설계
Data Ingestion
데이터 송신 고려사항
- 안정성
- 처리량 및 속도, 지연시간
- 확장성
- 고가용성
- 지원하는 데이터 소스 커넥터
- 관리 용이성
Message Queue
메세지 지향 미들웨어(MOM)
비동기 메세지를 사용하는 다른 응용 프로그램 사이 데이터 송수신을 의미
이 MOM을 구현한 시스템을 MQ(Message Queue)라 함
프로그래밍에서 MQ는 프로세스나 프로그램이 데이터를 서로 교환할 때 사용하는 방법
데이터 교환 시 시스템이 관리하는 메세지 큐를 이용하는 것이 특징
서로 다른 프로세스, 프로그램 사이 메세지 교환 시 AMQP(Advanced Message Queuing Protocol)을 이용
Producer가 메세지 큐에 전송하면 Consumer가 처리하는 방식, 그 사이에 message 프로세스가 추가
MQ를 사용하여 비동기로 요청을 처리하고 queue에 저장하여 consumer에게 병목을 줄임
특징
- 비동기(Asynchronous)
Queue에 넣기 때문에 나중에 처리 가능 - 비동조(Decoupling)
애플리케이션과 분리 가능 - 탄력성(Resilience)
일부 실패 시 전체에 영향을 받지 않음 - (Redundancy)
실패할 경우 재실행 가능 - 보증(Guarantees)
작업 처리에 대한 확인 가능 - 확장성(Scalable)
다수의 프로세스가 큐에 메세지를 보낼 수 있음
사용자가 많아지거나 데이터가 많아지면 요청에 대한 응답을 기다리는 수가 증가
대기 시간이 지연되어 서비스가 정상적으로 되지 못하는 상황이 오기에 분산되 데이터 처리를 한 곳에 집중하면서 메세지 브로커를 통해 필요한 프로그램에 작업을 분산시키는 것이 목적
MQTT(Message Queueing Telemetry Transprot)
경량의 Publish/Subsribe(Pub/Sub) 기반 메시징 프로토콜
M2M(machine-to-machine)과 IoT에서 사용하기 위해 만들어짐
낮은 전력, 낮은 대역폭 환경에서도 사용 가능하도록 설계
- Open Source
- IoT Use Case (열악한 장치, 네트워크 상태 포함하는 Use Case)
- ISO Standard
- Edge, Data Center, Public Cloud와 같은 모든 Infra에서 배포 가능
- Pub/Sub Messaging만 가능
- Asynchronous Processing(Client가 오랫동안 Offline일 수 있음)
- Event의 Reprocessing 없음
Pub/Sub?
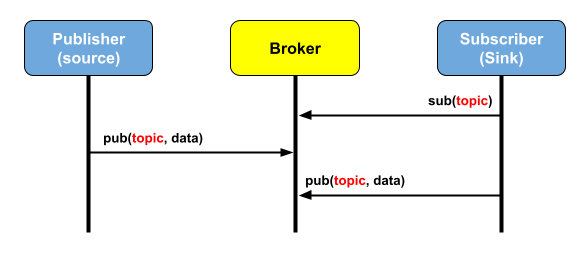
Publisher, Subscriber 모두 Broker에 대한 클라이언트
하나 이상의 Pub, Sub가 브로커에 연결해서 토픽을 발행하거나 구독할 수 있고, 다수의 클라이언트가 하나의 주제를 구독할 수 있음
Topic?
