쿠버네티스의 연결 담당 서비스
컨테이너를 다루는 표준 아키텍처, 쿠버네티스
쿠버네티스 연결을 담당하는 서비스
이전 포스팅에선 쿠버네티스 클러스터 내부에서 파드를 사용했습니다.
그런데 쿠버네티스 클러스터 내부에서만 파드를 이용하려고 쿠버네티스를 배우는 것은 아닙니다.
이번에는 외부 사용자가 파드를 이용하는 방법을 알아보겠습니다.
시작하기에 앞서 혼동되는 용어를 명확하게 짚고 넘어갑시다.
일반적인 서비스 : 웹 서비스나 네트워크 서비스처럼 운영 체제에 속한 서비스 데몬 또는 개발 중인 서비스
쿠버네티스의 서비스 : 외부에서 쿠버네티스 클러스터에 접속하는 방법, 서비스
가장 간단하게 연결하는 노드포트
외부에서 쿠버네티스 클러스터의 내부에 접속하는 가장 쉬운 방법은 노드포트를 서비스를 이용하는 것입니다.
노드포트 서비스를 설정하면 모든 워커 노드의 특정 포트(노드포트)를 열고 여기로 오는 모든 요청을 노트포트 서비스로 전달합니다.
그리고 노드포트 서비스는 해당 업무를 처리할 수 있는 파드로 요청을 전달합니다.
노드포트 서비스로 외부에서 접속하기
-
디플로이먼트 파드를 생성합니다.
kubectl create deployment np-pods --image=sysnet4admin/echo-hname

-
배포된 파드를 확인하고,
kubectl create로 노드포트 서비스를 생성합니다. 여기서는 편의를 위해 이미 정의한 오브젝트 스펙을 이용합니다.kubectl create -f ~/_Book_k8sInfra/ch3/3.3.1/nodeport.yaml

- 사용하는 오브젝트 스펙은 다음과 같습니다.
- 기존 파드 구조에서
kind가Service로 바뀌었고, spec에 컨테이너에 대한 정보가 없습니다. - 그리고 접속에 필요한 네트워크 관련 정보(protocol, port, targetPort, nodePort)와 서비스의
type을NodePort로 지정했습니다.
apiVersion: v1 kind: Service metadata: name: np-svc spec: selector: app: np-pods ports: - name: http protocol: TCP port: 80 targetPort: 80 nodePort: 30000 type: NodePort - 기존 파드 구조에서
-
노드포트 서비스로 생성한 np-svc 서비스를 확인합니다.
kubectl get services

- 노드포트의 포트 번호가 30000번으로 지정됐습니다.
- CLUSTER-IP(10.96.0.1)은 쿠버네티스 클러스터의 내부에서 사용하는 IP로, 자동으로 지정됩니다.
-
쿠버네티스 클러스터의 워커 노드 IP를 확인합니다.
kubectl get nodes -o wide
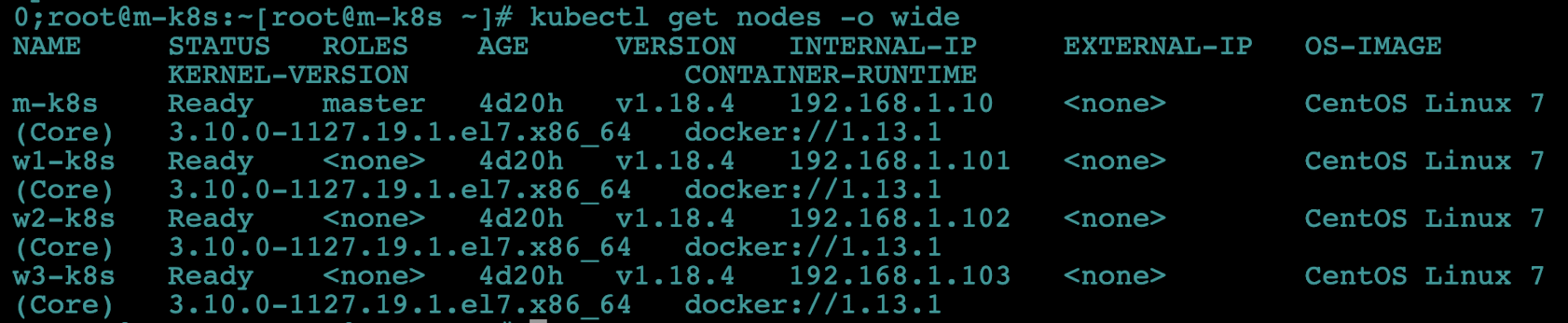
-
호스트 노트북에서 웹 브라우저를 띄우고 확인한 워커 노드의 IP와 30000번(노드포트 포트 번호)으로 접속해 외부에서 접속되는지 확인합니다.
- 화면에 파드 이름이 표시되는지도 확인합니다.
- 이때 파드가 하나이므로 화면에 보이는 이름은 모두 동일합니다.
-kubectl get pods





배포된 파드에 모든 노드의 노드포트를 통해 외부에서도 접속할 수 있음을 확인했습니다!
부하 분산 테스트하기
조금 더 현실적인 시나리오로 테스트해봅시다.
디플로이먼트로 생성된 파드 1개에 접속하고 있는 중에, 파드가 3개로 증가하면 접속이 어떻게 바뀔까요?
즉, 부하가 분산되는지(로드밸런서 기능) 확인해보겠습니다.
- 호스트 노트북에서 파워셸을 띄우고 다음 명령을 실행합니다.
-
이 명령은 반복적으로 192.168.1.101:30000(w1-k8s의 노드포트)에 접속해 접속한 파드 이름을 화면에 표시(Invoke-RestMethod)합니다.
-
이렇게 하면 파드가 1개에서 3개로 늘어나는 시점을 관찰할 수 있습니다.
-
먼저 파워셸(powershell)을 설치합니다.

-
명렁어를 입력합니다.
$i=0; while($true) { % { $i++; write-host -NoNewline "$i $_" } (Invoke-RestMethod "http://192.168.1.101:30000")-replace '\n', " " }
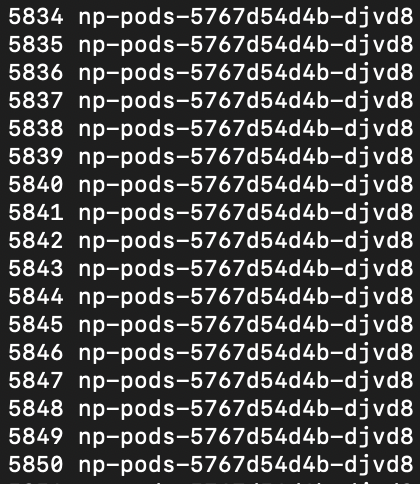
명령을 실행하면 위와 같이 현재 접속한 호스트 이름을 순서대로 출력합니다.
-
- 파워셸로 코드를 실행하고 나면 쿠버네티스 마스터 노드에서 scale을 실행해 파드를 3개로 증가시킵니다.
kubectl scale deployment np-pods --replicas=3

- 배포된 파드를 확인합니다.
kubectl get pods

- 파워셸 명령 창에 표시되는 파드 이름에 배포된 파드 3개가 돌아가면서 표시되는지 확인합니다. 즉, 부하분산이 제대로 되는지 확인합니다!
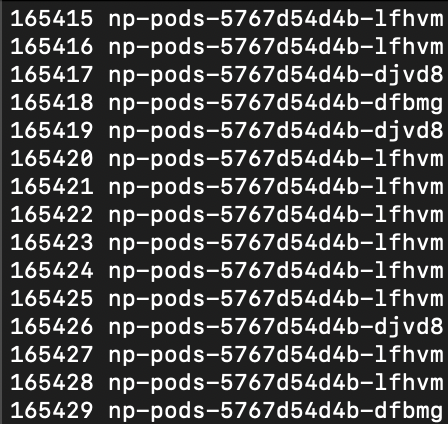
신기합니다. 어떻게 추가된 파드를 외부에서 추적해 접속하는 것일까요?
이는 오드포트 오브젝트 스펙에 적힌 np-pods와 디플로이먼트의 이름을 확인해 동일하면 같은 파드라고 간주하기 때문입니다.
추적 방법은 많지만, 여기서는 가장 간단하게 이름으로 진행했습니다.
- 노드포트의 오브젝트 스펙인 nodeport.yaml의 파일 일부
spec:
selector:
app: np-pods expose로 노드포트 서비스 생성하기
노드포트 서비스는 오브젝트 스펙 파일로만 생성하는 걸까요?
아닙니다, 노드포트 서비스는 expose 명령어로도 생성할 수 있습니다.
- expose 명령어를 사용해 서비스로 내보낼 디플로이먼트를 np-pods로 지정합니다.
- 해당 서비스의 이름은
np-svc-v2로, 타입은NodePort로 지정합니다.(서비스 타입은 반드시 대소문자를 구분해야 합니다!, 구분하지 않으면 invaild 오류가 발생합니다.) - 마지막으로 서비스가 파드로 보내줄 연결 포트를 80번으로 지정합니다.
kubectl expose deployment np-pods --type=NodePort --name=np-svc-v2 --port=80

- 해당 서비스의 이름은
- 실행된 서비스를 확인합니다.
kubectl get services

- 오브젝트 스펙으로 생성할 땐 포트 번호를 30000번으로 지정했으나 expose를 사용하면 노트포트의 포트 번호를 지정할 수 없습니다.
- 포트 번호는 30000~32767에서 임의로 지정되므로 현재는 31143번으로 생성된 것을 볼 수 있습니다.
- 호스트 노트북에서 웹 브라우저를 띄우고 192.168.1.101:31143으로 접속합니다. 배포된 파드 중 하나의 이름이 웹 브라우저에 표시되는지 확인합니다.

