쿠버네티스의 개념과 기본 사용법
컨테이너를 다루는 표준 아키텍처, 쿠버네티스
컨테이너 인프라 소개
앞의 포스트에서 배운 코드를 응용해 컨테이너 인프라 테스트 환경을 자동으로 구축해보겠습니다.
- 컨테이너란?
하나 이상의 목적을 위해 독립적으로 작동하는 프로세스
- 컨테이너 인프라 환경이란?
리눅스 운영 체제의 커널 하나에서 여러 개의 컨테이너가 격리된 상태로 실행되는 인프라 환경
개인 서버에서는 1명의 관리자가 다양한 응용프로그램을 사용하므로 각각의 프로그램을 컨테이너로 구현할 필요가 거의 없습니다.
기업 환경에서는 다수의 관리자가 수백 또는 수천 대의 서버를 함께 관리하기 때문에 일관성을 유지하는 것이 매우 중요합니다.
이런 경우 컨테이너 인프라 환경을 구성하면 눈송이 서버(여러 사람이 작업하여 설정의 일관성이 떨어진 서버)를 방지하는데 효과적입니다.
또한 가상화 환경에서는 각각의 가상 머신이 모두 독립적인 운영 체제 커널을 가지고 있어야 하기 때문에 자원을 더 소모해야하고 성능이 떨어지게 됩니다.
하지만 컨테이너 인프라 환경에서는 OS 커널 하나에 컨테이너 여러 개가 격리된 형태로 실행되기 때문에 자원을 효율적으로 사용할 수 있고 거치는 단계가 적어서 속도도 훨씬 빠릅니다.
- 쿠버네티스가 주목받은 이유
- 이미 가상화 환경에서 상용 솔루션(VMware)을 이용해 안정적으로 시스템 운용이 가능했고 관리되고 있었습니다.
- 시간이 지나 커널을 공유해 더 많은 애플리케이션을 올릴 수 있는 컨테이너가 도입되면서, 늘어난 컨테이너 관리의 필요성이 대두됩니다.
- 기존의 컨테이너 관리 솔루션(Docker Swarm, Mesos, Nomad 등)들은 현업의 요구 사항을 충족시키기에 부족한 점이 있었습니다.
- 그래서 컨테이너 인프라 환경이 주는 많은 잠점에도 불구하고 보편화되기가 어려웠습니다.
- 2014년, 구글이 쿠버네티스를 오픈소스화하면서 누구나 접근하기 용이해졌습니다. 이후 기능이 추가되면서 생태계가 풍부해졌고 컨테이너 인프라 관리 솔류션의 표준으로 자리 잡게 되었습니다.
쿠버네티스 이해하기
컨테이너 오케스트레이션 솔루션
-
도커 스웜(Docker Swarm)
- 간단한 설치, 사용의 용이함
- 기능이 다양하지 않아 대규모 환경에 적용하려면 사용자 환경 변경 필요
- 소규모 환경에서는 유용하다 -
메소스(Mesos)
- 아파치 오픈 소스 프로젝트 | 트위터, 에어비엔비, 애플, 우버 등에서 검증된 솔루션
- 2016년 DC/OS(Data Center OS, 대규모 서버 환경에서 자원을 유연하게 공유하며 하나의 자원처럼 관리하는 도구) 지원으로 매우 간결해졌다.
- 기능을 충분히 활용하려면 분산 관리 시스템과 연동이 필요하다.
- 따라서 여러가지 솔루션을 유기적으로 구성해야하는 부담이 있다. -
노매드(Nomad)
- 베이그런트를 만든 해시코프사의 컨테이너 오케스트레이션
- 간단한 구성으로 컨테이너 오케스트레이션 환경 제공
- 기능이 부족하므로 여러 기능을 사용하는 환경이 아닌 가볍고 간단한 기능만 필요한 환경에서 사용하기 권장됌
- 해시코프의 Consul(서비스 검생, 구성 및 분할 기능 제공)과 Vault(암호화 저장소)와의 연동이 원할하므로 이런 도구에 대한 사용 성숙도가 높은 조직이라면 도입을 고려해도 괜찮음 -
쿠버네티스(Kubernetes)
- 다른 솔루션보다 시작하는 데 어려움이 있지만, 쉽게 사용할 수 있는 도구들이 있어서 설치가 쉬워지는 추세
- 다양한 형태로 발전하고 있어 컨테이너 오케스트레이션을 넘어 IT 인프라 자체를 컨테이너화하고, 컨테이너화된 인프라 제품군을 쿠버네티스 위에서 동작할 수 있게 만든다.
- 거의 모든 벤더와 오픈 소스 진영에서 쿠버네티스를 지원하고 그에 맞게 통합 개발하고 있다. 그러므로 컨테이너 오케스트레이션을 학습/도입하려면 쿠버네티스를 우선적으로 고려한다. -
쿠버네티스 : 컨테이너 오케스트레이션을 위한 솔루션
- 오케스트레이션(Orchestration) : 복잡한 단계를 관리하고 요소들의 유기적인 관계를 미리 정의해 손쉽게 사용하도록 서비스를 제공하는 것
- 컨테이너 오케스트레이션 : 다수의 컨테이너를 유기적으로 연결/실행/종료할 뿐만 아니라 상태를 추적하고 보존하는 등 컨테이너를 안정적으로 사용할 수 있게 만들어 주는 것
쿠버네티스 구성 방법 - 3가지
관리형 쿠버네티스
퍼블릭 클라우드 업체에서 제공하는 관리형 쿠버네티스인 EKS(Amazon Elastic Kubernetes Service), AKS(Azure Kubernetes Service), GKE(Google Kubernetes Service) 등을 사용합니다.
- 구성이 이미 다 갖춰져 있고 마스터 노드를 클라우드 업체에서 관리하기 때문에 학습용으로는 적합하지 않습니다.
설치형 쿠버네티스
수세의 Rancher, 레드햇의 OpenShift와 같은 플랫폼에서 제공하는 설치형 쿠버네티스를 사용합니다.
- 유료여서 쉽게 접근하기 어렵습니다.
구성형 쿠버네티스
사용하는 시스템에 쿠버네티스 클러스터를 자동으로 구성해주는 솔루션을 사용합니다.
- 주요 솔루션으로는 kubeadm, kops(Kubernetes operations), KRIB(Kubernetes Rebar Integrated Bootstrap), Kuberspray가 있습니다.
- kubeadm이 가장 널리 알려져 있습니다.
* kubeadm은 사용자가 변경하기 수월하고 온프레미스(On-Premises)와 클라우드를 모두 지원하며, 배우기 쉽습니다.
쿠버네티스 구성하기
학습을 위해 사용자 설정이 가장 많이 필요한 kubeadam으로 쿠버네티스를 구성하겠습니다.
또한 쿠버네티스가 설치되는 서버 노드는 가상 머신을 이용해 실제 온프레미스에 가깝게 구성합니다.
설치되는 과정을 베이그런트로 자동화해 필요하면 쿠버네티스 테스트 환경을 재구성할 수 있게 합니다.
이전 포스팅에서 알아본 것과 같이 베이그런트는 가상 머신을 프로비저닝을 위해 여러 종류의 명령어를 제공합니다. 자주 사용하는 명령어는 추후 따로 포스팅하겠습니다.
- kubespary는 실제 업무 환경에서도 매우 편리하게 쿠버네티스 클러스터를 자동으로 배포할 수 있는 도구이므로 나중에 따로 포스팅하겠습니다.
베이그런트를 이용한 쿠버네티스 테스트 환경 구축
- 추후 학습의 편의를 위해 책의 저자가 준비해놓은 실습파일을 통해 진행합니다.
-
쿠버네티스 실습 환경을 만들어 줄 베이그런트 스크립트 파일과 실습에 사용할 소스코드 파일들을 내려받습니다. 깃허브 링크
- 저는 데스크탑에 k8s 폴더를 만들어 git clone을 진행했습니다. Code-Download ZIP을 눌러 내려받아서 사용하셔도 무방합니다.
-
ch3/3.1.3 폴더로 이동하여 실습에 필요한 파일이 있는지 확인합니다.
-
앞선 포스트와 같이 실습에 필요한 파일의 설명은 다음과 같습니다.
- Vagrantfile
- 베이그런트 프로비저닝을 위한 정보를 담고 있는 메인 파일
- 명령 프롬프트에서 Vagrantfile이 있는 경로에서
vagrant up을 하면 현재 호스트 내부에 Vagrantfile에 정의된 가상 머신들을 생성하고, 생성한 가상 머신에 쿠버네티스 클러스트를 구성하기 위한 파일들을 호출해 쿠버네티스 클러스터를 자동으로 구성합니다.
- Vagrantfile
-
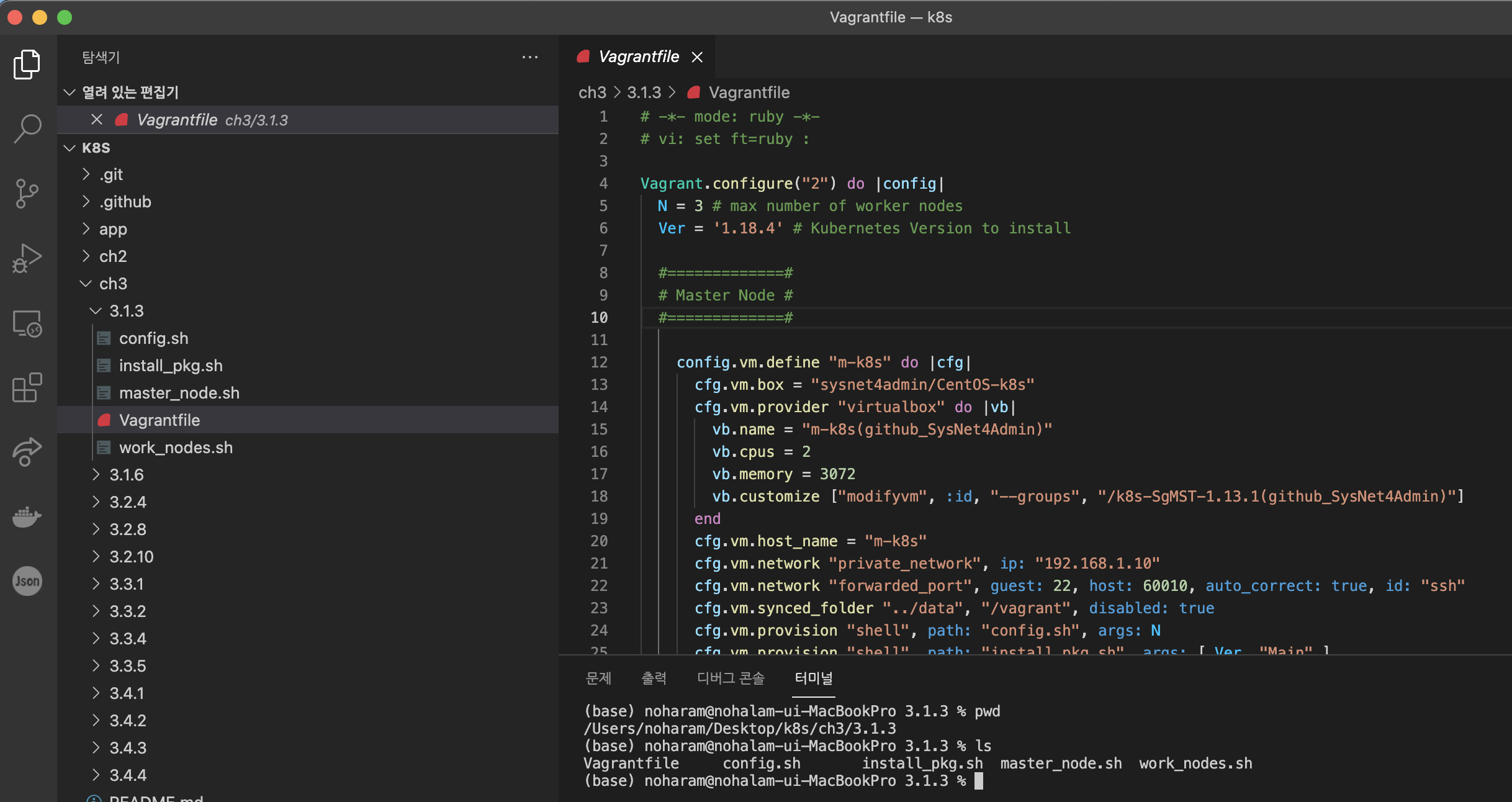
Vagrantfile의 구성을 살펴보겠습니다.
앞선 포스팅을 참고하며 각 행이 어떤 의미를 가지고 작성되어있는지 꼼꼼히 읽어봅시다. 이번엔 워커 노드 변수, 버전 변수, 마스터/워커 노드를 위한 provision, args의 존재 등이 추가되었군요!
또한 이전 포스팅과 달리 마스터/워커 노드의 메모리가 늘어난 부분도 확인할 수 있네요.
(1..N).each do |i| 반복문에서도 워커 개수 변수인 N의 수정을 통해 워커 노드의 개수를 손쉽게 변경할 수 있다는 점이 눈에 띄네요.
새로운 내용에는 주석을 작성해놓았습니다.
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
N = 3 # 쿠버네티스에서 작업을 수행할 워커 노드의 변수(N=3), (args:N)으로 config.sh로 넘긴다. 사용자가 워커 노드의 개수를 직접 조절할 수 있게 한다.
Ver = '1.18.4' # 쿠버네티스 버전을 사용하자 선택할 수 있도록 변수로 저장
#=============#
# Master Node #
#=============#
config.vm.define "m-k8s" do |cfg|
cfg.vm.box = "sysnet4admin/CentOS-k8s"
cfg.vm.provider "virtualbox" do |vb|
vb.name = "m-k8s(github_SysNet4Admin)"
vb.cpus = 2
vb.memory = 3072
vb.customize ["modifyvm", :id, "--groups", "/k8s-SgMST-1.13.1(github_SysNet4Admin)"]
end
cfg.vm.host_name = "m-k8s"
cfg.vm.network "private_network", ip: "192.168.1.10"
cfg.vm.network "forwarded_port", guest: 22, host: 60010, auto_correct: true, id: "ssh"
cfg.vm.synced_folder "../data", "/vagrant", disabled: true
cfg.vm.provision "shell", path: "config.sh", args: N
# args: [ Ver, "Main" ] 을 추가해 쿠버네티스 버전 정보(Ver)와 Main이라는 문자를 install_pkg.sh로 넘긴다. Ver 변수는 각 노드에 해당 버전의 쿠버네티스를 설치하게 한다. Main은 install_pkg.sh에서 조건문으로 처리해 마스터 노드에만 이 책의 전체 실행 코드를 내려받게 한다.
cfg.vm.provision "shell", path: "install_pkg.sh", args: [ Ver, "Main" ]
# 쿠버네티스 마스터 노드를 위한 master_node.sh를 추가한다.
cfg.vm.provision "shell", path: "master_node.sh"
end
#==============#
# Worker Nodes #
#==============#
(1..N).each do |i|
config.vm.define "w#{i}-k8s" do |cfg|
cfg.vm.box = "sysnet4admin/CentOS-k8s"
cfg.vm.provider "virtualbox" do |vb|
vb.name = "w#{i}-k8s(github_SysNet4Admin)"
vb.cpus = 1
vb.memory = 2560
vb.customize ["modifyvm", :id, "--groups", "/k8s-SgMST-1.13.1(github_SysNet4Admin)"]
end
cfg.vm.host_name = "w#{i}-k8s"
cfg.vm.network "private_network", ip: "192.168.1.10#{i}"
cfg.vm.network "forwarded_port", guest: 22, host: "6010#{i}", auto_correct: true, id: "ssh"
cfg.vm.synced_folder "../data", "/vagrant", disabled: true
cfg.vm.provision "shell", path: "config.sh", args: N
cfg.vm.provision "shell", path: "install_pkg.sh", args: Ver
# 쿠버네티스 워커 노드를 위한 worker_node.sh를 추가한다.
cfg.vm.provision "shell", path: "work_nodes.sh"
end
end
end- confis.sh를 살펴봅시다.
- kubeadm으로 쿠버네티스를 설치하기 위한 사전 조건을 설정하는 스크립트 파일입니다. 쿠버네티스의 노드가 되는 가상 머신에 어떤 값을 설정하는지 살펴봅시다.