Pub와 Sub는 토픽 기준으로 작동
토픽은 슬래시를 이용하여 계층적 구조로 구성 가능해서 대량의 센서 기기들을 효율적으로 관리 가
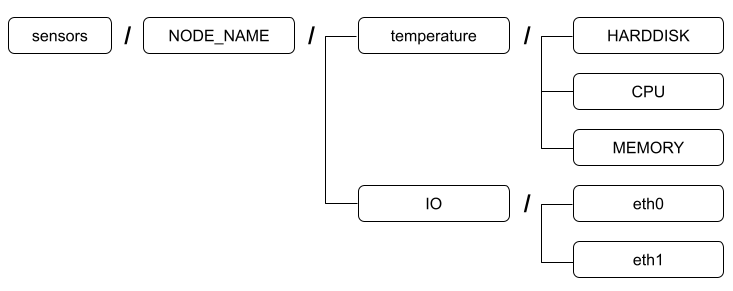
Message Bus System
MQTT Broker가 메세지 버스를 만들고 여기에 메세지를 흘려보내 버스에 붙은 애플리케이션들이 메세지를 읽어감
메세지 구분을 위해 Topic을 이름으로 하는 메세지 채널을 만듬
애플리케이션들은 메세지 버스에 연결하고 관심있는 토픽을 등록하여 Sub or Pub 수행
QoS (Quality of Service)
- 0
메세지는 한번만 전달, 전달 여부 확인 안함 - 1
메세지는 반드시 한 번 이상 전달되나 핸드셰이킹 하지 않기에 중복 전송될 수 있음 - 2
메세지는 한번만 전달되며 핸드셰이킹 과정을 통해 추적
높은 품질을 보장하나 성능 희생이 따름
NO TCP/IP, TCP/IP가 섞인 로컬 네트워크에서는 QoS 1, 2 선택이 유리
원격 네트워크에서는 0번이 유리
offline 모드에서 메세징 지원을 위해 메세지 박스 서비스 제공한다고 가정
QoS 1일 경우 다음 연결에 메세지 보내기 위해 자체 queue에 저장
시스템 입장에서는 queue에 있는 메세지를 읽어야 하는데 메세지 박스에서 읽어야 하는지를 판단해야 함
클라이언트는 MQTT queue에 있는 메세지를 읽기 위해 이전에 연결했던 MQTT에 연결해야 하는데 이는 클러스터 구성을 어렵게함
QoS 레벨 0으로 하고 소프트웨어에서 QoS 처리를 하는 것이 깔끔