- 노드포트로 쿠버네티스 클러스터 내부에 접속하는 방법을 알아봤습니다. 다음 실습 진행을 위해 배포한 디플로이먼트와 서비스 2개를 모두 삭제합니다.
kubectl delete deployment np-podskubectl delete services np-svckubectl delete services np-svc-v2

사용 목적별로 연결하는 인그레스(Ingress)
노드포트 서비스는 포트를 중복 사용할 수 없어서 1개의 노드포트에 1개의 디플로이먼트만 적용됩니다.
그렇다면 여러 개의 디플로이먼트가 있을 때 그 수만큼 노드포트 서비스를 구동해야 할까요??
쿠버네티스는 이런 경우에 인그레스를 사용합니다.
- 인그레스(Ingress)
- 고유한 주소를 제공해 사용 목적에 따른 다른 응답 제공
- 트래픽에 대한 L4/L7 로드밸런서와 보안 인증서를 처리하는 기능 제공
- 인그레스를 사용하려면 인그레스 컨트롤러가 필요
- 다양한 인그레스 컨트롤러가 있지만 여기선 쿠버네티스에서 프로젝트로 지원하는 NGINX 인그레스 컨트롤러로 구성
- 궁극적인 목표는 사용자가 접속하는 경로에 따라 다른 결괏값을 제공하는 것입니다.
- 결괏값의 맞춤법을 확인해보다 알게되었는데 사이시옷 규정에 따라 평소에 쓰던 최대값, 최소값 등과 달리 최댓값, 최솟값이 옳은 맞춤법이라고 하더군요.. 쿠버테니스와 상관없는 내용이지만 틀리게 쓰는 경우가 많은 것 같아 참고하시라고 말씀드립니다!
- (고윳값(固有-), 교찻값(交叉-), 극댓값(極大-), 근삿값(近似-), 기댓값(期待-), 요솟값(要素-), 원잣값(原子-), 유횻값(有效-), 전셋값(傳貰-), 최솟값(最小-), 최젓값(最低-) 등)
- NGINX 컨트롤러 작동 단계
- 사용자는 노드마다 설정된 노드포트를 통해 노드포트 서비스로 접속합니다. 이때 노드포트 서비스를 NGINX 인그레스 컨트롤러로 구성합니다.
- NGINX 인그레스 컨트롤러는 사용자의 접속 경로에 따라 적합한 클러스터 IP 서비스로 경로를 제공합니다.
- 클러스터 IP 서비스는 사용자를 해당 파드로 연결해 줍니다.
- 인그레스 컨트롤러는 파드와 직접 통신할 수 없어서 노드포트 또는 로드밸런서 서비스와 연동되어야 합니다. 따라서 노드포트로 이를 연동했습니다.
인그레스 컨트롤러 서비스가 파드와 직접 통신하지 못하고 노드포트 서비스와 연동하여 실행되는 개념이 어려운데요, 실습을 진행하며 이해해보도록 합시다!
- 테스트용으로 디플로이먼트 2개(in-hname-pod, in-ip-pod)을 배포합니다.
kubectl create deployment in-hname-pod --image=sysnet4admin/echo-hnamekubectl create deployment in-ip-pod --image=sysnet4admin/echo-ip


- 배포된 파드 상태를 확인합니다.
kubectl get pods

- NGINX 인그레스 컨트롤러를 설치합니다. 여기에는 많은 종류의 오브젝트 스펙이 포함됩니다. 설치되는 요소들은 NGINX 인그레스 컨트롤러 서비스를 제공하기 위해 미리 지정되어 있습니다.
kubectl apply -f ~/_Book_k8sInfra/ch3/3.3.2/ingress-nginx.yaml
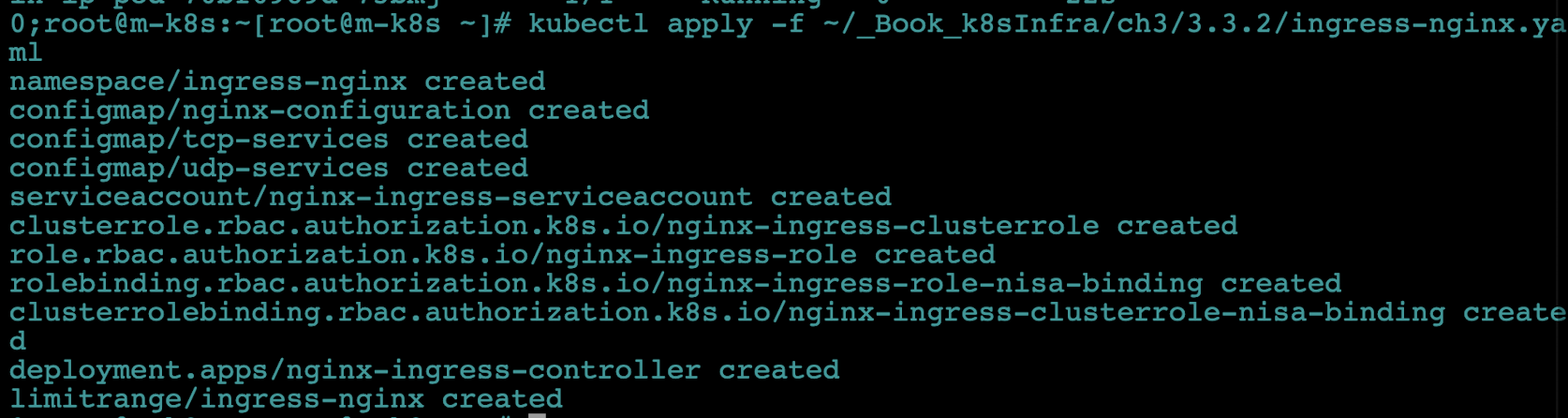
- NGIX 인그레스 컨트롤러의 파드가 배포됐는지 확인합니다.
- NGINX 인그레스 컨트롤러는 default 네임스페이스가 아닌 ingress-nginx 네임스페이스에 속하므로
-n ingress-nginx옵션을 추가해야 합니다.
--n은 namespace의 약어로, default 외의 네임스페이스를 확인할 떄 사용하는 옵션입니다.- 파드뿐만 아니라 서비스를 확인할 때도 동일한 옵션을 줍니다.
kubectl get pods -n ingress-nginx

- NGINX 인그레스 컨트롤러는 default 네임스페이스가 아닌 ingress-nginx 네임스페이스에 속하므로
- 인그레스를 사용자 요구 사항에 맞게 설정하려면 경로와 작동을 정의해야 합니다. 파일로도 설정할 수 있으므로 다음 경로로 실행해서 미리 정의해둔 설정을 정용합니다.
kubectl apply -f ~/_Book_k8sInfra/ch3/3.3.2/ingress-config.yaml

인그레스를 위한 설정 파일은 다음과 같습니다. 이 파일은 들어오는 주소 값과 포트에 따라 노출된 서비스를 연결하는 역할을 설정합니다.
외부에서 주소 값과 노드포트를 가지고 들어오는 것은 hname-svc-default 서비스와 연결된 파드로 넘기고, 외부에서 들어오는 주소 값, 노드포트와 함께 뒤에 /ip를 추가한 주소 값은 ip-svc 서비스와 연결된 파드로 접속하게 설정했습니다.
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
# Ingress의 이름
# 이름을 통해서 통신할 ingress 컨트롤러를 확인
name: ingress-nginx
# 메타테이터의 기록 및 변경
# 여기선 rewrite-target을 /(기본주소)로 지정함
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
# 규칙을 지정
rules:
- http:
paths:
# 기본 경로 규칙
- path:
# 연결되는 서비스와 포트
backend:
serviceName: hname-svc-default
servicePort: 80
# 기본 경로에 ip라는 이름의 경로 추가
- path: /ip
# 연결되는 서비스와 포트
backend:
serviceName: ip-svc
servicePort: 80
# 기본 경로에 your-directory 경로 추가
- path: /your-directory
# 연결되는 서비스와 포트
backend:
serviceName: your-svc
servicePort: 80- 인그레스 설정 파일이 제대로 등록됐는지 확인합니다.
kubectl get ingress

