
코드만 따로 분석하려고 한다.
왜 그런지 모르겠지만 웹서버만 보면 멍해지는 기분이 든다.
마약...
보다는
감기약에 가깝다.
먹기 싫다.

왜 딸기맛 감기약이라고 했을까?
딸기가 정말로 그런 맛이었다면
딸기는 다른 방식으로 진화했어야 할 것이다.
수액에 독이 있고, 열매가 폭발하거나
https://earthwow.org/19198/hura-crepitans/


킹강앵무...
이제부터 금강모기가 될 것이다.

그 자체가 독으로 가득 찬 놈도 있다.
https://namu.wiki/w/만치닐
하지만 '딸기맛 감기약 대신에 다른 맛 감기약'이라고 하면 나을까 생각하니
그것도 아닌 것 같긴하다.
가지맛 감기약이라고 하면 누가 먹겠는가
좋다
그렇다면 이제부터 딸기맛 코드를 철저하게 분석해보자.
사실 구현은 그냥 따라치는 정도가 끝이어서.. 분석하는 게 정말 중요할 것 같다는 생각이 들었다.
소켓
코드에 딥다이브하기 전에 이 친구의 정의부터 확실하게 해야할 것 같다.
동기가 '그래서 소켓이 뭔데?'라고 물어봤는데
파일 디스크립터가 네트워크 IO를 파일로 다룰 때 쓰는 녀석 주저리주저리
열리고 닫히니까 통로가 아닐까 그리고 끝점 주저리주저리
설명할 수 밖에 없었다.
아는 척 좋아하는 나로서는 곤혹스러웠다.
그래서 얘 정체부터 확실하게 짚고 넘어가야 할 것 같았다.
얘도 후레크레피탄스 나무 검색하다가 갑자기 소켓 물어보니까 당황했나보다.
주저리주저리 이상한 사진을 검색해놨다.
아는 척하는 걸 좋아하는 놈들의 공통점인 것 같다.
정확하게 알고 싶다. 함수인가? 파일인가? 추상화된 개념인가? 물리적인 개념인가?

뭐라고 생각하면 좋을지 고민을 해보니
사실 파일 디스크립터도 비슷한 녀석이긴 하다.
얘도 함수도, 파일도, 물리적인 개념도 아닐 것이다.
그래서 비슷한지 물어봤다.

종결
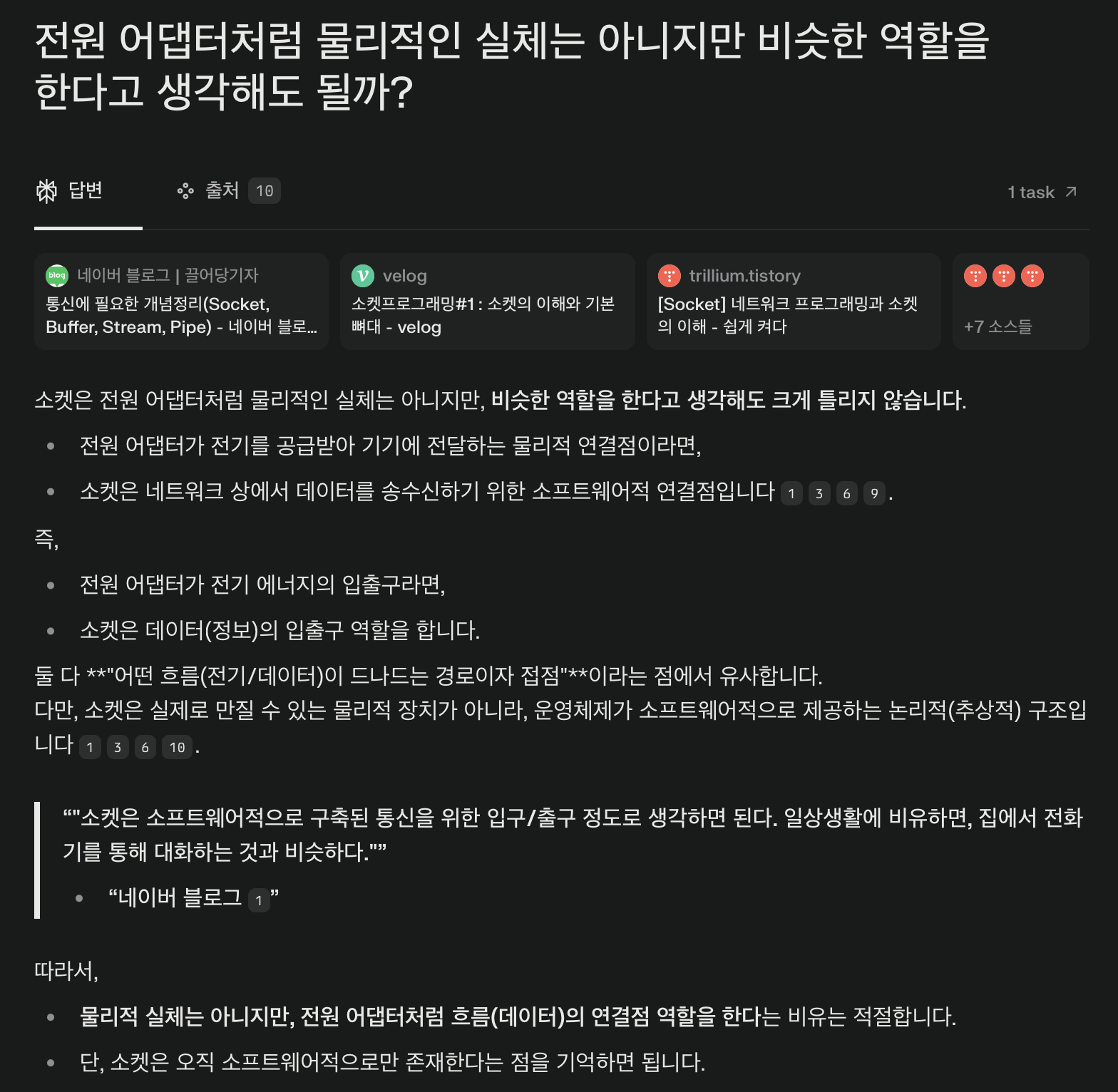
다 비슷하대
소켓은 사실 메타몽이 아닐까?
common function
echo의 client 코드 부분을 설명하다가 급하게 만들었다.
아래 함수들에 대한 설명이 필요하다는 생각이 들었기 때문이다.
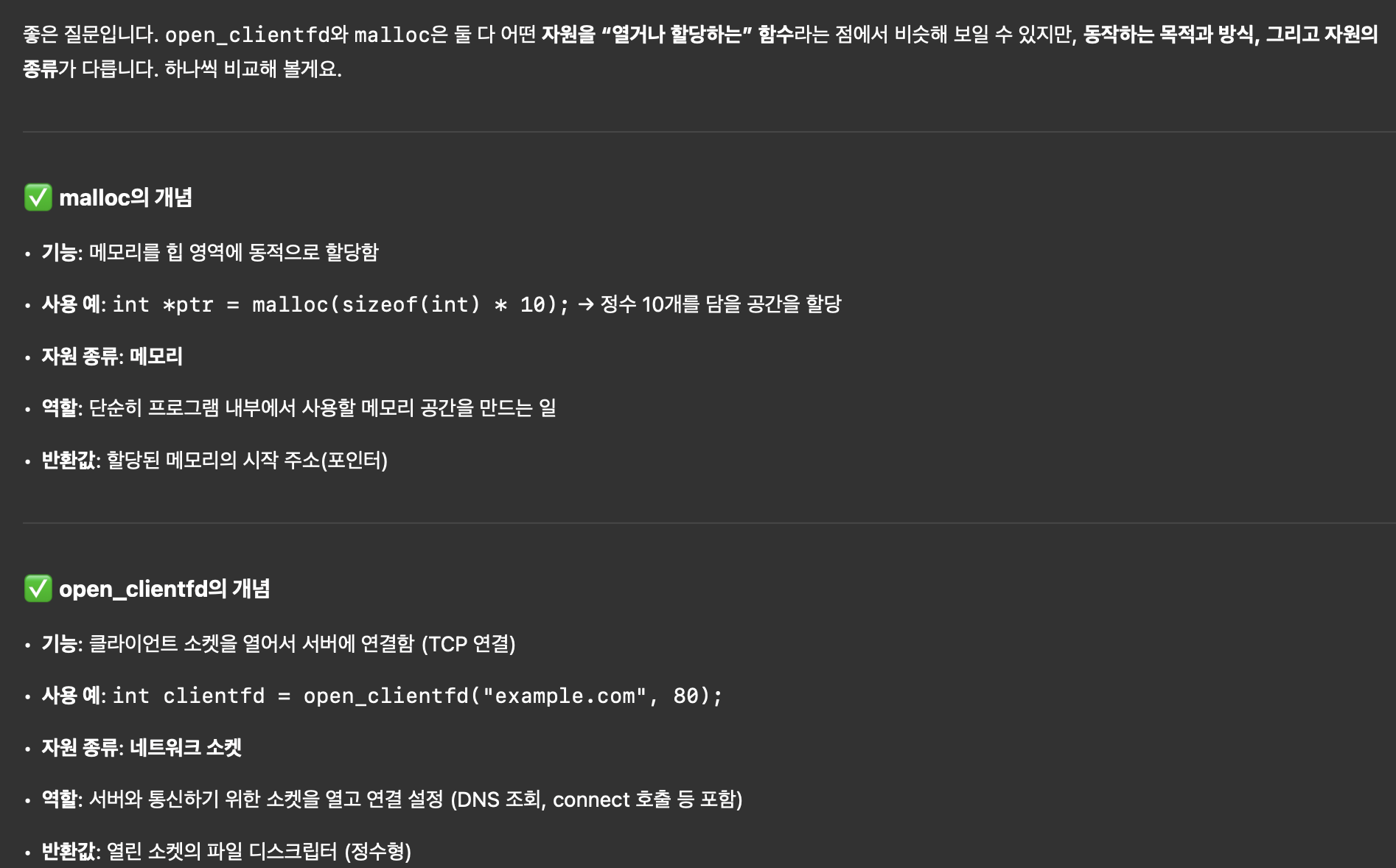
Open_clientfd(char* hostname,char* port)
접속할 사이트의 ip주소와 port를 이용해, 해당 서버에 연결된 클라이언트 소켓을 생성하고 반환하는 함수이다.
먼저 csapp.c라는 라이브러리를 타고 왔더니
int Open_clientfd(char *hostname, char *port)
{
int rc;
if ((rc = open_clientfd(hostname, port)) < 0)
unix_error("Open_clientfd error");
return rc;
}얘도 마찬가지로 open_clientfd를 호출하고 있다.
근데 여기서 하나 살펴야 될 건 hostname이라는 매개변수명이다.
host를 구성하는 다양한 것(IP주소, 역할, 호스트명)들이 있는데 (echo, client의 host 참고)
그 중 호스트명이 선택된 것 같다.
아무튼 open_clientfd를 타고 한 번 더 넘어간다. 꽉 잡자.
int open_clientfd(char *hostname, char *port) {
int clientfd, rc;
struct addrinfo hints, *listp, *p;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Open a connection */
hints.ai_flags = AI_NUMERICSERV; /* ... using a numeric port arg. */
hints.ai_flags |= AI_ADDRCONFIG; /* Recommended for connections */
if ((rc = getaddrinfo(hostname, port, &hints, &listp)) != 0) {
fprintf(stderr, "getaddrinfo failed (%s:%s): %s\n", hostname, port, gai_strerror(rc));
return -2;
}
/* Walk the list for one that we can successfully connect to */
for (p = listp; p; p = p->ai_next) {
/* Create a socket descriptor */
if ((clientfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Connect to the server */
if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)
break; /* Success */
if (close(clientfd) < 0) { /* Connect failed, try another */ //line:netp:openclientfd:closefd
fprintf(stderr, "open_clientfd: close failed: %s\n", strerror(errno));
return -1;
}
}
/* Clean up */
freeaddrinfo(listp);
if (!p) /* All connects failed */
return -1;
else /* The last connect succeeded */
return clientfd;
}
생각보다 무한도전에 아찔 짤이 없다...
분석할 생각하니 진짜 아찔하다.
근데 보면볼수록 뭔가 말록 생각이 드는 건
왤까?

지난 주 우리 조 PPT의 커버사진이다.

대차게 까였다.
open_clientfd 함수에서 hints는 힙 메모리를 쓰지 않는다.
왜냐하면 지역변수로 선언됐기 때문이다.
내가 원한건 이런게 아니다.
좀 더 매달려봤다.