Broker
MQTT 서버가 아닌 Broker인 이유는 발행인과 구독자가 메세지를 주고 받을 수 있도록 다리 역할만 하기 때문
다른 기능들은 중계를 도와주는 부가 기능일 뿐
REST와의 차이
REST
REST는 웹 서비스 개발을 위한 아키텍처 스타일
HTTP, CoAP 등 여러 프로토콜과 함께 사용할 수 있음
파일, 개체, 미디어 같은 구성 요소와 함께 작동 가능하며 POST, DELETE, PUT, GET 메소드 사용 가능
MQTT
매우 단순한 형태의 데이터를 송수신
메세지가 작기에 저전력, 낮은 처리 능력, 열악한 인터넷 환경에서 사용 가능
QoS 플래그로 메시지 전달에 대해 보장하기 때문에 IoT 장치에서 많이 사용됨
Apache Kafka
LinkedIn에서 처음 개발된 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 Mission Critical Application을 위한 Open-Source distributed event streaming platform
주요 특징
대용량 실시간 로그 처리에 특화되어 설계된 메시징 시스템
기존 범용 메시징 시스템 대비 TPS(Transaction Per Second)가 우수
분산 시스템을 기본으로 설계되었기에 다른 메세징 시스템에 비해 분산, 복제 구성이 손쉬움
AMQP 프로토콜을 사용하지 않고 단순한 메세지 헤더를 지닌 TCP 기반 프로토콜 사용하여 오버헤드 감소시킴