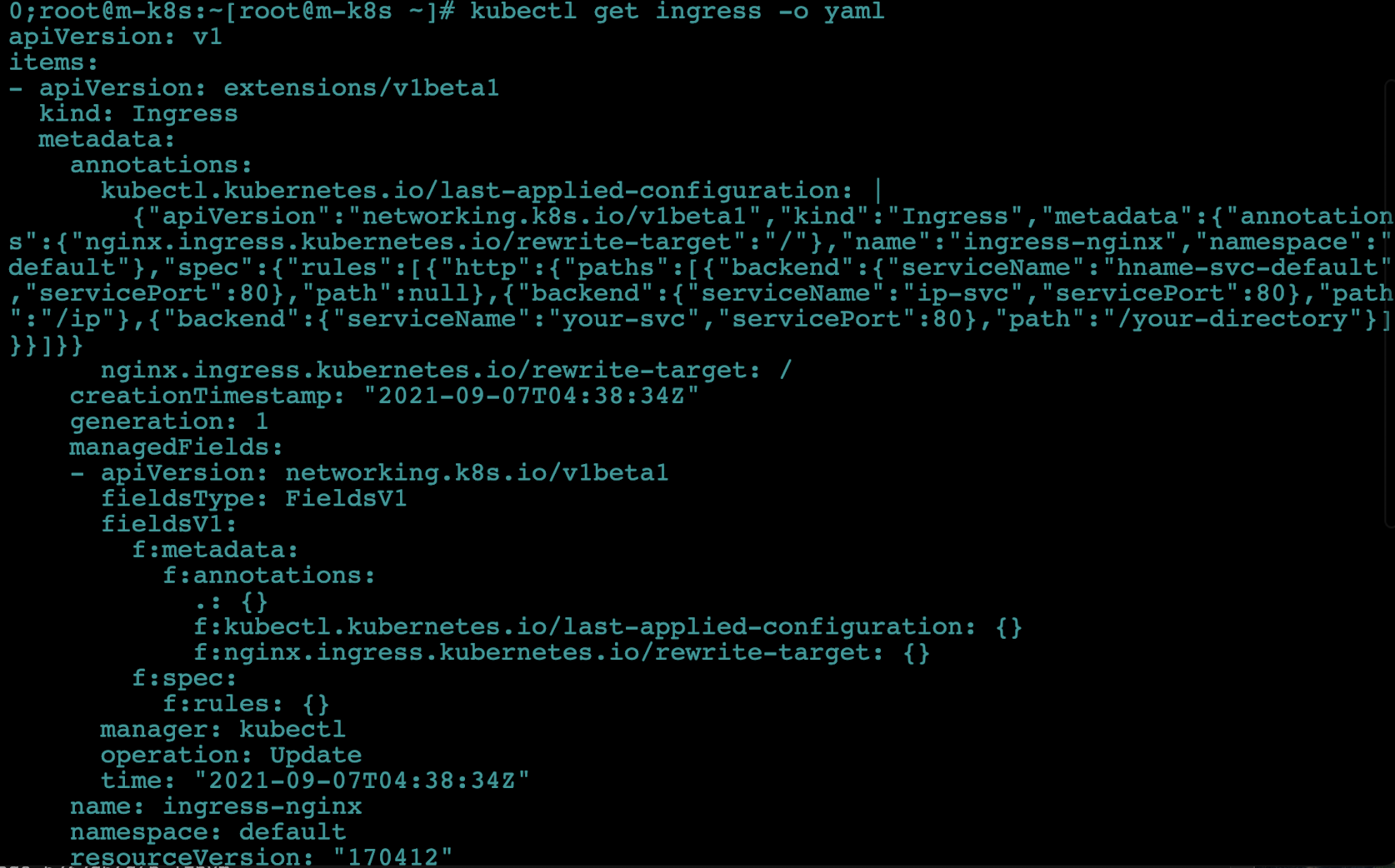
- 인그레스에 요청한 내용이 확실하게 적용됐는지 확인합니다.
kubectl get ingress -o yaml- 이 명령은 인그레스에 적용된 내용을 야믈 형식으로 출력해 적용된 내용을 확인할 수 있습니다.
- 우리가 적용한 내용 외에 자동으로 생성하는 것까지 모두 확인할 수 있습니다.
- 이 명령을 응용하면 오브젝트 스펙 파일을 만드는 데 도움이 됩니다!
- NGINX 인그레스 컨트롤러 생성과 인그레스 설정을 완료했습니다. 이제 외부에서 NGINX 인그레스 컨트롤러에 접속할 수 있게 노드포트 서비스로 NGINX 인그레스 컨트롤러를 외부에 노출합니다.
kubectl apply -f ~/_Book_k8sInfra/ch3/3.3.2/ingress.yaml

- 적용하는 코드는 다음과 같습니다.
- 기존 노드포트와 달리 http를 처리하기 위해 30100번 포트로 들어온 요청을 80번 포트로 넘기고, https를 처리하기 위해 30101번 포트로 들어온 것을 443번 포트로 넘깁니다.- 그리고 NGINX 인그레스 컨트롤러가 위치하는 네임스페이스를
ingress-nginx로 지정하고 NGINX 인그레스 컨트롤러의 요구 사항에 따라 셀릭터를ingress-nginx로 지정했습니다.apiVersion: v1 kind: Service metadata: # 서비스 이름 name: nginx-ingress-controller # 네임스페이스 이름 namespace: ingress-nginx spec: # 사용할 프로토콜과 포트들을 지정 ports: # http에 대한 프로토콜 및 포트 지정 - name: http protocol: TCP port: 80 targetPort: 80 nodePort: 30100 # https에 대한 프로토콜 및 포트 지정 - name: https protocol: TCP port: 443 targetPort: 443 nodePort: 30101 # 셀렉터의 레이블 지정 selector: app.kubernetes.io/name: ingress-nginx # 서비스 타입을 설정 type: NodePort
- 그리고 NGINX 인그레스 컨트롤러가 위치하는 네임스페이스를
- 노드포트 서비스로 생성된 NGINX 인그레스 컨트롤러(nginx-ingress-controller)를 확인합니다.
- 이때도
-n ingress-nginx로 네임스페이스를 지정해야만 내용을 확인할 수 있습니다. kubectl get services -n ingress-nginx

- 이때도
- expose 명령으로 디플로이먼트도 서비스로 노출합니다(2개).
- 외부와 통신하기 위해 클러스터 내부에서만 내용하는 파드를 클러스터 외부에 노출할 수 있는 구역으로 옮기는 것입니다.
- 내부와 외부 네트워크를 분리해 관리하는 DMZ(DeMilitarized Zone, 비무장지대)와 유사한 기능입니다.
- 비유적으로 표현하면 각 방에 있는 물건을 외부로 내보내기 전에 공용 공간인 거실로 모두 옮기는 것과 가습니다.
kubectl expose deployment in-hname-pod --name=hname-svc-default --port=80,443kubectl expose deployment in-ip-pod --name=ip-svc --port=80,443

- 생성된 서비스를 점검해 디플로이먼트들이 서비스에 정상적으로 노출되는지 확인합니다. 새로 생성된 서비스는 default 네임스페이스에 있으므로
-n옵션으로 네임스페이스를 지정하지 않아도 됩니다.kubectl get services

- 이제 준비가 끝났습니다. 노트북에서 웹 브라우저를 띄우고
192.168.1.101:30100에 접속해 외부에서 접속되는 경로에 따라 다르게 작동하는지 확인합니다.- 이때 워커 노드 IP는 101,102,103 어떤 것이든 상관 없습니다.
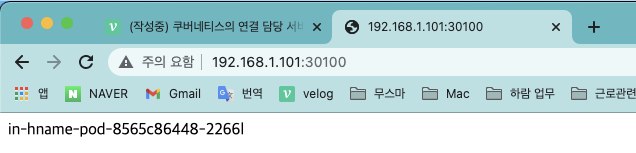
- 이때 워커 노드 IP는 101,102,103 어떤 것이든 상관 없습니다.
- 경로를 바꿔서
192.168.1.101:30100/ip로 접속해봅니다.- 요청 방법과 파드의 ip(CIDR로 임의 생성되므로 예시와 다를 수 있습니다.)가 반환되는지 확인합니다.

- 요청 방법과 파드의 ip(CIDR로 임의 생성되므로 예시와 다를 수 있습니다.)가 반환되는지 확인합니다.
- 이번엔
https://192.168.1.101:30101로 접속해 https 연결도 정상적으로 작동하는지 확인합니다.- 30101은 HTTPS의 포트인 443번으로 변환해 접속됩니다. 단, 브라우저에 따라 경고 메세지가 뜰 수도 있습니다.
- 파드 이름이 브라우저에 표시되는지 확인합니다.
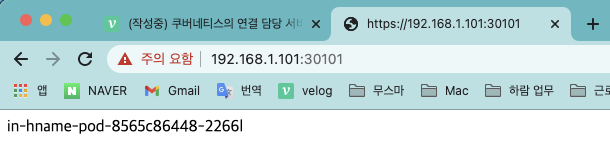
- 마지막으로
https://192.168.1.101:30101/ip를 입력해 마찬가지로 요청 방법과 파드의 IP 주소가 표시되는지 확인합니다.
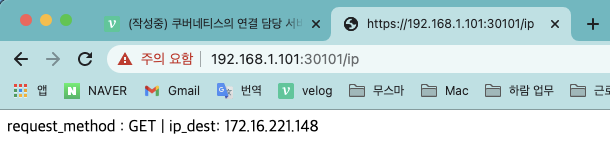
- NGINX 인그레스 컨트롤러 구성과 테스트가 끝났습니다. 다음 실습 진행을 위해 배포한 디플로이먼트와 모든 서비스를 삭제합니다.
kubectl delete deployment in-hname-podkubectl delete deployment in-ip-podkubectl delete services hname-svc-defaultkubectl delete services ip-svc