#!/usr/bin/env bash
# vim configuration
# vi를 호출하면 vim을 호출하도록 프로파일에 입력합니다. vim을 통해 코드 하이라이트를 넣어 가독성을 높힐 수 있습니다.
echo 'alias vi=vim' >> /etc/profile
# 쿠버네티스의 설치 요구 조건을 맞추기 위해 스왑되지 않도록 설정합니다.
# swapoff -a to disable swapping
swapoff -a
# 시스템이 다시 시작되더라도 스왑되지 않도록 설정합니다.
# sed to comment the swap partition in /etc/fstab
sed -i.bak -r 's/(.+ swap .+)/#\1/' /etc/fstab
# kubernetes repo
# 쿠버네티스의 리포지터리를 설정하기 위한 경로가 너무 길어지지 않게 변수로 처리합니다.
gg_pkg="packages.cloud.google.com/yum/doc" # Due to shorten addr for key
# EOF ~ EOF : 쿠버네티스를 내려받을 리포지터리를 설정하는 구문입니다.
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://${gg_pkg}/yum-key.gpg https://${gg_pkg}/rpm-package-key.gpg
EOF
# selinux가 제한적으로 사용되지 않도록 permissive 모드로 변경합니다.
# Set SELinux in permissive mode (effectively disabling it)
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 브리지 네트워크를 통과하는 IPv4와 IPv6의 패킷을 iptables가 관리하게 설정합니다.
# 파드(Pod, 쿠버네티스에서 실행되는 객체의 최소 단위)의 통신을 iptables로 제어합니다. 필요에 따라 IPVS(Ip Virtual Server) 같은 방식으로도 구성할 수 있습니다.
# RHEL/CentOS 7 have reported traffic issues being routed incorrectly due to iptables bypassed(RHEL/CentOS 7은 우회된 iptables로 인해 잘못 라우팅되는 트래픽 문제를 보고했습니다.)
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# br_netfilter 커널 모듈을 사용해 브리지로 네트워크를 구성합니다. 이때 IP 마스커레이드(Masquerade)를 사용해 내부 네트워크와 외부 네트워크를 분리합니다.
# IP 마스커레이드는 쉽게 설명하면 커널에서 제공하는 NAT(네트워크 주소 변환) 기능으로 이해하면 됩니다.
# 실제로는 br_netfilter를 적용함으로써 앞서 적용한 iptables가 활성화됩니다.
modprobe br_netfilter
# 쿠버네티스 안에서 노드 간 통신을 이름으로 할 수 있도록 각 노드의 호스트 이름과 IP를 /etc/hosts에 설정합니다.
# 이떄 워커 노드는 Vagrantfile에서 넘겨받은 N변수로 전달된 노드 수에 맞게 동적으로 생성합니다.
# local small dns & vagrant cannot parse and delivery shell code.
echo "192.168.1.10 m-k8s" >> /etc/hosts
for (( i=1; i<=$1; i++ )); do echo "192.168.1.10$i w$i-k8s" >> /etc/hosts; done
# 외부와 통신할 수 있게 DNS 서버를 지정합니다.
# config DNS
cat <<EOF > /etc/resolv.conf
nameserver 1.1.1.1 #cloudflare DNS
nameserver 8.8.8.8 #Google DNS
EOF- install_pkg.sh를 살펴봅시다.
- 클러스터를 구성하기 위해서 가상 머신에 설치돼야 하는 의존성 패키지를 명시합니다.
- 실습에 필요한 소스 코드를 특정 가상 머신(m-k8s) 내부에 내려받도록 설정되어 있습니다.
#!/usr/bin/env bash
# install packages
yum install epel-release -y
yum install vim-enhanced -y
yum install git -y # 깃허브 이용을 위해 git을 설치합니다.
# install docker
# 쿠버네티스를 관리하는 컨테이너를 설치하기 위해 도커를 설치/구동합니다.
yum install docker -y && systemctl enable --now docker
# install kubernetes cluster
# 쿠버네티스를 구성하기 위해 첫 번째 변수($1=Ver='1.18.4')로 넘겨받은 1.18.4버전의
# kubectl, kubelet, kubeadm을 설치하고 kubelet을 시작합니다.
yum install kubectl-$1 kubelet-$1 kubeadm-$1 -y
systemctl enable --now kubelet
# git clone _Book_k8sInfra.git
# 이 책의 전체 실행 코드를 마스터 노드에만 내려받도록 Vagrantfile에서 두 번째 변수($2='Main')을 받습니다.
# 깃에서 코드를 clone하여 실습을 진행할 루트 홈디렉토리(/root)로 옮깁니다.
# 배시 스크립트(.sh)를 찾아서 바로 실행 가능한 상태가 되도록 chmod 700으로 설정합니다.
if [ $2 = 'Main' ]; then
git clone https://github.com/sysnet4admin/_Book_k8sInfra.git
mv /home/vagrant/_Book_k8sInfra $HOME
find $HOME/_Book_k8sInfra/ -regex ".*\.\(sh\)" -exec chmod 700 {} \;
fi- master_node.sh를 살펴봅시다.
- 1개의 가상 머신(m-k8s)을 쿠버네티스 마스터 노드로 구성하는 스크립트입니다.
- 쿠버네티스 클러스터를 구성할 때 꼭 선택해야 하는 컨테이너 네트워크 인터페이스(CNI, Container Network Interface)도 함께 구성합니다.
#!/usr/bin/env bash
# init kubernetes
# kubeadm을 통해 쿠버네티스의 워커 노드를 받아들일 준비를 합니다. 먼저 토큰을 임의로 지정하고
# ttl(time to live, 유지되는 시간)을 0으로 설정해서 기본값인 24시간 후에 토큰이 계속 유지되게 합니다.
# 워커 노드가 정해진 토큰으로 들어오게 합니다. 쿠버네티스가 자동으로 컨테이너에 부여하는 네트워크를
# 172.16.0.0/16(172.16.0.1~172.16.255.254)로 제공하고,
# 워커 노드가 접속하는 API 서버의 IP를 192.168.1.10으로 지정해 워커 노드들이 자동으로 API서버에 연결되게 합니다.
kubeadm init --token 123456.1234567890123456 --token-ttl 0 \
--pod-network-cidr=172.16.0.0/16 --apiserver-advertise-address=192.168.1.10
# config for master node only
# 마스터 노드에서 현재 사용자가 쿠버네티스를 정상적으로 구동할 수 있게 설정 파일을 루트의 홈디텍토리(/root)에 복사하고 쿠버네티스를 이용할 사용자에게 권한을 줍니다.
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# config for kubernetes's network
# 컨테이너 네트워크 인터페이스인 캘리코(Calico)의 설정을 적용해 쿠버네티스의 네트워크를 구성합니다.
kubectl apply -f \
https://raw.githubusercontent.com/sysnet4admin/IaC/master/manifests/172.16_net_calico.yaml- work_nodes.sh 를 살펴봅시다.
#!/usr/bin/env bash
# config for work_nodes only
# kubeadm을 이용해 쿠버네티스 마스터 노드에 접속합니다. 이 떄 연결에 필요한 토큰은 기존에 마스터 노드에서 생성한 임의의 토큰을 사용합니다.
# 간단하게 구성하기 위해 `--discovery-token-unsafe-skip-ca-verification`으로 인증을 무시하고
# API 서버 주소인 192.168.1.10으로 기보 포트 번호인 6443번 포트에 접속하도록 설정합니다.
kubeadm join --token 123456.1234567890123456 \
--discovery-token-unsafe-skip-ca-verification 192.168.1.10:6443- 쿠버네티스를 구성하는 데 필요한 파일들을 살펴봤으니 구성 과정으로 돌아갑시다.
- 명령 프롬프트를 열고 쿠버네티스 설치 파일이 있는 디렉토리로 이동합니다.
- vagrant up 명령을 실행합니다. 쿠버네티스 클러스터가 자동으로 구성됩니다.
cd /Users/noharam/Desktop/k8s/ch3/3.1.3 vagrant up- 저번 포스팅에서 생성했던 가상머신이 남아있으면 오류가 발생합니다. Virtualbox에서 모두 삭제해줍시다.(우클릭 후 삭제)
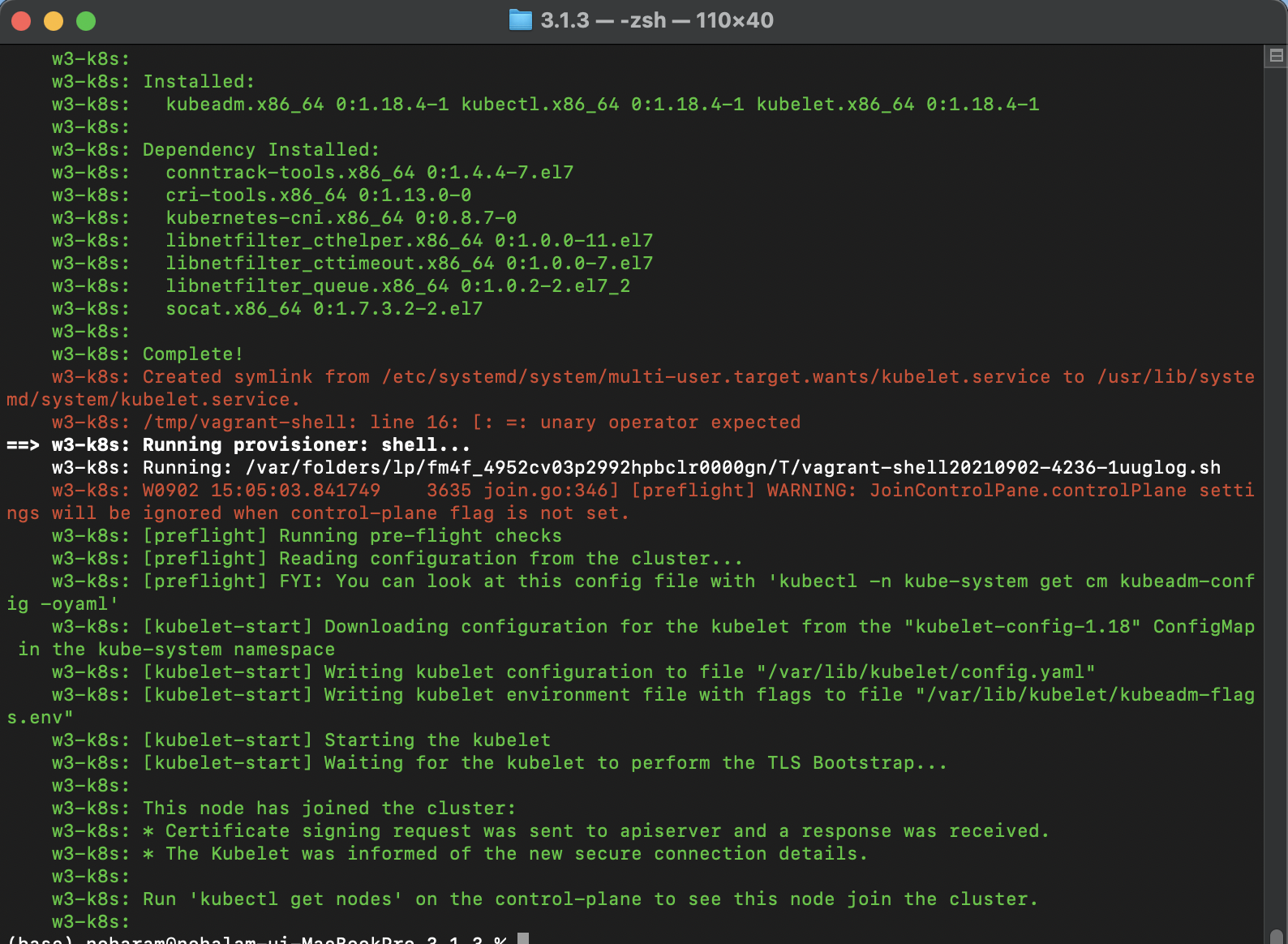
- 명령 프롬프트에서 쿠버네티스 클러스터가 정상적으로 구성되는지 확인하고, Virtualbox에서도 모두 정상적으로 뜨는지 확인합니다.
* 중간중간 몇 가지 에러가 발생하긴 하는데 일단 진행해보겠습니다.
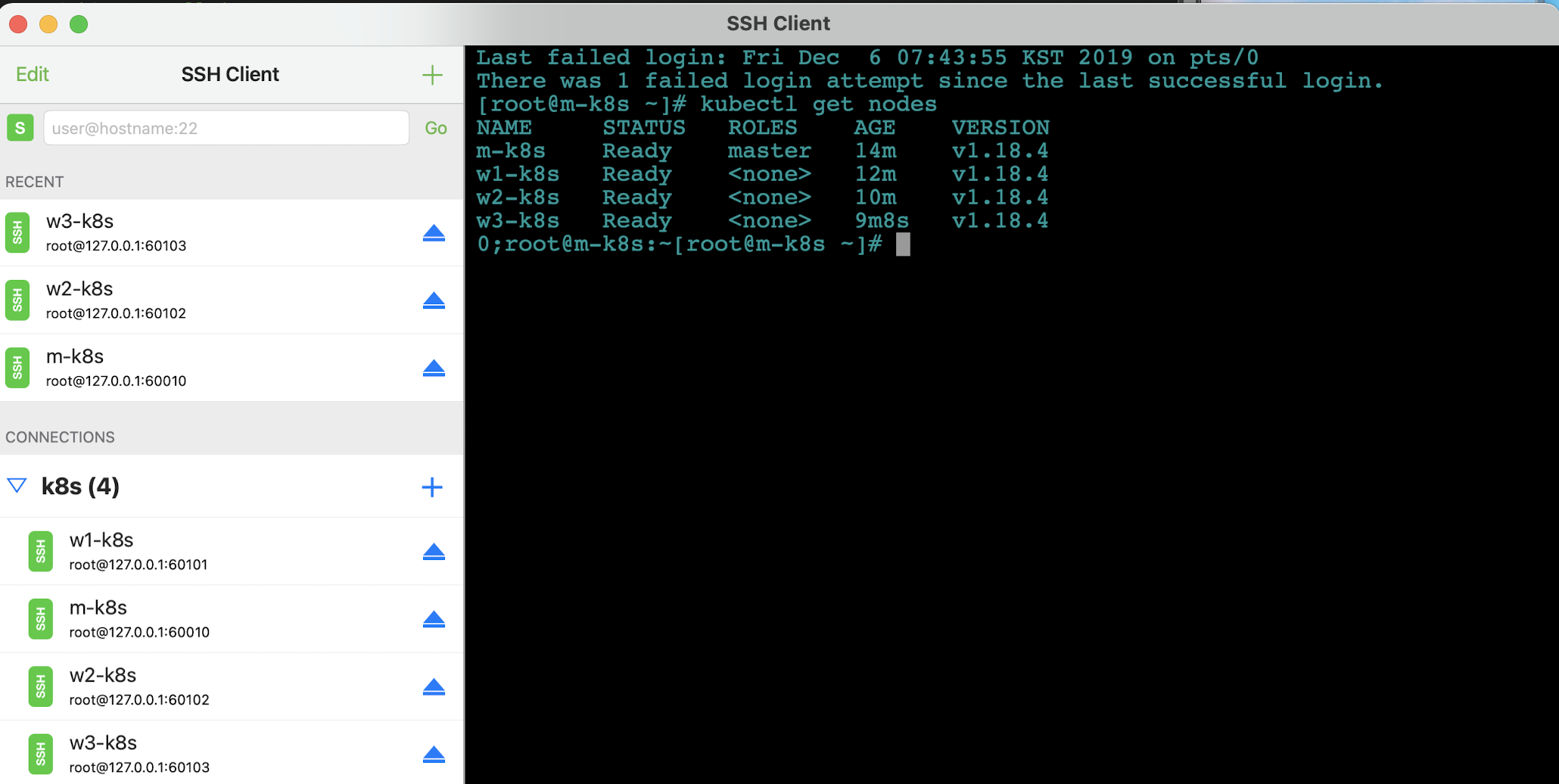
- 클러스터가 모두 구성되면 SSH CLIENT를 열고 세션 창에서
m-k8s를 선택해 터미널에 접속합니다.(이전 포스팅에서 진행했듯이) kubectl get nodes명령을 입력하여 쿠버네티스 클러스터에 마스터 노드와 워커 노드들이 정상적으로 생성되고 연결됐는지 확인합니다.
이렇게 쿠버네티스 클러스터 구성이 끝났습니다. 이제 쿠버네티스를 구성하는 요소를 살펴보면서 쿠버네티스의 개념과 용어를 알아봅시다.
파드 배포를 중심으로 쿠버네티스 구성 요소 살펴보기
앞에 나온 kubectl, kubelet, API 서버, Calico 등은 모두 쿠버네티스 클러스터를 이루는 구성 요소입니다.
그 외에 etcd, 컨트로럴 매니저, 스케쥴러, kube-proxy, 컨테이너 런타임, 파트 등이 있습니다.
각 요소가 어떤 역할을 담당하는지 차근차근 알아봅시다.
우선 설치된 쿠버네티스 구성 요소를 kubectl get pods --all-namespaces 명령으로 확인해봅시다.
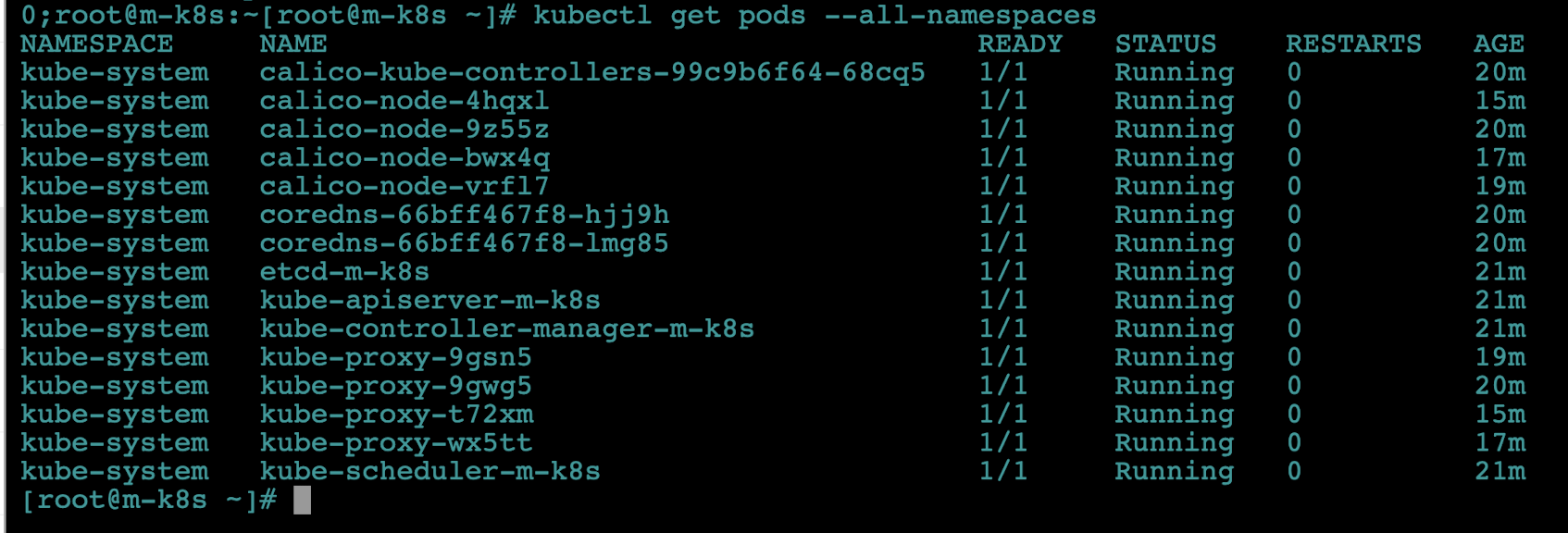
모든 네임스페이스에서 파드를 수집해 보여줍니다. 쿠버네티스 클러스터를 이루는 구성요소들은 파드 형태로 이루어져 있음을 알 수 있습니다.
- --all-namespaces는 기본 네임스페이스인 default를 제외한 모든 것을 표시한다는 의미입니다. 추후에 네임스페이스에 대해 더 자세히 포스팅하겠습니다.
쿠버네티스 구성 요소의 이름 생성 규칙
-
쿠버네티스의 구성 요소는 동시에 여러 개가 존재하는 경우 중복되 이름을 피하려고 뒤에 Hash 코드가 상비됩니다. 해시 코드는 무작위 문자열로 생성됩니다.
-
구성 요소의 이름을 직접 지정할 수도 있지만, 언제라도 문제가 발견되면 다시 생성되는 특성을 가지는 파드로 이루어져 있어서 자동으로 이름을 지정하는 것이 관리하기 쉽습니다.
-
coredns에는 중간에 66bff467f8이라는 문자열이 하나 더 있는데, 이는 레플리카셋(ReplicaSet)을 무작위 문자열로 변형해 추가한 것입니다. 추후에 네임스페이스와 같이 포스팅 하겠습니다.
관리자나 개발자가 파드를 배포할 때
쿠버네티스의 구성 요소의 유기적인 연결 관계를 표헌하면 다음과 같습니다.(출처 : 컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커 - 조훈,심근우,문성주 지음(2021)")