Producer가 broker에게 다수 메세지 전송 시 batch 형태로 한번에 전달할 수 있어 TCP/IP 라운드트립 횟수를 줄일 수 있음
파일 시스템에 메시지를 저장하기 때문에 별도의 설정을 하지 않아도 데이터의 영속성(durabiility)이 보장
기존 메시징 시스템에서는 처리되지 않고 남아있는 메시지의 수가 많을 수록 시스템의 성능이 크게 감소하였으나, Kafka에서는 메시지를 파일 시스템에 저장하기 때문에 메시지를 많이 쌓아두어도 성능이 크게 감소하지 않음
많은 메시지를 쌓아둘 수 있기 때문에, 실시간 처리뿐만 아니라 주기적인 batch 작업에 사용할 데이터를 쌓아두는 용도로도 사용할 수 있음
Consumer에 의해 처리된 메시지(acknowledged message)를 곧바로 삭제하는 기존 메시징 시스템과는 달리 처리된 메시지를 삭제하지 않고 파일 시스템에 그대로 두었다가 설정된 수명이 지나면 삭제하도록 처리
데이터베이스, 센서, 모바일 장치, 클라우드 서비스 및 소프트웨어 어플리케이션과 같은 이벤트 소스에서 데이터를 이벤트 스트림 형태로 실시간 캡처, 나중에 검색할 수 있도록 내구성 있게 저장, 이벤트 스트림을 실시간으로 조작, 처리, 대응 및 다른 대상 기술로 라우팅 하는데 특화
기존의 메시징 시스템에서는 broker가 consumer에게 메시지를 push해 주는 방식인데 반해, Kafka는 consumer가 broker로부터 직접 메시지를 가지고 가는 pull 방식으로 동작
