태로 남습니다.
동적 방법은 물리적 자원 한도 내에서 사용자의 요청 조건에 맞게 자동으로 PV를 만들어 주는 것으로,
다양한 볼륨 플러그인을 통해 동적 생성이 가능합니다.
해당 플러그인들은 스토리지클래스(StorageClass)라는 쿠버네티스 리소스를 통해 PV를 생성하게 되느넫,
PVC 템플릿에서 storageClassName 항목에 StorageClass명을 넣기만 하면 됩니다.
컨트롤러는 파드를 관리합니다.
레플리카셋, 디플로이먼트, 데몬셋, 스테이트풀셋, 잡 등이 있으며 어플리케이션의 성격에 따라 파드가 원하는 상태로 유지하는 일을 합니다.
또한 안정적이고 탄력적 운영에 필요한 스케일링, 롤아웃, 롤백, 롤링 업데이트 등의 일도 합니다.
레플리카셋은 지정된 수의 파드가 항상 실행되도록 유지하는 컨트롤러입니다.
커스텀 배포가 필요하지 않은 경우에는 직접 사용하기 보다는 상위 개념인 디플로이먼트를 사용할 것을 권장합니다.
디플로이먼트는 가장 기본적인 컨트롤러이며, Stateless 어플리케이션을 배포할 때 사용합니다.
디플로이먼트를 생성하면 레플리카의 수대로 파드가 생성되며 이것을 관리할 레플리카셋도 생성됩니다.
파드 수 유지 말고도 롤백, 스케일링, 롤릴 업데이트 등 다양한 배포 전략을 지원합니다.
데몬셋은 말 그대로 데몬 프로세스로 띄워야 할 앱이 있을 경우에 사용합니다.
노드에 단 하나의 파드를 실행하며 노드가 죽으면 따라서 사라집니다.
그래서 로그 수집기나 모니터링 관련 프로세스가 필요할 경우에 사용합니다.
스테이트풀셋은 상태를 가지고 파드들을 관리하는 컨트롤러입니다.
파드는 순서대로 실행되며 삭제는 역순으로 진행됩니다. 순서없이(병렬) 실행도 가능합니다.
각각의 파드는 다른 컨트롤러와 다르게 파드 이름 뒤에 순서를 나타내는 n의 숫자가 붙습니다.
잡은 하나 이상의 파드가 요청된 작업을 실행한 후 정상적으로 종료(파드의 Status가 Succeed일 경우)하였느닞 관리하는 컨트롤러입니다.
즉, 한 번만 실행하는 작업들에 적합한 컨트롤러입니다.
예를 들어 도커이미지를 만든다던지, 머신러닝 학습을 수행한다던지 말입니다.
만약 요청된 작업이 실패한다던가, 혹슨 하드웨어 장래 등으로 정상적인 종료가 되지 않은다면,
설정된 값(backof-fLimit:기본값은 6)에 의해 정상적인 종료가 될 떄까지 파드를 실행시킵니다.
잡은 병렬로도 실행 가능하며 완료갯수도 정할 수 잇습니다.
잡을 주기적으로 실행할 수 있는 크론잡(CronJob) 컨트롤러도 있습니다.
유닉스의 cron과 같은 형식을 사용하며 실행은 잡과 동일하게 행동합니다.
서비스는 생성한 파드를 위부에서 접근할 수 있게 해주는 오브젝트입니다.
파드의 엔드포인트를 제공하며, 로드밸런싱과 정의된 IP를 묶어 서비스로 제공합니다.
컨트롤러에 의해 생성된 파드는 동적으로 생성되기 때문에 서비스는 파드에 정의된 레이블로 서비스할 파드를 결정합니다.
이런 느슨한 결합으로 인해 파드가 어디에서 실행되든 사용자는 서비스 정보만 확인하면 됩니다.
서비스는 크게 4가지 타입으로 나뉩니다.
- ClusterIP : 기본 탕비이며 클러스터 내부에서만 접근 가능합니다.
- NodePort : 모든 노드에 지정된 포트를 할당합니다. 어떤 노드든 지정한 포트를 통해서 파드에 접근이 가능합니다. 클러스터 외부/내부 다 접근이 가능합니다.
- LoadBalancer : 쿠버네티스를 지원하는 로드밸런서 장비에서 사용합니다. 정의된 로드밸런서 아이피(External IP)를 통해 외부에서 접근이 가능합니다.
- ExternalName : 앞서 3개 타입괃 ㅏ르게 클러스터 내부에서 외부로 나갈 때 사용됩니다. 외부로 접근할 때 사용하기 때문에 레이블 셀렉터가 필요 없습니다.
네임스페이스는 논리적으로 분리된 작업 그룹이라고 보면 됩니다.
작업 그룹은 쿠버네티스 오브젝트들을 가지고 있습니다.
즉, 오브젝트들의 그룹이라고 보면 됩니다.
권한설정을 통해 격리, 공유가 가능하며, 사용자 분리를 네임스페이스 분리로 사용하곤 합니다.
(현재 kubeflow의 다중 사용자 지원도 네임스페이스 기반입니다.)
쿼터 설정도 가능하여 특정 네임스페이스에 쿼터를 적용할 수 잇습니다.
쿠버네티스를 설치하게 되면 쿠버네티스 운영을 위한 네임스페이스들을 생성하게 되는데 아래와 같습니다.
- default : 기본 네임스페이스입니다. 사용자가 명령을 실행할 때 특정 네임스페이스를 지정하지 않는다면 여기서 실행됩니다.
- kube-system : 쿠버네티스 관리용 파드, 설정이 있는 네임스페이스입니다. etcd, api-server, proxy, coredns, 네트워크 플러그인, CPU 플러그인 등이 여기에 있습니다.
- kube-public : 쿠버네티스 클러스터 내의 모든 사용자(미인증 사용자 포함)가 접근할 수 있는 네임스페이스입니다. 만약 전체적으로 공유해야 할 서비스나 파드 같은 오브젝트가 있다면 여기에 생성하면 됩니다.
- kube-node-lease : 1.13 이후로 추가된 네임스페이스이며 노드의 임대 오브젝트들을 관리합니다.
물론 쿠베플로우를 설치하게 되면 kubeflow라는 이름으로 네임스페이스가 생성되며 거기서 각종 파드, 서비스 드으이 오브젝트들이 설치가 됩니다.