음...
memset(&hints, 0, sizeof(struct addrinfo));이는 스택 내부의 hints 주소부터 struct addrinfo의 크기만큼 초기화시키는 것이다.
그렇다면 addrinfo란 무엇일까?
addrinfo
struct addrinfo {
int ai_flags; /* AI_PASSIVE, AI_CANONNAME, AI_NUMERICHOST */
int ai_family; /* PF_xxx */
int ai_socktype; /* SOCK_xxx */
int ai_protocol; /* 0 or IPPROTO_xxx for IPv4 and IPv6 */
socklen_t ai_addrlen; /* length of ai_addr */
char *ai_canonname; /* canonical name for hostname */
struct sockaddr *ai_addr; /* binary address */
struct addrinfo *ai_next; /* next structure in linked list */
};뭐가 뭔지 모르겠으니 AI에게 설명을 들어보자.
| 필드명 | 설명 |
|---|---|
| int ai_flags | 주소 정보 검색 시 사용할 옵션 플래그. 예: AI_PASSIVE, AI_CANONNAME, AI_NUMERICHOST 등. 여러 플래그를 OR 연산으로 조합해서 사용함. |
| int ai_family | 주소 패밀리(프로토콜 종류). 예: AF_INET(IPv4), AF_INET6(IPv6), AF_UNSPEC(제한 없음) 등. |
| int ai_socktype | 소켓 타입. 예: SOCK_STREAM(TCP), SOCK_DGRAM(UDP) 등. |
| int ai_protocol | 사용 프로토콜. 일반적으로 0(자동 선택), 또는 IPPROTO_TCP, IPPROTO_UDP 등. |
| socklen_t ai_addrlen | ai_addr의 크기(바이트 단위). |
| char *ai_canonname | 호스트의 정규화된 이름(공식 호스트명). 플래그에 AI_CANONNAME이 설정된 경우에만 사용됨. |
| struct sockaddr *ai_addr | 실제 네트워크 주소 정보가 담긴 구조체 포인터. |
| struct addrinfo *ai_next | 연결 리스트의 다음 주소 정보를 가리키는 포인터. 여러 주소가 있을 때 순차적으로 접근 가능. |
익숙한 것도, 익숙하지 않은 것도 보인다.
- ai_flags
주소 정보 검색 시 사용할 옵션 플래그- AI_PASSIVE: 소켓을 패시브(수동) 오픈용으로 사용 (ex. 서버)
- AI_CANONNAME: 호스트의 공식 이름(정규화된 이름)을 반환하도록 요청함.
- AI_NUMERICHOST: hostname 인자가 반드시 숫자 주소여야 하며, 이름-주소 변환(DNS)을 하지 않음
- AI_ADDRCONFIG: 시스템 설정에 주소 유형(IPv4, IPv6)에 맞는 주소만 반환
- AI_V4MAPPED: IPv6 소켓을 사용하는 프로그램이 IPv4 주소만 제공받았을 때에도 통신이 가능하도록 해줌
- AI_ALL: 두 종류의 주소(실제 IPv6 주소와 IPv4-mapped IPv6 주소) 모두를 반환함.
얘네를 OR 연산하여 플래그를 설정한다고 보면 된다.
말록에서 주소와 할당 여부를 OR 연산으로 했던 것과 비슷하다고 생각하면 될 것 같다.
- ai_family(프로토콜 종류)
- AF_INET(IPv4)
- AF_INET6(IPv6)
- AF_UNSEPC(제한없음)
그럼 IPv4와 IPv6가 뭐고 어떤 차이가 있을까?
IPv4: 32비트 10진수 네 개로 구성(ex 192.168.1.1)
IPv6: 128비트 16진수 여덟 개 - IPv6는 무한대에 가까운 주소 공간, 헤더 구조 간소화, 기본 내장 보안, 자동 주소 할당 등의 장점을 가지고 있다.
- ai_socktype
- ai_protocol
TCP, UDP 등은 https://velog.io/@mogiyoon/Krafton-Jungle-Eighth#3-글로벌-ip-인터넷
에 간단하게 설명돼 있으니 읽어보자.
왜 TCP, UDP를 소켓 타입과 프로토콜 타입으로 구분해서 명기하는 걸까?
소켓 타입과 프로토콜 타입의 TCP/UDP (feat.AI)
사실 거의 항상 피처링은 AI긴 하다. 모든 순간이... 너였다...
-
소켓 타입
데이터 전송 방식(연결 지향형(TCP, SOCK_STREAM), 비연결지향형(UDP, SOCK_DGRAM)을 지정함. 즉 데이터가 어떻게 전송될지(신뢰성, 순서 보장, 데이터 경계 등)을 결정함 -
프토토콜 타입
실제로 어떤 네트워크 프로토콜을 사용할지 지정함. 같은 소켓 타입이라도 여러 프로토콜이 존재할 수 있기 때문에, 최종적으로 사용할 프로토콜을 명확히 지정할 필요가 있음
항상 이런 식이다. 항상 모호하게 알려준다.
그래서 섞어서 쓸 수 있냐고 물어봤다.
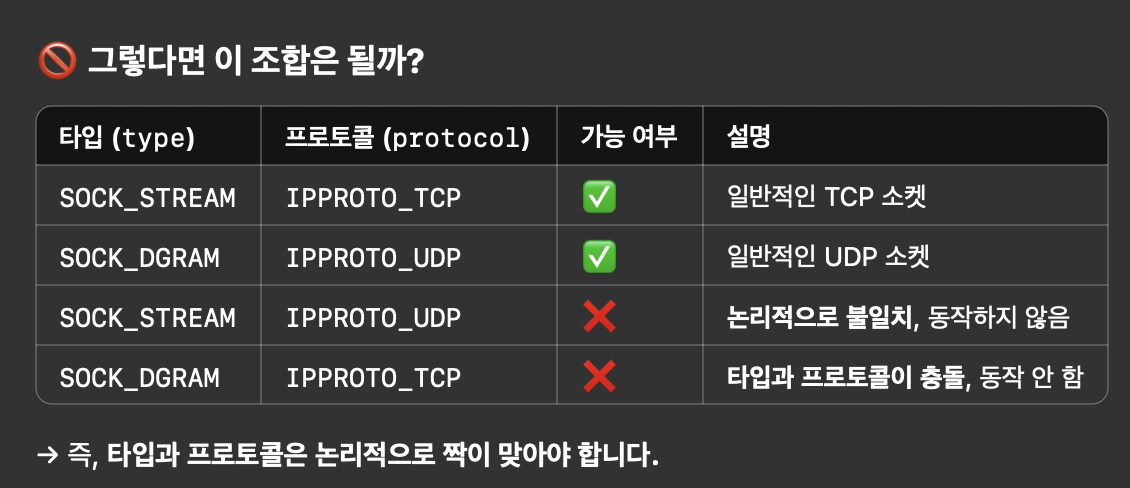
항상 이런 식이다.

라고 할 뻔~
그러니까
해당 addrinfo 데이터가 SOCK_STREAM 방식을 쓰는 소켓 타입이라는 거다.
TCP는 연결 지향형 방식 중 하나라고 생각하면 될 듯 하다.
아유 그러면 STREAM 타입과 DGRAM 타입이 뭔지도 알아봐야겠네^^
- Stream 타입
- 데이터를 보내기 전 반드시 상대방과 연결(Connect) 과정을 거칩니다.
- 데이터가 순서대로, 손실 없이, 중복 없이, 신뢰성 있게 전달됩니다.
- 데이터는 바이트 스트림(연속된 데이터 흐름)으로 전달되어, 데이터 경계가 없습니다.
- 예시: 파일 전송, 웹 브라우징, 이메일 등 신뢰성이 중요한 서비스
- Dgram 타입
- 연결 과정 없이 바로 데이터를 보낼 수 있습니다.
- 데이터가 순서대로 도착한다는 보장이 없고, 손실되거나 중복될 수 있습니다.
- 데이터는 메시지(패킷) 단위로 전송되어, 보낸 단위 그대로 도착(데이터 경계가 있음).
- 예시: 실시간 게임, 음성/영상 스트리밍, DNS 등 빠른 응답이 중요한 서비스
나는 무좍건 Stream이 좋다고 생각했는데 예시를 보니 꼭 그런 것만은 아닌 것 같다.
그리고 글을 읽어보니 Stream은 패킷 단위로 전송하는 게 아니구나~ 라고 생각했는데

스트림도 결국 패킷 단위로 쪼개져 전송되는 것은 맞다.
아유 어렵다 어려워~
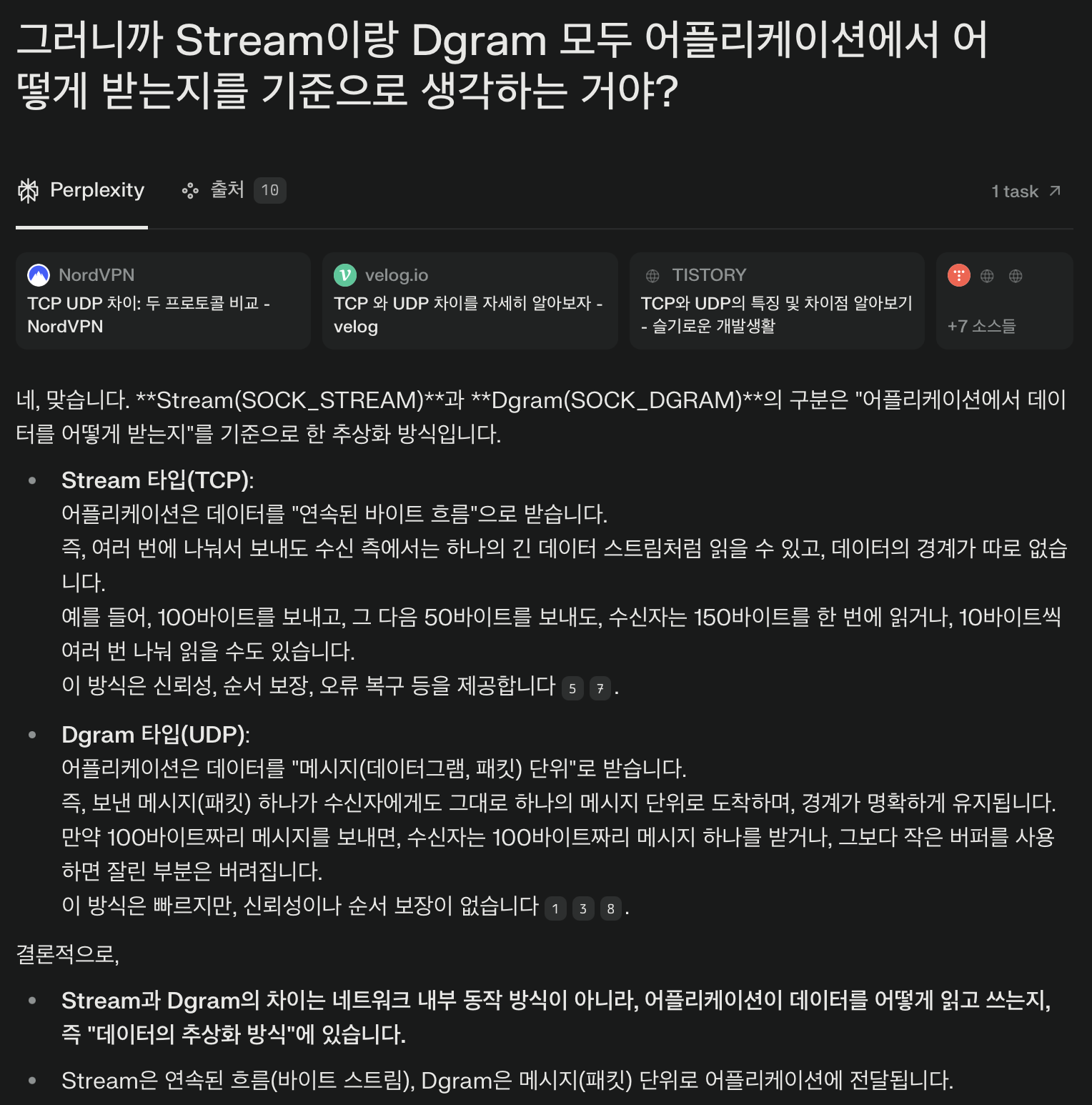