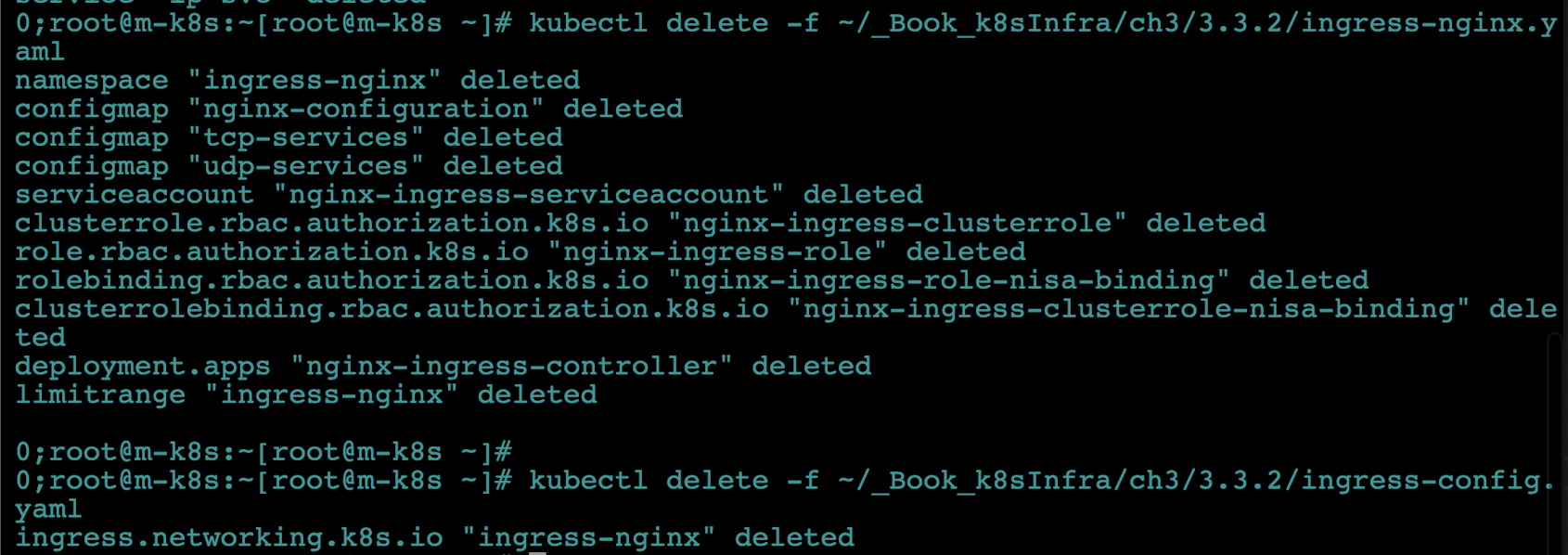
- NGINX 인그레스 컨트롤러와 관련된 내용도 모두 삭제합니다. 여러 가지 내용으 혼합됐으므로 설치 파일을 이용해 삭제하기를 권장합니다.
kubectl delete -f ~/_Book_k8sInfra/ch3/3.3.2/ingress-nginx.yamlkubectl delete -f ~/_Book_k8sInfra/ch3/3.3.2/ingress-config.yaml
클라우드에서 쉽게 구성 가능한 로드밸런서
앞에서 배운 연결 방식은 들어오는 요청을 모두 워커 노드의 노드포트를 통해 노드포트 서비스로 이동하고, 이를 다시 쿠버네티스의 파드로 보내는 구조였습니다.
이 방식은 매우 비효율적입니다.
그래서 쿠버네티스에는 로드밸런서(LoadBalancer) 라는 서비스 타입을 제공해 간단한 구조로 파드를 외부에 노출하고 부하를 분산합니다.
그런데 왜 먼저 로드밸런서를 사용하지 않았을까요?
로드밸런서를 사용하려면 로드밸런서를 이미 구현해 둔 서비스업체의 도움을 받아 쿠버네티스 클러스터 외부에 구현해야 하기 떄문입니다.
클라우드에서 제공하는 쿠버네티스를 사용하고 있다면 다음과 같이 선언만 하면 됩니다.(그래서 이 실습은 EKS, GKE, AKS에서만 가능합니다. 추후에 AKS를 구축해보게 된다면 실습해보도록 하죠!)
그러면 쿠버네티스 클러스터에 로드밸런서 서비스가 생성돼 외부와 통신할 수 있는 IP(EXTERNAL-IP)가 부여되고, 외부와 통신할 수 있으며 부하도 분산됩니다.
kubectl expose deployment ex-lb --type=LoadBalancer --name=ex-svckubectl get services ex-svc
그렇다면 우리가 만든 테스트 가상 환경(온프레미스)에서는 로드밸런서를 사용하는 것은 불가능할까요?
대안을 알아봅시다!
온프레미스에서 로드밸런서를 제공하는 MetalLB
온프레미스에서 로드밸런서를 사용하려면 내부에 로드밸런서 서비스를 받아주는 구성이 필요한데, 이를 지원하는 것이 MetalLB입니다.
-
MetalLB
- 베어메탈(bare metal, 운영 체제가 설치되지 않은 하드웨어)로 구성된 쿠버네티스에서도 로드밸런서를 사용할 수 있게 고안된 프로젝트
- 특별한 네트워크 설정이나 구성이 있는 것이 아니라 기존의 L2 네트워크(ARP/NDP)와 L3 네트워크(BGP)로 로드밸런서를 구현합니다.
- 그러므로 네트워크를 새로 배워야 할 부담이 없으며 연동하기도 매우 쉽습니다.
- 여기서는 L2 네트워크로 로드밸런서를 구현하고, 클라우드 로드밸런서와 거의 동일한 경로로 통신하며, 테스트 목적으로 두 개의 MetalLB 로드밸런서 서비스를 구현하겠습니다.
-
MetalLB controller
- 작동 방식(Protocol)을 정의하고 EXTERNAL-IP를 부여해 관리
-
MetalLB speaker
- 정해진 작동 방식(L2/ARP, L3/BGP)에 따라 경로를 만들 수 있도록 네트워크 정보를 광고하고 수집해 각 파드의 경로를 제공합니다.
- L2는 스피커 중에서 리더를 선출해 경로 제공을 총괄하게 합니다.
구성을 확인했으니 MetalLB로 온프레미스 쿠버네티스 환경에서 로드밸런서 서비스를 사용하도록 구성해보겠습니다!
-
디플로이먼트를 이용해 2종료(lb-hname-pods, lb-ip-pods)의 파드를 생성합니다. 그리고 scale 명령으로 파드를 3개로 늘려 노드당 1개씩 파드가 배포되게 합니다.
kubectl create deployment lb-hname-pods --image=sysnet4admin/echo-hnamekubectl scale deployment lb-hname-pods --replicas=3kubectl create deployment lb-ip-pods --image=sysnet4admin/echo-ipkubectl scale deployment lb-ip-pods --replicas=3

-
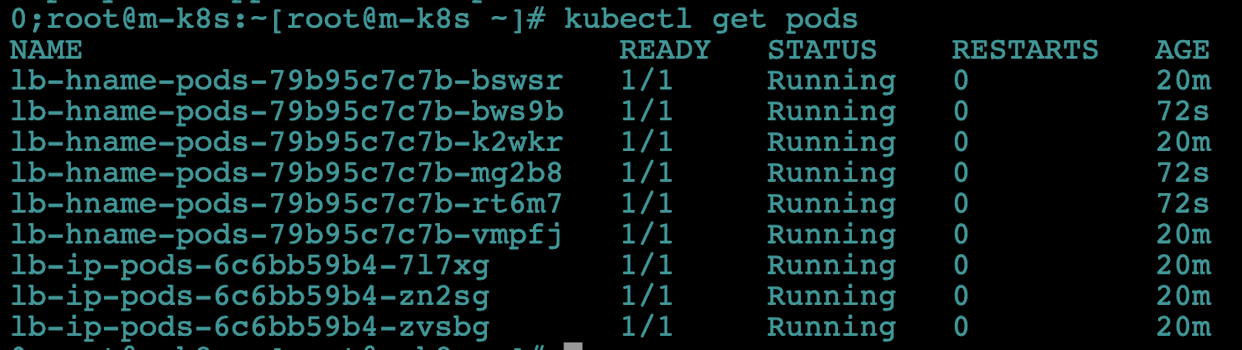
2종류의 파드가 3개씩 총 6개가 배포됐는지 확인합니다.
kubectl get pods

-
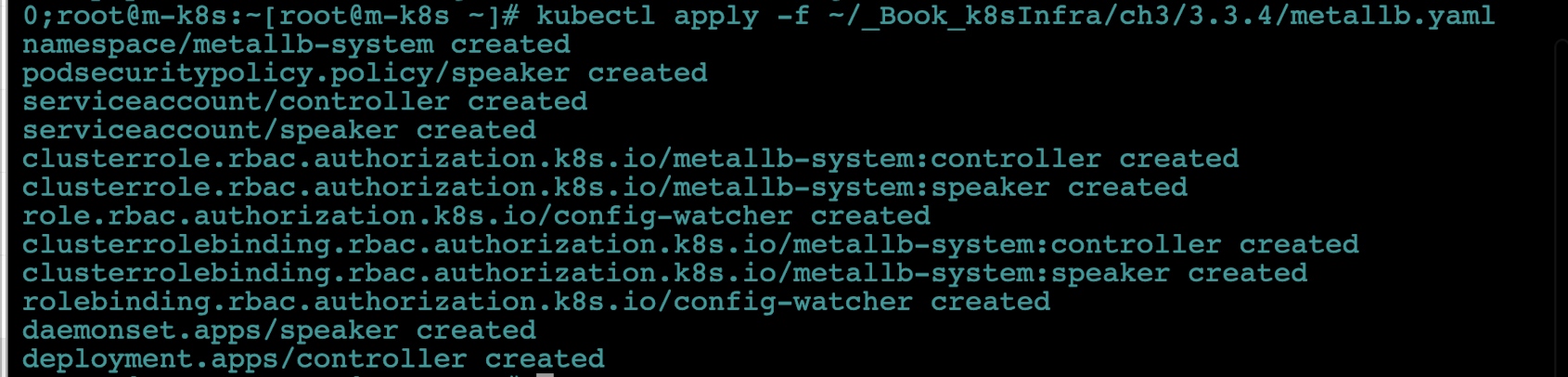
인그레스와 마찬가지로 사전에 정의된 오브젝트 스펙으로 MetalLB를 구성합니다. 이렇게 하면 MetalLB에 필요한 요소가 모두 설치되고 독립적인 네임스페이스(metallb-system)도 함께 만들어집니다.
kubectl apply -f ~/_Book_k8sInfra/ch3/3.3.4/metallb.yaml
-
배포된 MetalLB의 파드가 5개(controller 1개, speaker 4개)인지 확인하고, IP와 상태도 확인합니다.
kubectl get pods -n metallb-system -o wide

-
인그레스와 마찬가지로 MetalLB도 설정을 적용해야 하는데, 다음 방법으로 적용합니다. 이때 오브젝트는 ConfigMap을 사용합니다.
- ConfigMap은 설정이 정의된 포맷이라고 생각하면 됩니다.
kubectl apply -f ~/_Book_k8sInfra/ch3/3.3.4/metallb-l2config.yaml
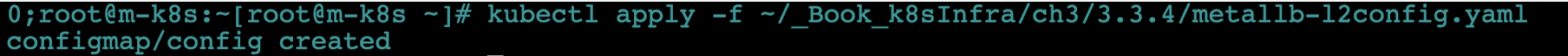
- 파일 구성을 살펴봅시다!
apiVersion: v1 kind: ConfigMap metadata: # 네임스페이스 이름 namespace: metallb-system # 컨피그맵 이름 name: config data: # 설정내용 config: | # metallb의 세부 설정 address-pools: - name: nginx-ip-range # metallb에서 제공하는 로드밸런서의 동작 방식 protocol: layer2 # metallb에서 제공하는 로드밸런스의 Ext 주소 addresses: - 192.168.1.11-192.168.1.13
-
ConfigMap이 생성됐는지 확인합니다.
kubectl get configmap -n metallb-system