네임스페이스에 속하지 않는 오브젝트들도 있습니다.
대표적으로 Node, PersistentVolume, StorageClass, ClusterRole, ClusterRoleBinding이 있습니다.
오브젝트 템플릿
쿠버네티스에서 사용자가 오브젝트를 다루는 방법에는 2가지가 있습니다.
kube-api-server에서 API 리퀘스트로 요청하는 방법과
kubectl이라는 커맨드라인 툴을 이용하는 방법입니다.
kube-api-server를 이용하는 방법은 JSON 형태의 리퀘스트 바디를 작성하여 마스터 노드의 6443 port로 API 리퀘스트를 요청합니다.
이것은 별도의 클라이언트를 구성하지 않는다면 관리가 불편합니다.
그래서 대부분의 사용자들은 쿠버네티스에서 정의한 템플릿으로 야믈 타입의 파일을 작성한 후 kubectl을 이용하여 요청합니다.
kubectl은 이 YAML 파일을 JSON 형태로 변환하여 kube-api-server에 API request를 합니다.
야믈은 모든 데이터를 스칼라, 리스트, 맵의 조합으로 구성할 수 있게 설계되었기 때문에 쿠버네티스에서 사용하는 오브젝트들을 표현하기에 부족함이 없습니다.
쿠버네테스 오브젝트를 관리하기 위한 야믈 파일은 크게 4개의 필드로 구성되며 거의 모든 오브젝트들이 이 4개의 필드를 공통으로 포함합니다.
- apiVersion, Kind(오브젝트 종류), metadata(이름이나 레이블 등의 오브젝트 메타정보), spec(파드의 컨테이너 생성정보)
각각의 오브젝트 템플릿들이 사용하는 필드들을 확인하려면kubectl explain <오브젝트 타입명>을 실행하면 됩니다.
레이블과 셀렉터, 어노테이션
레이블과 어노테이션은 오브젝트 템플릿 내의 메타데이터에서 key=value 형식으로 정의됩니다.
같은 형식으로 정의되지만 레이블은 특정 오브젝트를 선택하기 위한 인식표같은 것이고,
어노테이션은 오브젝트의 주석 같은 것입니다.
특정 레이블을 찾는 역할을 하는 것은 셀렉터라는 필드입니다.
셀럭터는 spec 필드의 하위 필드이며 셀렉터 하위필드에서 특정 레이블 값을 설정합니다.
인그레스
인그레스는 클러스터 외부에서 들어오는 요청을 처리하는 규칙들을 정의한 오브젝트입니다.
외부의 요청을 처리하는점에 있어서 서비스와 같은 일을 하지만,
서비스는 L4 레이어, 인그레스는 L7 레이어를 지원한다는 점에서 큰 차이가 이습니다.
L4 레이어는 호스트명 라우팅, URL Path 라우팅 등이 불가하기 때문에
L7 레이어인 인그레스를 서비스의 앞단에 두고 사용하는 것이 최근 추세입니다.
그 외에도 SSL/TLS 엔드포인트, 도메인 기반 가상 호스팅 등을 지원합니다.
다른 포트들은 노출하지 않으며 HTTP/HTTPS 경로만 노출합니다.
만약 그 외의 서비스를 외부로 노출하려면 서비스 타입(Service.Type)을 NodePort나 LoadBalancer로 설정해야 합니다.
인그레스는 규칙 명세가 모인 오브젝트이기 떄문에, 단일로는 실행할 수 없으며, 실행하는 인그레스 컨트롤러가 필요합니다.
Envoy, Ha-proxy 등 다양한 오픈소스가 지원을 하고 있으며,
쿠버네티스에서 공식적으로 제공하는 것은 gce용 ingress-gce와 nginx ingress controller입니다.
일반적으로 nginx ingress controller를 많이 사용합니다.
쿠베플로우도 대시보드 및 다양한 컴포넌트들에 대한 요청처리를 위해 인그레스가 사용되며
Istio라는 서비스 메쉬(ServiceMesh) 어플리케이션을 통해 인그레스를 지원합니다.
컨피그맵
컨피그맵은 환경설정을 저장하는 오브젝트입니다.
개발-테스트-운영 환경을 동일하게 유지하는 것은 해당 컨테이너가 얼마나 환경에 독립적인가에 달렸습니다.
그러기 위해서 컨테이너 내의 어플리케이션에 사용하는 환경변수를 분리하여 별도로 관리해야 합니다.
그럴 때 사용하는 것이 컨피그맵입니다.
시크릿
컨피그맵은 환경변수 값을 저장하는 오브젝트입니다.
하지만 애플리케이션에서 사용하는 환경변수 갑은 DB 비밀번호, 사용자 비밀번호, OAuth TOken같은 정보도 포함될 수 잇습니다.
이런 정보는 노출되어서는 안되기 때문에 쿠버네티스에서는 시크릿이라는 별도의 오브젝트를 통해 관리합니다.
시크릿은 쿠버네티스 API에 접근시 서비스 어카운트가 사용하는 내장 시크릿과
어플리케이션이 사용하는(사용자가 만든) 사용자 저으이 시크릿으로 나누어집니다.
내장 시크릿은 서비스 어카운트가 생성될 떄 만들어지며 kube-api-server에서 사용할 수 있는 API에 접근 가능합니다.
사용자 정의 시크릿은 명령형 명령어를 통해 생성 가능하며, 지정된 템플릿을 통해서도 생성가능합니다.
명령형 명령어로 시크릿을 생성하면 각 필드의 값은 base64의 값으로 저장됩니다.
하지만 템플릿으로 생설할 경우엔 각 필드의 값을 base64로 인코딩 해서 넣어주어야 합니다.
시크릿의 구조는 apiVersion, kind, metadata, type, data로 되어 있습니다.
type은 시크릿의 종류를 정의하는데 쿠버네티스는 이하 크게 4가지 타입의 시크릿을 지원합니다.
- Opaque : key-value 형태의 기본 값으로 정의합니다.
- kubernetes.io/dockerconfigjson : 로그인이 필요한 도커 레지스트리의 로그인 정보입니다.(~/.docker/config.json) 파드가 컨테이너의 이미지를 pilling 해올 때 사용합니다.
- kubernetes.io/tls : TLS 인증정보를 저장합니다.