아마 이 이상 이해하려면 OSI 7계층에 대한 이해가 필요할 것 같다.
-
socklen_t ai_addrlen
은 넘어가겠다. -
char* ai_canonname
- 정규화된 이름은 호스트 이름과 도메인 이름 전체를 포함하고, 중복이나 모호함 없이 유일하게 특정 호스트를 식별할 수 있게 하며, DNS 조회 시 정확한 이름 해석을 가능하게 합니다.
- 예시: www.example.com.
-
struct sockaddr* ai_addr
- 뭐 주소겠지
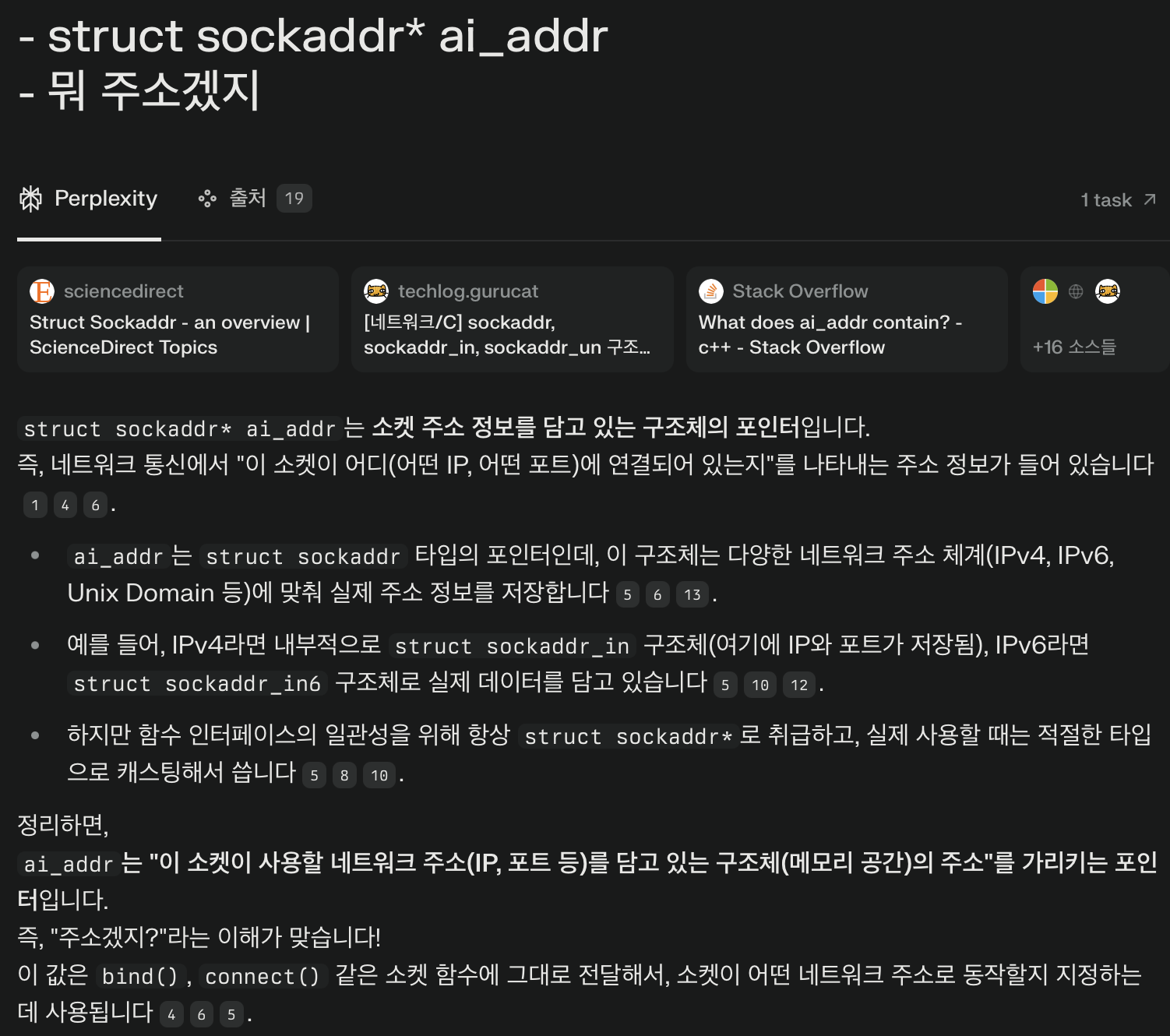 음 정확하게는 소켓 주소 정보를 담고 있다고 한다.
음 정확하게는 소켓 주소 정보를 담고 있다고 한다.
- structure addrinfo* ai_next:
- addrinfo를 링크드 리스트로 관리하나보다~
hints.ai_socktype = SOCK_STREAM; /* Open a connection */
hints.ai_flags = AI_NUMERICSERV; /* ... using a numeric port arg. */
hints.ai_flags |= AI_ADDRCONFIG; /* Recommended for connections */갈 길이 멀다. 넘어간다.
if ((rc = getaddrinfo(hostname, port, &hints, &listp)) != 0) {
fprintf(stderr, "getaddrinfo failed (%s:%s): %s\n", hostname, port, gai_strerror(rc));
return -2;
}이 녀석 마주칠 줄 알았다.
근데 함수 구조를 보려고 했더니 잘 나와있지가 않다.
...굳이굳이인가?
반환값만 알아보자.
getaddrinfo (const char* host, const char* service, const structure addrinfo* hints, structure addrinfo** result)
사람이 읽기 쉬운 도메인 주소를 컴퓨터가 통신할 수 있는 IP 주소로 변환함.
- 도메인 이름(www.google.com)이나 서비스 이름(http 또는 포트 번호)을 입력하면 해당 호스트와 서비스에 사용할 수 있는 네트워크 주소 정보(IP 주소, 포트 등)을 반환함(DNS resolving)
- 도메인 이름, 서비스 이름, 옵션(hints)에 따라 조건에 맞는 주소 정보를 addrinfo 구조체의 연결리스트 형태로 반환함.
- 반환된 결과는 소켓 생성, 연결, 바인드 등에 바로 사용 가능함.
- 반환된 메모리는 사용 후 반드시 freeaddrinfo()함수로 해제해야 함.
근데 왜 addrinfo는 연결리스트의 형태일까?
그러니까 왜? addrinfo는 여러 개가 있는 걸까?
Q. 왜 여러 개의 addrinfo가 필요한가?
A.
- 하나의 도메인에 여러 IP가 할당될 수 있음.
- 예를 들어 www.google.com은 여러 IPv4, IPv6 주소를 동시에 가질 수 있음.
- 하나의 호스트가 여러 네트워크 인터페이스(유/무선)을 사용할 수도 있음.
- 서로 다른 프로토콜/소켓 타입을 지원함
- 하나의 서비스(http)가 여러 소켓 타입(TCP, UDP 등)을 지원할 수 있음.
이 중 하나를 적절한 하나를 선택하나보다.
/* Walk the list for one that we can successfully connect to */
for (p = listp; p; p = p->ai_next)
{
/* Create a socket descriptor */
if ((clientfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Connect to the server */
if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)
break; /* Success */
if (close(clientfd) < 0)
{ /* Connect failed, try another */ //line:netp:openclientfd:closefd
fprintf(stderr, "open_clientfd: close failed: %s\n", strerror(errno));
return -1;
}
} 앞의 getaddrinfo가 뭐하는 녀석인지 어느 정도 이해했다면,
for문과 list 보자마자 뭐하는지 감이 잡혀야 한다.
우선 socket 함수나 connect 함수가 뭔지 모르겠다면
https://velog.io/@mogiyoon/Krafton-Jungle-Eighth#4-2-socket-함수
https://velog.io/@mogiyoon/Krafton-Jungle-Eighth#4-3-connect-함수
이걸 참고하자.
사실 나도 다시 참고하고 있다.
하나씩 더 뜯어서 보겠다. 주석의 설명도 참고해보자. 주석도 코드다.
/* Create a socket descriptor */
if ((clientfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */소켓 디스크립터를 만들고 있다.
addrinfo 리스트를 돌면서 소켓 디스크립터로 만들 수 있는 녀석을 찾는 것 같다.
음수일 때 continue인 것을 보면 양수인 값을 반환하는 것 같다.
혹시 떠오르는 것 있는가?
맞다.
프로세스 내에서 디스크립터는 고유 양수 번호를 가지고 있다.
따라서
/* Connect to the server */
if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)
break; /* Success */이 코드로 진행됐을 때는 둘 중 하나로 결정이 난 상태이다.
적당한 소켓 디스크립터를 반환했거나, 소켓 디스크립터를 생성하지 못한 경우이다.
따라서 음수가 아니면 제대로 생성된 것이므로
break한다.
if (close(clientfd) < 0)
{ /* Connect failed, try another */ //line:netp:openclientfd:closefd
fprintf(stderr, "open_clientfd: close failed: %s\n", strerror(errno));
return -1;
} 여기까지 왔다면 적당한 소켓을 생성하지 못한 것이고 디스크립터를 닫는 것이다.
그리고 실패하면 에러 호출한다.
Open_listenfd(char* hostname,char* port)
서버용 리스닝 수동 소켓을 반환하는 함수이다. 소켓은 클라이언드 요청에 대한 큐를 가지고 있다.
int open_listenfd(char *port)
{
struct addrinfo hints, *listp, *p;
int listenfd, rc, optval = 1;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Accept connections */
hints.ai_flags = AI_PASSIVE | AI_ADDRCONFIG; /* ... on any IP address */
hints.ai_flags |= AI_NUMERICSERV; /* ... using port number */
if ((rc = getaddrinfo(NULL, port, &hints, &listp)) != 0)
{
fprintf(stderr, "getaddrinfo failed (port %s): %s\n", port, gai_strerror(rc));
return -2;
}
/* Walk the list for one that we can bind to */
for (p = listp; p; p = p->ai_next)
{
/* Create a socket descriptor */
if ((listenfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Eliminates "Address already in use" error from bind */
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, // line:netp:csapp:setsockopt
(const void *)&optval, sizeof(int));
/* Bind the descriptor to the address */
if (bind(listenfd, p->ai_addr, p->ai_addrlen) == 0)
break; /* Success */
if (close(listenfd) < 0)
{ /* Bind failed, try the next */
fprintf(stderr, "open_listenfd close failed: %s\n", strerror(errno));
return -1;
}
}
/* Clean up */
freeaddrinfo(listp);
if (!p) /* No address worked */
return -1;
/* Make it a listening socket ready to accept connection requests */
if (listen(listenfd, LISTENQ) < 0)
{
close(listenfd);
return -1;
}
return listenfd;
}open_clientfd와 비슷한 느낌이 든다.
memset과 hints 부분은 앞을 참고하자.
if ((rc = getaddrinfo(NULL, port, &hints, &listp)) != 0)
{
fprintf(stderr, "getaddrinfo failed (port %s): %s\n", port, gai_strerror(rc));
return -2;
}여기 부분 역시 앞에서 설명했던 내용이다. 다만 host 부분이 NULL이다.
이렇게 getaddrinfo의 host 부분을 NULL로 설정하고 옵션을 AI_PASSIVE로 지정하면
소켓은 INADDR_ANY(IPv4: 0.0.0.0, IPv6: ::)와 bind 하게된다.
이는 모든 네트워크 인터페이스의 모든 IP 주소에서 들어오는 연결을 모두 수신할 수 있다.
/* Walk the list for one that we can bind to */
for (p = listp; p; p = p->ai_next)
{
/* Create a socket descriptor */
if ((listenfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Eliminates "Address already in use" error from bind */
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, // line:netp:csapp:setsockopt
(const void *)&optval, sizeof(int));
/* Bind the descriptor to the address */
if (bind(listenfd, p->ai_addr, p->ai_addrlen) == 0)
break; /* Success */
if (close(listenfd) < 0)
{ /* Bind failed, try the next */
fprintf(stderr, "open_listenfd close failed: %s\n", strerror(errno));
return -1;
}
}여기는 비슷하면서 다르다.
우선
if ((listenfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */여기서 리스트를 돌며 적당한 소켓을 생성하고 listen 파일 디스크립터에 할당한다.
그리고 새로운 함수가 등장한다.
setsockopt(int socket, int level, int optname, const void* optval, socklen_t optlen)
소켓의 동작 방식을 제어하기 위해 소켓의 다양한 옵션 값을 설정하는 함수.
- socket: 옵션을 설정할 소켓 디스크립터
- level: 옵션의 레벨
- optname: 설정할 옵션의 이름
- optval: 옵션 값이 저장된 버퍼의 포인터
- optlen: 옵션 값 버퍼의 크기
| level | optname | 설명 |
|---|---|---|
| SOL_SOCKET | SO_REUSEADDR | 주소 재사용 허용 |
| SOL_SOCKET | SO_KEEPALIVE | keepalive 패킷 사용 |
| SOL_SOCKET | SO_BROADCAST | 브로드캐스트 허용 |
| SOL_SOCKET | SO_RCVBUF | 수신 버퍼 크기 설정 |
| SOL_SOCKET | SO_SNDBUF | 송신 버퍼 크기 설정 |
| IPPROTO_TCP | TCP_NODELAY | Nagle 알고리즘 비활성화 |
| IPPROTO_IP | IP_TTL | IP 패킷의 TTL(Time To Live) 설정 |
| IPPROTO_IP | IP_MULTICAST_TTL | 멀티캐스트 패킷의 TTL 설정 |
if (bind(listenfd, p->ai_addr, p->ai_addrlen) == 0)
break; /* Success */bind를 통해서 서버 커널에 연결된 서버 디스크립터에 listp의 주소를 바인딩한다.
근데 listp에 있는 주소들은 호스트가 NULL인 주소들이다
그래서 bind되는 주소들은 0.0.0.0이나 ::가 아닐까 생각했다.
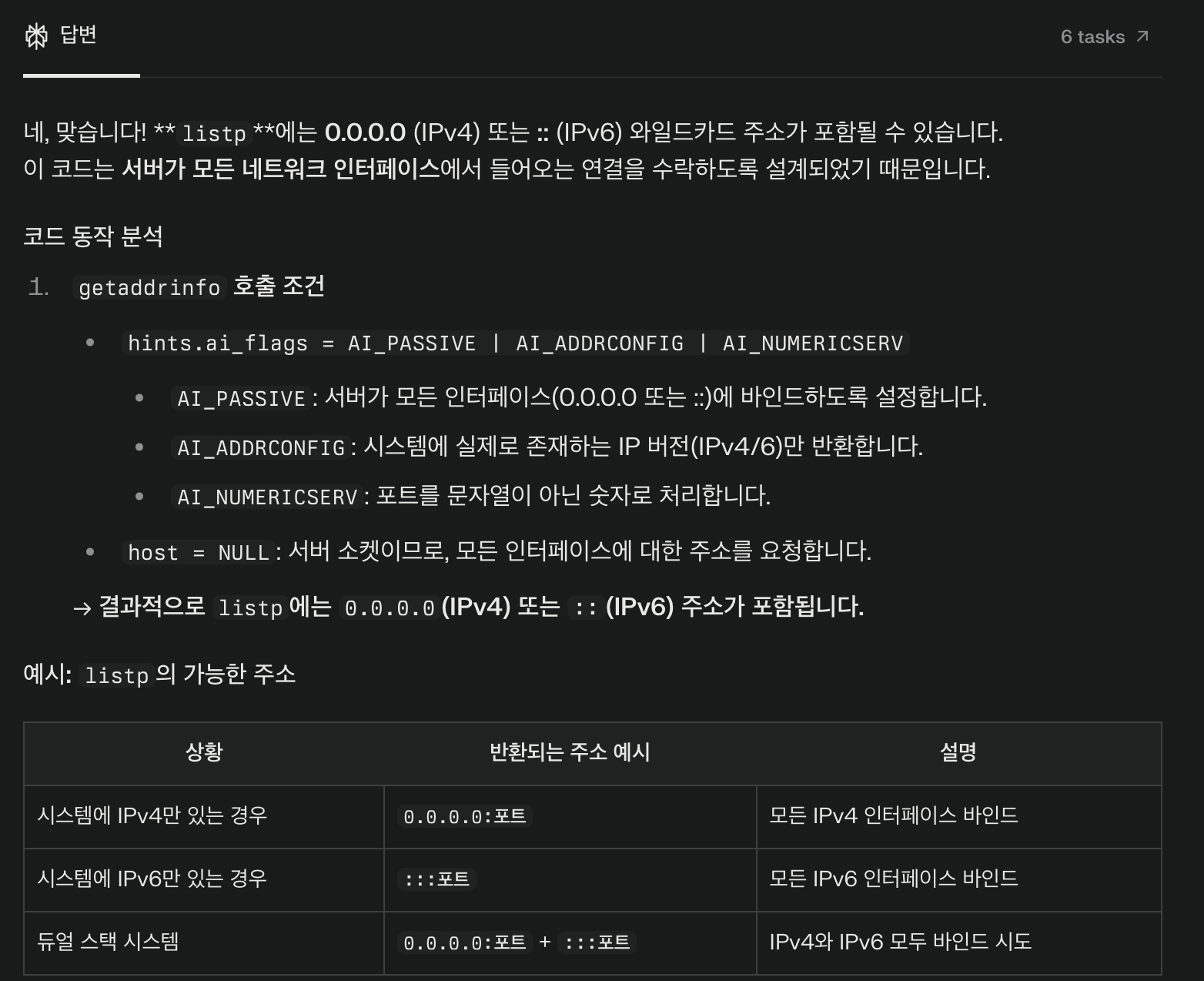 다른 주소도 포함될 수 있다고 한다.
다른 주소도 포함될 수 있다고 한다.
if (close(listenfd) < 0)
{ /* Bind failed, try the next */
fprintf(stderr, "open_listenfd close failed: %s\n", strerror(errno));
return -1;
}에러 처리 구문이다.
if (listen(listenfd, LISTENQ) < 0)
{
close(listenfd);
return -1;
}listen 함수는 어떤 녀석일까?
int listen(int socket, int backlog);소켓을 '클라이언트의 연결 요청을 받을 수 있는 상태'로 전환하는 함수라고 한다.
listen을 호출하면 해당 소켓은 "수동 소켓"이 되어 클라이언트의 연결 요청을 받을 준비가 된다.
backlog는 연결 대기 큐에 쌓일 수 있는 최대 연결 요청 수를 의미한다.
그리고 이 소켓을 반환한다.
Rio_readinitb(rio_t* rp, int fd)
void Rio_readinitb(rio_t *rp, int fd)
{
rio_readinitb(rp, fd);
} 다시 타고 넘어가서
void rio_readinitb(rio_t *rp, int fd)
{
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
}rio_t의 구조를 확인해보자.
struct rio_t
#define RIO_BUFSIZE 8192
typedef struct {
int rio_fd; /* Descriptor for this internal buf */
int rio_cnt; /* Unread bytes in internal buf */
char *rio_bufptr; /* Next unread byte in internal buf */
char rio_buf[RIO_BUFSIZE]; /* Internal buffer */
} rio_t;- int rio_fd: 해당 구조체와 관련된 파일 디스크립터를 저장함
- int rio_cnt: 내부 버퍼에 남아 있는, 아직 읽지 않은 바이트 수를 저장함
- char *rio_bufptr: 내부 버퍼에서 다음에 읽을 위치를 가리키는 포인터
- char rio_buf[RIO_BUFSIZE]: RIO_BUFSIZE만큼의 실제 데이터를 임시로 저장하는 버퍼
여기서 버퍼는 rio_fd에 저장된 파일 디스크립터를 통해 데이터를 읽어오거나 쓴다.
그렇다면 다시 readinitb로 가보자.
void rio_readinitb(rio_t *rp, int fd)
{
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
}rio_fd에 파일 디스크립터를 할당하고
바이트 수를 0으로 초기화한 뒤,
버퍼가 읽는 위치(rio_bufptr)를 버퍼 저장 주소의 첫 주소(rio_buf)로 초기화했다.
rio_buf[]는 배열이므로 rio_buf는 배열의 첫 주소를 가리킨다.
Rio_writen(int fd, void* usrbuf, size_t n)
unbuffered robust I/O
usrbuf에서 n크기의 데이터를 가져와서 fd(파일 디스크립터)에 쓰고
모든 데이터를 성공적으로 쓸 때까지 반복하기 때문에 항상 n을 반환하며, 에러가 발생하면 -1을 반환한다.
void Rio_writen(int fd, void *usrbuf, size_t n)
{
if (rio_writen(fd, usrbuf, n) != n)
unix_error("Rio_writen error");
}타 넘
ssize_t rio_writen(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nwritten;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nwritten = write(fd, bufp, nleft)) <= 0) {
if (errno == EINTR) /* Interrupted by sig handler return */
nwritten = 0; /* and call write() again */
else
return -1; /* errno set by write() */
}
nleft -= nwritten;
bufp += nwritten;
}
return n;
}해석의 시간이다.
ㅠ