-
-o yaml옵션을 주소 다시 실행해 MetalLB의 설정이 올바르게 적용됐는지 확인합니다.kubectl get configmap -n metallb-system -o yaml
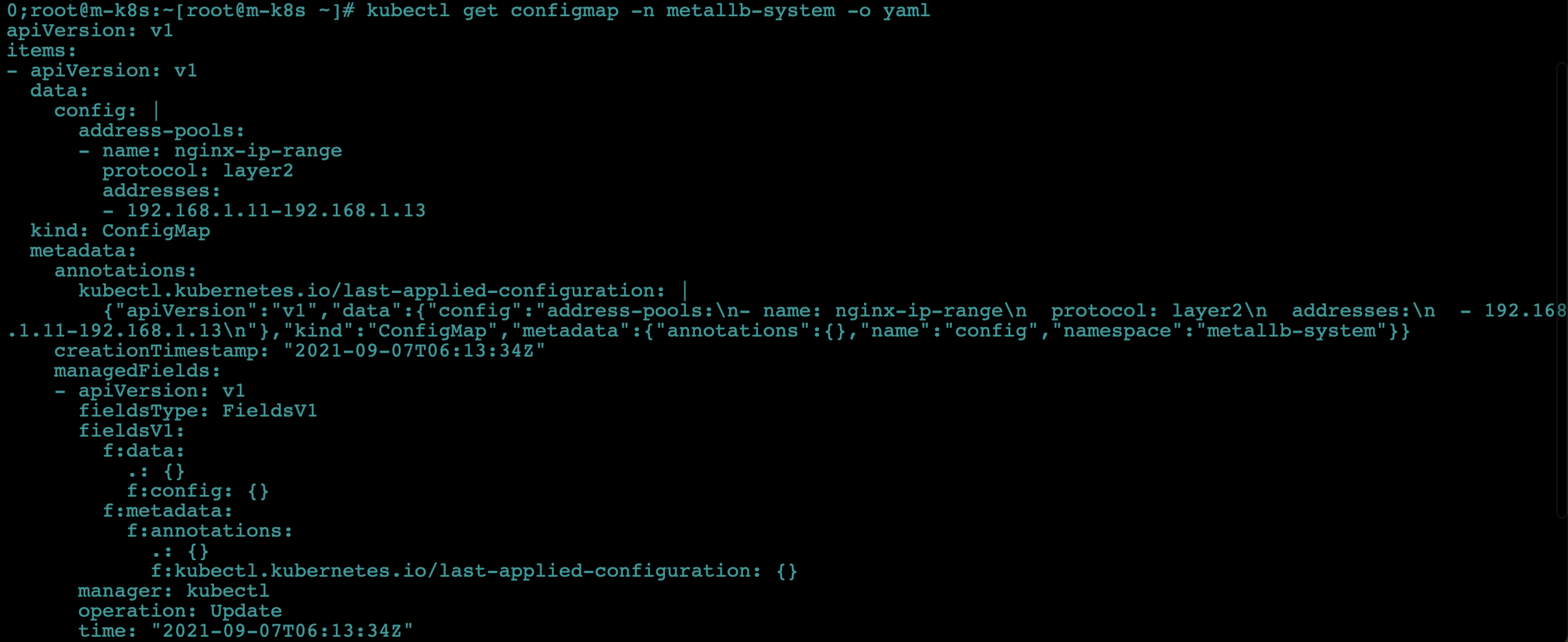
-
모든 설정이 완료됐으니 이제 각 디플로이먼트(lb-hname-pods, lb-ip-pods)를 로드밸런서 서비스로 노출합니다.
kubectl expose deployment lb-hname-pods --type=LoadBalancer --name=lb-hname-svc --port=80kubectl expose deployment lb-ip-pods --type=LoadBalancer --name=lb-ip-svc --port=80

-
생성된 로드밸런서 서비스별로 CLUSTER-IP와 EXTERNAL-IP가 잘 적용됐는지 확인합니다. 특히 EXTERNAL-IP에 ConfigMap을 통해 부여한 IP를 확인합니다!
kubectl get services

-
EXTERNAL-IP가 잘 작동하는지 확인해 봅시다. 브라우저에서 192.168.1.11에 접속합니다. 배포된 파드 중 하나의 이름이 브라우저에 표시되는지 확인하세요!

-
이번엔 192.168.1.12로 접속해 파드의 요청 방법과 IP가 표시되는지 확인합니다.
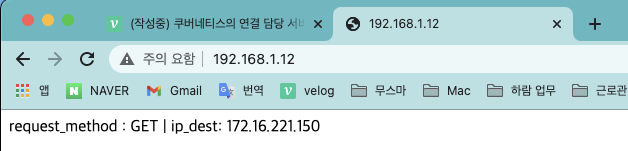
-
파워셸 명령 창을 띄우고 셸 스크립트를 실행합니다. 로드밸런서 기능이 정상적으로 작동하면 192.168.1.11에서 반복적으로 결괏값을 가져옵니다.
$i=0; while($true) { % { $i++; write-host -NoNewline "$i $_" } (Invoke-RestMethod "http://192.168.1.11")-replace '\n', " " }
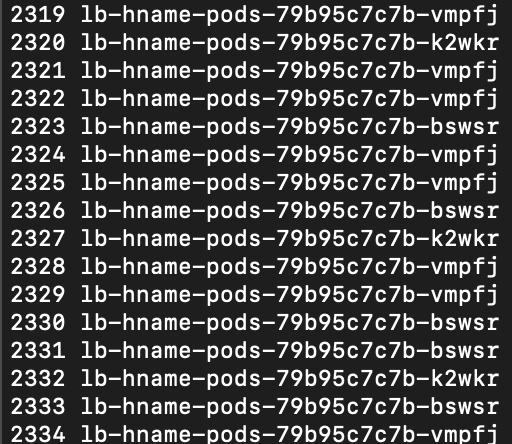
-
scale 명령으로 파드를 6개로 늘립니다.
kubectl scale deployment lb-hname-pods --replicas=6

-
늘어난 파드 6개에도 EXTERNAL-IP를 통해 접근되는지 확인합니다.
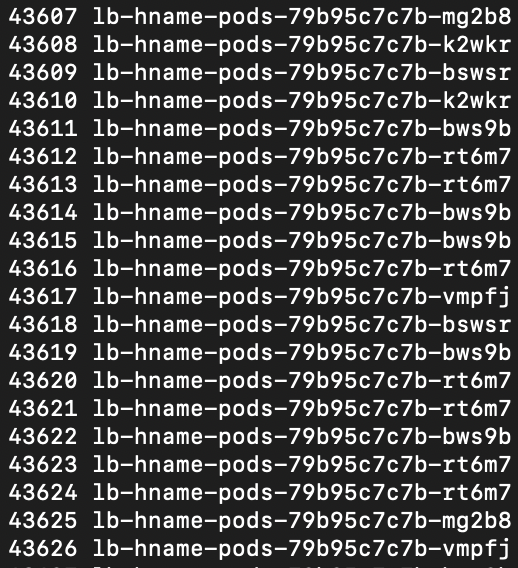
kubectl get pods
-
온프레미스에서도 로드밸런서를 사용할 수 있게 하는 MetalLB를 구성해봤습니다. 다음 실습을 진행하기 전에 배포한 디플로이먼트와 서비스는 삭제합니다. 단, MetalLB 설정은 계속 사용하므로 삭제하지 않겠습니다.
kubectl delete deployment lb-hname-podskubectl delete deployment lb-ip-podskubectl delete service lb-hname-svckubectl delete service lb-ip-svc
부하에 따라 자동으로 파드 수를 조절하는 HPA
지금까지는 사용자 1명이 파드에 접근하는 방법을 알아봤습니다.
그런데 사용자가 갑자기 늘어난다면 어떻게 될까요?
파드가 더 이상 감당할 수 없어서 서비스 불가(여기서 서비스는 쿠버네티스의 서비스가 아닙니다!)라는 결과를 초래할 수도 있습니다.
쿠버네티스는 이런 경우를 대비해 부하량에 따른 디플로이먼트의 파드 수를 유동적으로 관리하는 기능을 제공합니다.
이를 HPA(Horizontal Pod Autoscaler) 라고 합니다. HPA를 어떻게 설정하고 사용하는지 알아봅시다!
-
디플로이먼트 1개를
hpa-hname-pods라는 이름으로 생성합니다.kubectl create deployment hpa-hname-pods --image=sysnet4admin/echo-hname

-
앞에서 MetalLB를 구성했으므로 바로 expose를 실행해
hpa-hname-pods를 로드밸런서 서비스로 바로 설정할 수 있습니다.kubectl expose deployment hpa-hname-pods --type=LoadBalancer --name=hpa-hname-svc --port=80

-
설정된 로드밸런서 서비스와 부여된 IP를 확인합니다.
kubectl get services

-
HPA가 작동하려면 파드의 자원이 어느 정도 사용되는지 파악해야 합니다. 부하를 확인하는 명령은 리눅스의 top(table of processes)과 비슷한
kubectl top pods입니다.kubectl top pods

- 그러나 자원을 요청하는 설정이 없다며 에러가 발생합니다. HPA 작동하는 구조를 통해 에러가 발생하는 이유를 살펴봅시다.
- HPA 자원을 요청할 때 메트릭 서버(Metrics-Server)를 통해 계측밧을 전달받습니다.- 그런데 현재 우리는 메트릭 서버가 없기 때문에 에러가 발생합니다.
- 따라서 계측값을 수집하고 전달해 주는 메트릭 서버를 설정해야 합니다.
- 에러의 내용을 보면(get services http:heapster)를 요청합니다. 힙스터는 쿠버네티스 1.13 이전 버전에서 사용하던 모니터링 도구입니다. 1.13 버전부턴 메트릭 서버를 모니터링 도구로 추천합니다!
-
서비스에서와 마찬가지로 메트릭 서버도 오브젝트 스펙 파일로 설치할 수 있습니다.
- 그러나 오브젝트 스펙 파일이 여러 개라서
git clone이후에 디렉터리에 있는 파일들을 다시 실행하야 하는 번거로움이 있습니다.