- kubernetes.io/service-account-token : 쿠버네티스 인증 토큰을 저장합니다.
인증과 권한
쿠버네티스의 인증은 kube-api-server를 사용할 수 있는가로 정의됩니다.
다양한 방법들이 존재하지만 주로 쿠버네티스에서 제공하는 계정 체계를 이용하는 것과 TLS를 이용하는 것으로 나누어 집니다.
대부분 커맨드라인툴을 이용해서 쿠버네티스의 리소르를 사용하기 때문에 실제 인증 정보들은 사용자 홈 디렉터리에 있는 ~/.kube/config에 설정됩니다.
쿠버네티스의 계정 체계는 사용자 어카운트(User)와 서비스 어카운트(Service-Account)로 관리됩니다.
사용자 어카운트는 사용자 아이디의 개념입니다.
쿠버네티스는 사용자 정보를 관리하지 않으며 이것을 인증하는 시스템도 없기 때문에
사용자 어카운트는 외부 시스템을 통해 사용자 인증을 해야합니다.(파일을 통해서도 관리 가능)
그래서 사용자 어카운트는 쿠버네티스의 리소스로 관리되지 않습니다.
서비스 어카운트는 특정 네임스페이스의 리소스가 클러스터내의 리소스를 사용할 때,
kube-api-server에 인증을 받기 위해 사용되는 오브젝트 입니다.
서비스 아카운트가 생성될 때 시크릿도 같이 생성됩니다..
아래 사진은 쿠버네티스 디폴트 서비스 어카운트의 템플릿 예제입니다.
이 서비스 어카운트에 연결된 시크릿의 내용을 확인해보면 인증서와 토큰을 확인할 수 있습니다.
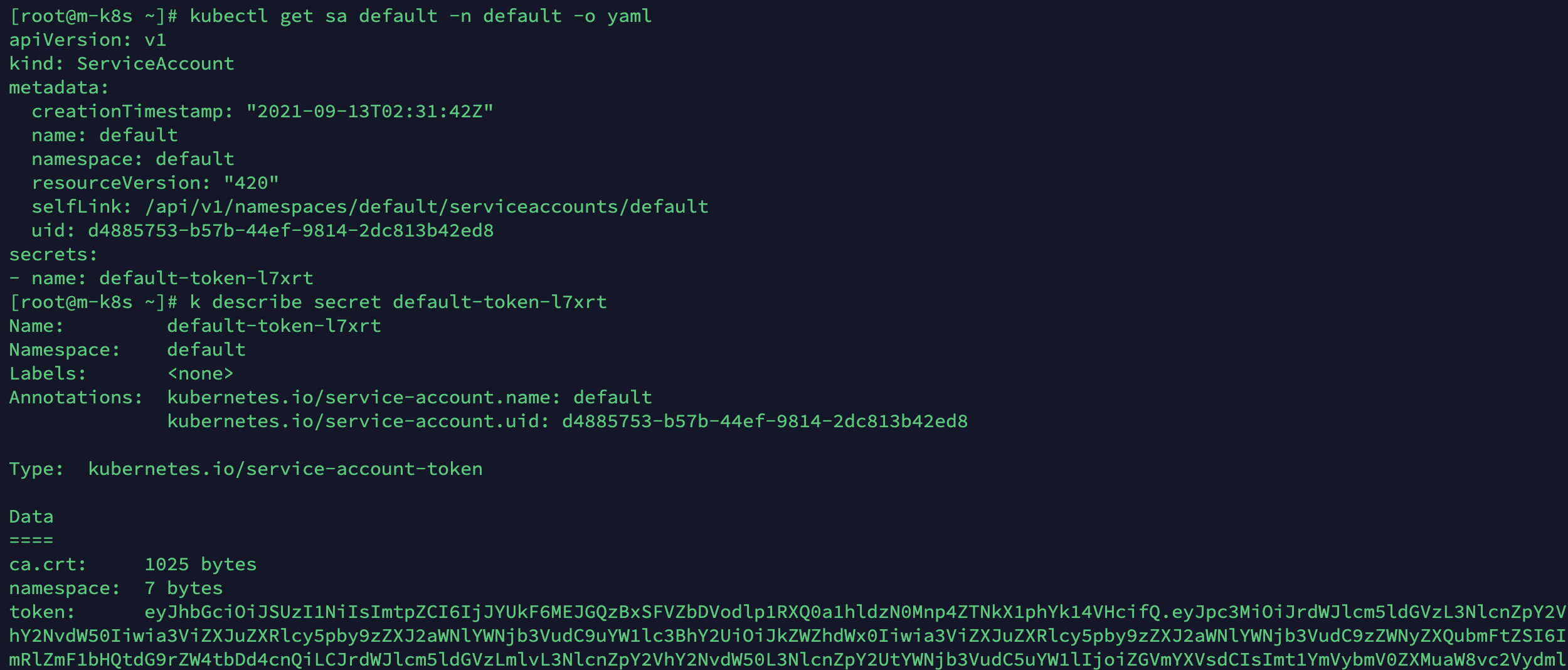
이 토큰 정보와 서비스 아카운트 이름을 ~/.kube/config에 설정하면 이 사용자는 default라는 서비스 어카운트의 권한을 가지게 됩니다.
쿠버네티스를 설치하고 나서 CLI를 통해 별다른 인증 없이 사용할 수 있었던 이유는
kubectl 설정에 TSL 인증정보가 포함되었기 떄문입니다.
이는 쿠버네티스트 설치 후에 나오는 완료 메세지에서 관리자의 설정을 ~/.kube/config로 복사하도록 지시되어 있기 때문에 가능합니다.
이렇게 복사된 인증정보는 관리자 권한이므로 어떠한 작업에도 인증제한이 없습니다.
이렇게 사용자 인증을 거치고 난 다음 API나 리소스를 사용할 수 있는 권한(Authorization)이 있는지 확인합니다.
쿠버네티스는 다양한 방법으로 권한 관리를 제공하지만 RBAC(Role-Based Access Controll, 알백)이라는 방법이 주로 쓰입니다.
알백은 롤(Role) 기반 권한 관리를 뜻하는데 API나 리소스를 사용할 수 있는 범위를 롤로 정의하여,
그 롤을 사용자에게 부여하는 방법입니다.