- nelft: 남은 쓰기 바이트 수를 의미한다.
- nwritten: 실제로 쓰인 바이트 수를 의미한다.
- bufp: 현재 쓰기 위치 포인터를 의미한다.
따라서 while문이 도는 동안(남은 쓰기 바이트 수가 남은 동안) 시스템 콜 write()를 호출해서 쓴다.
그럼 어디에 무엇을 쓰느냐?
ssize_t write(int fd, const void *buf, size_t count);파일 디스크립터(fd)에 buf 위치(bufp)에서 가져온 데이터를 count(nleft)바이트만큼 쓴다.
write는 기록한 바이트 크기만큼 반환하기 때문에
음수값이 반환됐을 경우 nwritten을 초기화하고 다시 fd에 쓴다.
만약 쓰기가 성공적으로 이뤄졌을 경우
남은 쓰기 바이트에서 실제로 쓴 바이트만큼 빼고,
버퍼 위치를 쓴 바이트만큼 옮긴다.
에러가 생기면 -1을, 제대로 다 쓰면 쓴만큼 반환한다.
Rio_read(rio_t* rp, char* usrbuf, size_t n)
buffered robust I/O
rio 버퍼에서 usrbuf에 n크기만큼의 데이터를 옮기거나
fd에서 읽은 값을 rio 버퍼로 옮겼다가 다시 usrbuf로 옮기는 함수로
옮긴 데이터 크기만큼 반환한다.
static ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n)
{
int cnt;
while (rp->rio_cnt <= 0)
{ /* Refill if buf is empty */
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf));
if (rp->rio_cnt < 0)
{
if (errno != EINTR) /* Interrupted by sig handler return */
return -1;
}
else if (rp->rio_cnt == 0) /* EOF */
return 0;
else
rp->rio_bufptr = rp->rio_buf; /* Reset buffer ptr */
}
/* Copy min(n, rp->rio_cnt) bytes from internal buf to user buf */
cnt = n;
if (rp->rio_cnt < n)
cnt = rp->rio_cnt;
memcpy(usrbuf, rp->rio_bufptr, cnt);
rp->rio_bufptr += cnt;
rp->rio_cnt -= cnt;
return cnt;
}읽는다.
해석하기 전에 read() 시스템 콜을 먼저 이해하자.
ssize_t read(int fd, void *buf, size_t count);rio 버퍼가 비어있을 때, 파일 디스크립터(fd)로부터 데이터를 count바이트만큼 읽고 buf에 저장한다.
따라서
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf));rio_fd로부터 rio_buf의 크기만큼을 읽고 rio_buf에 저장한 뒤
그만큼 rio_cnt를 늘린다.
즉, rio_buf를 리필한다고 보면된다.
만약 rio_cnt가 음수일 경우 시그널로 인한 중단이 아닐 경우 -1을 반환하고
rio_cnt가 0일 경우에는 파일의 끝에 도달했다는 것을 의미한다.
rio_cnt가 양수일 경우. 즉, fd에서 읽어서 버퍼에 저장된 데이터가 있을 경우
rio_bufptr(읽을 위치)를 rio_buf로 초기화시킨다.
읽을 바이트 크기(cnt)를 rio_read가 읽을 바이트 크기(n)로 맞추고
if (rp->rio_cnt < n)
cnt = rp->rio_cnt;만약 rio_read가 읽을 바이트 크기(n)가 버퍼 데이터 크기(rio_cnt)보다 클 경우,
읽을 바이트 크기(cnt)를 버퍼 데이터 크기(rio_cnt)로 수정한다.
memcpy를 사용하여 rio 버퍼에서 유저버퍼에 cnt 크기만큼 복사한다.
그리고 rio버퍼에서 다음 읽을 위치(rio_bufptr)를 cnt만큼 증가시키고
rio의 데이터 크기를 cnt만큼 줄인다.
그리고 읽은 버퍼 데이터 크기(cnt)를 반환한다.
Rio_readlineb(rio_t* rp, void* usrbuf, size_t maxlen)
buffered robust I/O
rio_read를 사용하여 한 글자씩 읽고 usrbuf으로 옮긴다.
최종적으로 한 줄을 옮긴 뒤, 옮긴 크기만큼 반환한다.
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
{
int n, rc;
char c, *bufp = usrbuf;
for (n = 1; n < maxlen; n++)
{
if ((rc = rio_read(rp, &c, 1)) == 1)
{
*bufp++ = c;
if (c == '\n')
{
n++;
break;
}
}
else if (rc == 0)
{
if (n == 1)
return 0; /* EOF, no data read */
else
break; /* EOF, some data was read */
}
else
return -1; /* Error */
}
*bufp = 0;
return n - 1;
}다시 하나씩 해석해보자.
*bufp = usrbuf;우선 bufp 포인터에 usrbuf의 주소를 저장한다.
for (n = 1; n < maxlen; n++)maxlen 크기만큼 반복한다.
if ((rc = rio_read(rp, &c, 1)) == 1)rio_read를 이용해서 rio 버퍼에서 한 글자를 읽어와 char c에 저장한다.
*bufp++ = c;유저 버퍼에 한 글자씩 저장하고 bufp(유저 버퍼에서 쓰는 위치)를 한 칸씩 이동한다.
if (c == '\n')
{
n++;
break;
}그러다 개행 문자를 만나면 for 문을 종료한다. 즉, rio_readlineb는 rio 버퍼에서 한 줄씩 읽어와서 유저 버퍼에 저장하는 함수이다.
만약 읽을 글자가 없을 경우(rc==0)
1. n이 하나도 증가하지 않았다면 파일의 끝부분이므로 0을 리턴한다.
2. n이 증가했다면 읽은 데이터가 있기 때문에 리턴하지 않고 for문을 break한다.
3. 다른 경우에는 에러가 발생한 것이므로 -1을 리턴한다.
*bufp = 0;
return n - 1;유저 버퍼의 마지막 부분에 0(널문자)을 넣고
읽은 바이트만큼을 리턴한다.
echo
책에 있는 것 그대로 따라했더니 잘 된다.
gcc로 컴파일 하기도 귀찮아서
proxy랑 tiny의 make파일을 참고해서 gpt랑 같이 echo의 makefile도 만들었다.
프로그래밍하면 CMakefile이 항상 보였던 거 같은데(플러터나 리액트 네이티브)
다음에는 CMakefile에 대해서도 알아봐야겠다.
echo는 총 4개의 파일이 필요하다.
csapp.c, csapp.h, echoclient.c, echoserveri.c
혹시 파일 이름이 다른 게 있고 만약 makefile을 쓸 예정이라면
makefile에서 변경하면 되겠다.
Makefile
CC = gcc
CFLAGS = -O0 -Wall -I . -g
# CFLAGS = -O2 -Wall -I . -g
# This flag includes the Pthreads library on a Linux box.
# Others systems will probably require something different.
LIB = -lpthread
all: echoclient echoserveri
csapp.o: csapp.c csapp.h
$(CC) $(CFLAGS) -c csapp.c
echoclient: echoclient.c csapp.o
$(CC) $(CFLAGS) -o echoclient echoclient.c csapp.o $(LIB)
echoserveri: echoserveri.c csapp.o
$(CC) $(CFLAGS) -o echoserveri echoserveri.c csapp.o $(LIB)
clean:
rm -f *.o echoclient echoserveri *~우리반 똑띠가 실수로 gcc를 잘못쳐서 파일을 날렸다고 하길래 make 파일을 만들었다.
나는 높은 확률로 잘못칠 예정이기 때문이다.
client
#include "csapp.h"
int main(int argc, char ** argv)
{
int clientfd;
char *host, *port, buf[MAXLINE];
rio_t rio;
if (argc != 3)
{
fprintf(stderr, "usage: %s <host> <port>\n", argv[0]);
exit(0);
}
host = argv[1];
port = argv[2];
clientfd = Open_clientfd(host, port);
Rio_readinitb(&rio, clientfd);
while (Fgets(buf, MAXLINE, stdin) != NULL)
{
Rio_writen(clientfd, buf, strlen(buf));
Rio_readlineb(&rio, buf, MAXLINE);
Fputs(buf, stdout);
}
Close(clientfd);
exit(0);
}한 줄씩 파헤쳐보자.
clientfd
int clientfd;줄임말이다. 무엇의? client file descriptor의.
클라이언트가 socket 함수를 통해 소켓을 생성하면,
해당 소켓을 식별할 수 있는 정수값(파일디스크립터)을 반환하는데 그 값이 clientfd이다.
나머지 선언된 친구들은 밑에 함수를 파헤치면서 확인해보자.
if (argc != 3)
{
fprintf(stderr, "usage: %s <host> <port>\n", argv[0]);
exit(0);
}아르그크가 3이 아닐 때, 에러 메시지를 보여주고 프로그램을 종료하는 것 같다.
아르그크가 뭘까?
매개변수에서 왔는데, argv도 같이 있다.
아르그브도 알아보자.
argc
argc란?
argument count의 약자로, 프로그램 실행 시 전달된 인수의 개수를 나타내는 정수
항상 최소 1이상의 값을 가지며, 0번 인덱스에는 실행 파일의 이름이 들어감.
실제로 입력한 인수의 개수는 argc-1임.
즉 아르그크가 3이라는 건 입력한 인수가 2개라는 의미이다. 0번 인덱스에는 실행 파일의 이름이 들어가기 때문이다.
인수는 언제 들어가야할까? 바로 파일을 실행할 때이다.
어떤 형식으로 들어가는가? 그리고 어떻게 사용이 되는가?
그건 이제 argv와 관련이 있다.
argv
아~르그브는 무엇일까?
argv란?
argument vector의 약자로, 명령행 인수들을 문자열 배열(포인터 배열)로 저장함
실행 가능파일을 실행시킬 때 ./example a b c ... 이런 형태로 실행시킨다.
여기서 example(실행 파일 이름), a, b, c ...이 argument가 된다.
따라서 argument vector는 이 argument들을 가리키게 되고
argument의 수가 argument count가 되는 것이다.
위의 예시에서는 argv[1] == a, argv[2] == b ...이 될 것이다.
우리는 make를 통해 생성된 echoclient를 ./echoclient로 실행시킬 것이다.
이 때, ./echoclient A B 이런 식으로 입력해야 파일이 실행된다는 얘기이다.
그렇다면 어떤 인수가 2개가 들어와야할까?
위 코드에서 살펴보면
host = argv[1];
port = argv[2];
라고 되어있다.
즉, 첫 번째 인수는 호스트이고, 두 번째 인수는 포트이다.
./echoclient host port
로 입력을 해야 실행이 된다는 것이다.
호스트에 대해서는 https://velog.io/@mogiyoon/Krafton-Jungle-Eighth
여기서 잠깐 다루고 지나갔다.
근데 사실 설명해보라고 하면, 정확하게 설명하기가 힘들다.
따라서 호스트와 포트에 대해서 살짝만 더 깊이 이해해보자.
HOST
호스트란?
네트워크 또는 인터넷에 연결되어 있는 컴퓨터나 기타 장치를 의미함.
호스트는 네트워크 상에서 다른 컴퓨터와 쌍방향 통신이 가능하며, 데이터를 주고받거나 서비스를 제공할 수 있음.
- IP 주소 보유: 호스트는 네트워크에서 자신을 식별할 수 있도록 고유한 IP 주소를 가짐. 이 주소를 통해 네트워크 내에서 각 호스트를 구분함.
- 역할: 호스트는 서버(서비스 제공자), 클라이언트(서비스 이용자), 또는 둘 모두의 역할을 할 수 있음.
- 호스트명: 사람이 읽기 쉬운 이름으로 IP 주소 대신 호스트를 식별하는 데 사용됨.
아마 첫 번째 인자로 들어가는 건 호스트명일 것 같은데, open_clientfd를 분석을 해보고 그 다음에 이해해보려 한다.
PORT
포트란?
네트워크에서 운영체제 통신의 종단점이자, 한 컴퓨터 내에서 실행 중인 여러 네트워크 서비스(프로세스)를 구분하기 위한 논리적인 식별자임.
- 역할: IP 주소가 네트워크 상의 특정 컴퓨터를 식별한다면, 포트 번호는 그 컴퓨터 내에서 어떤 프로그램(서비스)과 통신할지 지정함. 예를 들어, 한 컴퓨터에서 웹 서버와 메일 서버가 동시에 실행 중일 때, 각각 다른 포트 번호(80, 25)를 사용해 구분함.
- 포트 번호의 범위
- 0~1023: 잘 알려진 포트(HTTP: 80, HTTPS: 443)
- 1024-49151: 등록된 포트(Registered port)
- 49152~65535: 동적/사설 포트
두 번째 인자로 들어가는 건 번호일 것 같다. 아무 번호나 입력해도 될 지는... 모르겠다.
clientfd는 Open_clientfd 함수의 반환값을 받고 있는데,
앞서 설명했듯이
소켓 파일 디스크립터를 생성해서 연결까지 끝내고 반환하고 있다.
해당 함수에는 버퍼가 두 개가 있는데,
rio형의 RIO의 버퍼와 char 형의 사용자 버퍼가 있다.
Rio init함수는 rio라는 버퍼를 초기화하고 clientfd와 연결한다.
Fgets
Fgets는 문자열을 입력받을 때 사용하는 표준 라이브러리 함수로, 함수 원형은 다음과 같다.
char* fgets(char* str, int size, FILE* stream)str: 입력받은 문자열을 저장할 버퍼
size: 입력받을 최대 문자 수
stream: 입력 스트림(표준 입력: stdin)
Fputs
Fputs는 파일이나 표준 출력(화면) 같은 출력 스트림에 문자열을 쓰는 표준 라이브러리 함수로,
int fputs(const char *str, FILE *stream);str: 출력할 문자열
stream: 문자열을 쓸 대상
이 된다.
다시 코드로 돌아와서
while (Fgets(buf, MAXLINE, stdin) != NULL)
{
Rio_writen(clientfd, buf, strlen(buf));
Rio_readlineb(&rio, buf, MAXLINE);
Fputs(buf, stdout);
}즉, 입력 받은 문자열을 버퍼에 저장하고
Rio_writen에서 buf에 있는 크기만큼 clientfd에 쓴다.
현재 clientfd는 소켓과 연결되어 있으므로 서버로 데이터를 보내는 것이다.
그리고 Rio_readlineb는 rio에서 한 줄씩 읽어와서 buf에 저장한다.
저장된 buf는 Fputs를 통해 표준 출력 디스크립터에 출력된다.
근~데 여기서 궁금한게 생긴다.
rio에 있는 값들은 갑자기 어디서 튀어나온 것인가?
아마 서버로부터 온 데이터가 아닐까 싶다.
그렇다면 serveri 코드도 살펴봐야될 듯하다.
serveri
#include "csapp.h"
void echo(int connfd);
int main(int argc, char** argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
char client_hostname[MAXLINE], client_port[MAXLINE];
if (argc != 2)
{
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
while (1)
{
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen);
Getnameinfo((SA*) &clientaddr, clientlen, client_hostname, MAXLINE, client_port, MAXLINE, 0);
printf("Connected to (%s, %s)\n", client_hostname, client_port);
echo(connfd);
Close(connfd);
}
exit(0);
}serveri 역시 client처럼 인수를 하나 받는데, 바로 포트값이다.
그리고 Open_listenfd를 통해 연결 대기 중인 소켓을 할당받고
Accept 함수를 통해서 리스닝 소켓(listenfd)의 연결 대기 큐에 있던 클라이언트 요청을 바탕으로
새로운 소켓(connfd)에 클라이언트의 정보를 저장하고 반환한다.
클라이언트의 정보가 어떤 식으로 저장될 지 궁금해 물어보니


