
쓰레드(Thread)
- 메모리(Code, Data, Heap)는 공유하되, 실행 흐름(Stack)만 따로 가지는 경량 프로세스(LWP)
- 프로세스 내의 실행 흐름
쓰레드의 장단점 정리 : 글이 좀 길어질 것 같아 따로 정리했습니다.
1. 리눅스 커널이 보는 쓰레드 (LWP)
리눅스 커널은 '쓰레드'라는 별도의 객체를 모르기 때문에 쓰레드를 자원을 공유하는 특이한 프로세스로 취급합니다.
-
User 관점: "쓰레드" (하나의 프로그램 안에서 여러 함수가 동시에 도는 것)
-
Kernel 관점: "LWP (Light Weight Process)"
- 커널 입장에서는 그냥 프로세스(task_struct)입니다. 단, "부모와 메모리 방을 같이 쓰도록(공유하도록)" 설정된 특이한 프로세스일 뿐입니다.
- 리눅스 시스템 콜
clone()을 호출할 때CLONE_VM,CLONE_FS등의 플래그를 켜서 생성합니다.
2. 메모리 구조
쓰레드와 일반 프로세스의 결정적 차이는 "무엇을 공유하는가"입니다. 결론적으로는 스택만 따로 사용합니다.
- 코드 : 하나만 있으면 됨
- 데이터 : 전역변수
- 힙 : malloc -> 모든 쓰레드가 접근 가능
- 스택 : 각 쓰레드는 서로 다른 함수 실행
| 영역 | 공유 여부 | 설명 |
|---|---|---|
| Code | 공유함 | 프로그램 코드는 하나만 있으면 됨. |
| Data | 공유함 | 전역 변수(Global Variable)를 통해 쓰레드 간 통신 가능 (IPC 불필요). |
| Heap | 공유함 | malloc으로 잡은 메모리는 모든 쓰레드가 접근 가능. |
| Stack | 독립적 | (핵심) 각 쓰레드는 서로 다른 함수를 실행하므로, 지역 변수와 함수 호출 기록은 따로 가져야 함. |
2-1) 전역 vs 지역 메모리 공유 확인 예제
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
// [Data 영역] 모든 쓰레드가 공유 (통신 채널)
int g_count = 0;
void* thread_func(void* arg) {
char* name = (char*)arg;
// [Stack 영역] 각 쓰레드마다 독립적 (지역 변수)
int local_val = 0;
for (int i = 0; i < 3; i++) {
g_count++; // 공유 자원 수정
local_val++; // 내 전용 자원 수정
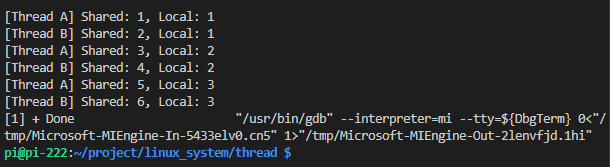
printf("[%s] Shared: %d, Local: %d\n", name, g_count, local_val);
sleep(1);
}
return NULL;
}
int main() {
pthread_t t1, t2;
// 리눅스 내부적으로는 clone() 시스템 콜을 통해 LWP 생성
pthread_create(&t1, NULL, thread_func, "Thread A");
pthread_create(&t2, NULL, thread_func, "Thread B");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}실행 결과
Shared값은 두 쓰레드가 섞여서 계속 증가함 (1, 2, 3, 4, 5, 6...). -> 자원 공유 증명Local값은 각자 1, 2, 3까지만 올라감. -> 스택 독립 증명
3. 프로세스 vs 쓰레드 비교
| 비교 항목 | 프로세스 (Process) | 쓰레드 (Thread / LWP) |
|---|---|---|
| 생성 비용 | 상대적으로 비쌈 (메모리 구조 전체 복사) | 저렴 (메모리 포인터만 복사) |
| 통신 방법 | 어렵다 (IPC: 파이프, 소켓 등 필요) | 쉽다 (전역 변수, 힙 메모리 직접 접근) |
| 문맥 전환 | 느림 (캐시/TLB 비워야 함) | 빠름 (메모리 맵이 같아서 캐시 유지 유리) |
| 안전성 | 하나 죽어도 다른 프로세스 영향 없음 | 하나 죽으면(Segfault) 프로세스 전체 사망 |
참고) 리눅스 시스템 콜 clone
프로세스인데 자원을 공유 가능한 이유는 clone() 시스템 콜 때문입니다.
fork(): 자원을 전부 복사 (Copy-on-Write).clone(): 플래그(CLONE_VM,CLONE_FS등)를 줘서 "복사하지 말고 포인터만 공유해"라고 지시함.