따라서 consumer는 자신의 처리능력만큼의 메시지만 broker로부터 가져오기 때문에 최적의 성능을 낼 수 있음
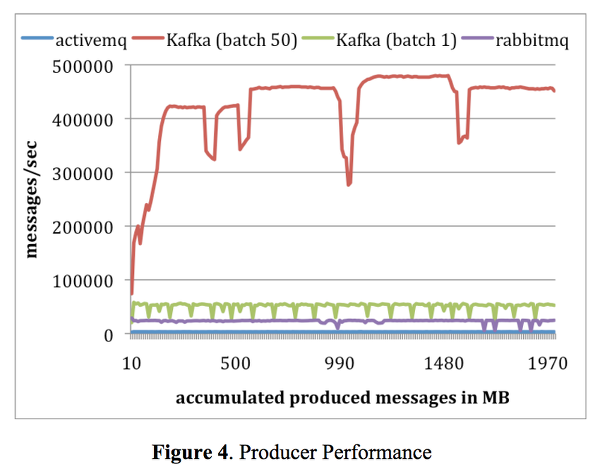
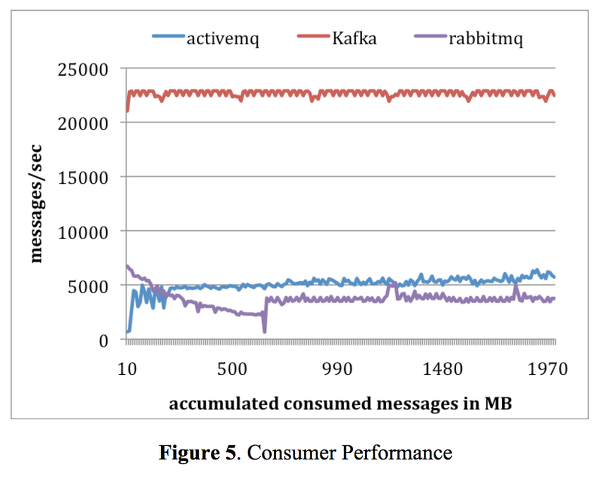
데이터의 지속적인 흐름, 해석 보장
올바른 정보가 올바른 위치에 적절한 시간에 있을 수 있도록 함
- 다른 시스템에서 지속적인 데이터 가져오기/내보내기 등 이벤트 스트림 Pub/Sub
- 원하는 기간 동안 지속적, 안정적으로 이벤트 스트림 저장
- 이벤트의 흐름을 처리
모든 기능이 분산되고 확장성이 뛰어나며 탄력적, 내결함성이 뛰어난 안전한 방식으로 제공
베어메탈 하드웨어, 가상 머신, 컨테이너, 사내, 클라우드에서 구현 가능
완전 관리형 서비스 또한 사용 가능 (AWS MSK, confluent 등)
- Pub/Sub Messaging, Streaming Processing, Data Integration 가능
- IoT Specific하지 않음
작동 방식
Server
여러 데이터 센터나 클라우드 영역에 걸쳐 있는 하나 이상의 서버 클러스터로 실행
서버 중 일부는 Broker라는 스토리지 계층 형성
다른 서버는 Kafka Connect를 실행하여 이벤트 스트림으로 데이터 가져오고 내보내 Kafka를 다른 Kafka 클러스터와 같은 기존 시스템과 통합
확장성, 내결함성
서버 중 하나라도 장애가 발생하면 다른 서버가 작업을 인계받아 데이터 손실 없이 지속적인 운영 보장
Client