- 또한 실습에서 사용하려면 몇 가지 추가 설정이 필요합니다. 그래서 쿠버네티스 메트릭 서버의 원본 소스(https://github.com/kubernetes-sigs/metrics-server)를 sysnet4admin 계정으로 옮겨 메트릭 서버를 생성하겠습니다.
kubectl create -f ~/_Book_k8sInfra/ch3/3.3.5/metrics-server.yaml

- 기존 코드에서 수정된 일부분을 살펴봅시다!
containers: - name: metrics-server image: k8s.gcr.io/metrics-server-amd64:v0.3.6 args: # Manually Add for lab env(Sysnet4admin/k8s) # skip tls internal usage purpose # TLS(Transport Layer Security)를 무시하게 합니다. - --kubelet-insecure-tls # kubelet could use internalIP communication # kubelet이 내부 주소를 우선 사용하게 합니다. - --kubelet-preferred-address-types=InternalIP - --cert-dir=/tmp - --secure-port=4443- 만약 쿠버네티스 메트릭 서버의 소스를 그대로 내려받아 실행하면 앞의 설정이 적용되지 않아 다음과 같은 에러가 발생합니다.
-kubectl top podserror: Metrics not available for pod default/hpa-hname-pods-~~, age:~~
- 그러나 오브젝트 스펙 파일이 여러 개라서
-
메트릭 서버를 설정하고 나면
kubectl top pods명령의 결과를 제대로 확인할 수 있습니다.- 완료되면 파드의 top값을 확인합니다. 현재는 아무런 부하가 없으므로 CPU와 MEMORY 값이 매우 낮게 나옵니다.

- 현재는 scale 기준 값이 설정되어 있지 않아서 파드 증설 시점을 알 수가 없습니다.
- 따라서 파드에 부하가 걸리기 전에 scale이 실행되게 디플로이먼트 기준 값을 기록합니다.
- 이때 디플로이먼트를 새로 베포하기보다는 기존에 배포한 디플로이먼트 내용을
edit명령으로 직접 수정합니다.
- 완료되면 파드의 top값을 확인합니다. 현재는 아무런 부하가 없으므로 CPU와 MEMORY 값이 매우 낮게 나옵니다.
-
edit명령을 실행해 배포된 디플로이먼트 내용을 확인합니다.- 40번쨰 줄에
resources: {}부분에서 {}을 생략하고 그 아래에 다음과 같이requests, limits항목과 그 값을 추가합니다. 이때 추가한 값은 파드마다 주어진 부하량을 결정하는 기준이 됩니다.
- 여기서 사용한 단위 m은 milliunits의 약어로 1000m은 1개의 CPU가 됩니다. 따라서 10m은 파드의 CPU 0.001 사용을 기준으로 파드를 증서하게 설정한 겂입니다.- 또한 순간적으로 한쪽 파드가 부하가 몰릴 경우를 대비해 CPU 사용 제한을 0.05로 주었습니다. 추가가 끝나면 Vim과 동일하게 저장(:wq!)하고 나옵니다.
kubectl edit deployment hpa-hname-pods- 책에서 제시한 것과 같이 cpu: "50m" 등으로 설정하면 limits, requests 등이 invaild라는 오류가 납니다. 쿠버네티스 공식 Docs를 참고하여 아래와 같이 수정해주세요(제가 작성한 것과 같이).
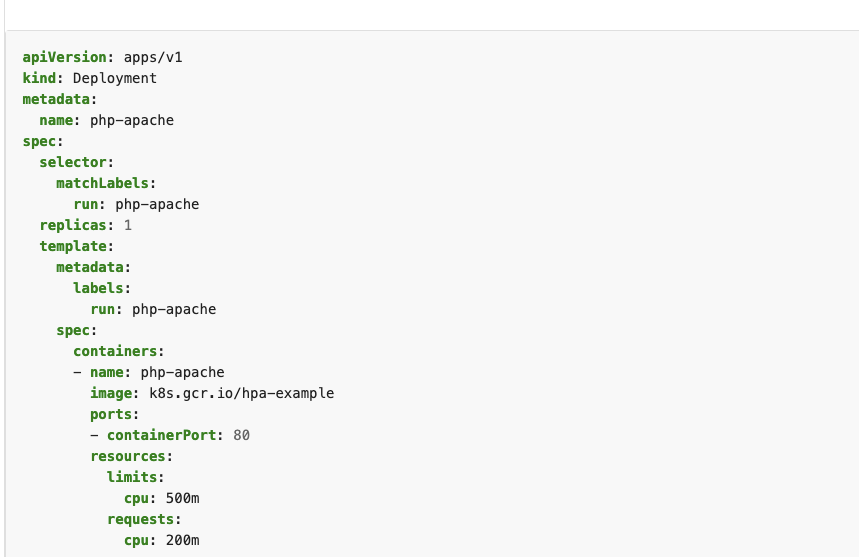
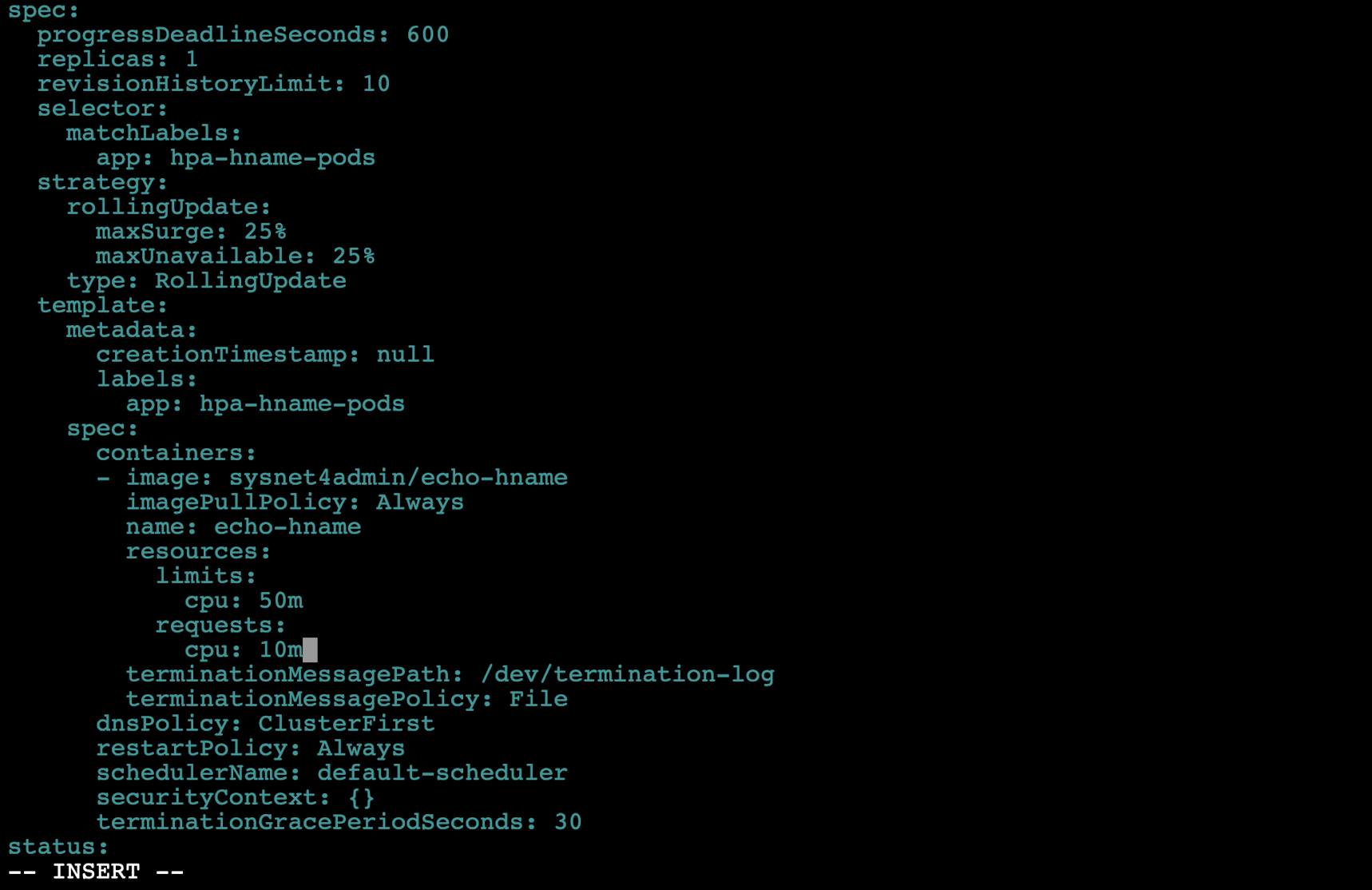

- 40번쨰 줄에
-
일정 시간이 지난 후
kubectl top pods를 실행하면 스펙이 변경돼 새로운 파드가 생성된 것을 확인할 수 있습니다.