4. pthread 예제
전역 변수를 공유한다는 특징을 보여주는 간단한 예제
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
// [Data 영역] 모든 쓰레드가 공유하는 전역 변수
int g_counter = 0;
void* worker(void* arg) {
// [Stack 영역] 이 변수는 이 쓰레드만 가짐
int local_val = 0;
g_counter++; // 옆 쓰레드와 같이 쓰는 변수 수정
printf("쓰레드 실행 중... 공유값: %d\n", g_counter);
return NULL;
}
int main() {
pthread_t t1, t2;
// 쓰레드(=LWP) 생성
pthread_create(&t1, NULL, worker, NULL);
pthread_create(&t2, NULL, worker, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}실행 결과
쓰레드 실행 중... 공유값: 1
쓰레드 실행 중... 공유값: 2
[1] + Done "/usr/bin/gdb" --interpreter=mi --tty=${DbgTerm} 0<"/tmp/Microsoft-MIEngine-In-2eya5ony.p44" 1>"/tmp/Microsoft-MIEngine-Out-2l3o11ba.oxb"4-2) 10000개의 쓰레드를 돌리는 simple_thread
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
#define thread_count 10000
// [Data 영역] 모든 쓰레드가 공유하는 전역 변수
int g_counter = 0;
void* worker(void* arg) {
// [Stack 영역] 이 변수는 이 쓰레드만 가짐
int local_val = 0;
long my_id=(long)arg;
printf("Thread : %ld ", my_id);
g_counter++; // 옆 쓰레드와 같이 쓰는 변수 수정
printf("쓰레드 실행 중... 공유값: %d\n", g_counter);
return NULL;
}
int main() {
pthread_t t[thread_count];
// 쓰레드(=LWP) 생성
for (size_t i = 0; i < thread_count; i++)
{
pthread_create(&t[i], NULL, worker, (void*)i);
}
for (size_t i = 0; i < thread_count; i++)
{
pthread_join(t[i], NULL);
}
return 0;
}실행 결과
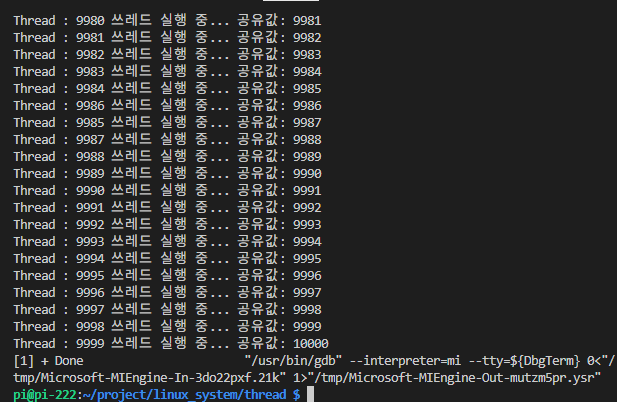
4.3) 응답성 & Blocking I/O 예제
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
// [백그라운드 쓰레드] 무거운 작업 (Blocking I/O 시뮬레이션)
void* download_task(void* arg) {
printf(" [Worker] 대용량 파일 다운로드 시작... (5초 소요)\n");
// sleep()은 대표적인 Blocking 상태입니다.
// 싱글 쓰레드였다면 여기서 프로그램 전체가 멈춥니다.
for(int i=1; i<=5; i++) {
sleep(1);
printf(" [Worker] 다운로드 중... %d0%%\n", i*2);
}
printf(" [Worker] 다운로드 완료!\n");
return NULL;
}
// [메인 쓰레드] UI 담당 (Responsiveness)
int main() {
pthread_t tid;
// 1. 무거운 작업을 별도 쓰레드에게 위임 (Non-blocking 효과)
pthread_create(&tid, NULL, download_task, NULL);
// 2. 메인 쓰레드는 멈추지 않고 사용자 입력에 계속 반응함
char input[100];
printf("[Main] 다운로드 중에 다른 작업을 할 수 있습니다.\n");
printf("[Main] 아무거나 입력해보세요 (종료하려면 'q'): ");
while(1) {
// 사용자의 입력을 기다림 (UI 반응성 유지)
scanf("%s", input);
if (input[0] == 'q') break;
printf("[Main] 입력 확인: %s (다운로드와 상관없이 잘 작동함)\n", input);
printf("[Main] 또 입력하세요: ");
}
pthread_join(tid, NULL); // 작업 끝날 때까지 대기 후 종료
return 0;
}실행 결과
[Worker] 대용량 파일 다운로드 시작... (5초 소요)
[Main] 다운로드 중에 다른 작업을 할 수 있습니다.
[Main] 아무거나 입력해보세요 (종료하려면 'q'): [Worker] 다운로드 중... 20%
[Worker] 다운로드 중... 40%
[Worker] 다운로드 중... 60%
[Worker] 다운로드 중... 80%
[Worker] 다운로드 중... 100%
[Worker] 다운로드 완료!
d
[Main] 입력 확인: d (다운로드와 상관없이 잘 작동함)
[Main] 또 입력하세요: q
[1] + Done "/usr/bin/gdb" --interpreter=mi --tty=${DbgTerm} 0<"/tmp/Microsoft-MIEngine-In-ooxwnvve.nbo" 1>"/tmp/Microsoft-MIEngine-Out-abo402yg.yj1"
// ************************************
// 다운로드 중간에도 q 열심히 입력 > 종료 안됌
[Worker] 대용량 파일 다운로드 시작... (5초 소요)
[Main] 다운로드 중에 다른 작업을 할 수 있습니다.