통신 순서를 따라가며 흐름을 이해하고, 각각의 기능을 파악해봅시다.
파드를 배포하는 순서에 따라 요소들의 역할을 정리해보겠습니다.
마스터 노드
0. Kubectl
- 쿠버네티스 클러스터에 명령을 내리는 역할.
- 다른 구성 요소들과 다르게 바로 실행되는 명령 형태인 바이너리(binary)로 배포되기 때문에 마스터 노드에 있을 필요는 없다.
- 통상적으로 API 서버와 주로 통신하므로 이 책에서는 API 서버가 위치한 마스터 노드에 구성되었다.
1. API 서버
- 쿠버네티스 클러스트의 중심 역할을 하는 통로
- 주로 상태 값을 저장하는 etcd와 통신
- 그 밖의 요소들도 API 서버를 중심에 두고 통신하므로 역할이 매우 중요
- 회사에 비유하면 모든 직원과 상황을 관리하고 목표를 설정하는 관리자에 대항
2. etcd
- 구성 요소들의 상태 값이 모두 저장되는 곳
- 회사에 비유하면 관리자가 모든 보고 내용을 기록하는 노트(ERP랄까)
- 실제로 etcd 외의 다른 구성 요소는 상태 값을 관리하지 않음
- etcd의 정보만 백업되어 있다면 긴급한 장애 상황에서도 쿠버네티스 클러스터는 복구할 수 있다.
- etcd는 분산 저장이 가능한 Key-Value 저장소이므로, 복제해 여러 곳에 저장해 두면 하나의 etcd에서 장애가 나타나고 시스템의 가용성 확보 가능
- 이와 같은 멀티 마스터 노드 형태는 부록에서 kubespray로 구성(추후 포스팅)
* etcd의 의미 : etcd는 약어가 아닙니다. 리눅스의 구성 정보를 주로 가지고 있는 etc 디렉터리와 distributed(퍼뜨렸다)의 합성어입니다. 구성 정보를 퍼뜨려 저장하겠다는 의미.
3. 컨트롤러 매니저
- 쿠버네티스 클러스터의 오브젝트 상태를 관리
- 예를 들어, 워커 노드에서 통신이 되지 않는 경우, 상태 체크와 복구는 쿠버네티스 클러스터에 속한 노드 컨트롤러에서 이루어진다.
- 다른 예로, 레플리카셋 컨트롤러는 레플리카셋에 요청받은 파드 개수대로 파드를 생성한다.
- 뒤에 나오는 서비스와 파드를 연결하는 역할을 하는 엔드포인터 컨트롤러 또한 컨트롤러 매니저
- 이와 같이 다양한 상태 값을 관리하는 주체들이 컨트롤러 매니저에 소속돼 각자의 역할을 수행한다.
4. 스케쥴러
- 노드의 상태와 자원, 레이블, 요구 조건 등을 고려해 파드를 어떤 워커 노드에 생성할 것인지를 결정하고 할당
- 스케줄러라는 이름에 걸맞게 파드를 조건에 맞는 워커 노드에 지정하고, 파드가 워커 노드에 할당되는 일정을 관리하는 역할을 담당
워커 노드
5. kubelet
- 파드의 구성 내용(PodSpec)을 받아서 컨테이너 런타임으로 전달하고, 파드 안의 컨테이너들이 정상적으로 작동하는지 모니터링
6. 컨테이너 런타임(CRI, Container Runtime Interface)
- 파드를 이루는 컨테이너의 실행을 담당
- 파드 안에서 다양한 종류의 컨테이너가 문제없이 작동하게 만드는 표준 인터페이스
7. 파드(Pod)
- 한 개 이상의 컨테이너로 단일 목적의 일을 하기 위해서 모인 단위
- 웹 서버 역할(Nginx 등)을 할 수도 있고, 로그나 데이터 분석을 할 수도 있다.
- 파드는 언제라도 죽을 수 있는 존재이다. -> 쿠버네티스를 처음 배울 때 가장 이해하기 어려운 부분
- 가상 머신은 언제라도 죽을 수 있다고 가정하고 디자인하지 않지만, 파드는 언제라도 죽을 수 있다고 가정하고 설계됐기 때문에 쿠버네티스는 여러 대안을 디자인했다. 추후 여러 테스트를 통해 같이 이해해봅시다.
선택 가능한 구성 요소
0~7번은 기본 설정으로 배포된 쿠버네티스에서 이루어지는 통신 단계를 구분한 것입니다. 이외에 선택적으로 배포하는 것들은 순서와 상관이 없기 때문에 10번대로 구분하여 표시합니다. 선택 가능한 부가 요소는 너무 깊은 내용이라 간단하게 개념만 살펴보고 넘어갑니다.
11. 네트워크 플러그인
- 쿠버네티스 클러스터의 통신을 위해서 네트워크 플러그인을 선택하고 구성해야 한다.
- 일반적으로 CNI(Container Network Interface)로 구성하는데, 주로 사용하는 CNI에는 캘리코(Calico), 플래널(Flannel), 실리움(Cilium), 큐브 라우터(Kube-router), 로마나(Romana), 위브넷(WeaveNet), Canal이 있다.
12. CoreDNS
- 클라우드 네이티브 컴퓨팅 재단에서 보증하는 프로젝트
- 빠르고 유연한 DNS 서버, 쿠버네티스 클러스터에서 도메인 이름을 이용해 통신하는데 사용
- 실무에서 쿠버네티스 클러스터를 구성하여 사용할 때는 IP보다 도메인 네임을 편리하게 관리해주는 CoreDNS를 사용하는 것이 일반적
- 쿠버네티스 클러스터를 구성하여 배포할 때 IP를 알려주는게 아닌 CoreDNS를 통해 구성한 도메인 네임으로 통신하게 하기!- 자세한 내용은 여기
사용자가 배포된 파드에 접속할 때
이번엔 파드가 배포된 이후 사용자 입장에서 배포된 파드에 접속하는 과정을 살펴봅시다.
- kube-proxy
- 쿠버네티스 클러스터는 파드에 위치한 노드에 kube-proxy를 통해 파드가 통신할 수 있는 네트워크를 설정
- 이때 실제 통신은 br_netfilter와 iptabels로 관리한다.
- 두 기능은 Vagrantfile에서 호출하는 config.sh 코드 설명을 참조
- 파드
- 이미 배포된 파드에 접속하고 필요한 내용을 전달받는다.
- 대부분의 사용자는 파드가 어느 워커 노드에 위치하는지 신경 쓰지 않아도 된다.
쿠버네티스의 각 구성 요소를 파드의 배포와 접속 관점에서 설명했지만, 아직 이해되지 않는 부분이 많습니다. 파드가 배포되는 과정을 살펴보며 구성 요소를 좀 더 깊이 알아봅시다.
파드의 생명주기로 쿠버네티스 구성 요소 살펴보기
구성 요소의 기능만 나열해서는 이해하기 어려우니 파드가 배포되는 과정을 하나하나 자세히 살펴보며 역할을 정리해봅시다.
쿠버네티스의 가장 큰 강점은 구성 요소마다 하는 일이 명확하게 구분돼 각자의 역할만 충실하게 수행하면 클러스터 시스템이 안정적으로 운영된다는 점입니다.
각자의 역할이 명확하게 나뉘어진 것은 마이크로서비스 아키텍쳐(MSA) 구조와도 밀접하게 연관됩니다.
또한 문제가 발생했을 때 어느 구성 요소에서 문제가 발생했는지 디버깅하기 쉽습니다.
생명주기(Life Cycle)은 파드가 생성, 수정, 삭제되는 과정을 나타냅니다.
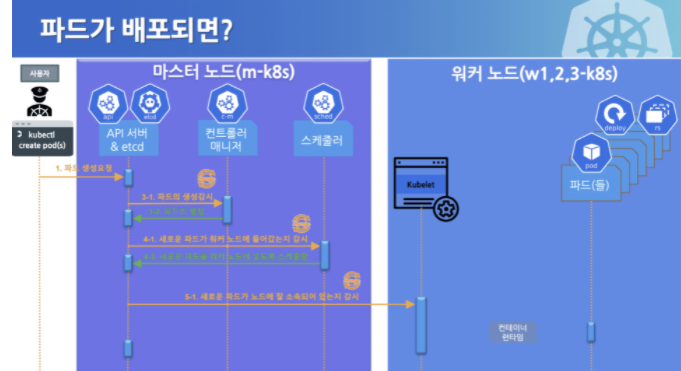
- kubectl을 통해 API 서버에 파드 생성 요청
kubectl create pod - (업데이트가 있을 때 마다 매번) API 서버에 전단될 내용이 있으면 API 서버는 etcd에 전달된 내용을 모두 기록해 클러스터의 상태 값을 최신으로 유지, 각 요소가 상태를 업데이트 할 때마다 모두 API서버를 통해 etcd에 기록됌
- API서버에 파드 생성이 요청된 것을 컨트롤러 매니저가 인지하면 컨트럴라 매니저가 파드를 생성하고, 이 상태(생성했다!)를 API 서버에 전달. 참고로 아직 어떤 워커 노드에 파드를 적용할지는 결정되지 않은 상태로 파드만 생성됌.
- API 서버에 파드에 생성됐다는 정보를 스케줄러가 인지함. 스케쥴러는 생성된 파드를 어떤 워커 노드에 적용할지 조건을 고려해 결정하고 해당 워커 노드에 파드를 띄우도록 요청(API 서버에 요청)
- API 서버에 전달된 정보대로 지정한 워커 노드에 파드가 속해있는지 스케줄러가 kubelet으로 확인(내 말대로 잘 띄웠니?)
- kubelet에서 컨테이너 런타임으로 파드 생성을 요청
- 파드가 생성됌
- 파드가 사용가능한 상태가 됌
- "API 서버는 감시만 하는걸까?" : 쿠버네티스를 이해하는데 매우 중요한 부분입니다.
- 쿠버네티스는 작업을 순서대로 진행하는 워크플로(workflow, 작업 잘차) 구조가 아니라 선언적인(declarative) 시스템 구조를 가지고 있습니다.
- 즉, 각 요소가 추구하는 상태(desired status)를 선언하면 현재 상태(current status)와 맞는지 점검하고 그게 맞추려고 노력하는 구조로 되어 있습니다.
- 따라서 각 요소가 추구하는 상태를 API 서버에 선언하면 다른 요소들이 API 서버에 와서 현재 상태와 비교하고 그에 맞게 상태를 변경하려고 합니다.
- 여기서 API는 현재 상태 값을 가지고 있는데 이것을 보존하기 위해 etcd가 필요합니다.(API와 etcd는 한몸처럼 움직이도록 설계되어 있습니다)
- 다만, 워커 노드는 워크플로 구조에 따라 설계됐습니다. 쿠버네티스가 kubelet과 컨테이너 런타임을 통해 파드를 생성하고 제거하는 구조여서 선언적인 방식으로 구조화하기에는 어려움이 있기 때문입니다.
- 또한 명령이 절차적으로 전달되는 방식은 시스템의 성능을 높이는 데 효율적입니다. 하지만 마스터 노드는 이미 생성된 파드들을 유기적으로 연결하므로 쿠버네티스 클러스터를 안정적으로 유지하려면 선언적인 시스템이 더 낫습니다.
쿠버네티스 구성 요소의 기능 검증하기
Kubectl
앞서 kubectl은 마스터 노드에 위치할 필요가 없다고 했습니다. 실제로 쿠버네티스 클러스터 외부에서 쿠버네티스 클러스터에 명령을 내릴 수도 있습니다. 어느 곳에서든지 kubectl을 실행하려면 어떤 부분이 필요한지 봅시다.
-
SSH CLIENT 세션 창에서 w3-k8s를 더블클릭해 터미널에 접속해서
kubectl get nodes를 실행합시다.