롤은 일반 롤과 전역 롤이라고 할 수 있는 클러스터 롤로 나누어집니다.
일반 롤은 해당 롤을 가지고 있는 네임스페이스에 한정됩니다.
물론 네임 스페이스에 종속적이지 않은 API나 리소스도 사용할 수 있습니다.
롤의 매니패스트 파일은 spec대신 rules 필드가 사용합니다.
rules 하위 필드는 아래와 같이 구성됩니다.
- apiGroups : API 그룹들을 설정합니다. ""일 경우 core API(/api/v1) 그룹입니다.
- resources : 자원을 설정합니다. 쿠버네티스 오브젝트라고 보시면 됩니다.
- verbs : 어떤 동작을 할 것인지 설정합니다. Create, Get, List, Updata, Patch, Delete 등이 있습니다.
아래는 쿠버네티스의 클러스터롤 목록의 일부입니다.
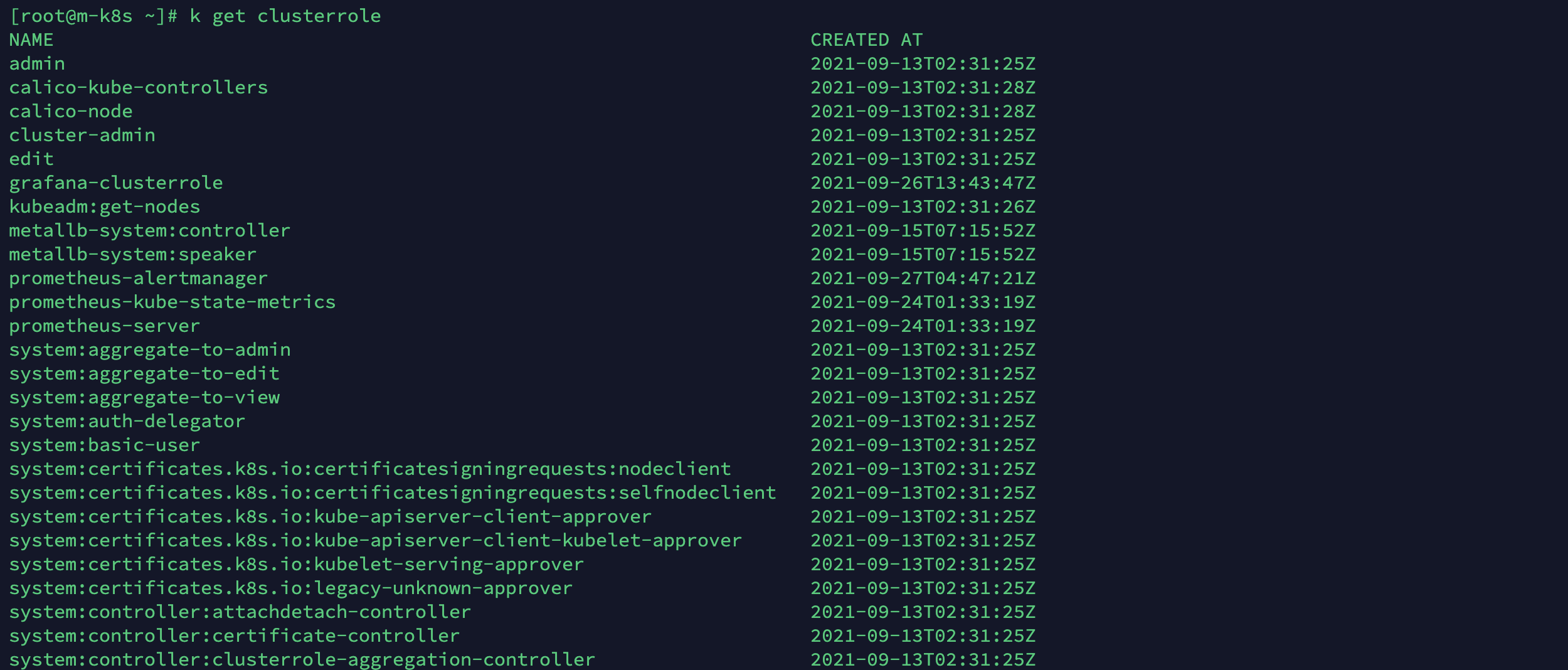
설정한 롤을 사용자와 연결하는 것을 롤 바인딩(RoleBinding) 오브젝트가 담당합니다.
클러스터롤은 클러스터롤 바인딩(ClusterRoleBinding) 오브젝트가 담당합니다.
아래 코드는 moey920@musma.net이란 유저에게 바인딩된 롤을 보여주는 템플릿 예제의 일부입니다.
기본 템플릿에서 spec대신 roleRef와 subjects가 추가되어 잇습니다.
2개의 필드는 이름만 틀리고 하위 필드는 동일합니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
annotataion:
role: admin
user: moey920@musma.net
creationTimestamp: "2021-09-30T16:16:05Z"
name: namespaceAdmin
namespace: moey920
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kubeflow-admin
subjects:
apiGroup: rbac.authorization.k8s.io
kind: User
name: moey920@musma.net- roleRef : 바인딩 시킬 롤에 대한 정보를 정의합니다.
- subjects : 어떤 계정 유형을 바인딩할 것인지 지정합니다. ServiceAccount, User, Group# 중 선택 가능합니다.
여기서는 User라는 계정 유형에 kubeflow-admin이라는 ClusterRole이 바인딩 되어 있는 것을 알 수 있습니다.
쿠베플로우 섹션에서 자세히 다루겠지만 쿠베플로우의 사용자 계정 인증은 온프레미스 환경에서는 Dex라는 OpenID 인증 방식 시스템으로 사용자 계정관리를 합니다.
사용자가 등록이 되면 Dex는 사용자 명과 동일한 네임스페이스를 생성한 후 쿠베플로우의 리소스를 사용할 수있게 쿠베플로우 클러스터롤을 바인딩 합니다.
쿠베플로우 설치
설치 조건
쿠베플로우를 설치하기 위해서는 2가지가 준비되어야 합니다.
- Kubernetes
- Kustomize
앞서 설명했듯이 쿠버네티스 기반의 ML 툴킷이기 때문에 쿠버네티스는 사전 설치되어 있어야 합니다.