커널 내부의 소켓에 저장된다고 한다.
getnameinfo(const struct sockaddr* __restrict, socklen_t, char* __restrict, socklen_t, char* __restrict, socklen_t, int);
눈 아프게 만드는 매개변수들이다.
이 친구는 getaddrinfo의 반대로 동작하는 친구이다.
소켓 주소가 주어지면 호스트/서비스명으로 변환한다.
IP 주소를 호스트명(도메인명), 포트 번호를 서비스명(http)로 변환할 수 있다.
const struct sockaddr\* \__restrict, socklen_t,
char\* \__restrict, socklen_t,
char\* \__restrict, socklen_t,
int위부터 차례대로
소켓 주소와 그 크기
호스트명을 저장할 버퍼와 크기
서비스명을 저장할 버퍼와 크기
동작을 제어할 플래그
이다.
사람이 읽을 수 있는 방식으로 변환하기 때문에
로그에 남기거나 출력할 때 쓴다고 한다.
그 다음은 echo함수에 connfd를 넣고
닫는다.
echo
void echo(int connfd)
{
size_t n;
char buf[MAXLINE];
rio_t rio;
Rio_readinitb(&rio, connfd);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
{
printf("server received %d bytes\n", (int)n);
Rio_writen(connfd, buf, n);
}
}어디서 많이 보던 구문들이다.
Rio_readinitb(&rio, clientfd);
while (Fgets(buf, MAXLINE, stdin) != NULL)
{
Rio_writen(clientfd, buf, strlen(buf));
Rio_readlineb(&rio, buf, MAXLINE);
Fputs(buf, stdout);
}클라이언트에서 이 구문 생각이 나는가
입력할 경우 clientfd에 쓰고, rio버퍼에 있는 것을 다시 읽어서 출력하는 구문이다.
비슷한 방식으로 해석해보면
서버에서는 rio 버퍼를 읽고 바이트 수를 출력한 뒤에 다시 소켓에 버퍼를 쓴다.
결국 에코에서는
Rio_readinitb(&rio, connfd);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
{
printf("server received %d bytes\n", (int)n);
Rio_writen(connfd, buf, n);
}이 구문과
Rio_readinitb(&rio, clientfd);
while (Fgets(buf, MAXLINE, stdin) != NULL)
{
Rio_writen(clientfd, buf, strlen(buf));
Rio_readlineb(&rio, buf, MAXLINE);
Fputs(buf, stdout);
}이 구문에 의해 통신이 이루어진다고 볼 수 있다.
번외
여전히 모르겠다.
클라이언트에서 clientfd 소켓에 쓰면 야무지게 서버의 connfd 소켓의 rio 버퍼에 들어가는 걸까?
반대로
connfd 소켓에 쓰면 야무지게 clientfd 소켓의 rio 버퍼에 들어갈까
Rio_realineb의 Rio_read의 read가 그 역할을 해낸다는 것은 알겠다.
Rio_readlineb(&rio, buf, MAXLINE)타넘
rc = rio_read(rp, &c, 1)타넘
read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf)그러니까 read() 함수가 호출되는 순간 데이터를 읽어야하는 것 아닌가?
read()는 계속 데이터가 들어오는지 확인하나?
라고 생각했는데,
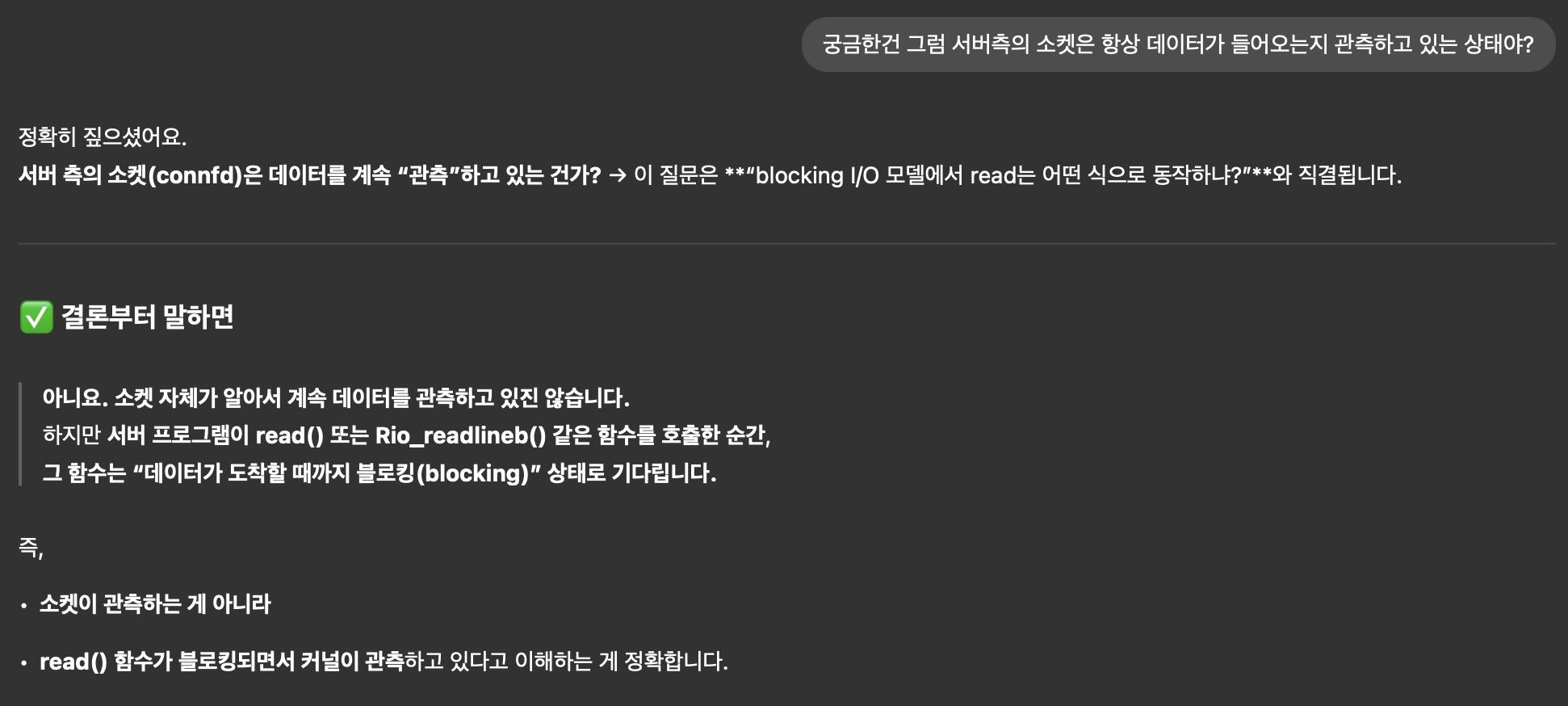
read()함수는 블로킹된 상태고, 커널이 관측하고 있다.
블로킹됐다는 말, 어디서 들어본 것 같다.
https://velog.io/@mogiyoon/Krafton-Jungle-Eighth#4-소켓-인터페이스
소켓 인터페이스에서 나오는 말이다.
그러면 이해가 된 것 같다!
번번외
[클라이언트 사용자 버퍼]
|
v
write(clientfd)
|
v
[커널 TCP 송신 버퍼] ───────► TCP 네트워크 전송 ───────► [커널 TCP 수신 버퍼]
|
v
read(connfd, rio_buf)
|
v
[서버 rio 내부 버퍼]질문하다가 뭔가 좋은게 나와서 넣었다.
번번번외
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
{
printf("server received %d bytes\n", (int)n);
Rio_writen(connfd, buf, n);
}여기에
printf("%s", buf);프린트문 하나를 추가했다.
바이트만 표시되는 건 아쉽다.
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
{
printf("server received %d bytes\n", (int)n);
printf("%s", buf);
Rio_writen(connfd, buf, n);
}그리고 서버를 돌렸다.
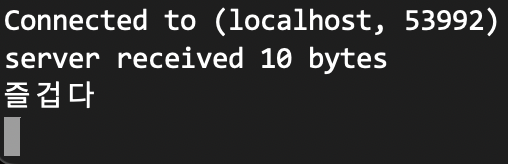
즐겁다!
tiny
tiny... 그렇지만 코드는 tiny하지 않겠지
다 안다.
베껴서 치면 되는 걸...
그걸 다르게 입력해버려서 디버깅한다고 고생했다...
아무튼 완성했다.
원래 사진은 고질라인데

(tiny 웹서버 화면)
https://namu.wiki/w/Italian%20Brainrot/등장%20캐릭터
블루베리니 옥토푸시니로 바꿨다.
브레인롯의 최대 아웃풋이라고 생각한다.
눈 정화