-
명령을 실행해도 쿠버네티스의 노드들에 대한 정보가 표시되지 않습니다.
- 쿠버네티스 클러스터의 정보를 kubectl이 알지 못하기 때문입니다.
- 파드 생명주기로 쿠버네티스 구성 요소 살펴보기를 보면 kubectl은 API 서버를 통해 쿠버네티스에 명령을 내립니다. 따라서 kubectl이 어디에 있더라도 API 서버의 접속 정보만 있다면 어느 곳에서든 쿠버네티스 클러스터에 명령을 내릴 수 있습니다.
-
쿠버네티스 클러스터의 정보(/etc/kubernetes/admin.conf)를 마스터 노드에서 scp(secure copy) 명령으로 w3-k8s의 현재 디렉토리(.)에 받아옵니다.
- 이때 접속 기록이 없기 때문에 known_hosts로 저장하도록 yes를 입력합니다. 마스터 노의 접속 암호인 vagrant도 입력합니다.
scp root@192.168.1.10:/etc/kubernetes/admin.conf .

-
kubectl get nodes에 쿠버네티스 클러스터 정보를 입력받는 옵션(--kubeconfig)과 마스터 노드에서 받아온 admin.conf를 입력하고 실행해봅시다.kubectl get nodes --kubeconfig admin.conf

노드 정보가 정상적으로 표시됩니다. kubectl을 실행하려면 무엇이 필요한지 확인했습니다.
kubelet
kubelet은 쿠버네티스에서 파드의 생성과 상태 관리 및 복구 등을 담당하는 매우 중요한 구성 요소입니다. 따라서 kubelet에 문제가 생기면 파드는 정상적으로 관리되지 않습니다.
- 기능을 검증하려면 실제로 파드를 배포해야 합니다.
- m-k8s에서
kubectl create -f ~/_Book_k8sInfra/ch3/3.1.6/nginx-pod.yaml명령으로 nginx 웹 서버 파드를 배포합니다.

- m-k8s에서
kubectl get pod명령으로 배포된 파드가 정상적으로 배포된 상태(Running)인지 확인합니다.

kubectl get pods -o wide명령을 실행해 파드가 배포된 워커 노드를 확인합니다.- -o 옵션 : output, 특정 형식으로 출력
- wide : 출력 정보를 더 많이 표시

- 배포된 노드인 w1-k8s에 접속해
systemctl stop kubelet으로 kubelet 서비스를 멉춥니다.

- m-k8s에서
kubectl get pod으로 상태를 확인하고kubectl delete pod nginx-pod명령으로 파드를 삭제합니다.


- 명령창에 아무런 변화가 없습니다. Ctrl+C를 눌러 명령을 중지합니다.

- 다시
kubectl get pod명령으로 파드의 상태를 확인합니다. 결과를 보면 nginx-pod를 삭제(Termination)하고 있습니다. 하지만 kubelet 서비스가 작동하지 않는 상태라 파드는 삭제되지 않습니다.
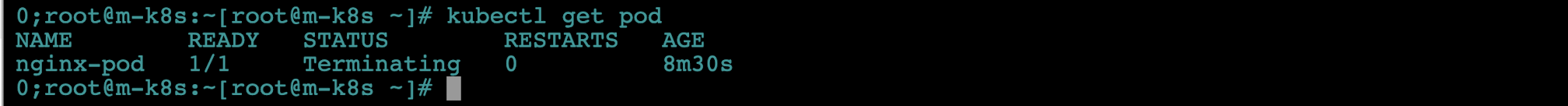
- kubelet에 문제가 생기면 파드가 정상적으로 관리되지 않는다는 사실을 확인했으니 w1-k8s에서
systemctl start kubelet을 실행해 kubelet을 복구합니다.

- 잠시 후에 m-k8s에서
kubectl get pod명령으로 nginx-pod가 삭제됐는지 확인합니다.

kube-proxy
kubelet이 파드의 상태를 관리한다면 kube-proxy는 파드의 통신을 담당합니다. 앞서 config.sh 파일에서 br_netfilter 커널 모듈을 적재하고 iptables를 거쳐 통신하도록 설정했습니다.
그런데 이 설정이 정상적으로 작동하지 않는다면, 즉 kube-proxy에 문제가 생기면 어떻게 되는지 확인해봅시다.
-
테스트하기 위해 m-k8s에 다시 파드를 배포합니다.
kubectl create -f ~/_Book_k8sInfra/ch3/3.1.6/nginx-pod.yaml
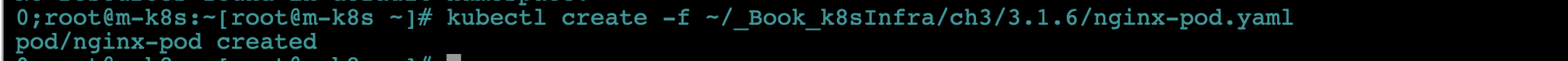
-
kubectl get pods -o wide명령을 실행해 IP와 파드가 배포된 워커 노드를 확인합니다.- 이번에는 w2-k8s로 배포되었군요. 아까 설명했듯이 스케줄러에 의해 파드는 임의의 워커 노드에 배정됩니다.

- 이번에는 w2-k8s로 배포되었군요. 아까 설명했듯이 스케줄러에 의해 파드는 임의의 워커 노드에 배정됩니다.
-
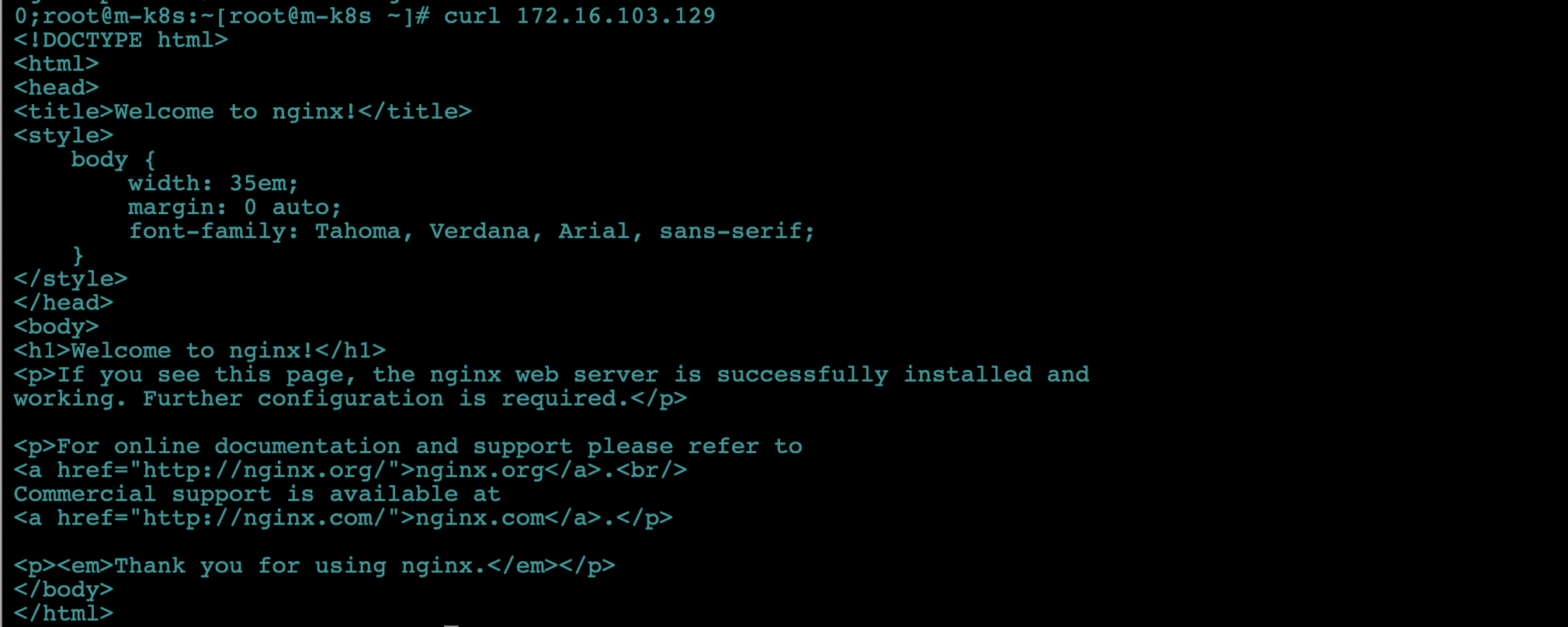
curl(client URL)로 전 단계에서 확인한 파드의 IP로 nginx 웹 서버 메인 페이지 내용을 확인합니다.
curl 172.16.103.129
-
w2-k8s 터미널에서
modprobe -r br_netfilter명령으로 파드가 위치한 워커 노드에서 br_netfilter 모듈을 제거합니다.- -r 옵션 : remove
- 그리고 네트워크를 다시 시작해 변경된 내용을 적용합니다. 이렇게 kube-proxy에 문제가 생기는 상황을 만듭니다.

-
다시 m-k8s에서 curl로 nginx 웹 서버의 정보를 받아옵니다. 계속 파드에서 정보를 받아오지 못하는 상태라면 Ctrl+C로 요청을 종료합니다.

-
kubectl get pod -o wide로 파드 상태를 확인합니다.

- 파드의 노드 위치(w2-k8s)와 IP(172.16.103.129)가 변경되진 않았는지, 작동상태(Running)엔 문제가 없는지 확인합니다.
- kube-proxy가 이용하는 netfilter에 문제가 있어서 nginx 웹 서버와의 통신만이 정상적으로 이루어지지 않는 상태인 것을 확인했습니다.
-
정상적으로 파드의 nginx 웹 서버 페이지 정보를 받아올 수 있는 상태로 만들어 봅시다. 워커 노드에서
modprobe br_netfilter명령을 실행해 br_netfilter를 커널에 적재하고 시스템을 재시작해서 적용합니다.modprobe br_netfilterreboot- (mac)SSH CLIENT 프로그램에서는 결재 광고가 나와서 그런지 자동으로 재시작되지는 않습니다. 다시 세션에서 w2-k8s를 더블클릭해서 접속해주세요.
-
일정 시간이 지난 후 다시 마스터 노드에서 파드의 상태를 확인하면 파드가 1회 다시 시작했다는 의미로 RESTARTS가 1로 증가하고 IP가 변경된 것을 확인할 수 있습니다.

-
바뀐 IP로 curl 명령을 실행해 파드로부터 정보를 정상적으로 받아오는지 확인합니다.

-
다음 내용을 진행하기 위해 배포한 파드를 삭제합니다.
kubectl delete -f ~/_Book_k8sInfra/ch3/3.1.6/nginx-pod.yaml

쿠버네티스의 기본 사용법 배우기!
파드를 생성하는 방법
쿠버네티스를 사용한다는 것은 결국 사용자에게 효과적으로 파드를 제공한다는 뜻입니다.
따라서 가장 먼저 파드를 생성해 봅시다.
이미 구성 요소 검증 파트에서 nginx 웹 서버 파드를 생성하고 삭제해봤습니다.
그러나 방법이 조금 복잡했습니다. 더 간단하게 생성하는 방법을 알아봅시다.
-
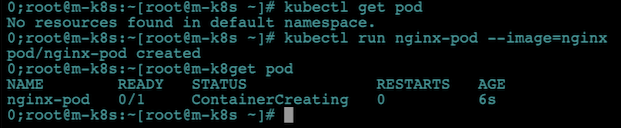
kubelet run을 실행하면 쉽게 파드를 생성할 수 있습니다.
run 다음에 나올 nginx는 파드의 이름이고, --image=nginx는 생성할 이미지의 이름입니다.
kubectl run nginx-pod --image=nginx
-
그렇다면 왜
kubectl create라는 명령어를 사용할까요? create로 파드를 생성해서 run 방식과 비교해봅시다!