물론 퍼블릭 클라우드 서비스에서 제공하는 쿠버네티스 클러스터 서비스를 사용해도 상관 없습니다.(GCP의 GKE나 AWS의 EKS 같은 서비스)
저는 AWS의 EFS(Elastic File System)와 EKS(Elastic Kubernetes Service), 그리고 CDK8s(CDK for Kubernetes)를 연계하여 ML workflow를 구축하는 것을 목표로 공부하고 있습니다.
쿠버네티스 버전에 따라 설치 가능한 쿠베플로우의 버전도 틀립니다.
호환성 부분에서 문제를 발생시키기 떄문에 되도록 권장 버전을 설치하기 바랍니다.
AWS의 EKS 등 퍼블릭 클라우드의 경우 따로 관리되고 있는 버전을 명시하여 패키지 설치와 고급 사용자용 매니페스트 설치를 지원합니다. kubeflow 공식 홈페이지 설치 가이드

저는 로컬 호스트에서 쿠버네티스 1.18버전을 사용하고 있으므로 kubeflow는 아래 사진에 의거하여 1.2버전을 설치해보도록 하겠습니다.(AWS EKS가 아니지만, 정상 동작하는지 한번 봅시다!)

쿠베플로우는 데스크탑이나 서버, 기존의 쿠버네티스 클러스터, 퍼블릭 클라우드 등 다양한 환경에서 설치가 가능합니다.
쿠버네티스 위에서 실행되기 때문에 쿠버네티스의 환경에 따라서도 설치 방법들도 나누어집니다.
온프레미스 환경에서 쿠버네티스를 설치 후 쿠베플로우를 설치하는 방법도 있으며,
Vagrant나 Virtual Box를 통해서 MiniKF라는 쿠베플로우 배포판을 설치할 수도 있고,
Minikube라는 VM으로 구성된 싱글노드 쿠버네티스 환경 위에서도 설치가 가능합니다.
Mircok8s라는 쿠버네티스 배포판에서는 쿠베플로우를 애드온으로 지원하기도 합니다.
쿠버네티스의 설치는 처음 접하는 사용자에겐 난이도가 있기 때문에 쿠베플로우 사용만이 목적이라면
MiniKF, Minikube, Microk8s도 좋은 선택입니다.
Kustomize는 앞선 포스팅에서 살펴봤듯이 쿠버네티스 오브젝트의 배포를 편하게 도와주는 툴입니다.
기존 오브젝트 템플릿을 통해 배포하던 방식은 애플리케이션이 복잡해지면 파일도 많아지고
배포환경에 따른 변경들도 자주 일어나 관리가 어렵습니다.
그래서 좀 더 체계화된 배포 방법들이 필요합니다.
Kustomize나 Helm 등이 이런 문제를 별도의 템플릿 파일들을 통해서 해결해줍니다.
쿠베플로우도 컴포넌트들이 쿠버네티스 오브젝트로 구성되어 있기 때문에 kustomize를 통해서 설치를 진행합니다.
kustomize는 쿠버네티스 1.14 버전부터 쿠버네티스 커맨드라인 툴의 커맨드로 포함되기 시작했습니다.
그래서 1.14버전 이상을 사용중이라면 따로 설치할 필요가 없습니다.
쿠버네티스 설치
쿠버네티스 설치 과정은 생략하겠습니다. 이전 포스팅을 참고해주세요!
이전 포스팅에서 만들어놓았던 VM은 우분투 기반이 아니라 설치에 필요한 apt 명령어 사용이 불가능해서 정상적인 실습을 진행하기 어렵네요.
이전 포스팅 VM 기준(CentOS)으로 설치방법을 안내하니, GCP나 AWS 인스턴스 등으로 진행하시는 분은 아래 부분의 코드는 여기서 링크에서 도커와 엔비디아 도커 인스톨 코드를 확인해주시기 바랍니다.
도커 설치
# Docker 필요 패키지 설치
$ yum -y install yum-utils device-mapper-persistent-data lvm2
# stable 저장소 설정
$ yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# Docker CE 설치
$ yum install -y docker-ce-18.09.9
$ cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
$ mkdir -p /etc/systemd/system/docker.service.d
$ systemctl daemon-reload
$ systemctl restart docker
$ exitVM 인스턴스(환경에 따라 필요한 방법을 선택하시면 되겠습니다), 컨테이너 런타임으로 사용할 도커, 도커의 GPU 리소스 사용을 위한 nvidia-docker를 설치해주세요!
여기까지가 마스터 노드와 워커 노드 공통 설치 영역입니다.
nvidia-docker는 이전 포스팅에서 설치하지 않았기 때문에 설치를 진행하겠습니다!
코드는 여기서 확인가능합니다.
CentOS nvidia-docker2.0 설치는 여기를 확인해주세요!
- yum install -y wget도 진행해야합니다.
저는 Disable old Nouveau driver는 아래 코드로 대체합니다.
wget https://busybox.net/downloads/binaries/1.28.1-defconfig-multiarch/busybox-x86_64
mv busybox-x86_64 busybox
chmod +x busybox
./busybox$ release="ubuntu"$(lsb_release -sr | sed -e "s/\.//g")
$ sudo apt install sudo gnupg
$ sudo apt-key adv --fetch-keys "http://developer.download.nvidia.com/compute/cuda/repos/"$release"/x86_64/7fa2af80.pub"
$ sudo sh -c 'echo "deb http://developer.download.nvidia.com/compute/machine-learning/repos/'$release'/x86_64 /" > /etc/apt/sources.list.d/nvidia-machine-learning.list'
$ sudo apt update
$ apt-cache search nvidia
$ sudo apt-get install -y nvidia-XXX
$ sudo apt-get install -y dkms nvidia-modprobe
$ sudo reboot
$ sudo cat /proc/driver/nvidia/version | nvidia-smi
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update
$ sudo apt-get install -y nvidia-docker2
# daemon.json에 구문을 추가하여 아래와 같이 바꿔주세요.
$ sudo vi /etc/docker/daemon.jeson
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
$ sudo systemctl restart docker
$ sudo docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi마스터 노드일 경우 sudo kubeadmin init --pod-network-cidr=<사용할 IP> 명령으로 쿠버네티스 초기화를 시킵니다.