-
hpa-hname-pods에
autoscale을 설정해서 특정 조건이 만족되는 경우 자동으로scale명령이 수행되도록 하겠습니다.- 여기서
min은 최소 파드의 수,max는 최대 파드의 수입니다.cpu-percent는 CPU 사용량이 50%를 넘기면 autoscale하겠다는 의미입니다. kubectl autoscale deployment hpa-hname-pods --min=1 --max=30 --cpu-percent=50

- 여기서
* HPA를 통해 늘어나는 파드 수 계산 방법
HPA는 다음과 같은 바업ㅂ으로 파드의 증가 또는 감소를 조절합니다.
디플로이먼트 스펙에서 resources의 CPU를 10으로 설정하고, autoscale에서 cpu-percent를 50%로 했다고 가정하겠습니다.
- `kubectl top pods`로 확인된 파드의 메트릭이 다음과 같다고 해봅시다.
`CPU(cores) : 29m, MEMORY(bytes) : 1Mi`
- 파드는 29m이라는 부하를 받고 있습니다. 1개의 파드가 처리할 수 있는 부하는 10m이고,
CPU 부하량이 50%가 넘으면 추가 파드를 생성해야 하므로 부하가 5m이 넘으면 파드를 증설하게 돼 있습니다.
따라서 29m/5를 하고 올림하면 6이라는 숫자가 나옵니다. 결국 증가하는 파드의 수를 6입니다.
이때 부하 총량을 가지고 HPA가 작동하기 때문에 일부 파드는 5m을 넘을 수도 있습니다.
- 예를 들어 1개의 파드에서만 다음과 같이 부하(27m)가 발생한다면 해당 부하는 분산되지 않습니다.
따라서 부하 부산을 위해서는 쿠버네티스 서비스를 통해 파드 그룹인 디플로이먼트에 도달해야 합니다.
- `kubectl get hpa`를 실행하면 HPA의 현재 상태를 요약해서 보여줍니다.-
테스트를 위해 마스터 노드 창과 파워셸 창을 띄웁니다.
- 슈퍼푸티와 다르게 mac SSH Client에서는 다중 창을 지원하지 않기 때문에 불편하지만 하나의 마스터 노드 창에서 작업을 진행합니다.
- 마스터 노드 창에서는 호스트 컴퓨터에서 제공하는 부하를 출력하고(2초에 한번씩 자동으로 상태를 확인,
watch kubectl top pods,watch kubectl get pods) 파워셸은 HPA를 테스트합니다.
- 슈퍼푸티와 다르게 mac SSH Client에서는 다중 창을 지원하지 않기 때문에 불편하지만 하나의 마스터 노드 창에서 작업을 진행합니다.
-
HPA를 테스트하기 위해 반복문을 실행합니다. 부하를 주는 명령은 로드밸런서를 테스트 했던 코드와 동일합니다. 마스터 노드에서는 부하량을 감지하는지 확인합니다.
-
마스터 노드 :
watch kubectl top pods -
파워셸 :
$i=0; while($true) { % { $i++; write-host -NoNewline "$i $_" } (Invoke-RestMethod "http://192.168.1.11")-replace '\n', " " }

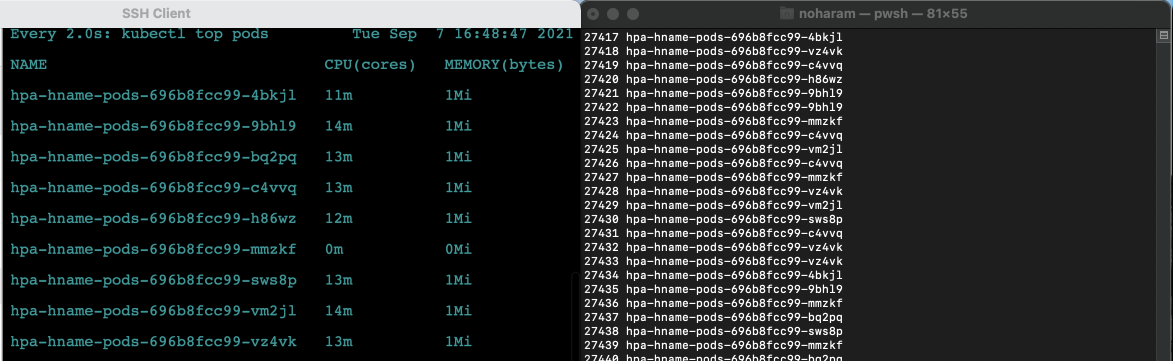
-
-
부하량이 늘어남에 따라 파드가 새로 생성되는지 확인합니다.
- 마스터 노드 : Ctrl+C로 빠져나온뒤(watch top pods 상태)
watch kubectl get pods실행
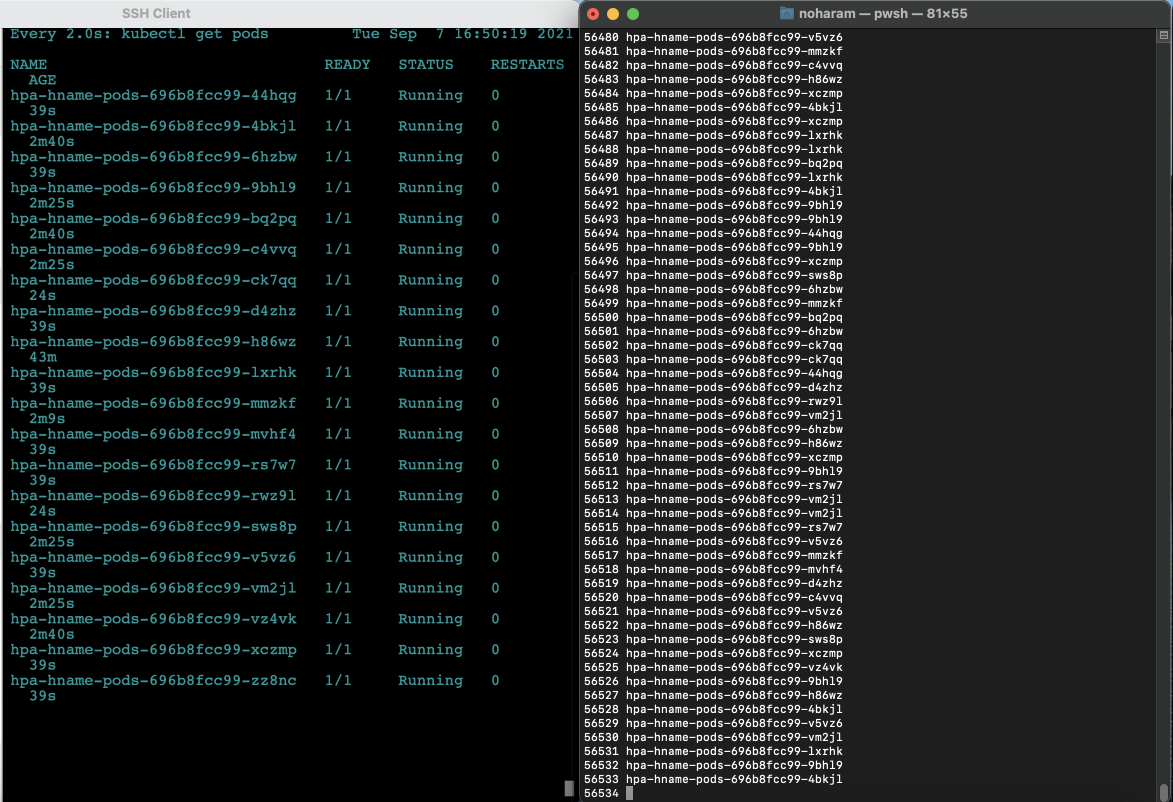
- 마스터 노드 : Ctrl+C로 빠져나온뒤(watch top pods 상태)
-
부하 분산으로 생성된 파드의 부하량이 증가하는지 확인합니다.
- 마스터 노드 : Ctrl+C로 빠져나온뒤(watch get pods 상태)
watch kubectl top pods실행