--image 라는 옵션이 없다는 에러 메세지만 나오고 파드는 생성되지 않습니다. create로 파드를 생성하려면 deployment를 추가해서 실행해야 합니다. 이때 기존 파드 이름과 중복을 피하고자 파드의 이름을 dpy-nginx로 지정해 생성합니다.kubectl create deployment dpy-nginx --image=nginx

-
생성된 파드의 이름을 확인해봅시다.
dpy-nginx-c8d778df-gnqzh
이름에서 dpy-nginx를 제외한 나머지 부분은 무작위로 생성됩니다.(위의 쿠버네티스 구성 요소의 이름 생성 규칙을 참고해주세요!) -
두 가지 방식으로 생선한 파드가 모두 제대로 돌아가는지 확인해봅시다. IP를 확인해봅시다.
kubectl get pods -o wide

- 각 파드에서 curl 명령을 실행해 웹 페이지 정보를 잘 받아오는지 확인합니다.
curl 172.16.103.131
curl 172.16.132.1


-
두 방식 모두 nginx 웹 서버가 정삭적으로 작동합니다. 그렇다면 run과 create deployment로 생성한 파드엔 무슨 차이가 있을까요?
- run으로 파드를 생성하면 단일 파드 1개만 생성되고 관리됩니다.
- create deployment로 파드를 생성하면 디플로이먼트(Deployment)라는 관리 그룹 내에서 파드가 생성됩니다.
- 비유하자면 run은 초코파이 1개이고, create deployment는 초코파이 상자 안에 들어있는 초코파이 1개입니다.
이제 파드와 디플로이먼트가 어떻게 구성되어 있는지, 디플로이먼트는 파드를 어떻게 관리하는지 알아봅시다!
- 쿠버네티스 1.18 버전 이후부터는
run의 사용을 권고하지 않으며, create 혹은 run --generator=run-pod/v1을 사용하도록 권장됩니다.(예시입니다. 실행하지 않으셔도 됩니다.)
-kubectl create deployment nginx-create --image=nginxkubectl run nginx-run --image=nginx --generator=run-pod/v1
오브젝트란
파드와 디플로이먼트는 스펙(spec)과 상태(status) 등의 값을 가지고 있습니다.
이러한 값을 가지고 있는 파드와 디플로이먼트를 개별 속성을 포함해 부르는 단위를 오브젝트(object)라고 합니다.
쿠버네티스는 여러 유형의 오브젝트를 제공하는데, 기본 오브젝트부터 살펴봅시다.
기본 오브젝트
기본 오브젝트에는 다음 네 가지가 있습니다.
-
파드(Pod)
- 쿠버네티스에서 실행되는 최소 단위(웹 서비스를 구동하는데 필요한 최소 단위)
- 독립적인 공간과 사용 가능한 IP를 가진다
- 하나의 파드는 1개 이상이 컨테이너를 가지기 때문에 여러 기능을 묶어 하나의 목적으로 사용할 수도 있다.
- 범용으로 사용할 때는 대부분 1개의 파드에 1개의 컨테이너를 적용한다.
-
네임스페이스(Namespaces)
- 쿠버네티스 클러스터에 사용되는 리소스들을 구분해 관리하는 그룹
- 이번 포스팅엔 3가지 네임스페이스를 사용한다. 특별히 지정하지 않으면 기본으로 할당되는 default, 쿠버네티스 시스템에 사용되는 kube-system, 온프레미스에서 쿠버네티스를 사용할 경우 외부에서 쿠버네티스 클러스터 내부로 접속하게 도와주는 컨테이너들이 속해 있는 metallb-system이 있다.
-
볼륨(Volume)
- 파드가 생성될 때 파드에서 사용할 수 있는 디렉터리를 제공
- 기본적으로 파드는 영속되는 개념이 아니라서 제공되는 디텍토리도 임시로 사용
- 파드가 사라지더라도 저장과 보존이 가능한 디렉토리를 볼륨 오브젝트를 통해 생성하고 사용 가능
-
서비스(Service)
- 파드는 클러스터 내에서 유동적이기 때문에 접속 정부가 고정일 수 없다
- 파드 접속을 안정적으로 유지하도록 서비스를 통해 내/외부로 연결된다
- 새로 파드가 생성될 때 부여되는 새로운 IP를 기존에 제공하는 기능과 연결해준다
- 쿠버네티스 외부에서 내부로 접속할 때 내부가 어떤 구조로 돼 있는지, 파드가 살았는지 죽었는지 신경 쓰지 않아도 이를 논리적으로 연결하는 것
- 기존 인프라에서 로드밸런서, 게이트웨이와 비슷한 역할
- 서비스라는 이름 때문에 개념을 잡기 어렵지만 아래서 더 자세히 다뤄보자
디플로이먼트
기본 오브젝트만으로 쿠버네티스를 사용할 수도 있지만, 더 효율적으로 작동하도록 기능을 조합하고 추가해 구현한 것이 디플로이먼트입니다.
이 외에도 데몬셋(DaemonSet), 컨피그맵(ConfigMap), 레플리카셋(ReplicaSet), PV(PersistentVolume), PVC(PersistentVolumeClaim), 스테이트풀셋(StatefulSet) 등이 있으며, 앞으로도 요구 사항에 따라 목적에 맞는 오브젝트들이 추가될 것입니다.
쿠버네티스에서 가장 많이 쓰이는 디플로이먼트 오브젝트는 파드에 기반을 두고 있으며, 레플리카셋 오브젝트를 합쳐 놓은 형태입니다.
레플리카셋은 레플리케이션컨트롤러(ReplicationController)가 발전한 형태지만, 현재는 레플리카셋만 알면 됩니다.
레플리카셋에 관한 자세한 설명은 아래서 진행됩니다.
앞에서 생성한 dpy-nginx의 디플로이먼트 계층 구조는
디플로이먼트 > 레플리카셋 > 파드1,파드2,... 와 같이 이루어져 있씁니다.
실제로 API 서버와 컨트롤러 매니저는 단순히 파드가 생성되는 것을 감시하는 것이 아니라 디플로이먼트처럼 레플리카셋을 포함하는 오브젝트의 생성을 감시합니다!
API서버 / 컨트롤러 매니저
-> 디플로이먼트 생성 감시
<- 레플리카셋 생성
-> 레플리카셋 생성 감시
<- 레플리카셋에서 선언한 파드(s) 생성쿠버네티스는 한번에 이해하기 어려우니 처음부터 끝까지 실습을 진행해보고 처음부터 다시 읽어보시길 권장드립니다. 또한 쿠버네티스 오브젝트 생태계는 계속 변화하므로 모든 것을 외울 필요 없이 필요한 부분을 찾아 적재적소에 필요한 오브젝트를 사용하는 것이 현명합니다.
- 쿠버네티스에서 사용하는 nginx 이미지는 어디서 가져오나요?
- 컨테이너로 도커를 사용하므로 도커의 기본 저장소인 도커 허브에서 이미지를 가지고옵니다.- 클라우드 서비스를 이용한다면 업체에서 제공하는 GCR, ECR, ACR 등을 사용할 수도 있습니다.
- 온프레미스는 내부 데이터 센터에 따로 저장소를 설정해 사용할 수 있습니다.
- 편의를 위해 이 포스팅(책)에서는 저자의 도커 허브 저장소에서 제공하는 이미지를 사용합니다!
-
간단히 디플로이먼트를 생성하고 삭제해봅시다.
-
저자의 저장소에서 필요한 이미지를 내려받아 디플로이먼트를 생성합니다.
- 이미지 경로는sysnet4admin/echo-hname이며, 전자는 계정 이름이고 후자는 이미지 이름입니다. -
생성 :
kubectl create deployment dpy-hname --image=sysnet4admin/echo-hname


-
삭제 :
kubectl delete deployment dpy-hname
- create를 delete로 대체하고, --image 옵션을 제외해줍니다.

이제 디플로이먼트를 왜 생성하는지, 왜 필요한지 알아봅시다!
-
레플리카셋으로 파드 수 관리하기
많은 사용자들 대상으로 웹 서비스를 하려면 다수의 파드가 필요한데, 이를 하나씩 생성한다면 매우 비효율적입니다. 그래서 쿠버네티스는 다수의 파드를 만드는 레플리카셋 오브젝트를 제공합니다.
예를 들어 파드를 3개 만들겠다고 레플리카셋에 선언하면 컨트롤러 매니저와 스케줄러가 워커 노드에 파드를 3개 만들도록 선언합니다.
그러나 레플리카셋은 파드 수를 보장하는 기능만 제공하기 때문에 롤링 업데이트 기능 등이 추가된 디플로이먼트를 사용해 파드 수를 관리하기를 권장합니다.
- 먼저 배포된 파드의 상태를 확인합니다.
kubectl get pods

- nginx-pod를
scale명령으로 3개로 증가시킵니다. 여기서 --relicas=3은 파드의 수를 3개로 맞추는 옵션입니다.kubectl scale pod nginx-pod --replicas=3

리소스를 찾을 수 없다는 에러가 나옵니다. nignx-pod는 run으로 실행됐기 때문에(pod으로 생성) 디플로이먼트 오브젝트에 속하지 않기 때문입니다. - 디플로이먼트로 생성된 dpy-nginx를 scale명령과 --relicas=3 옵션으로 파드의 수를 3개로 만듭니다.
kubectl scale deployment dpy-nginx --replicas=3

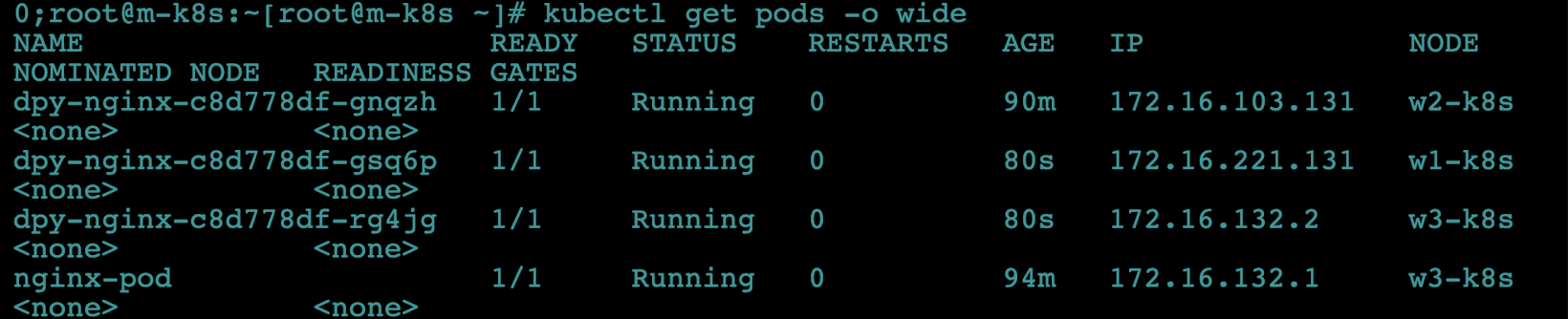
- dpy-nginx의 모든 파드가 정상적으로 워커 노드에 적용되고 IP가 부여됐는지
kubectl get pods -o wide명령으로 확인해봅시다.
- 다음 실습 진행을 위해 생성한 디플로이먼트를 삭제합니다.
kubectl delete deployment dpy-nginx