(tiny cgi-bin 화면) - ? 뒤에 num1=10&num2=20 이런 형태로 넣어야 한다.
눈 악화
이제 코드를 분석해보자.
int main(int argc, char** argv)
보통 메인 함수를 마지막에 설명한다.
왜냐하면 다른 기능들에 대해서 이해가 돼야 메인 함수가 이해가 되기 때문이다.
근데 이 코드에서 우리가 모르는 함수는 하나 밖에 없다.
int main(int argc, char **argv)
{
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
/* Check command line args */
if (argc != 2)
{
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}
listenfd = Open_listenfd(argv[1]);
while (1)
{
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); // line:netp:tiny:accept
Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd); // line:netp:tiny:doit
Close(connfd); // line:netp:tiny:close
}
}줄줄 설명하겠다.
if (argc != 2)
{
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}파일 실행 시 인자 1개(포트)를 입력해야 한다.
입력 인자가 1개가 아니면 종료한다.
fprintf
int fprintf(FILE* stream, const char* format, ...);fprintf 함수는 지정한 파일 스트림(stream)*에 형식화된 데이터를 출력하는 함수이다.
FILE* stream: 데이터를 출력할 대상 파일 포인터 (예: fopen으로 연 파일, stdout, stderr 등)
format: 출력 형식 지정 문자열 (예: "%d %s")
...: 출력할 값들
* 파일 스트림: 프로그램과 파일(또는 입출력 장치) 사이에서 데이터를 주고받기 위해 형성되는 데이터 흐름(통로)뭔가 파일 디스크립터랑 느낌이 비슷한데
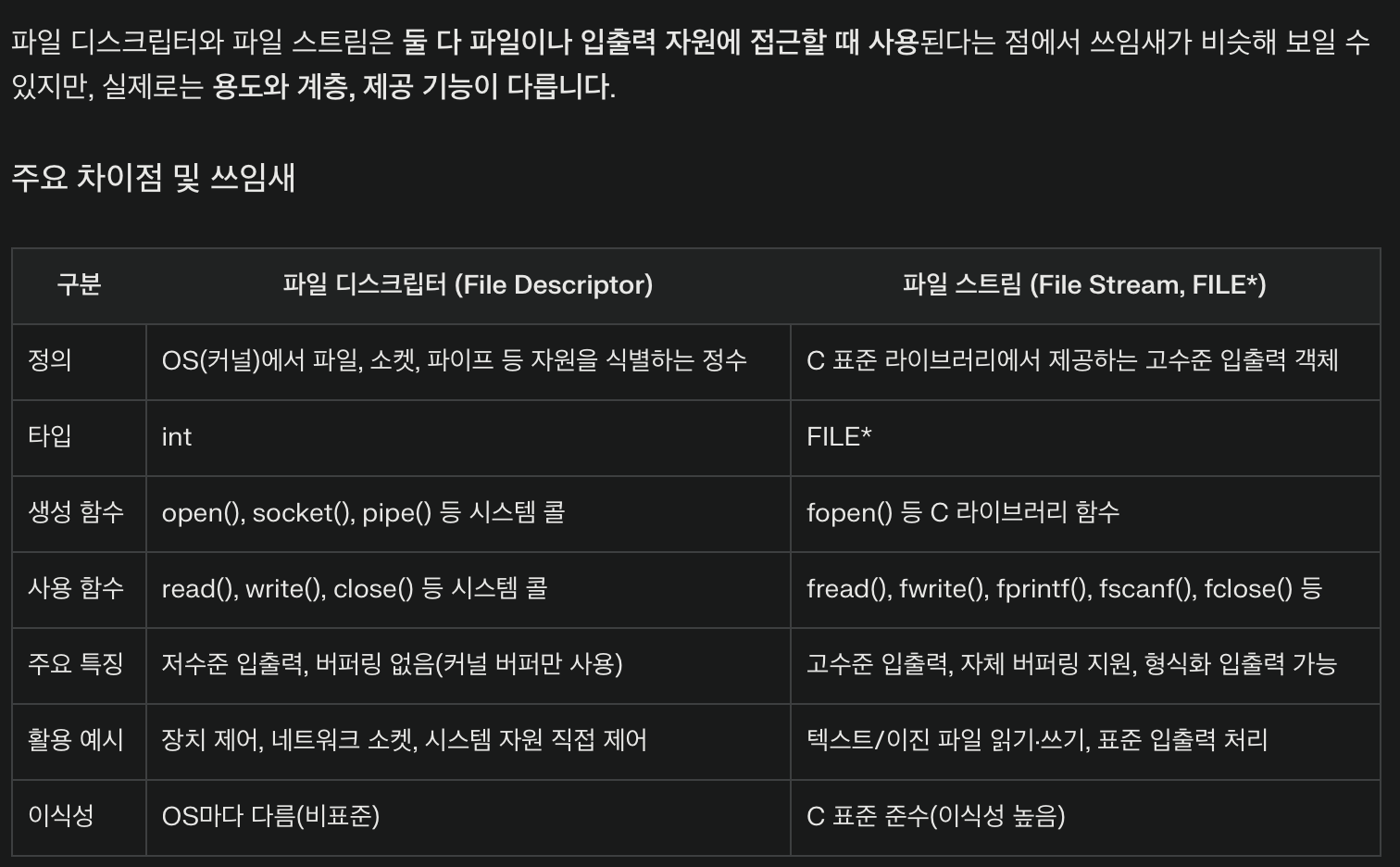
또 살짝 다르다.
아무튼 여기서는 stderr 파일 스트림에 에러 메시지를 출력하고 있다고 생각하면 된다.
listenfd = Open_listenfd(argv[1]);입력 받은 포트를 통해 리스닝 소켓을 생성한다.
while (1)
{
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); // line:netp:tiny:accept
Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd); // line:netp:tiny:doit
Close(connfd); // line:netp:tiny:close
}리스닝 소켓을 통해 클라이언트의 요청을 받고, 클라이언트의 정보를 새로운 소켓에 저장한다.
그리고 호스트 이름 및 포트를 출력한다.
그리고 새로 생성된 소켓을 doit에 넘겨준다.
그리고 닫는다.
그리고
그리고
void clienterror(int fd, char* cause, char* errnum, char* shortmsg, char* longmsg);
doit이 나올 줄 알았는가?
아니다.
doit에 가장 먼저 나오는 함수가 clienterror이기 때문에
clienterror를 먼저 설명할 예정이다.
어쩌면 doit은 가장 나중에 설명할지도 모른다.
void clienterror(int fd, char* cause, char* errnum, char* shortmsg, char* longmsg)
{
char buf[MAXLINE], body[MAXBUF];
/* Build the HTTP response body */
sprintf(body, "<html><title>Tiny Error</title>");
sprintf(body, "%s<body bgcolor=""ffffff"">\r\n", body);
sprintf(body, "%s%s: %s\r\n", body, errnum, shortmsg);
sprintf(body, "%s<p>%s: %s\r\n", body, longmsg, cause);
sprintf(body, "%s<hr><em>The Tiny Web server</em>\r\n", body);
/* Print the HTTP response */
sprintf(buf, "HTTP/1.0 %s %s\r\n", errnum, shortmsg);
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-type: text/html\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Content-length: %d\r\n\r\n", (int)strlen(body));
Rio_writen(fd, buf, strlen(buf));
Rio_writen(fd, body, strlen(body));
}sprintf
이번엔 sprintf이다. 정말 다양한 기능이 많은 프린터라고 볼 수 있겠다.
int sprintf(char *str, const char *format, ...);형식화된 데이터를 문자열 버퍼에 저장하는 함수라고 한다.
앞서 sscanf는 문자열 버퍼에서 꺼내서 변수에 할당했다고 하면,
이 함수는 그 반대의 역할을 한다고 생각하면 된다.
위에서는 body라는 버퍼 안에 값들을 넣고 있다고 생각하면 된다.
살짝 추가로 말하자면 \r\n은 캐리지리턴과 줄바꿈의 조합으로
커서를 맨 앞으로 옮겨서 줄바꿈을 하는 것이다.
특히 HTTP에서는 \r\n을 써야 줄바꿈이 인식이 된다고 한다.
/* build the http response body */ 의 결과는
<html><title>Tiny Error</title><body bgcolor="ffffff">
501: Not implemented
<p>Tiny does not implement this method.: GET
<hr><em>The Tiny Web server</em>이런 느낌이다.
/* print the http response */ 를 살펴보자.
현재 코드들은 서버에서 돌아가고 있는 코드들이다.
서버가 Rio-writen을 한다는 건 클라이언트에게 전송한다는 의미이다.
클라이언트에게는
HTTP/1.0 501 Not Implemented
Content-type: text/html
Content-length: 202
<html><title>Tiny Error</title><body bgcolor="ffffff">
501: Not Implemented
<p>Tiny does not implement this method.: POST
<hr><em>The Tiny Web server</em>위와 같이 전달이 된다.
이는 웹으로 직접 접속하거나 텔넷을 활용하는 두 가지 방식으로 확인할 수 있다.
상태 코드 200(OK)인 경우와 상태 코드 404(Not found)인 경우를 모두 확인해보자.
200
- 웹
앞서 보여준 블로베리니 옥토푸시니가 있다.
- telnet

이렇게 입력하면
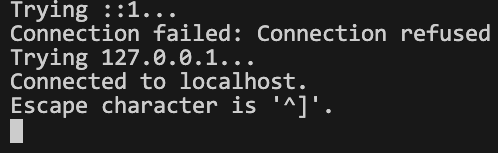
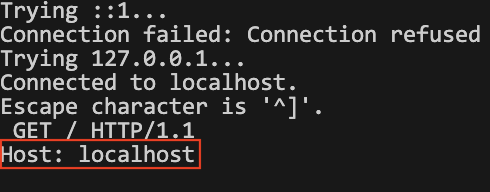
이런 형태로 나오는데 여기에
GET / HTTP/1.1
Host: localhost
(엔터 한 번 더)이렇게 입력하면 된다.
한 줄 비운 걸로 구분하기 때문에 마지막에 꼭 엔터 한 번 더 치길 바란다.
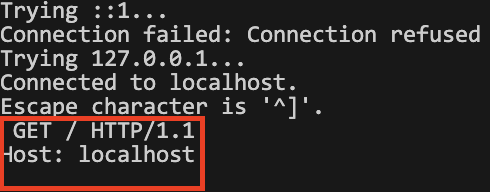
그럼
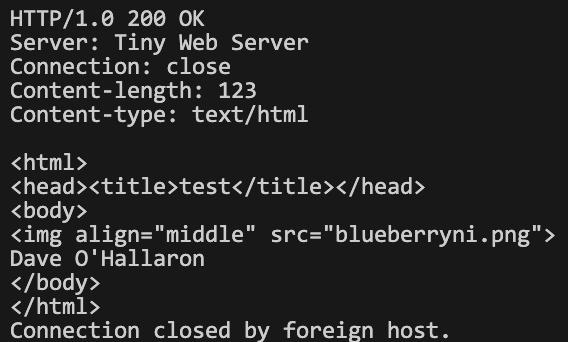
위와 같은 결과가 나온다. (src="blueberryni)
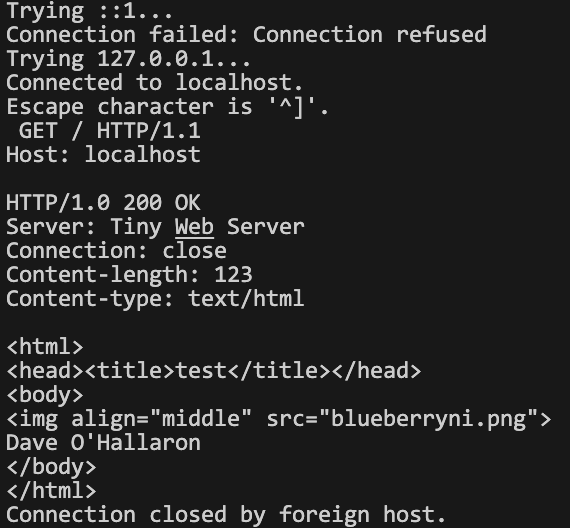 전체적으로는 이런 느낌이다.
전체적으로는 이런 느낌이다.
404
예는 에러를 위해 일부러 엉터리 페이지를 입력해야한다.
/test를 쓰겠다.
- 웹