- 마스터 노드 : Ctrl+C로 빠져나온뒤(watch get pods 상태)
-
더 이상 파드가 새로 생성되지 않는 안정적인 상태가 되는 것을 확인하고(저는 파드가 21개가 되니 안정적인 상태가 되었습니다. 부하량은 대체로 5~6m입니다.) 부하를 생성하는 파워셸 창을 종료합니다.
- Ctrl+C 로 종료
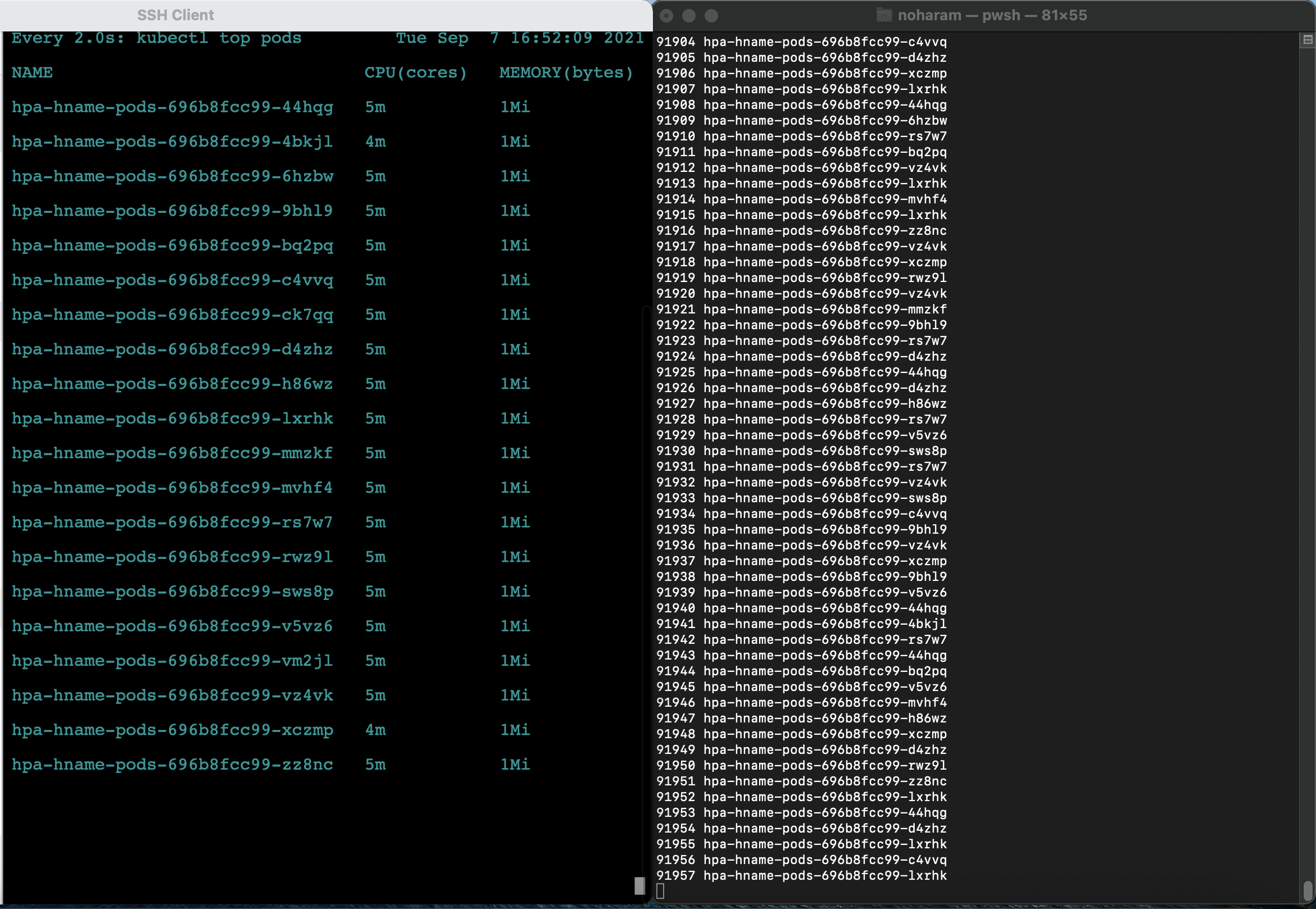
- Ctrl+C 로 종료
-
일정 시간이 지난 후 더 이상 부하가 없으면
autoscale의 최소 조건인 파드 1개의 상태로 돌아가기 위해 파드가 종료되는 것을 확인합니다. 이번에는 시간이 좀 더 걸립니다.watch kubectl get pods로 보면 Terminating 상태로 변하고 사라지는 것을 볼 수 있고,watch kubectl top pods를 보면 각 파드의 CPU 부하량이 바뀌고 삭제되는 것을 확인 할 수 있습니다.- 부하가 0m이 되는 모습
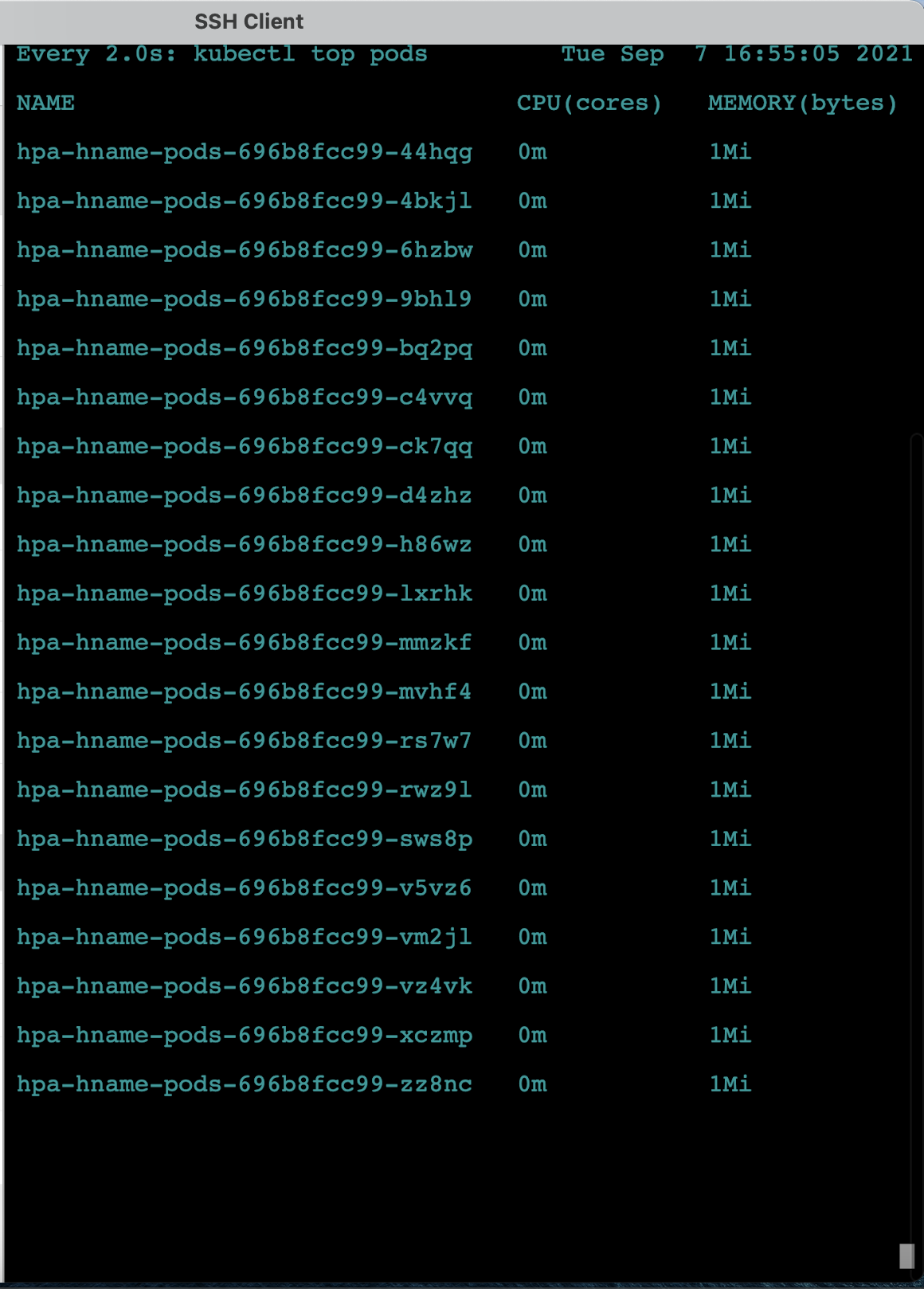
-
사용하지 않는 파드는 모두 종료되고 최솟값인 1개만 남습니다.

-
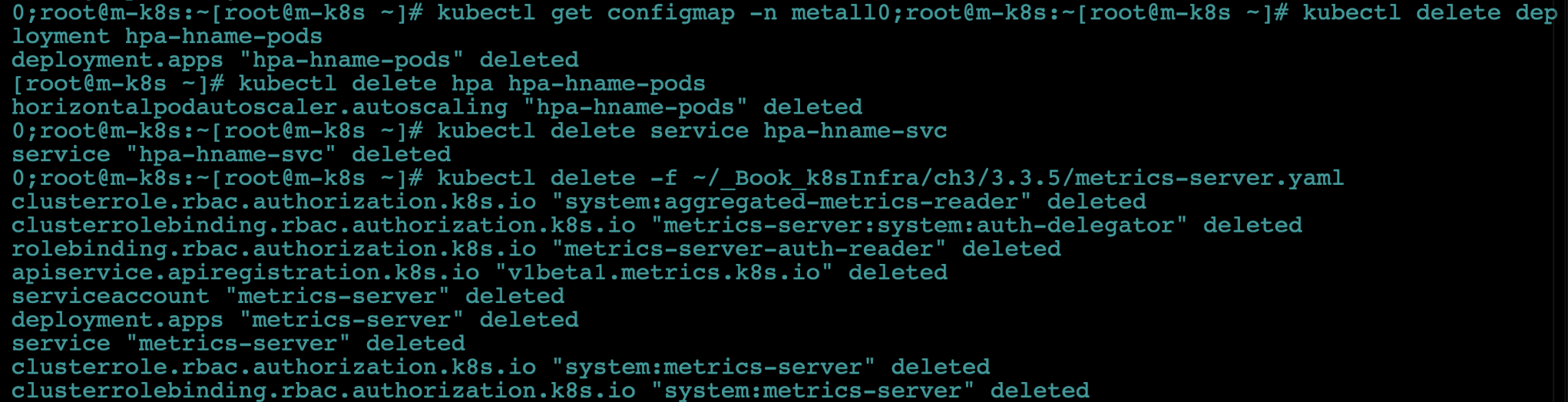
부하 테스트가 끝났습니다. 파드 부하량에 따라 HPA가 자동으로 파드 수를 조절하는 것을 확인했습니다. HPA를 잘 활용하면 자원의 사용을 극대화하면서 서비스 가동률을 높일 수 있습니다. 앞에서와 마찬가지로 생성한 디플로이먼트, 서비스, 메트릭 서버를 삭제합니다. MetalLB는 계속 사용하므로 삭제하지 않습니다.
kubectl delete deployment hpa-hname-podskubectl delete hpa hpa-hname-podskubectl delete service hpa-hname-svckubectl delete -f ~/_Book_k8sInfra/ch3/3.3.5/metrics-server.yaml
쿠버네티스에서 파드를 생성한 후에 실제로 쿠버네티스 외부의 사용자들이 쿠버네티스 내부에 있는 파드에 접속할 수 있도록 경로를 만들어주는 여러 가지 종류의 서비스들을 살펴봤습니다.
다음 포스팅에서는 마지막으로 디플로이먼트 외의 다른 오브젝트를 사용해 보겠습니다!
본 게시물은 "컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커 - 조훈,심근우,문성주 지음(2021)" 기반으로 작성되었습니다.