- TIP : 쿠버네티스는 클러스터 구조여서 단일 노드와 파드만 사용하는 경우는 흔하지 않습니다. 일반적으로 명령어를 복수형으로 사용해도 별 문제없습니다(nodes, pods), 또한 쿠버네티스는 alias(별칭)을 통해 단수로 입력하든 복수로 입력하든 유연하게 명령어를 사용하게 해줍니다.
스펙을 지정해 오브젝트 생성하기
kubectl create deployment를 통해 디플로이먼트를 생성하긴 했지만, 1개의 파드만 생성되었습니다.
디플로이먼트 생성과 동시에 한꺼번에 여러 파드를 만드는 방법을 알아봅시다!
create에서는 --replicas 옵션을 사용할 수 없고, scale은 이미 만들어진 디플로이먼트에서만 사용할 수 있습니다!
이런 설정을 적용하려면 필요한 내용을 파일로 작성해야 합니다.
이때 작성하는 파일을 오브젝트 스펙(spec) 이라고 합니다.
오브젝트 스펙은 일반적으로 야믈(YAML) 문법으로 작성합니다.
최근 상용, 오픈 소스 기술들은 스펙과 상태 값을 주로 야믈로 작성하므로 문법에 익숙해지는 것이 좋습니다.
- 야믈(YAML)이란? 처음엔 또 다른 마크업 언어(Yet Another Markup Language)의 약어였는데 공식 사이트에서 데이터 내용을 쉽게 파악할수 있는 표준이라는 뜻에서 야믈은 단순히 마크업 언어가 아니다(YAML Ain't Markup Language)라고 다시 정의했습니다.
- 마크업(Markup)이란 문서나 데이터의 구조를 태그를 이용해 기술하는 것을 의미합니다.
3개의 nginx 파드를 디플로이먼트 오브젝트로 만들어 보겠습니다. 명령어로는 3개의 파드를 가진 디플로이먼트를 만들 수 없으므로 오브젝트 스펙을 작성해 디플로이먼트를 만듭니다.
-
~/.Book_k8sInfra/ch3/3.2.4/echo-hname.yaml파일의 내용을 살펴봅시다.apiVersion: apps/v1 # API 버전 kind: Deployment # 오브젝트 종류 metadata: name: echo-hname labels: app: nginx spec: replicas: 3 # 몇 개의 파드를 생성할지 결정 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: echo-hname image: sysnet4admin/echo-hname # 사용되는 이미지apiVersion은 오브젝트를 포함하는 API 버전을 의미합니다. apps/v1은 여러 종류의 오브젝트를 가지고 있는데, 그 중에서 Deployment를 선택해 레플리카셋을 생성합니다.
-
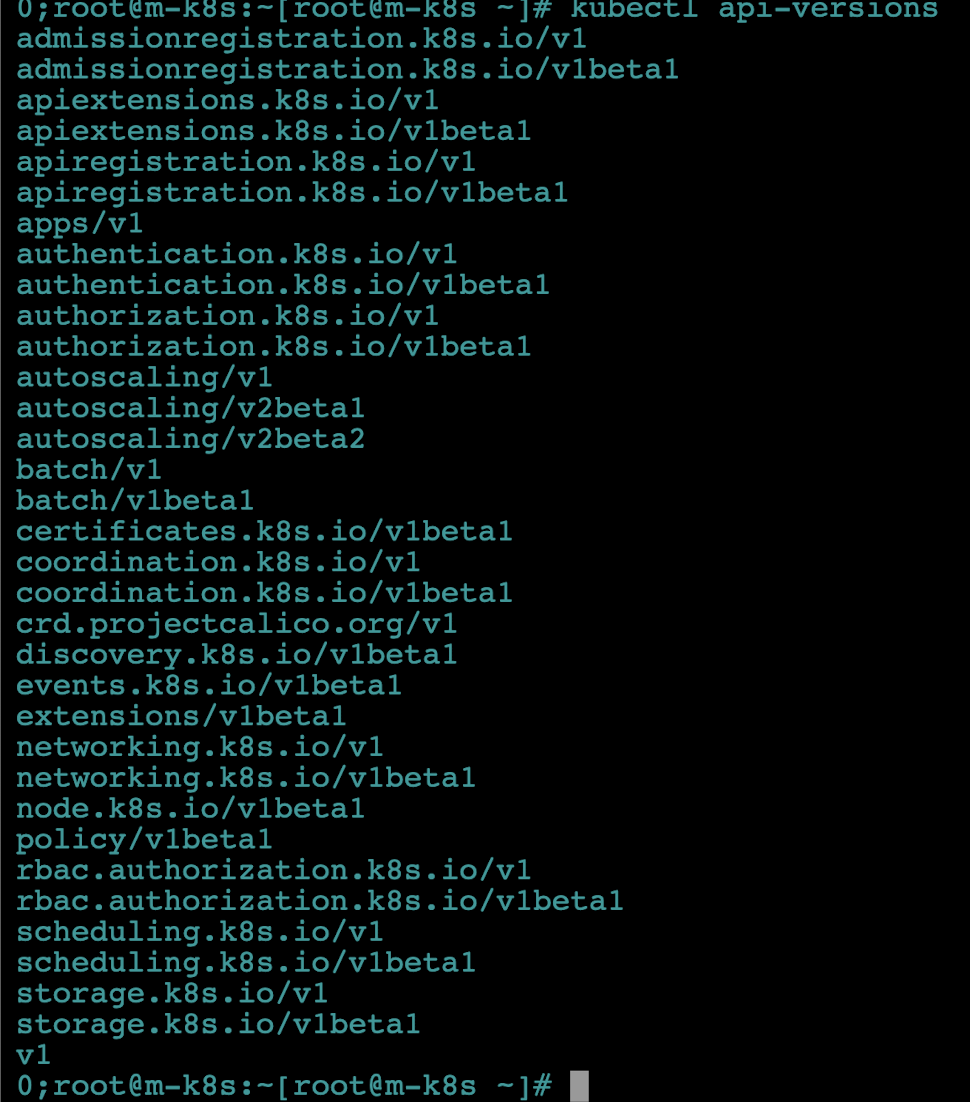
사용 가능한 API 버전을 확인하려면(사용가능한 버전은 쿠버네티스 버전에 따라 다릅니다)?
kubectl api-versions
파일을 살펴보면 이전에 살펴본
nginx-pod.yaml과 template 부분이 동일함을 알 수 있습니다. 즉, template 하위의 metadata와 spec이 동일하게 사용됩니다!
쿠버네티스는 API 버전마다 포함되는 오브젝트(kind)도 다르고 요구하는 애용도 다릅니다. 그러므로 기존에 만들어진 파일을 수정하면서 이해해 보고 필요한 내용을 그때마다 정리하는 것이 좋습니다.
-
echo-hname.yaml 파일을 이용해 디플로이먼트를 생성해 봅시다.
- 현재 디플로이먼트는 파드 3개를 생성하도록 replicas에 정의되어 있습니다.
kubectl create -f ~/_Book_k8sInfra/ch3/3.2.4/echo-hname.yaml

-
spec파일(.yaml)을 이용해 생성한 echo-hname 파드가 3개인지 확인합니다.

-
이번에는 echo-hname.yaml 파일을 수정해 파드를 6개로 늘려보겠습니다.
- 파일에서 replicas의 값을 3에서 6으로 변경합니다.
- 이때 사용하는 명령어는 sed(streamlined editor)입니다. 그 위에 몇 가지 옵션이 따라옵니다.
--i는 --in0place의 약어로 변경한 내용을 현재 파일에 바로 적용합니다./s는 주어진 패턴을 원하는 패턴으로 변경합니다.- sed 사용이 어렵다면 에디터툴(vim, vscode 등)을 사용하여 변경하셔도 됩니다.
sed -i 's/replicas: 3/replicas: 6/' ~/_Book_k8sInfra/ch3/3.2.4/echo-hname.yaml

-
replicas의 값이 변경되었는지 확인합니다.
cat ~/_Book_k8sInfra/ch3/3.2.4/echo-hname.yaml | grep replicas

-
변경된 내용을 적용합니다.
kubectl create -f ~/_Book_k8sInfra/ch3/3.2.4/echo-hname.yaml

echo-hname이 이미 존재하기 때문에 에러가 발생합니다. 물론 scale 명령으로 파드 수를 느릴 수도 있지만, 파일을 통해 파드 수를 늘리려면 어떻게 해야할까요? 배포된 오브젝트의 스펙을 변경하고 싶을 떄는 어떻게 해야할까요? 지금부터 알아봅시다!
apply로 오브젝트 생성하고 관리하기
- run은 파드를 간단하게 생성하는 매우 편리한 방법입니다. 하지만 단일 파드만 생성할 수 있어 간단한 테스트 용도가 아니면 사용하기 부적합합니다.
- 그렇다고 create로 디플로이먼트를 생성하면 앞서 확인한 것처럼 파일의 변경 사항을 바로 적용할 수 없다는 단점이 있습니다.
- 그래서 쿠버네티스는 apply라는 명령어를 제공합니다. apply를 통해 오브젝트를 관리해봅시다!
-
replicas를 6으로 수정한 echo-hname.yaml 파일을 kubectl apply 명령으로 적용합니다.
kubectl apply -f ~/_Book_k8sInfra/ch3/3.2.4/echo-hname.yaml

오브젝트를 처음부터 apply로 생상한 것이 아니어서 경고가 뜹니다. 작동에는 문제가 없지만 일관성에 문제가 생길 수 있습니다. 이처럼 변경 사항이 발생할 가능성이 있는 오브젝트는 처음부터 apply로 생성하는 것이 좋습니다.
-
명령이 적용된 후에 echo-hname이 6개로 늘어났는지 확인합니다. 특히 AGE를 확인해 최근 추가된 파드 3개를 확인합니다.
kubectl get pods

-
kubectl apply를 활용하면 파일의 변경 사항도 쉽게 적용할 수 있다는 것을 확인했습니다. 명령 창 등에 직접 애드혹(ad-hoc, 일회적 사용)으로 오브젝트를 생성할 때는 create를 사용하고 변경 가능성이 있는 오브젝트는 파일로 작성후 apply를 적용하도록 합시다!구분 run create apply 명령 실행 제한적임 가능함 안 됨 파일 실행 안 됨 가능함 가능함 변경 가능 안 됨 안 됨 가능함 실행 편의성 매우 좋음 매우 좋음 좋음 기능 유지 제한적임 지원됨 다양하게 지원됨
파드의 컨테이너 자동 복구 방법
쿠버네티스는 거의 모든 부분이 자동 복구되도록 설계됐습니다.
특히 파드의 자동 복구 기술은 셀프 힐링(Self-Healing)이라고 하는데,
제대로 작동하지 않는 컨테이너를 다시 시작하거나 교체해 파드가 정삭적으로 작동하게 합니다.
셀프 힐링 기능을 확인하는 테스트를 해봅시다!
-
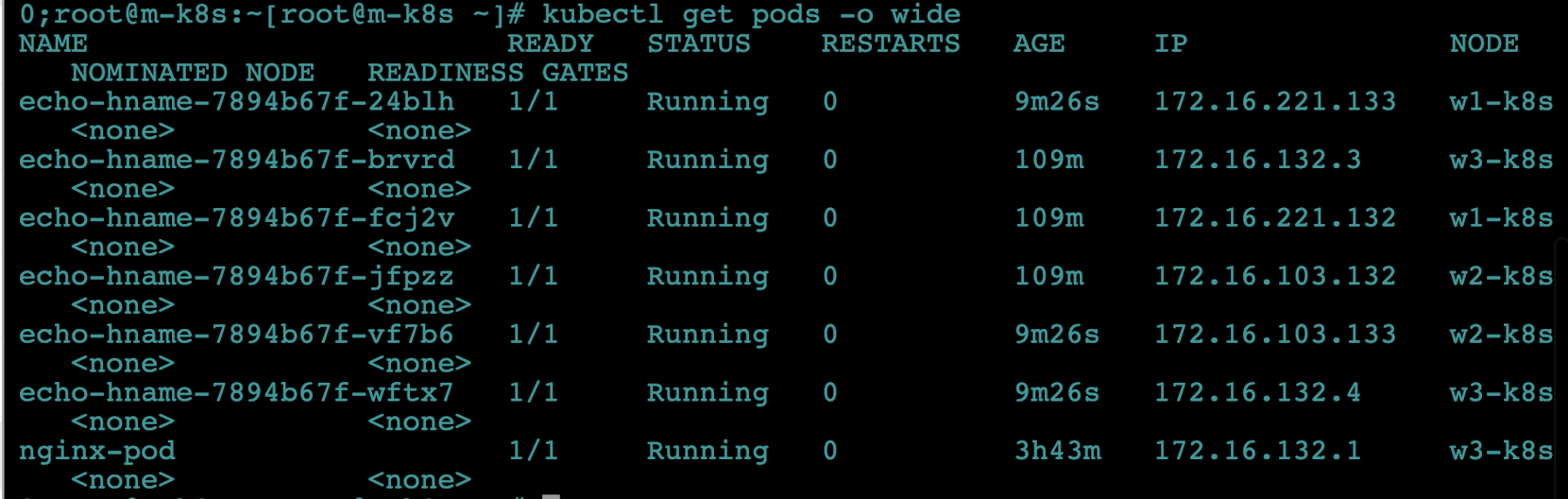
파드에 접속하려면 파드의 IP를 알아야하니까,
kubectl get pods -o wide로 확인해봅시다.
-
kubectl exec -it nginx-pod -- /bin/bash명령을 실행해 파드 컨테이너의 셸(shell)에 접속합니다.

- exec는 execute(실행)을 의미합니다
i옵션은 stdin(standard input, 표준 입력)이고, t는 tty(teletypewriter, 명령줄 인터페이스)를 뜻합니다.- 이 두개를 합친 it는 표준 입력을 명령줄 인터페이스로 작성한다는 의미입니다.
- 파드인 nginx-pod에 /bin/bash를 실행해 nignx-pod의 컨테이스 배시 셸에 접속합니다.
--의 의미 :
- exec에 대한 인자 값을 나누고 싶을 때 사용- 예를 들어 nginx-pod에서 /run의 내용을 보고 싶다면 파드 이름 뒤에
ls /run을 입력하면 됩니다. --를 사용할 때는 보이지 않던 DEPRECATED 메세지가 함께 표시됩니다. kubectl exec -it nginx-pod ls /run

- 그렇다면, /run의 권한을 보고 싶을 땐 어떻게 할까요? -l(long listing format) 옵션을 붙여 확인하면 될 것 같습니다. 하지만 실행하면 에러가 발생합니다. 이는 -l을 exec의 옵션으로 인식하기 때문에 그렇습니다!
kubectl exec -it nginx-pod ls -l /run

- 이런 경우 명령을 구분해야 하는데, 이때
--를 사용합니다.kubectl exec -it nginx-pod -- ls -l /run

- 예를 들어 nginx-pod에서 /run의 내용을 보고 싶다면 파드 이름 뒤에
-
배시 셸에 접속하면 컨테이너에서 구동하는 nginx의 PID(Process ID, 프로세스 식별자)를 확인합니다. nginx의 PID은 언제나 1입니다. 그 이유는 나중에 포스팅하도록 하겠습니다.
cat /run/nginx.pid

-
ls -l 명령으로 프로세스가 생성된 시간을 확인합니다.
ls -l /run/nginx.pid

-
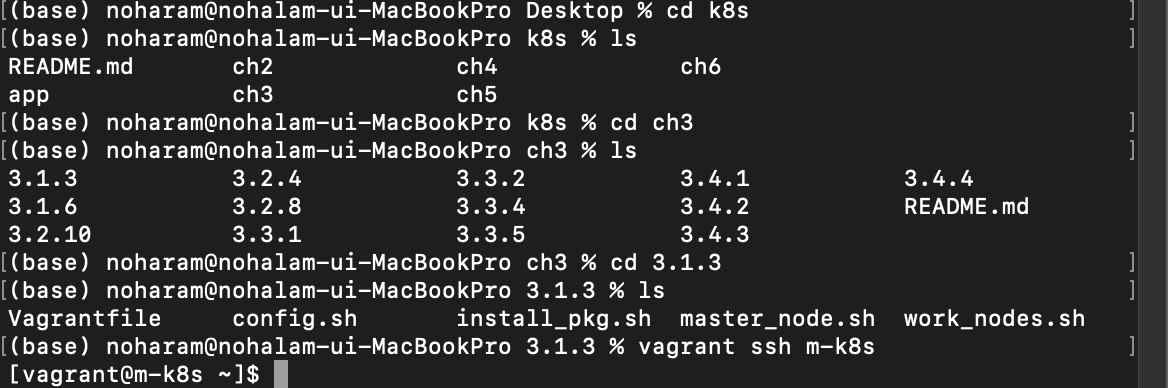
(mac의 경우)zsh 터미널에서 m-k8s의 터미널을 1개 더 띄우고, 이 터미널 화면에서 nginx-pod의 IP(172.16.132.1, 각자 생성된 IP를 확인해주세요.)에서 돌아가는 웹 페이지를 1초마다 한 번씩 요청하는 스크립트를 실행합니다.
- 윈도우의 경우 슈퍼푸티에서 m-k8s 터미널을 하나 더 실행하기만 하면 되지만, mac의 SSH CLIENT에서 같은 세션에 대해 터미널 창을 추가하는 방법을 몰라서 zsh 터미널로 접근합니다. 방법은 아래 이미지를 확인해주세요.(앞서 3.1.3 페이지에서 vagrant를 구동하였기 때문에
vagrant ssh m-k8s도 3.1.3 폴더에서 진행합니다.)
- curl에서 요청한 값만 받도록 --silent 옵션을 추가합니다. 이 스크립트로 nginx의 상태도 체크합니다.
i=1; while true; do sleep 1; echo $((i++)) `curl --silent 172.16.132.1 | grep title` ; done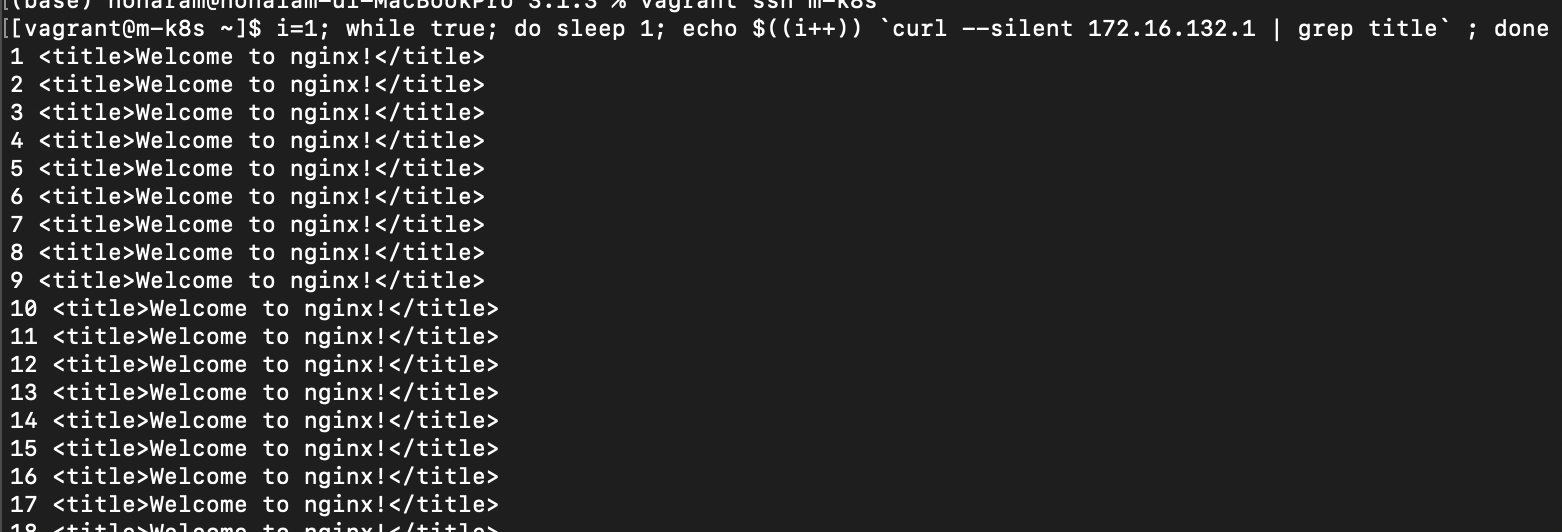
- 윈도우의 경우 슈퍼푸티에서 m-k8s 터미널을 하나 더 실행하기만 하면 되지만, mac의 SSH CLIENT에서 같은 세션에 대해 터미널 창을 추가하는 방법을 몰라서 zsh 터미널로 접근합니다. 방법은 아래 이미지를 확인해주세요.(앞서 3.1.3 페이지에서 vagrant를 구동하였기 때문에
-
다시 돌아와 배시 셸에서 nginx 프로세서인 PID 1번을 kill 명령으로 종료합니다.