여기서 쿠버네티스 사용을 위한 어드인 인증 관련 설정을 사용자 홈 디렉터리에 복사하는 과정과
쿠버네티스의 네트워크 정책을 정의하는 부분이 포함됩니다.
아래 명령을 차례대로 따라오면 됩니다.
$ sudo kubeadmin init --pod-network-cidr=<사용할 IP>
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
# enable master node scheduling
$ kubectl taint nodes --all node-role.lubernetes.io/master-
$ kubectl apply -f https://docs.projectcalico.org/v3.20.1/manifests/calico.yaml쿠버네티스를 초기화시킨 노드가 마스터 노드가 되며,
초기화 과정을 마치면 이 노드에 조인 할 수 있는 토큰값을 포함한 kubeadm 명령어가 노출됩니다.
이 명령어를 워커 노드에 그대로 복사하여 실행시키면 워커 노드가 정상적으로 마스터 노드에 조인됩니다.
$ sudo kubeadm join <ip> --token <토큰> --discovery-token-ca-cert-hash <해시값>쿠버네티스 설치가 완료되면 정상적으로 쿠버네티스 클러스터가 설치되었는지 확인해봅니다.
노드의 STATUS가 Ready가 되면 정상적으로 설치된 것입니다.
저는 이전 포스팅에서 미리 설치해두었고, 마스터 노드만 전원을 켜두었기 때문에
전원을 켜놓지 않은 워커 노드가 NotReady인 상태입니다.

이제 쿠버네티스 스토리를 위한 스토리지클래스(StorageClass)를 설치합니다.
쿠베플로우는 동적 프로비저닝을 지원하는 스토리지클래스가 필요합니다.
대부분의 스토리지클래스가 동적 프로비저닝을 지원해주며, 여기서는 로컬 스토리지를 지원하는
local-path-storage와 NFS 스토리지를 지원하는 nfs-client-provisioner를 설치합니다.
물론 nfs-client-provisioner를 설치하기 위해서는 NFS 서버 정보도 필요합니다.
그 전에 확인할 것은 NFS는 버전 4 이상이어야 하며(nfsstat -s)
/etc/exports 폴더 설정에서 no_root_squash 옵션이 포함되어 있어야 합니다.
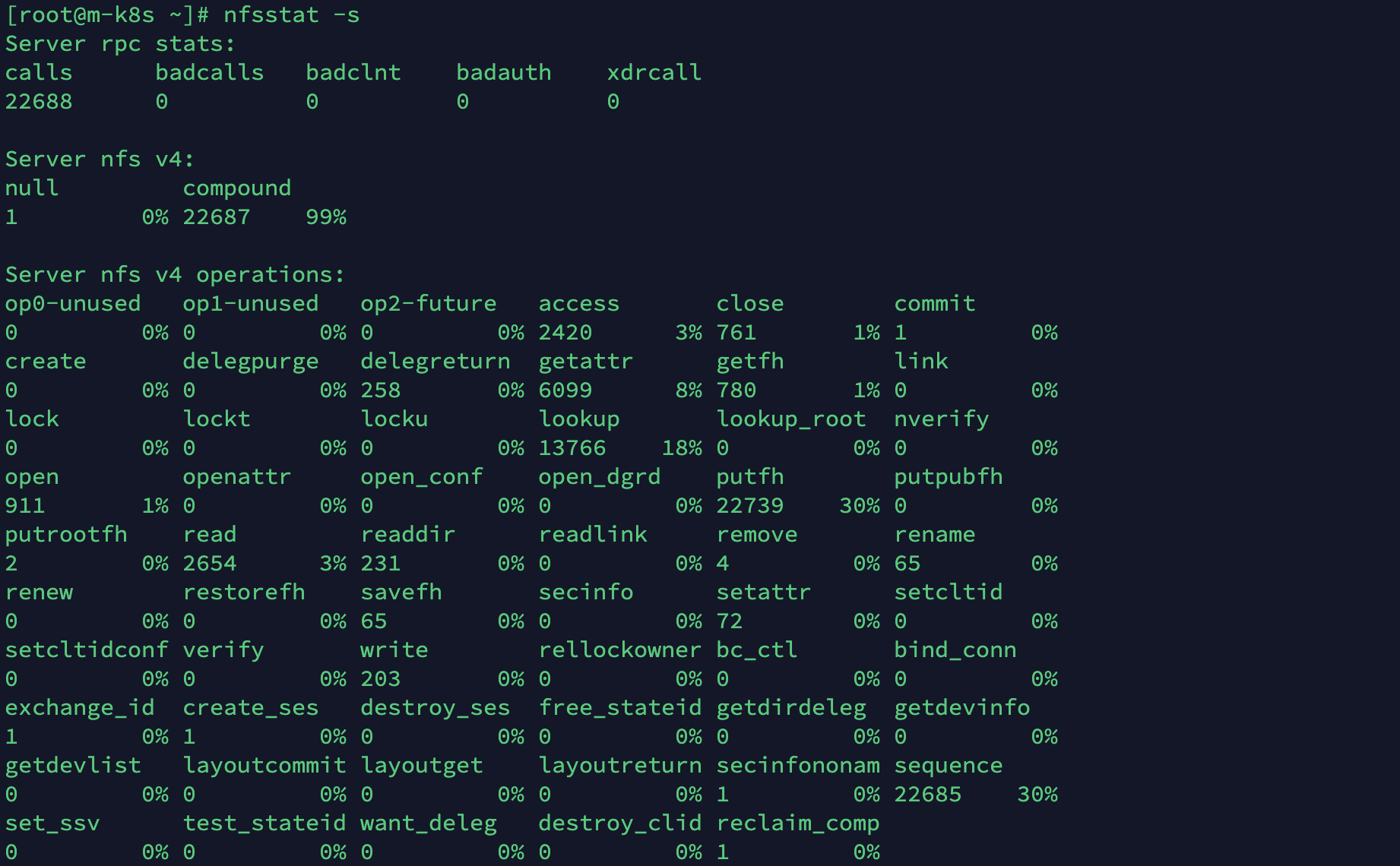

그리고 클러스터 내의 각 노드들은 NFS 서버에 접속할 수 있는 NFS client가 설치되어 있어야 합니다.
확인이 끝났다면 Helm 이라는 쿠버네티스 배포툴을 이용하여 nfs-client-provisioner 패키지를 설치합니다.
$ kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
$ curl https://raw.githubusercontent.com/helm/helm/master/scripts/get > get_helm.sh
$ chmod 700 get_helm.sh
$ ./get_helm.sh
$ kubectl -n kube-system create sa tiller
$ kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller
$ helm init --service-account tiller
$ helm repo update
# to install nfs-client-provisioner
$ helm install --name my-release --set nfs.server=x.x.x.x --set nfs.path=/exported/path stable/nfs-client-provisioner
$ kubectl patch storageclass nfs-client -p '{"metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'


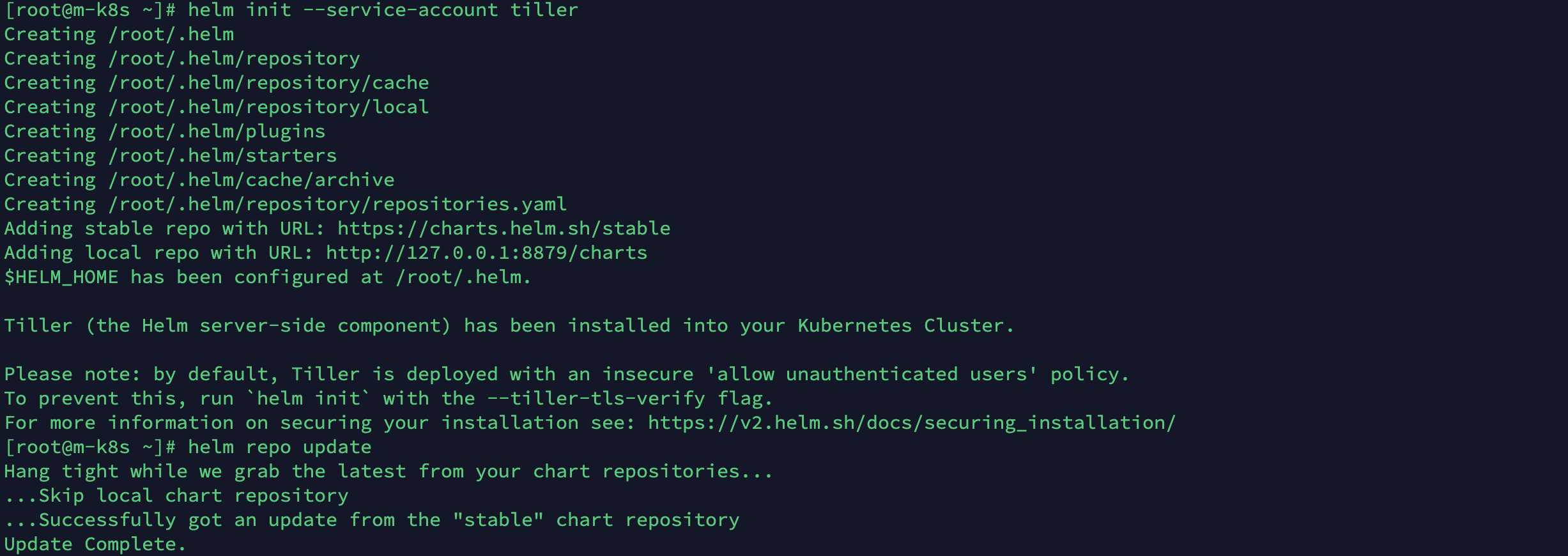
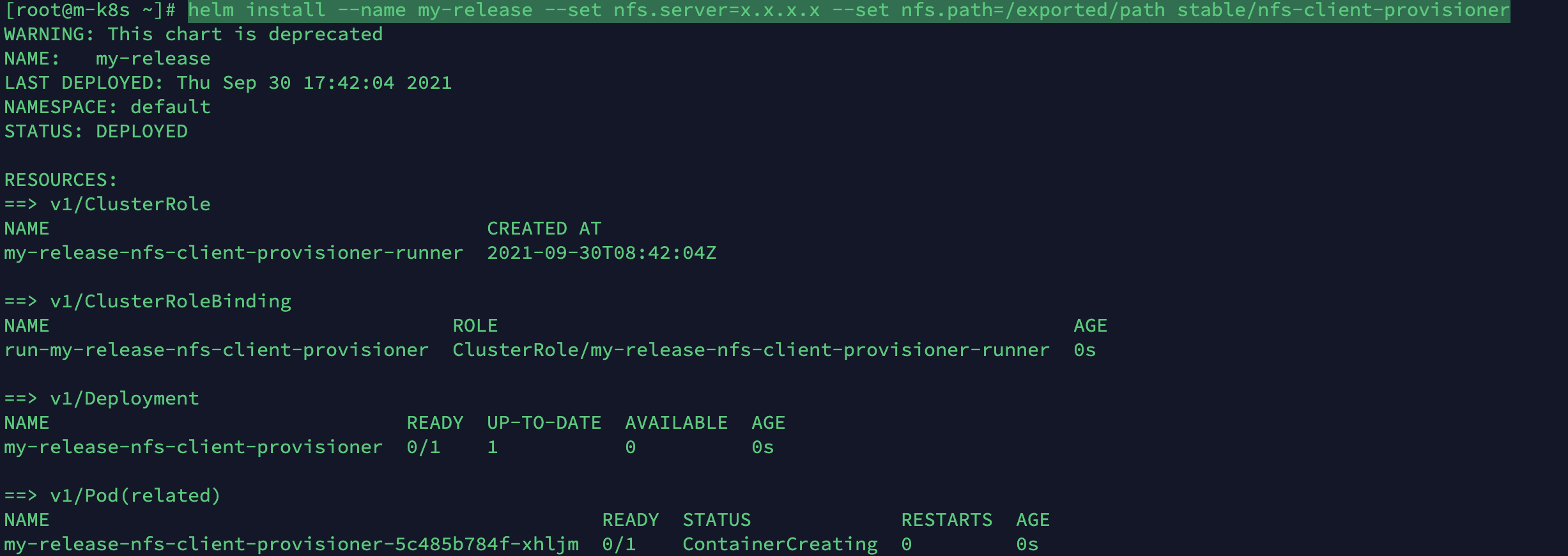

정상적으로 설치가 된다면 kubectl get storageclass 라는 명령으로 설치된 스토리지클래스를 확인할 수 있습니다. nfs-client가 default로 설정되어 있다면 성공입니다!