404 Not found... 참 많이 본 문구다.

우리는 이걸 해본적이 있다.
- telnet
아까 입력했던
GET / HTTP/1.1
Host: localhost
(엔터 한 번 더)이거 대신
GET /test HTTP/1.1
Host: localhost
(엔터 한 번 더)를 입력할 예정이다.
그럼 이런 결과가 나온다.
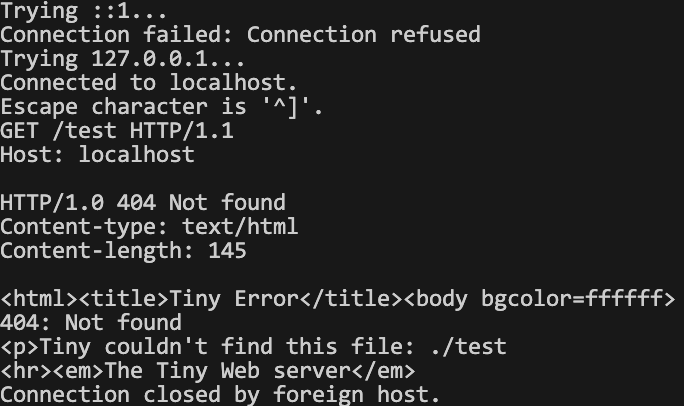
굿
void read_requesthdrs(rio_t *rp)
void read_requesthdrs(rio_t *rp)
{
char buf[MAXLINE];
Rio_readlineb(rp, buf, MAXLINE);
while(strcmp(buf, "\r\n"))
{
Rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
}
return;
}함수 이름에서 알 수 있듯이 요청 헤더를 읽는 함수다.
맨 윗줄이 요청 시작줄(request line)이고
그 아래부터 요청 헤더이다.
위에서는 한 줄로 끝났지만 더 길어지기도 한다.
코드를 보면
Rio_readlineb(rp, buf, MAXLINE);
while(strcmp(buf, "\r\n"))
{
Rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
}
return;Rio_readlineb를 통해서 한 줄씩 읽어가는데
strcmp(buf, "\r\n")인 동안 돌아간다.
strcmp
int strcmp(const char *str1, const char *str2);두 문자열이 처음부터 끝까지 모두 같을 때 0을 반환하고
그 외에는 다른 정수를 반환하는 함수이다.
strcmp(buf, "\r\n")에서
buf와 "\r\n"이 완전히 일치할 때 0을 반환하므로
완전히 일치하기 전까지는 계속 돌아간다는 의미이다.
buf는 rio_readlineb로 한 줄씩 계속 읽어오고 있으므로
한 줄 전체가 "\r\n"일 때까지, 즉 빈 줄을 만날 때까지
읽어온다는 의미이다.
그러니 Host: localhost를 입력한 뒤에 반드시 다시 엔터를 한 번 더 쳐야한다.
엥 리눅스에서 엔터는 \n 아닌가?
할 수 있겠지만
지금 HTTP 프로토콜 기반으로 통신을 하고 있으니 엔터를 치면
HTTP 클라이언트에 의해 \r\n이 되겠다.
근데 웃긴건 별다른 동작은 하지 않고
출력만 하고 리턴한다.. (첫 줄은 출력하지도 않는다.)
다른 요청 헤더는 무시한다는 의미이다.
int parse_uri(char* uri, char* filename, char* cgiargs)
uri가 동적 컨텐츠를 포함하면 0, 정적 컨텐츠이면 1을 반환하는 함수이다.
int parse_uri(char* uri, char* filename, char* cgiargs)
{
char* ptr;
if (!strstr(uri, "cgi-bin")) // Static content
{
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
if (uri[strlen(uri) - 1] == '/')
{
strcat(filename, "home.html");
}
return 1;
}
else // Dynamic content
{
ptr = index(uri, '?');
if (ptr)
{
strcpy(cgiargs, ptr+1);
*ptr = '\0';
}
else
{
strcpy(cgiargs, "");
}
strcpy(filename, ".");
strcat(filename, uri);
return 0;
}
}if (!strstr(uri, "cgi-bin"))
strstr
char *strstr(const char *haystack, const char *needle);문자열 안에서 특정 부분 문자열(서브스트링)을 찾는 함수다.
haystack은 검색 대상이 되는 문자열이고, needle은 찾고자하는 부분 문자열이다.
부분 문자열을 찾으면 그 위치를 반환한다.
따라서
if (!strstr(uri, "cgi-bin"))여기서는 uri 내부에 cgi-bin이 없다는 것을 의미한다.
{
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
if (uri[strlen(uri) - 1] == '/')
{
strcat(filename, "home.html");
}
return 1;
}strcpy
char* strcpy(char *dest, const char *src);dest 배열에 src 문자열(문자열 시작 주소부터 널문자까지)을 복사하는 함수다.
strcat
char* strcat(char *dest, const char *src);dest 배열에 src 문자열(문자열 시작 주소부터 널문자까지)을 이어붙이는 함수다.
따라서 결과적으로
cgiargs: ""
filename: .uri
처럼 되는데
if (uri[strlen(uri) - 1] == '/')uri 마지막 원소가 '/'이면
filename: ./home.html이 된다.
else
uri 내부에 cgi-bin이 있다면 동적 컨텐츠가 있다는 것을 의미하고,
{
ptr = index(uri, '?');
if (ptr)
{
strcpy(cgiargs, ptr+1);
*ptr = '\0';
}
else
{
strcpy(cgiargs, "");
}
strcpy(filename, ".");
strcat(filename, uri);
return 0;
}index
char *index(const char *str, int c);str에서 c가 처음 등장하는 위치(포인터)를 반환한다.
if (ptr)
{
strcpy(cgiargs, ptr+1);
*ptr = '\0';
}따라서 cgiargs에 ? 뒤*(ptr+1)에 있는 문자열을 복사하고
*ptr은 널문자로 만든다.
따라서
strcpy(filename, ".");
strcat(filename, uri);여기에서 filename: .uri가 되는데
?를 널문자로 바꿨으므로
filename: .uri(?전까지)가 된다.
void serve_static(int fd, char* filename, int filesize)
정적 콘텐츠 연결 성공을 표시하고 클라이언트에게 파일을 제공하는 함수이다.
void serve_static(int fd, char* filename, int filesize)
{
int srcfd;
char* srcp, filetype[MAXLINE], buf[MAXBUF];
/* Send response headers to client */
get_filetype(filename, filetype);
sprintf(buf, "HTTP/1.0 200 OK\r\n");
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length: %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype);
Rio_writen(fd, buf, strlen(buf));
printf("Response headers:\n");
printf("%s", buf);
/* Send response body to client */
srcfd = Open(filename, O_RDONLY, 0);
srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);
Close(srcfd);
Rio_writen(fd, srcp, filesize);
Munmap(srcp, filesize);
}주석이 달린 두 부분으로 나누어서 보겠다.
/* Send response headers to client */
/* Send response headers to client */
get_filetype(filename, filetype);
sprintf(buf, "HTTP/1.0 200 OK\r\n");
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length: %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype);
Rio_writen(fd, buf, strlen(buf));
printf("Response headers:\n");
printf("%s", buf);파일 타입을 얻은 뒤 버퍼에 관련 내용을 쓰고
서버 로그에 출력 및 클라이언트에게 전달하는 함수이다.
/* Send response body to client */
/* Send response body to client */
srcfd = Open(filename, O_RDONLY, 0);
srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);
Close(srcfd);
Rio_writen(fd, srcp, filesize);
Munmap(srcp, filesize);Open
파일 디스크립터의 냄새가 풀풀난다.
물어보자
int open(const char *pathname, int flags, mode_t mode); pathname: 열고자 하는 파일의 경로(문자열)
flags: 파일을 열 때의 옵션(필수)
mode: 파일 생성 시 접근 권한(선택, O_CREAT 사용 시 필요)
파일을 열거나 생성하고 파일 디스크럽터(정수값)을 반환하는 함수이다.
MMap
mmap 함수는 파일이나 디바이스의 내용을 프로세스 메모리에 직접 매핑해, 파일을 배열처럼 빠르고 효율적으로 다룰 수 있게 해주는 시스템 콜입니다. 대용량 파일 처리, 고속 입출력, 공유 메모리 등 다양한 시스템 프로그래밍에 널리 사용됩니다.
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);addr: 매핑할 메모리의 시작 주소(보통 NULL 또는 0을 넣어 시스템이 자동 지정)
length: 매핑할 메모리 영역의 크기(바이트 단위)
prot: 메모리 보호 속성 (예: PROT_READ, PROT_WRITE, PROT_EXEC)
flags: 매핑 방식 (예: MAP_SHARED, MAP_PRIVATE)
fd: 매핑할 파일의 파일 디스크립터(예: open()으로 얻은 값)
offset: 파일 내 매핑을 시작할 위치(바이트 단위, 보통 0)
srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);즉, 서버 메모리에 디스크에서 참조할 파일의 위치를 매핑한 뒤,
이를 소켓에 쓸 때 커널 버퍼에 데이터가 복사되고, 소켓에 데이터를 쓴다.
이후 매핑을 해제한다.
void serve_dynamic(int fd, char* filename, char* cgiargs)
void serve_dynamic(int fd, char* filename, char* cgiargs)
{
char buf[MAXLINE], *emptylist[] = { NULL };
/* Return first part of HTTP response */
sprintf(buf, "HTTP/1.0 200 OK\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Server: Tiny Web Server\r\n");
Rio_writen(fd, buf, strlen(buf));
if (Fork() == 0) // Child
{
/* Real server would set all CGI vars here */
setenv("QUERY_STRING", cgiargs, 1);
Dup2(fd, STDOUT_FILENO);
Execve(filename, emptylist, environ);
}
Wait(NULL);
}마찬가지로
/* Return first part of HTTP response */
sprintf(buf, "HTTP/1.0 200 OK\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Server: Tiny Web Server\r\n");
Rio_writen(fd, buf, strlen(buf));연결됐다는 표시를 클라이언트에게 전송한다.
그 밑 부분이 이해하기 까다로울 것 같다.
Fork
CS 책에서 많이 봤던 친구다. 자식 프로세스를 하나 만들었던 걸로 기억한다.
https://velog.io/@mogiyoon/Krafton-Jungle-Sixth#3-6-프로그램-실행을-위한-fork와-execve
아마 리턴값만 살펴보면 될 듯 하다.
리턴값:
- 부모 프로세스에서는 자식 프로세스의 PID(양수)를 반환
- 자식 프로세스에서는 0을 반환
- 실패 시 -1을 반환
생각해보니 리턴값도 그때 잠깐 봤었던 것 같다.
근데 리턴값이 2개다.
그렇다면 어떻게 되는 걸까?
Fork를 하면 이 코드를 실행하는 프로세스는 2개가 된다.
부모 프로세스와 자식 프로세스이다.
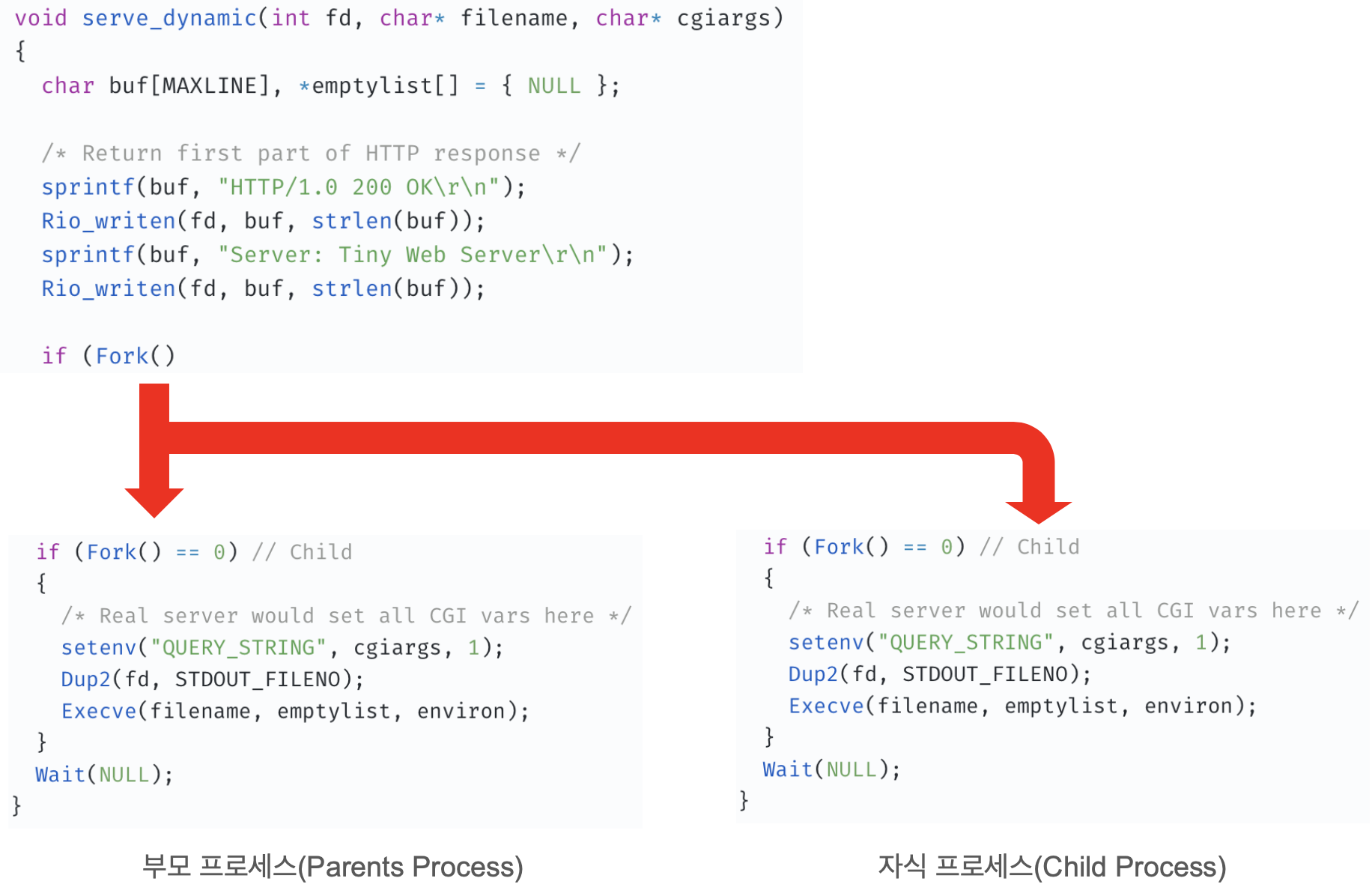
이런 느낌이다.
근데 부모 프로세스의 반환값은 양수이므로 결국 자식 프로세스만 코드를 실행하게 된다.
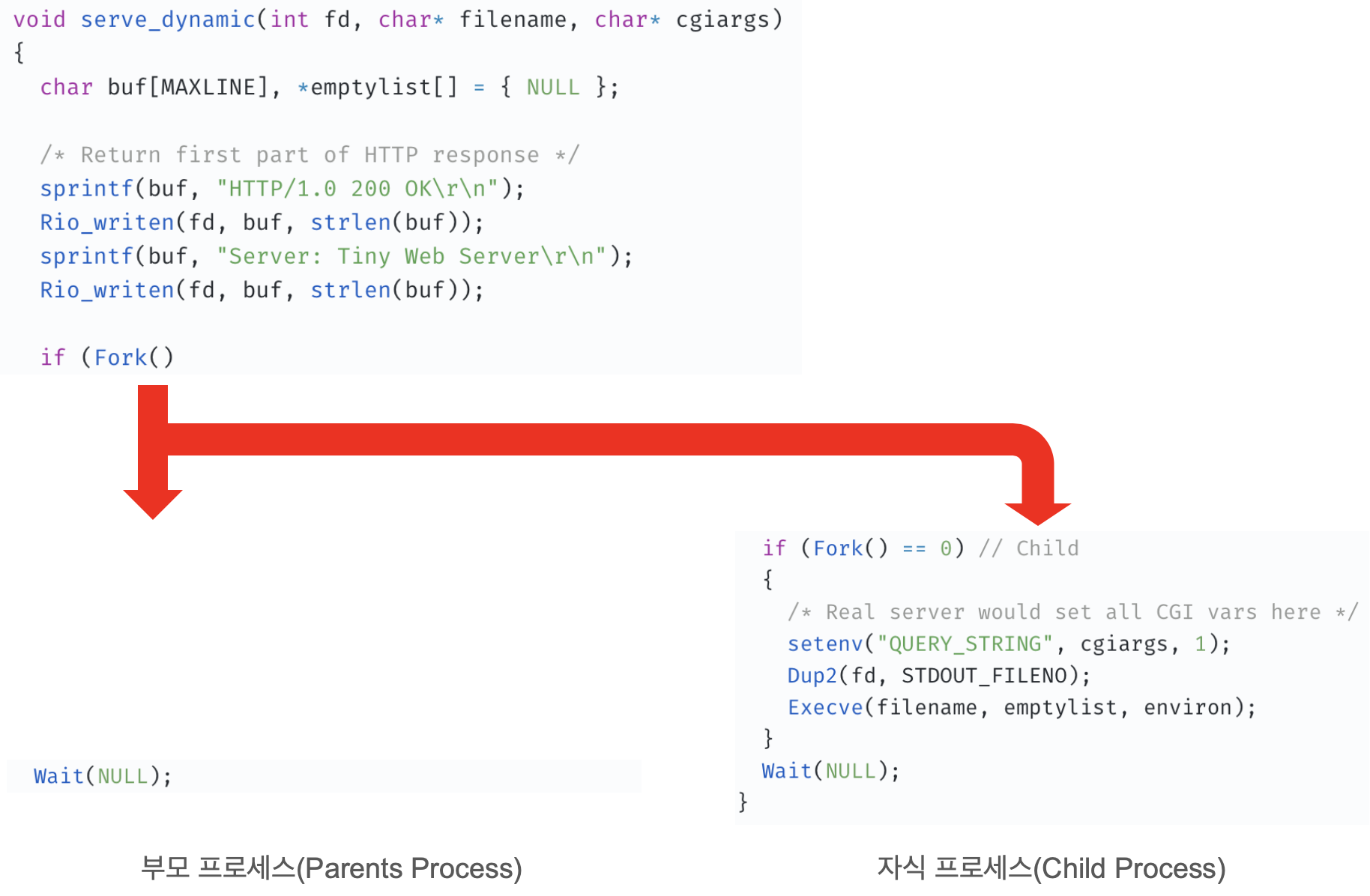
그럼 이제 자식 프로세스가 뭘 하는지 살펴보자.
setenv
setenv 함수는 C 언어에서 환경 변수를 설정하거나 수정할 때 사용하는 표준 함수입니다.
int setenv(const char *name, const char *value, int overwrite);name: 설정할 환경 변수의 이름(문자열)
value: 환경 변수에 저장할 값(문자열)
overwrite:
* 0이면, 이미 해당 이름의 환경 변수가 있을 때 값을 변경하지 않음
* 1이면, 기존 값이 있어도 새 값으로 덮어씀
setenv("QUERY_STRING", cgiargs, 1);즉, QUERY_STRING을 cgiargs로 덮어쓴다.
- QUERY_STRING란?
QUERY_STRING은 CGI(공통 게이트웨이 인터페이스) 환경에서 사용되는 표준 환경 변수로, 클라이언트(웹 브라우저 등)가 서버에 GET 방식으로 요청을 보낼 때 URL의 ? 뒤에 붙는 쿼리 파라미터(검색 문자열, name=value 쌍들)를 담고 있습니다.
표준 환경 변수?
얘는 그럼 어디에 있는 걸까?
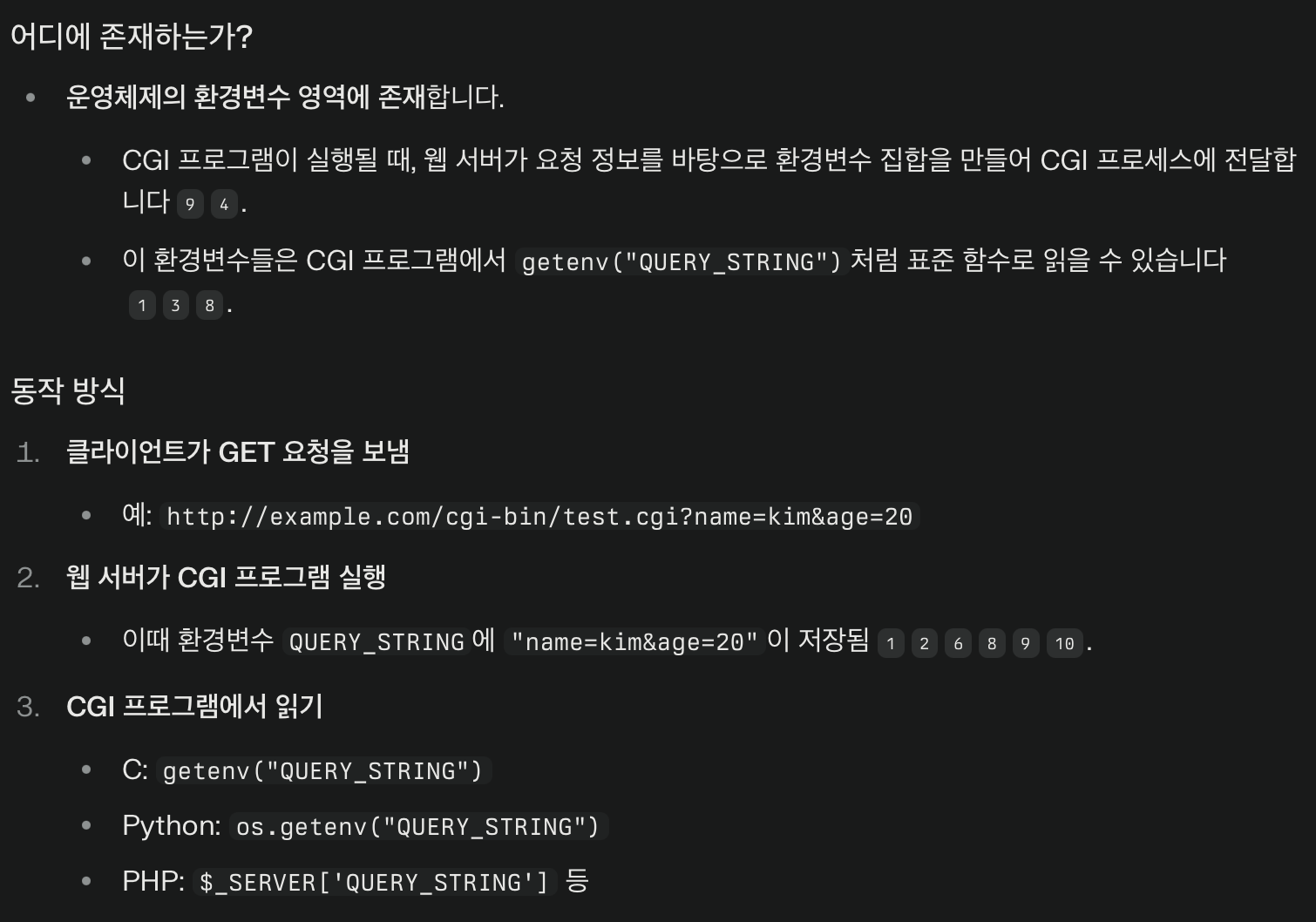
갑자기 분위기 운영체제
조금만 더 파보자.
-
운영체제의 환경변수란?
- 운영체제(윈도우, 리눅스 등)는 각 프로세스(프로그램 실행 단위)마다 "환경변수"라는 정보를 따로 관리합니다.
- 환경변수는 이름=값 쌍(예: PATH=/usr/bin) 형태로, 프로그램이 실행될 때 운영체제가 자동으로 메모리의 특정 영역(환경 영역)에 저장해줍니다.
- 이 환경변수는 프로세스가 실행 중일 때만 그 프로세스 안에서 접근 가능합니다.
-
그럼 이 환경변수라는 건 누구 마음대로 정하는 걸까?
- 운영체제/시스템이 미리 정해 놓은 환경변수
- 사용자 또는 응용프로그램이 직접 추가/수정하는 환경변수
- 프로그램 실행 시 일시적으로 만들어지는 환경변수
라고 한다. 여기서는 setenv를 통해 응용 프로그램이 만든 것이다.
그럼 왜 전역변수가 아니고 환경변수인 것일까?
우선 전역변수는 프로세스 내에서 사용가능한 변수이다.
그리고 환경변수는 부모-자식간 프로세스간 공유가 가능한 변수라고 한다.
근데, 타이니 서버와 CGI 프로그램은 부모-자식 프로세스 관계이다.
(이 부분에 대해서는 Dup2과 Execve를 통해 이해해나갈 예정이다.)
따라서 프로세스 간 변수를 공유하기 위해, 환경변수를 거치는 방법을 사용하는 것이다.
다음은 그냥 읽어보는 환경변수를 사용하는 이유이다.