-
zsh 터미널에서 1초마다 nginx 웹 페이지를 받아오는 스크립트의 상태를 확인해봅시다! 잠깐 프로세서가 종료되어 페이지를 받아오지 못하다가 자동 복구된 것을 확인할 수 있습니다.

-
다시 nginx-pod에 접속합니다. 그리고
ls -l을 실행합니다.kubectl exec -it nginx-pod -- /bin/bashls -l /run/nginx.pid

- nginx.pid가 생성된 시간으로 새로 생성된 프로세스인지 확인합니다.
- 다음 진행을 위해 exit 명령으로 다시 m-k8s의 배시 셸로 나옵니다.
-
ssh로 접근해서 계속 nginx 웹 페이지를 받아오고 있는 zsh 터미널도 종료해줍니다. 터미널을 끄면 자동으로 접속도 해제됩니다.
파드의 동작 보증 기능
쿠버네티스는 파드 자체에 문제가 발생하면 파드를 자동 복구해서 항상 동작하도록 보장하는 기능도 있습니다.
사실 이미 앞에서 이 기능을 경험해봤지만, 자세히 살펴봅시다.
-
파드에 문제가 발생하는 상황을 만듭니다.
- 앞에서 생성한 파드를 삭제합니다. 먼저 어떤 파드들이 있는지 확인합니다.
kubectl get pods

-
nginx-pod를 삭제합니다.
kubectl delete pods nginx-pod

-
파드의 동작을 보증하려면 어떤 조건이 필요합니다. 어떤 조건인지 확인하기 위해 다른 파드도 삭제해 서로 비교해 봅시다.
- 파드 목록 중 가장 상단에 있는
echo-hname-7894b67f-24blh를 삭제하겠습니다. kubectl delete pods echo-hname-7894b67f-24blh

- 파드 목록 중 가장 상단에 있는
-
삭제가 잘 되었는지
kubectl get pods로 확인합니다.-
하지만 아직도 6개의 파드가 살아 있고, 그 중 하나는 최근에 생성된 것으로 보입니다.
-
또한 앞에서 삭제한
echo-hname-7894b67f-24blh는 목록에 없습니다.

-
그 이유는 nginx-pod는 디플로이먼트에 속한 파드가 아니며 어떤 컨트롤러도 이 파드를 관리하지 않습니다. 따라서 nginx-pod는 바로 삭제되고 다시 생성되지도 않습니다.(단일파드, 동작 보증 X)
-
echo-hname은 디플로이먼트에 속한 파드입니다. 그리고 앞에서 echo-hanme에 속한 파드를replicas=6으로 선언했습니다.
- replicas는 선언한 파드의 수를 유지하고, 항상 확인하며 부족하면 새로운 파드를 만들어냅니다.- 따라서 임의로 파드를 삭제하면 삭제된 파드를 확인하고 총 개수(6개)를 맞추기 위해 새로운 파드를 1개 생성합니다.
감시 -> 차이 발견 -> 상태 변경 -> 변경 완료 후 다시 감시순서입니다.
-
이와 같이 디플로이먼트로 생성하는 것이 파드의 동작을 보장하기 위한 조건 입니다!
-
- 그렇다면 이렇게 파드가 자동 복구가 되면 디플로이먼트에 속한 파드는 어떻게 삭제할까요?
- 디플로이먼트에 속한 파드는 상위 디플로이먼트를 삭제해야 파드가 삭제됩니다.
kubectl delete deployment echo-hname

- 디플로이머트를 삭제한 후에 배포된 파드가 남아 있는지 확인합니다.
kubectl get pods

노드 자원 보호하기
여러가지 상황에서도 쿠버네티스는 파드를 안정적으로 작동하도록 관리한다는 것을 확인했습니다.
그렇다면 노드는 어떤 식으로 관리할까요? 우선 노드의 목적을 알아봅시다.
노드는 쿠버네티스 스커줄러에서 파드를 할당받고 처리하는 역할을 합니다.
최근에 몇 차례 문제가 생긴 노드에 파드를 할당하면 문제가 생길 가능성이 높습니다. 하지만 어쩔 수 없이 해당 노드를 사용해야 한다면 어떻게 할까요?
이런 경우는 영향도가 적은 파드를 할당해 질정 기간 사용하면서 모니터링 해야합니다.
즉, 노드에 문제가 생기더라도 파드에 문제를 최소화해야 합니다.
하지만 쿠버네티스는 모든 노드에 균등하게 파드를 할당하려고 합니다.
그렇다면 어떻게 문제가 생길 가능성이 있는 노드라는 것을 쿠버네티스에게 알려줄까요?
-> 해당 노드에 더는 파드를 할당하지 않는 기능을 사용합니다.
이런 경우에는 cordon 기능을 사용합니다. cordon으로 노드 관리를 실습해봅시다!
- 현재 배포된 파드가 없기 때문에 echo-hname.yaml을 적용해(apply) 파드를 생성합니다.
kubectl apply -f ~/_Book_k8sInfra/ch3/3.2.8/echo-hname.yaml

- scale 명령으로 배포한 파드를 9개로 늘립니다.
kubectl scale deployment echo-hname --replicas=9

- 배포된 9개의 파드가 작동하는지, IP 할당이 잘 됐는지, 각 노드로 공평하게 배분됐는지 확인합니다. 이때
kubectl get pods -o wide대신kubectl get pods -o=custom-columns를 사용합니다.-o는 output을 의미합니다custom-columns는 사용자가 임의로 구성할 수 있는 열을 의미합니다.NAME, IP, STATUS, NODE는 열의 제목이고, 콜론(:) 뒤에 내용 값인.metadata.name, .status.podIP, .status.phase, .spec.nodeName을 넣고 콤마로 구분합니다.kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

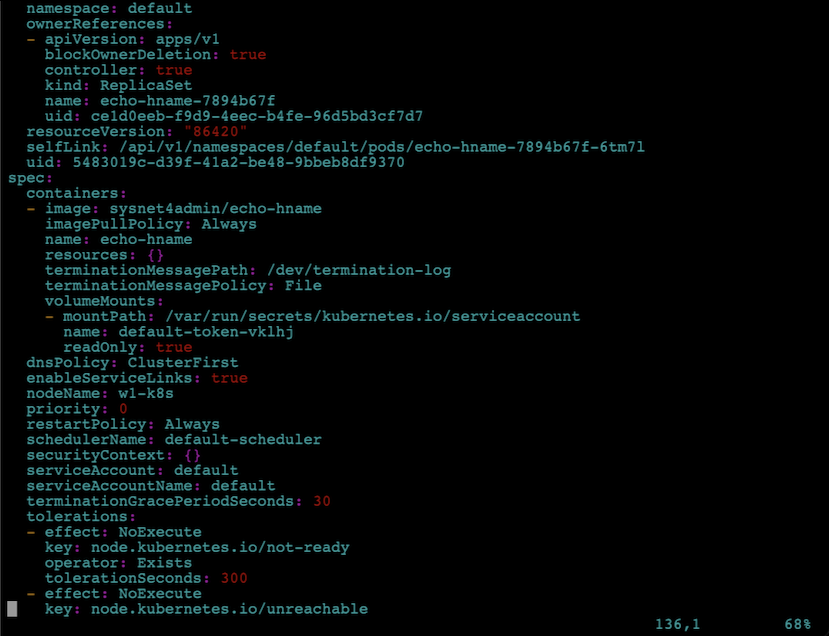
- 배포된 파드의 세부 값을 확인하는 방법
- 배포된 파드 중에 하나를 선택하고-o yaml옵션으로 내용을pod.yaml에 저장합니다.kubectl get pod echo-hname-7894b67f-6tm7l

- scale로 파드의 수를 3개로 줄입니다.
kubectl scale deployment echo-hname --replicas=3

- 각 노드에 파드가 1개씩만 남았는지 확인합니다.(균등하게 배분됨)
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

- 그런데 w3-k8s 노드에서 문제가 자주 발생해 현재 상태를 보존해야 하는 경우라고 가정합니다. w3-k8s 노드에 cordon 명령을 실행합니다.
kubectl cordon w3-k8s

- cordon 명령이 제대로 적용됐는지 확인합니다.
kubectl get nodes

- w3-k8s 노드가 더 이상 파드가 할당되지 않는 상태로 변경됐습니다.(해당 노드에 파드가 할당되지 않게 스케줄되지 않는 상태, SchedulingDisabled)
- 이 상태에서 파드 수를 다시 9개로 늘려봅시다.
kubectl scale deployment echo-hname --replicas=9

- 노드에 배포된 파드를 확인합니다. 특히 w3-k8s에 배포된 파드가 있는지 확인해봅니다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName
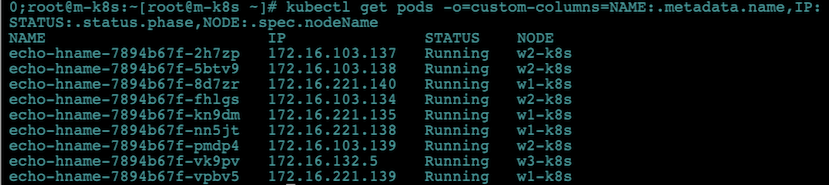
- 파드가 w3-k8s 노드를 제외하고 할당되어 배포된 것을 확인할 수 있습니다.
- 이번엔 다시 파드 수를 3개로 줄여봅시다.
kubectl scale deployment echo-hname --replicas=3

- 각 노드에 할당된 파드 수가 공평하게 1개씩인지 확인합니다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

uncordon명령으로 w3-k8s에 파드가 할당되지 않게 설정했던 것을 해제하고, 적용됐는지 확인합니다.kubectl uncordon w3-k8skubectl get nodes

이렇게 cordon 기능을 통해 노드에 파드를 더 이상 할당되지 않게 하는 방법을 알아봤습니다.
그렇다면 노드의 커널을 업데이트하거나, 노드의 메모리를 증성하는 등의 작업이 필요해서 노드를 꺼야할 때는 어떻게 하면 좋을까요?
노드 유지보수하기
쿠버네티스를 사용하다 보면 정기 또는 비정기적인 유지보수를 위해 노드를 꺼야 하는 상황이 발생합니다.
이런 경우를 대비해 쿠버네티스는 drain 기능을 제공합니다.
drain은 지정된 노드의 파드를 전부 다른 곳으로 이동시켜 해당 노드를 유지보수할 수 있게 합니다.
-
kubectl drain명령을 실행해 유지보수할 노드(w3-k8s)를 파드가 없는 상태로 반듭니다.kubectl drain w3-k8s- 그런데 명령을 실행하면 w3-k8s에서 데몬셋을 지울 수 없다서 명령을 수행할 수 없다고 나옵니다.