그 다음은 GPU 리소스를 사용하기 위한 nvidia-gpu-plugin을 설치합니다.
물론 각 노드들마다 nvidia-docker가 설치되어 있어야 정상 작동되며,
도커 데몬 설정 파일에 nvidia가 기본 런타임으로 잡혀 있어야 합니다.
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta4/nvidia-device-plugin.yml
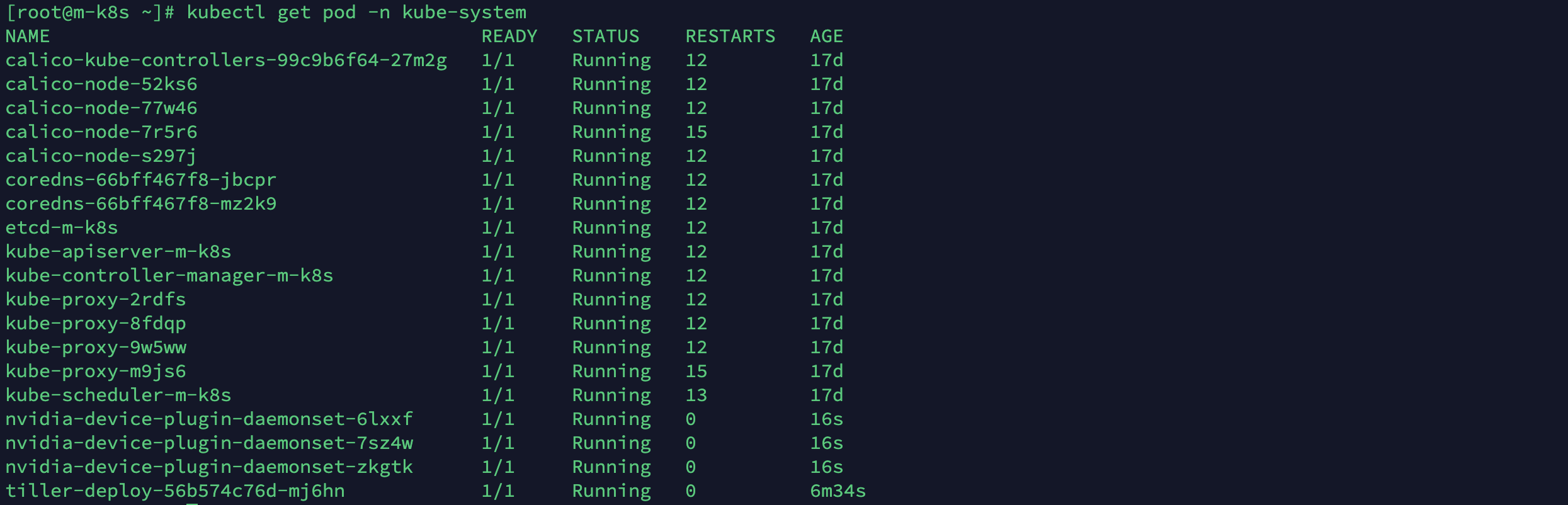
정상적으로 설치가 되었다면 GPU가 설치된 노드갯수 만큼 nvidia-device-plugin 파드가 생성됩니다.
- 이전 포스팅에서 생성한 VM(m-k8s)에 nvidia-docker가 정상적으로 설치되지 않아 kubeflow 설치 관련 사항은 일단 넘어가겠습니다.. 이후 모든 kubeflow 동작과정은 aws EKS에서 진행하니 참고하시길 바랍니다.
프라이빗 도커 레지스트리
앞으로 있을 예제들을 실행시키기 위해서는 도커 이미지를 저장할 프라이빗 도커 레지스트리를 설치해야 합니다.
쿠버네티스가 설치되어 있기 때문에 쿠버네티스 서비스로서 도커 레지스트리 서비스를 올립니다.
kubeflow-registry.default.svc.cluster.local:3000 주소로 생성됩니다.
이 주소는 쿠버네티스 서비스의 도메인 주소이기 때문에 쿠버네티스 내부에서 파드들이 조회를 할 수 있습니다.
먼저 매니페스트 파일을 다운로드 받아옵시다.
curl https://github.com/mojokb/handson-kubeflow/blob/master/registry/kubeflow-registry-deploy.yaml -o kubeflow-registry-deploy.yaml
curl https://github.com/mojokb/handson-kubeflow/blob/master/registry/kubeflow-registry-svc.yaml -o kubeflow-registry-svc.yaml
이제 디플로이먼트와 서비스를 등록합시다!
kubectl apply -f kubeflow-registry-deploy.yaml
kubectl apply -f kubeflow-registry-svc.yaml
하지만 kubeflow-registry.default.svc.cluster.local 이 주소는 쿠버네티스만 아는 주소이기 때문에 호스트에서는 인식이 가능하게 /etc/hosts에 입력을 해주어야 합니다.
in /etc/hosts
예제를 진행하지 않고, 실제로 aws EKS 환경에서 실무를 진행하며 kubeflow 사용법을 포스팅할 것이기 때문에 본 섹션은 넘어가겠습니다.
k9s
쿠버네티스를 사용하기 위해서 kubectl을 사용하지만 커맨드 라인 툴 특성상 로그나 모니터링 등의 편의성이 떨어집니다.
그래서 터미널상에서 이를 편하게 관리할 수 있는 툴을 소개합니다.
앞으로도 쿠버네티스 관련 작업들은 k9s로 진행할 에정입니다.
현재 리눅스, OSX, Window 플랫폼을 지원하며 다양한 설치 방법을 제공합니다.
실팽파일도 제공하기 때문에 실행파일을 다운로드 받아서 /usr/bin 경로로 복사한 후 실행시켜봅니다.
wget https://github.com/derailed/k9s/releases/download/v0.13.7/k9s_0.13.7_Linux_i386.tar.gz
tar xzvf k9s_0.13.7_Linux_i386.tar.gz
sudo mv k9s /usr/bin
k9s
kfctl
배포 플랫폼
스탠다드 쿠베플로우 설치
Dex 버전 설치
프로파일
쿠베플로우 삭제
본 게시물은 "쿠버네티스에서 머신러닝이 처음이라면! 쿠브플로우! - 이명환 저"를 기반으로 작성되었음을 알려드립니다.