[Main] 아무거나 입력해보세요 (종료하려면 'q'): q
[Worker] 다운로드 중... 20%
q [Worker] 다운로드 중... 40%
q
q [Worker] 다운로드 중... 60%
[Worker] 다운로드 중... 80%
[Worker] 다운로드 중... 100%
[Worker] 다운로드 완료!
[1] + Done "/usr/bin/gdb" --interpreter=mi --tty=${DbgTerm} 0<"/tmp/Microsoft-MIEngine-In-pjtj5mzs.sma" 1>"/tmp/Microsoft-MIEngine-Out-lnxzkko0.tep"+ 추가 트러블 슈팅) segmentation error 뜨는 이유?
코드에 대한 실행파일을 실행하자마자, a를 계속 눌러서 100개를 넘기게 되면 pthread_join(tid, NULL); 이 줄에서 segmentation error가 발생한다.
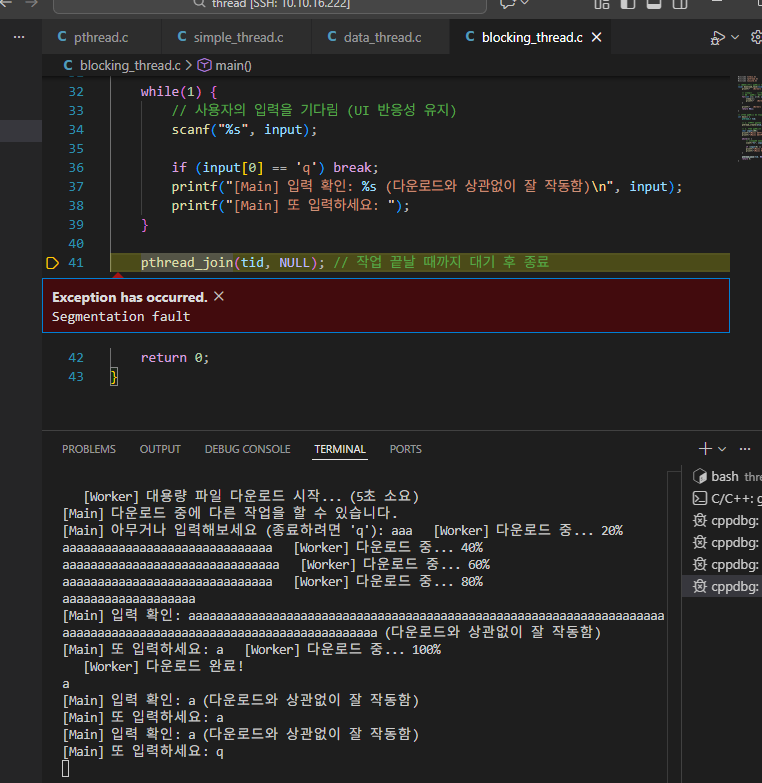
tid의 주소가 버퍼 오버플로우로 인해 오염됐기 때문이다. input[100] 배열에 100자를 넘게 입력하면, 스택 메모리에서 input 바로 위에 있던 tid 변수의 값을 덮어쓰게 된다.
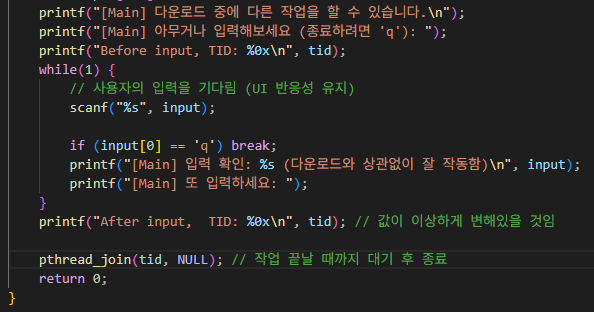
코드 상에 tid의 주소를 찍을 수 있도록 while 문 앞 뒤로 before, after로 찍어주면 아래와 같이 주소 값이 달라지는 것을 확인 가능하다.
[Worker] 대용량 파일 다운로드 시작... (5초 소요)
[Main] 다운로드 중에 다른 작업을 할 수 있습니다.
[Main] 아무거나 입력해보세요 (종료하려면 'q'):
Before input, TID: f7ddf1a0 // 이전 주소
aaaaaaa [Worker] 다운로드 중... 20%
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa [Worker] 다운로드 중... 40%
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa [Worker] 다운로드 중... 60%
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa [Worker] 다운로드 중... 80%
aaaaaaaaaaaaaaaaaaaaaaaaaa
[Main] 입력 확인: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa (다운로드와 상관없이 잘 작동함)
[Main] 또 입력하세요: [Worker] 다운로드 중... 100%
[Worker] 다운로드 완료!
a
[Main] 입력 확인: a (다운로드와 상관없이 잘 작동함)
[Main] 또 입력하세요: q
After input, TID: 61616161 // 주소 달라짐
[1] + Done "/usr/bin/gdb" --interpreter=mi --tty=${DbgTerm} 0<"/tmp/Microsoft-MIEngine-In-vflfciuz.aez" 1>"/tmp/Microsoft-MIEngine-Out-kxt4dy4u.hh4"
임베디드 개발자가 되기 위해 공부중입니다!