- 여기서
drain이 어떻게 작동하는지 알 수 있습니다.
- 실제로 파드를 옮기는 것이 아니라 노드에서 파드를 삭제하고 다른 곳에 다시 생성합니다.- 파드는 언제라도 삭제할 수 있기 때문에 쿠버네티스에서 대부분 이동은 파드를 지우고 재생성하는 과정을 의미합니다.
- 그런데 DaemonSet은 각 노드에 1개만 존재하는 파드라서 drain으로는 삭제할 수 없습니다!
-
이번에는
drain명령과ignore-daemonsets옵션을 함께 사용합니다. 이 옵션은 DaemonSet을 무시하고 진행합니다. 경고는 발생하지만 모든 파드가 이동됩니다.kubectl drain w3-k8s --ignore-daemonset

-
노드 w3-k8s에 파드가 없는지 확인합니다. 그리고 옮긴 노드에 파드가 새로 생성돼 파드 이름과 IP가 부여된 것도 확인합니다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

-
drain명령이 수행된 w3-k8s 노드의 상태를 확인합니다.cordon을 실행했을 때처럼SchedulingDisabled상태입니다.kubectl get nodes

-
유지보수가 끝났다고 가정하고 w3-k8s에 uncordon 명령을 실행해 스케줄을 받을 수 있는 상태로 복귀시키고, 다시 노드 상태를 확인합니다.
kubectl uncordon w3-k8skubectl get nodes

-
다음 진행을 위해 배포한
echo-hname을 삭제합니다. 배포된 파드가 없는 것을 확인합니다.kubectl delete -f ~/_Book_k8sInfra/ch3/3.2.8/echo-hname.yamlkubectl get pods

파드 업데이트하고 복구하기
파드를 운영하다 보면 컨테이너에 새로운 기능을 추가하거나 치명적인 버그가 발생해 버전을 업데이트해야 할 때가 있습니다.
또는 업데이트 도중 문제가 발생해 기존 버전으로 복구해야 하는 일도 발생합니다.
이런 일을 처리하는 방법을 알아봅시다!
파드 업데이트하기
-
다음 명령으로 컨테이너 버전 업데이트를 테스트하기 위한 파드를 배포합니다.
-
--record옵션은 매우 중요한 옵션으로, 배포한 정보의 히스토리를 기록합니다. -
kubectl apply -f ~/_Book_k8sInfra/ch3/3.2.10/rollout-nginx.yaml --record
-
적용한 코드는 다음과 같습니다. 앞서 살펴본 내용과 거의 비슷하며 중요한 부분은 버전을 정하는
image: nginx:1.15.12입니다. 여기에 컨테이너 버전을 지정하고, 설치한 후에 단계별로 버전을 업테이트합니다.apiVersion: apps/v1 kind: Deployment metadata: name: rollout-nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.15.12
-
-
record옵션으로 기록된 히스토리는rollout history명령을 실행해 확인할 수 있습니다.kubectl rollout history deployment rollout-nginx

-
배포한 파드의 정보를 확인합니다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

-
배포된 파드에 속해 있는 nginx 컨테이너 버전을
curl -I(헤더 정보만 보여주는 옵션) 명령으로 확인합니다.- 자신의 파드에 기록된 IP로 적용시켜야 하는 것 잊지 마세요!
curl -I --silent 172.16.132.9 | grep Server

-
set image명령으로 파드의 nginx 컨테이너 버전을 1.16.0으로 업데이트합니다. 이번에도--record명령을 포함해, 실행한 명령을 기록합니다.kubectl set image deployment rollout-nginx nginx=nginx:1.16.0 --record

-
업데이트한 후 파드의 상태를 확인합니다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

- 결과를 보니 파드의 이름과 IP가 변경되었습니다.
- 파드는 언제라도 지우고 다시 만들 수 있습니다.- 따라서 파드에 속한 nginx 컨테이너를 업데이트하는 가장 쉬운 방법은 relpicas의 수를 줄이고 늘려 파드를 새로 생성하는 것입니다.
- 이때 시스템의 영향을 최소화하기 위해 replicas에 속한 파드를 한번에 지우지 않고, 하나씩 순차적으로 지우고 생성합니다.
- 만일 파드의 수가 많다면, 하나씩이 아니라 다수의 파드가 순차적으로 업데이트 됩니다. 업데이트 기본값은 전체의 1/4(25%)이며, 최소값은 1입니다.
-
nginx 컨테이너가 1.16.0으로 모두 업데이트되면 Deployment의 상태를 확인합니다.
kubectl rollout status deployment rollout-nginx

-
rollout history명령을 실행해 rollout-nginx에 적용된 명령들을 확인합니다.kubectl rollout history deployment rollout-nginx

--record옵션을 적용한apply와set image명령이 기록되어 있는 것을 확인할 수 있습니다.
-
curl -I명령으로 업데이트가 제대로 이루어졌는지도 확인합니다.curl -I --silent 127.16.103.142 | grep Server

업데이트 실패 시 파드 복구하기
업데이트할 때 버전을 잘못 입력하면 어떻게 할까요? 업데이트 실패 시 파드를 복구하는 방법을 알아봅시다!
-
set image명령으로 nginx 컨테이너 버전을 의도(1.17.2)와 다르게 1.17.23으로 입력합니다.kubectl set image deployment rollout-nginx nginx=nginx:1.17.23 --record

-
한참이 지나고 나서도, 파드의 상태를 확인해보면 파드가 삭제되지 않고 pending(대기 중) 상태에서 변하지 않은 것을 볼 수 있습니다. 확인해봅시다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

-
어떤 문제인지 파악하기 위해
rollout status를 실행합니다.kubectl rollout status deployment rollout-nginx

- 새로운 replicas는 생성했으나(new replicas have been updated), 디플로이먼트를 배포하는 단계에서 대기 중(Waiting for deployment)으로 더 이상 진행되지 못하는 것을 확인할 수 있습니다.
- 한참 기다려보면, Deployment를 생성하려고 여러 번 시도했지만 끝내 생성되지 않았다는 메세지가 출력됩니다.
-
describe명령으로 문제점을 좀 더 자세히 살펴봅시다. 이 명령은 쿠버네티스의 상태를 살펴볼 때 유용합니다.kubectl describe deployment rollout-nginx
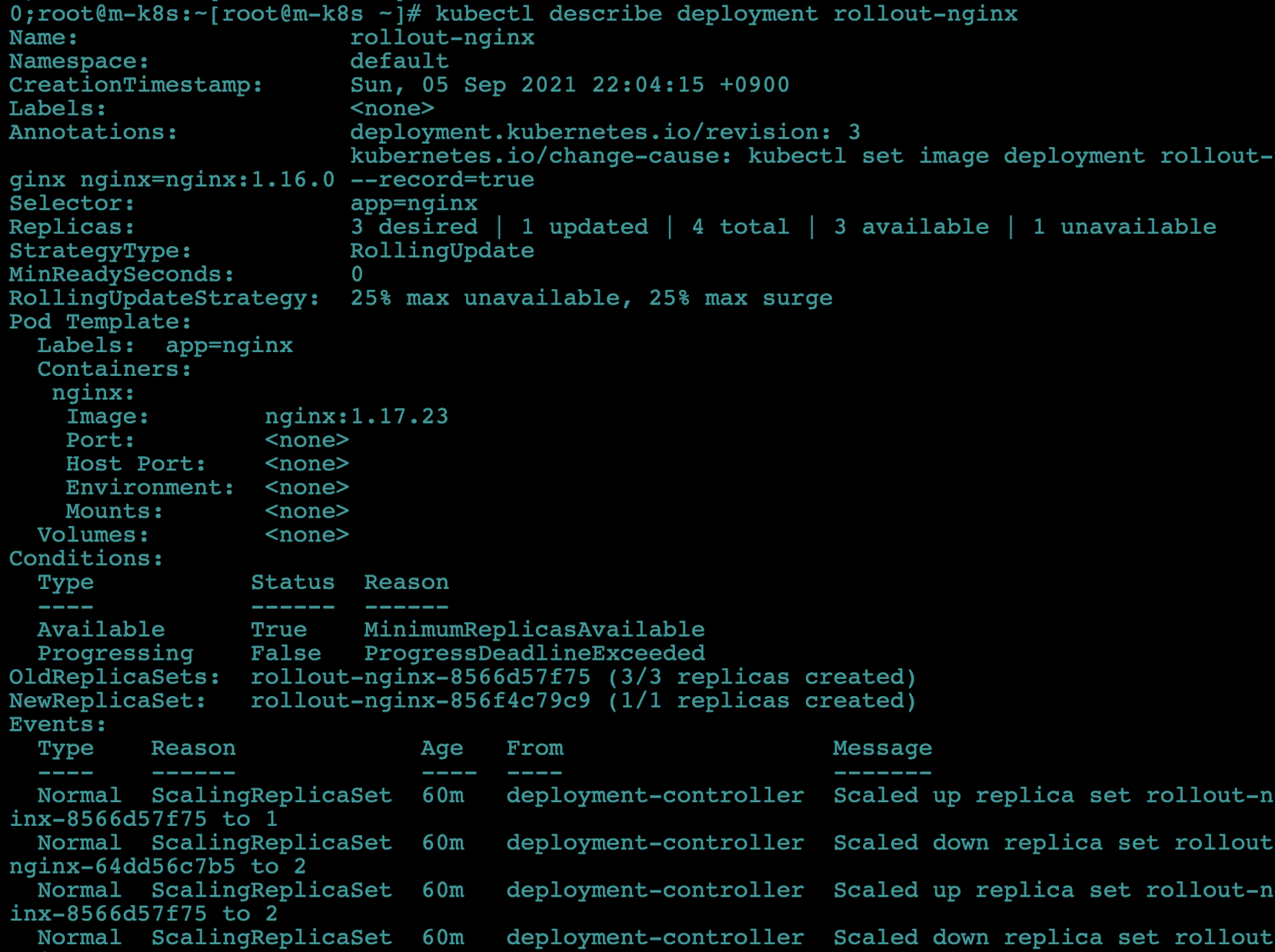
- describe 명령으로 확인하니 replicas가 새로 생성되는 과정에서 멈춰 있습니다.
- 이유는 1.17.23 버전의 nginx 컨테이너가 없기 때문입니다. 따라서 replicas가 생성을 시도했으나 컨테이너 이미지를 찾을 수 없어서 디플로이먼트가 배포되지 않았습니다.
- 배포할 때 이런 실수를 방지하고자 업데이터를 할 때
rollout을 사용하고--record로 기록하는 것입니다.
-
이제 정상적인 상태로 복구하는 방법을 알아봅시다. 업데이트할 떄 사용했던 명령들을
rollout history로 확인합니다.kubectl rollout history deployment rollout-nginx

-
rollout undo로 명령 실행을 취소해 마지막 단계(revision 3)에서 전 단계(revision 2)로 상태를 되돌립니다.kubectl rollout undo deployment rollout-nginx

-
파드의 상태를 다시 확인합니다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

-
rollout history로 실행된 명령을 확인합니다.kubectl rollout history deployment rollout-nginx

- revision 4가 추가되고 revision 2가 삭제됐습니다.
- 현재 상태를 revision 2로 되돌렸기 때문에 revision 2가 삭제되고 가장 최근 상태는 revision 4가 됩니다.
- nginx 1.16(2) -(set image)> 1.17.23(3) -(undo)> 1.16(4)
-
배포된 컨테이너의 버전을 확인합니다. 버전이 1.16.0이므로 상태가 되돌려졌음을 알 수 있습니다.
curl -I --silent 172.16.103.142 | grep Server

-
rollout status명령으로 변경이 정상적으로 적용됐는지 확인합니다.kubectl rollout status deployment rollout-nginx

-
describe로 현재 디플로이먼트 상태도 세부적으로 점검하고 넘어갑니다.kubectl describe deployment rollout-nginx
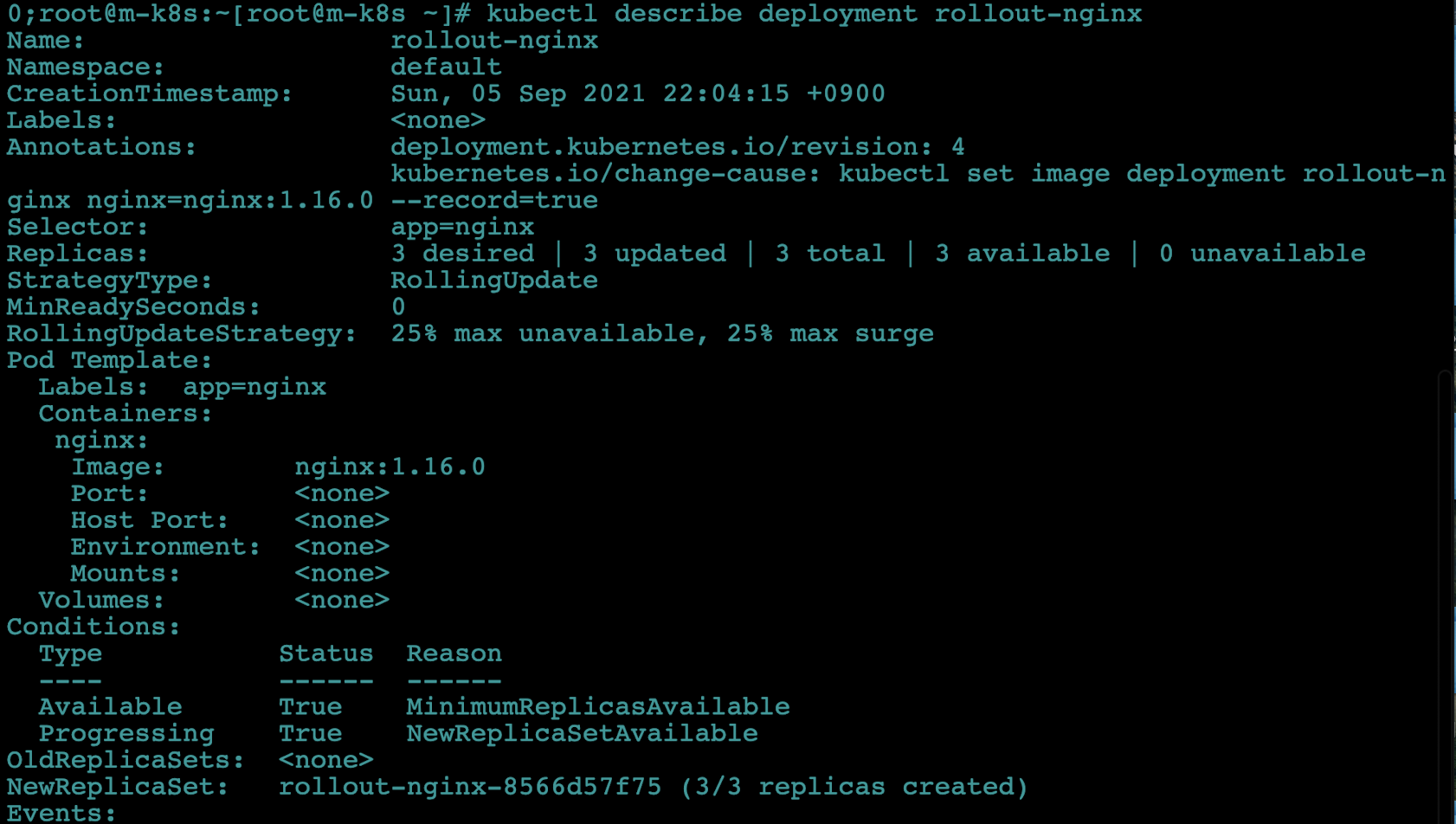
특정 시점으로 파드 복구하기
방금과 같이 바로 이전 상태가 아니라 특정 시점으로 돌아가고 싶다면 어떻게 할까요?
이럴 땐 --to-revision 옵션을 사용합니다.
- 처음 상태인 revision 1로 돌아가봅시다
kubectl rollout undo deployment rollout-nginx --to-revision=1

- 새로 생성된 파드들의 IP를 확인합니다.
kubectl get pods -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase,NODE:.spec.nodeName

- nginx 컨테이너의 버전을 확인합니다. 1.15.12 버전으로 처음 상태로 복구된 것을 볼 수 있습니다.
curl -I --silent 172.16.103.143 | grep Server

- 다음 단계 진행을 위해 배포한 디플로이먼트를 삭제하고, 배포된 파드가 없는지 확인합니다.
kubectl delete -f ~/_Book_k8sInfra/ch3/3.2.10/rollout-nginx.yamlkubectl get pods

지금까지 쿠버네티스의 파드를 통해서 오브젝트 구성을 살펴보고,
파드를 효율적으로 사용할 수 있게 해주는 디플로이먼트에 대해서 알아봤습니다.
또한 오브젝트를 생성하는 3가지 방법을 알아보고 각각의 사용 용도를 확인했습니다.
그리고 쿠버네티스의 가장 큰 강점 주으이 하나인 안정적인 작동을 위해서 제공되는 기능들을 알아보고
유지보수, 업데이트, 그리고 복구하는 방법도 살펴봤습니다.
다음 포스팅에선 쿠버네티스 연결을 담당하는 서비스와 알아두면 쓸모있는 쿠버네티스 오브젝트에 대해 알아보겠습니다!
본 게시물은 "컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커 - 조훈,심근우,문성주 지음(2021)" 기반으로 작성되었습니다.