Dup2
파일 디스크립터를 복사하는 시스템 콜
int dup2(int oldfd, int newfd);직관적으로 생겼다.
동작 방식
- oldfd가 참조하는 열린 파일을 newfd 번호로 복사함.
- newfd가 이미 열린 파일 디스크립터라면 닫고 복사함.
- 복사 후에는 oldfd와 newfd가 같은 파일을 가리키지만, 독립적으로 close할 수 있음.
그리고 여기서는
Dup2(fd, STDOUT_FILENO);fd가 참조하는 파일을 STDOUT_FILENO가 참조하게 한다.
그리고 STDOUT_FILENO의 정체는 '표준 출력을 나타내는 파일디스크립터'이다...!
참고로 fd는 연결 소켓을 참조하고 있다.
자식 프로세스의 표준 출력을 연결 소켓으로 만드는 과정이라 생각하면 되겠다.
Execve
현재 실행 중인 프로세스를 지정한 실행 파일로 완전히 대체하는 시스템 콜
이 친구도 예전에 본 친구다.
int execve(const char *pathname, char *const argv[], char *const envp[]);pathname: 실행하고자 하는 바이너리 파일이나 스크립트의 경로를 절대 경로나 상대 경로로 지정함.
argv[]: 실행 파일에 전달할 인자들의 배열 (main 함수의 argv와 비슷함, 마지막 원소는 반드시 NULL)
envp[]: 환경 변수 문자열 배열, 마지막은 NULL 이어야 하며 key=value 형식의 문자열을 전달함.
Execve(filename, emptylist, environ);따라서 여기서는 앞서 설명했 듯 filename: .uri(?전까지) 이다.
우리가 예시에서 입력할 동적 컨텐츠 주소는 localhost:8000/cgi-bin/adder?num1=1&num2=2 이므로
filename: ./cgi-bin/adder 이 된다.
emptylist = {NULL} 이므로 지나가고
environ은 갑자기 어디선가 튀어나온 변수다.
csapp.h에 들어가면
extern char **environ;이렇게 정의되어 있다.
environ은 현재 프로세스의 환경 변수 목록에 접근할 수 있도록 제공되는 전역 변수라고 한다.
따라서 위 내용처럼 선언만 하면, 환경 변수 목록을 가리키기 때문에 참조할 수 있다.
setenv 설정을 했다면 굳이 넘겨야되나 싶기도 했다.
물어보니, 환경 변수설정은 됐으나 execve를 사용하게 되면 명시적으로 다시 환경변수를 넘겨야 한다고 한다.
해서
자식 프로세스는
setenv("QUERY_STRING", cgiargs, 1);를 통해 환경변수가 설정되고
Dup2(fd, STDOUT_FILENO);를 통해 표준 출력도 연결 소켓으로 바뀐 뒤,
Execve(filename, emptylist, environ);를 통해 자식 프로세스를 adder 실행 프로그램으로 덮어쓰고, 환경변수를 해당 프로세스에 넘겨준다.
이제부터 doit 해보자.
void doit(int fd)
파일 디스크럽터 번호를 매개변수로 받는 두잇! 함수이다.
이름이 진짜 do it 인걸까?

우리 doit이 하고 싶은거 다해^^ 이런 느낌인가? 과하게 직관적이다.
코드를 보자.
void doit(int fd)
{
int is_static;
struct stat sbuf;
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];
char filename[MAXLINE], cgiargs[MAXLINE];
rio_t rio;
/* Read request line and headers */
Rio_readinitb(&rio, fd);
Rio_readlineb(&rio, buf, MAXLINE);
printf("Request headers:\n");
printf("%s", buf);
sscanf(buf, "%s %s %s", method, uri, version);
if (strcasecmp(method, "GET"))
{
clienterror(fd, method, "501", "Not implemented", "Tiny does not implement this method.");
return;
}
read_requesthdrs(&rio);
/* Parse URI from GET request */
is_static = parse_uri(uri, filename, cgiargs);
if (stat(filename, &sbuf) < 0)
{
clienterror(fd, filename, "404", "Not found", "Tiny couldn't find this file");
return;
}
if (is_static)
{
/* Serve static content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode))
{
clienterror(fd, filename, "403", "Forbidden", "Tiny couldn't read the file");
printf("error check: %d, %d\n", (S_ISREG(sbuf.st_mode)), (S_IRUSR & sbuf.st_mode));
return;
}
serve_static(fd, filename, sbuf.st_size);
}
else
{
/* Serve dynamic content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IXUSR & sbuf.st_mode))
{
clienterror(fd, filename, "403", "Forbidden", "Tiny couldn't run the CGI program");
return;
}
serve_dynamic(fd, filename, cgiargs);
}
}진짜 하고 싶은거 다 하는 코드가 맞는 것 같다.
먼저 rio 버퍼를 초기화하고 한 줄씩 읽어온다.
이 코드는 서버 역할을 하는 코드기 때문에
아마 클라이언트로부터 요청을 한 줄씩 읽으리라 생각한다.
sscanf(buf, "%s %s %s", method, uri, version);소켓에 가장 먼저 들어온 한 줄은
method, uri, version와 관련된 것 같다.
sscanf은 무슨 함수일까?
우선 함수 원형이다.
int sscanf(const char *str, const char *format, ...);str: 입력 문자열(파싱 대상)
format: 읽어올 데이터의 형식
...: 데이터를 저장할 변수의 주소들
즉 버퍼에 저장된 데이터를 형식에 따라서 변수의 주소들에게 저장한다.
궁금한 건, 클라이언트는 해당 서버에 접속만 했는데, 서버 소켓에 뭔가를 썼다.
이게 어떻게 가능한 걸까?
마법의 AI고동님께 물어보니


브라우저가 자동으로 요청 메시지를 전송했다고 한다.
따라서 버퍼에는 method, uri, version이 담긴다.
strcasecmp
strcasecmp는 대소문자 관계없이 같은지 비교하는 것이다.
if (strcasecmp(method, "GET"))method가 get이면 0이 반환된다.
에러가 있다면 clienterror를 통해 에러값이 출력되고, 연결 소켓에 쓴다.
read_requesthers를 통해 헤더 부분을 출력한다.
헤더는 무시된다.
parse_uri를 통해 uri, filename, cgiargs를 변경하고 동적/정적 여부를 반환하는데
-
정적인 경우
- cgiargs: "" (값이 없음)
- uri: 변화가 없다.
- filename
- ./home.html (uri가 '/'일 때)
- ./uri (uri가 '/'가 아닐 때)
-
동적인 경우
- cgiargs: ? 뒷부분
(num1=1&num2=2) - uri: ? 부분이 \0으로 바뀐다.
(cgi-bin/adder?num1=1&num2=2 => cgi-bin/adder\0num1=1&num2=2) - filename: ./uri (\0전까지)
(./adder)
- cgiargs: ? 뒷부분
stat
if (stat(filename, &sbuf) < 0)stat 함수는 파일의 다양한 상태 정보(메타데이터)를 얻기 위해 사용하는 표준 시스템 함수이다.
파일의 크기, 종류, 권한, 소유자, 마지막 접근/수정 시간 등 파일에 대한 상세 정보를 구조체(sbuf)에 채워줍니다
음수가 나오면 에러다.
S_ISREG
일반 파일인지 확인하는 POSIX 매크로이다.
이후 is_static에 따라 에러를 체크하고
S_IRUSR
파일 소유자가 파일에 대한 읽기 권한을 가지고 있는지 확인하는 POSIX 매크로이다.
S_IXUSR
파일 소유자가 파일에 대한 실행 권한을 가지고 있는지 확인하는 POSIX 매크로이다.
serve_static 혹은 serve_dynamic을 실행한다.
adder
현재 타이니 서버에서는 Execve(filename, emptylist, environ);를 통해 adder가 실행된다.
단순 더하기 프로그램이지만, 앞서 받은 매개변수들을 어떻게 활용하는지 한 번 확인해보자.
int main(void)
{
char *buf, *p;
char arg1[MAXLINE], arg2[MAXLINE], content[MAXLINE];
int n1 = 0, n2 = 0;
/* Extract the two arguments */
if ((buf = getenv("QUERY_STRING")) != NULL)
{
p = strchr(buf, '&');
*p = '\0';
strcpy(arg1, buf);
strcpy(arg2, p + 1);
n1 = atoi(strchr(arg1, '=') + 1);
n2 = atoi(strchr(arg2, '=') + 1);
}
/* Make the response body */
sprintf(content, "QUERY_STRING=%s\r\n<p>", buf);
sprintf(content + strlen(content), "Welcome to add.com: ");
sprintf(content + strlen(content), "THE Internet addition portal.\r\n<p>");
sprintf(content + strlen(content), "The answer is: %d + %d = %d\r\n<p>",
n1, n2, n1 + n2);
sprintf(content + strlen(content), "Thanks for visiting!\r\n");
/* Generate the HTTP response */
printf("Content-type: text/html\r\n");
printf("Content-length: %d\r\n", (int)strlen(content));
printf("\r\n");
printf("%s", content);
fflush(stdout);
exit(0);
}먼저
if ((buf = getenv("QUERY_STRING")) != NULL)getenv를 통해 환경변수(QUERY_STRING)를 가져와서 buf에 저장한다.
그리고 그 값이 NULL이 아닐 경우
p = strchr(buf, '&');
*p = '\0';buf에서 &의 위치를 찾고 널문자(\0)로 변경한다.
그렇게 되면, num1=1&num2=2가 num1=1\0num2=2으로 변하고
strcpy를 통해 arg1에는 num1=1, arg2에는 num2=2를 복사한다.
strchr를 통해 arg1과 arg2의 '='의 주소를 찾고, 그 다음 주소부터 문자열을 atoi에 넘긴다.
무슨 말이냐면
arg1 == "num1=1"이고 arg2 == "num2=2"인 상태인데
arg1에서 '='위치 다음은 1이고 arg2에서 '='위치 다음은 2이다.
atoi는 문자열을 정수로 변환시켜주는 함수인데,
n1 값에는 1이 n2 값에는 2가 저장된다.
숫자가 헷갈릴 수 있으니, 숫자를 바꿔서 전체 흐름을 다시 설명하겠다.
-
QUERY_STRING = "num1=10000&num2=152"
-
buf = "num1=10000&num2=152"
-
buf = "num1=10000\0num2=152"
-
arg1 = "num1=10000"
arg2 = "num2=152" -
n1 = 10000
n2 = 152
HTTP response와 response body는 앞서 많이 설명했으므로 설명하지 않겠다.
딱 하나
fflush
파일 스트림의 출력 버퍼에 남아 있는 데이터를 즉시 목적지로 내보내는 역할을 한다.
CGI에서 printf로 출력하는 내용은 버퍼에 쌓인다고 한다.
현재 파일의 표준 출력 디스크립터는 연결 소켓이므로 printf로 입력한 값들이 연결 소켓으로 출력된다.