네트워크 문제, 시스템 장애가 발생해도 이벤트 스트림을 병렬, 규모 및 무장애 방식으로 읽고 쓰고 처리하는 분산 애플리케이션, Micro Service 작성 가능
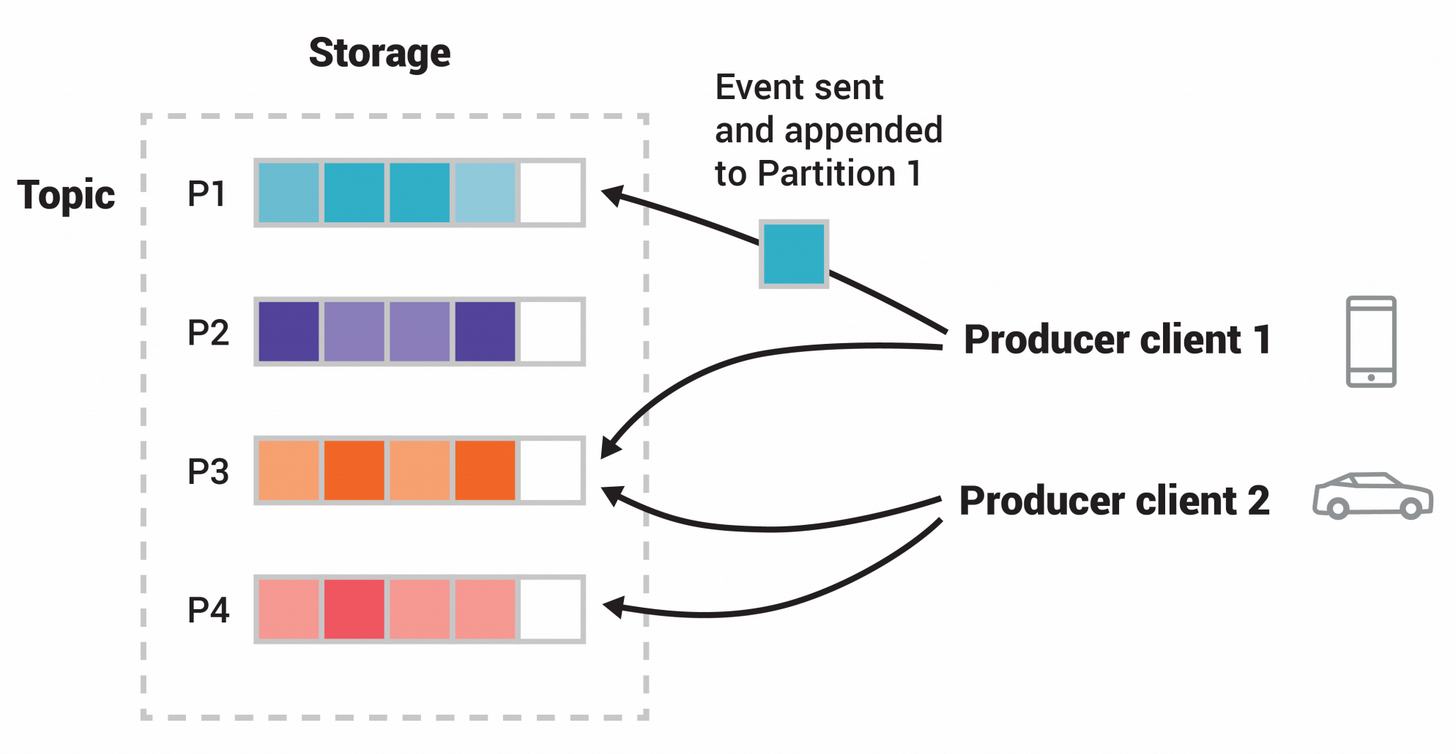
Consumer가 Broker로부터 직접 메세지를 가지고 가는 pull 방식으로 최적의 성능 내기에 좋음
많은 데이터를 전송, 최대 처리량을 유지하기에 대량 데이터 스트리밍에 적합
설계 방안
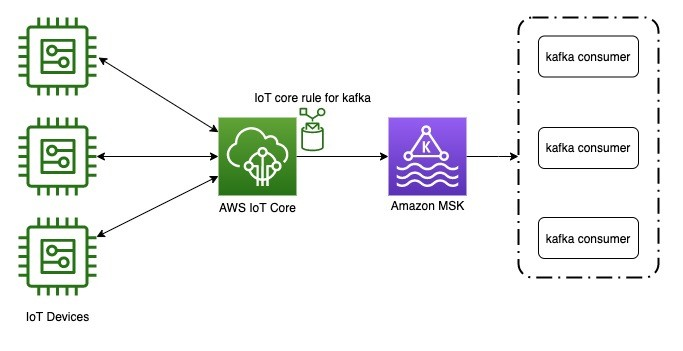
- IoT device(edge device)의 데이터를 Kafka가 실시간으로 Direct하게 받아오기는 어려움
- Kafka는 MQTT connector를 지원함 (source, sink 모두) (kafka로 들어오는 것을 source connect, 내보내는 것을 sink connect라고 함)
- Kafka의 MQTT connector를 사용하기 위해서는 MQTT Broker와 연결되어야 함 (아래 Reference 참조)
- Confluent MQTT Proxy를 사용하면 MQTT Broker 없이 Kafka로 데이터 전송 가능 (confluent platform 유)
- MQTT는 저전력, 낮은 대역폭 환경에서도 작동하도록 설계한 경량 IoT 프로토콜
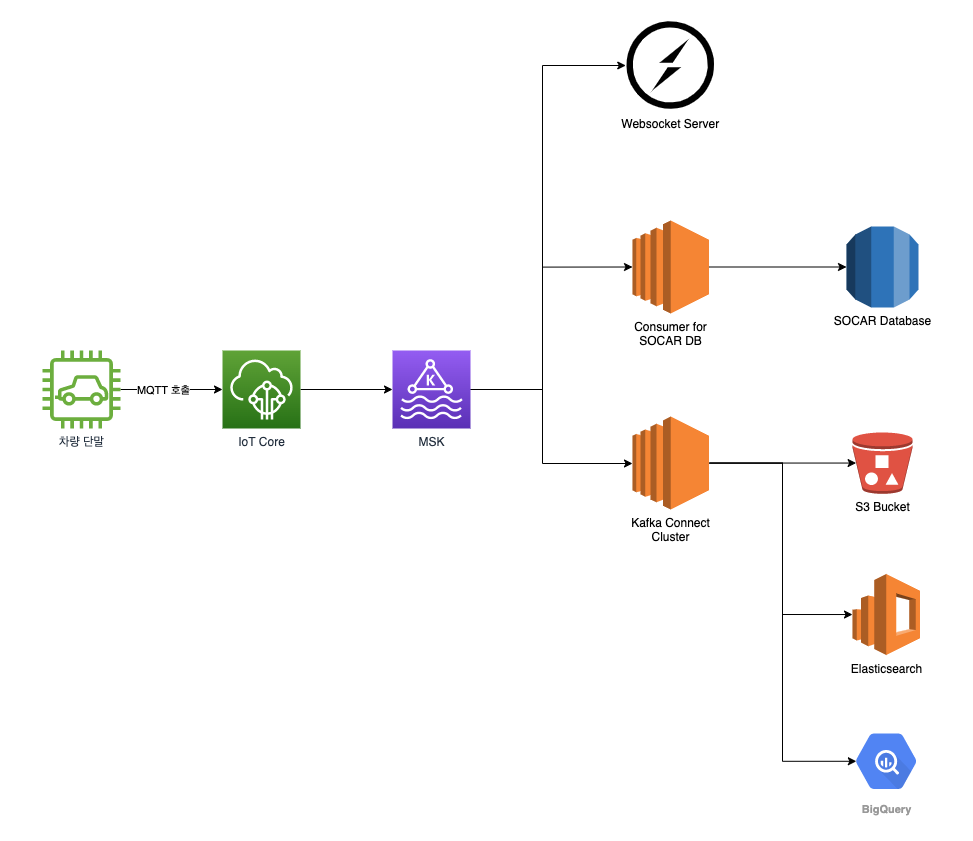
- 현재까지의 서베이 정보를 종합하면 edge device → MQTT → Kafka → Other Application 형태로 데이터를 받아오는 것이 Real-Time Streaming Data Ingestion 및 시스템의 확장성, 내결함성, 안정성 등을 위한 최선의 architecture로 고려됨
MQTT + Kafka Reference
다수의 IoT 디바이스들로부터 저전력, 낮은 대역폭에서 동작 가능하도록 설계되었지만 stream process, data intergration 지원하지 않는 MQTT와 다수의 IoT 디바이스와의 연결이 고려되지 않았지만 높은 처리량과 고가용성, 이벤트 재처리 및 우수한 통합성을 가진 Kafka의 조합은 IoT Use Case에 최적의 조합으로 널리 사용되고 있
Confluent, MQTT, and Apache Kafka Power Real-Time IoT Use Cases
Apache Kafka and MQTT (Part 1 of 5) - Overview and Comparison - Kai Waehner
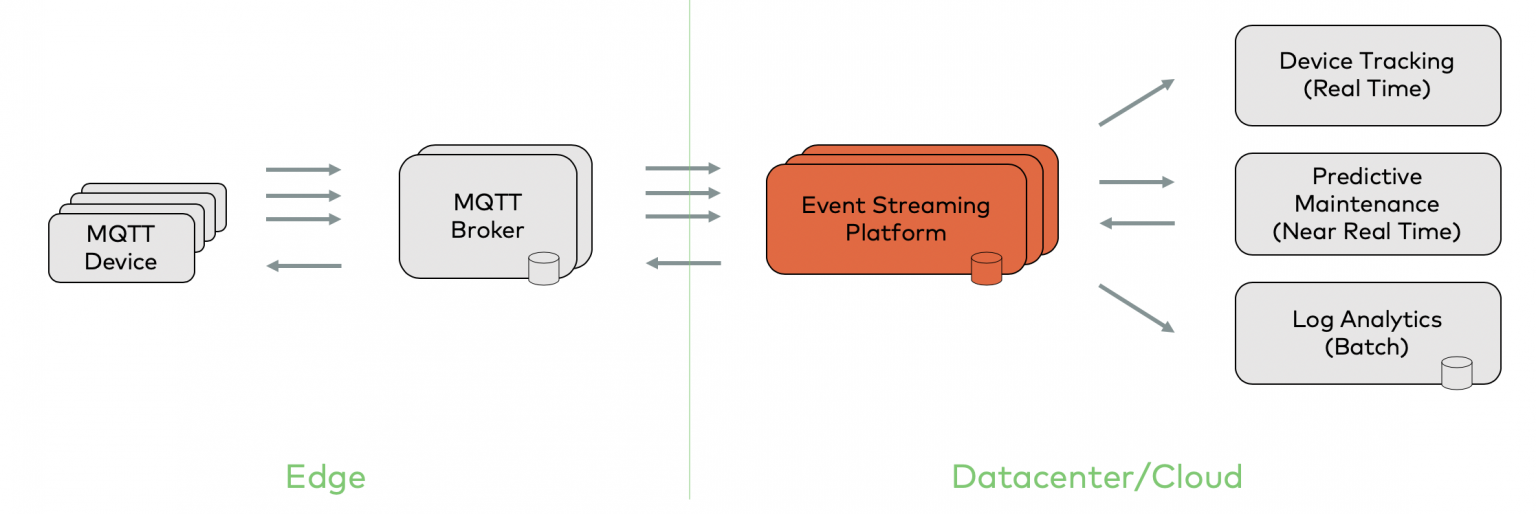
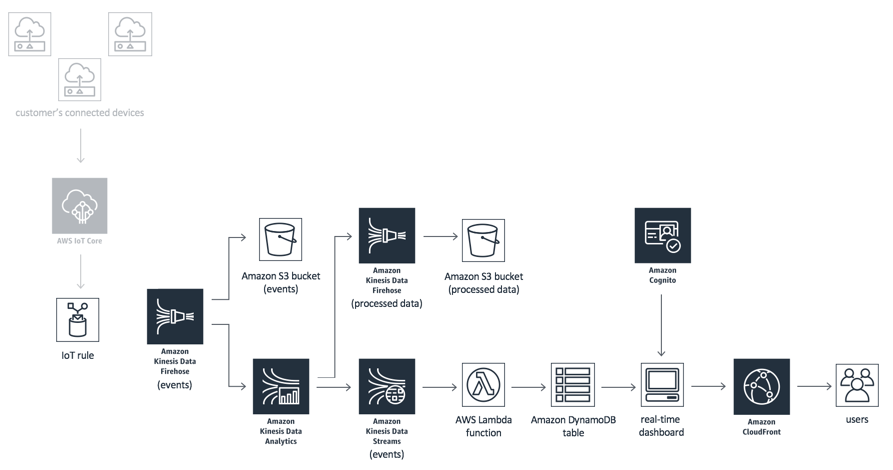
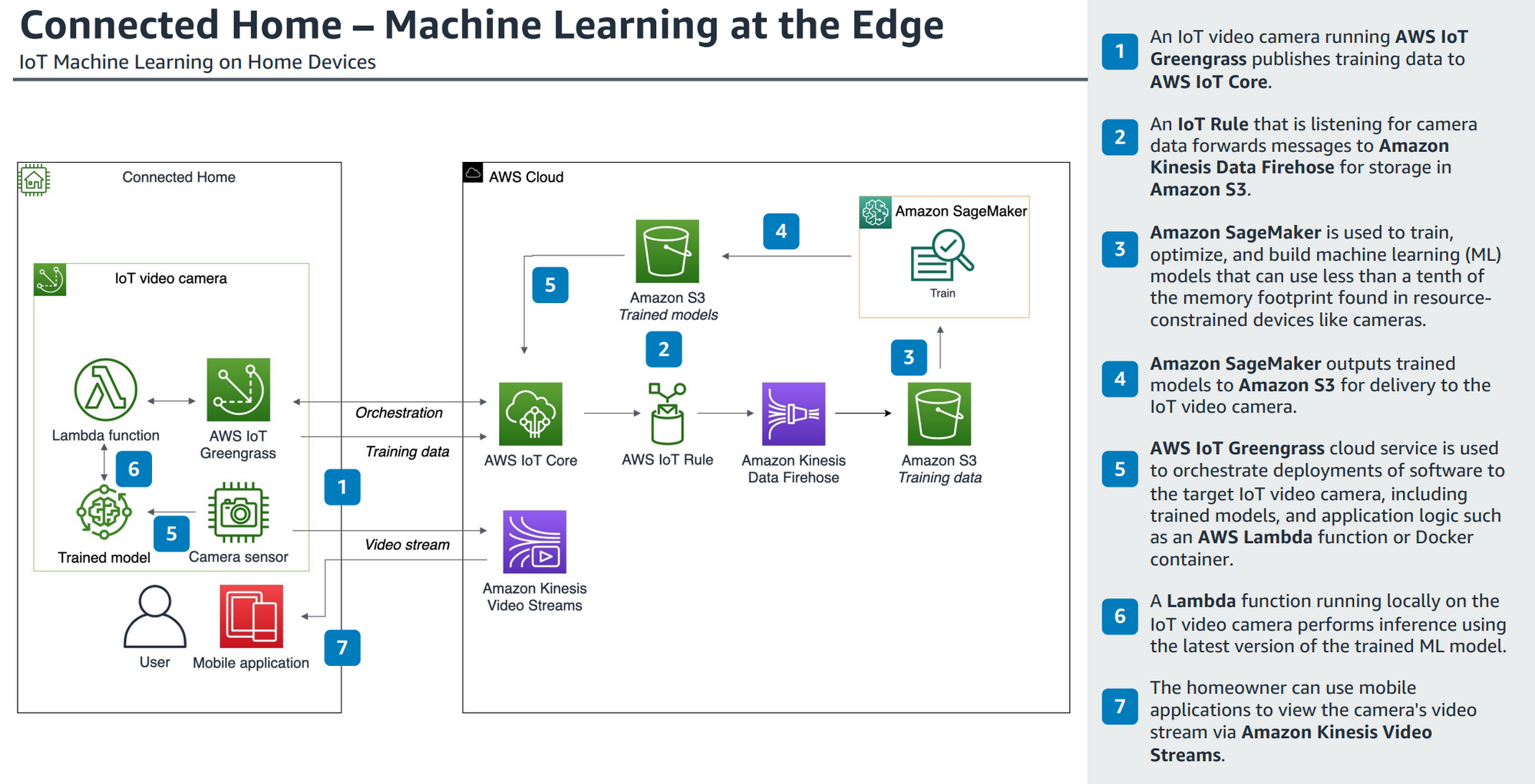
AWS IoT System Architecture Reference
AWS IoT Core : 클라우드에서 실행, 메시지 브로커에 메세지 게시할 가능성 높음
AWS IoT GreenGrass : 에지에서 실행, 클라우드 서비스를 지원하는 에지 런타임, 장치 소프트웨어 구성 및 관리 도구