1. 쓰레드의 장점
1-1) Programming Abstraction (프로그래밍 추상화):
- 복잡한 하나의 큰 작업을 "독립적인 작은 작업들"로 쪼개서 설계할 수 있어 코드가 직관적이 됩니다. (예: 화면 담당, 통신 담당, 계산 담당).
1-2) Parallelism (진정한 병렬 처리):
- 멀티 코어 CPU 환경에서 각 쓰레드가 서로 다른 코어에서 동시에 실행됩니다. (단일 프로세스 프로그램은 아무리 좋아도 코어 1개만 씀).
1-3) Improving Responsiveness (응답성 향상):
- *"멈추지 않는 앱"을 만듭니다. 무거운 작업(파일 복사) 중에도 사용자의 마우스 클릭이나 취소 버튼에 반응할 수 있습니다.
1-4) Blocking I/O 해결 (CPU 낭비 방지):
- 네트워크나 디스크가 데이터를 줄 때까지 기다리는 동안(Blocking), 다른 쓰레드는 멈추지 않고 CPU를 써서 계산을 계속합니다.
1-5) Context Switching (문맥 교환 비용 절감):
- 프로세스 교환은 "캐시 비우기 + 메모리 맵 교체" 등 대공사지만, 쓰레드 교환은 "레지스터 값(PC, SP)"만 쓱 바꾸면 되므로 훨씬 빠르고 가볍습니다.
1-6) Memory Savings (자원 절약):
- 프로세스를 새로 만들면 코드/데이터 영역을 또 복사해야 하지만, 쓰레드는 스택만 새로 파면 되므로 메모리를 매우 적게 먹습니다.
2. 쓰레드의 단점
2-1) 쓰레드의 치명적 단점 (개발자가 겪는 고통)
쓰레드는 자원을 공유하기 때문에 "양날의 검"입니다. 편한 만큼 위험합니다.
A. 동기화 문제 (Race Condition)
- 설명: "미묘한 시간 차나 잘못된 변수 공유"라는 말씀이 바로 이겁니다.
- 상황: 두 쓰레드가 동시에
count++를 하려고 할 때, 서로의 값을 덮어써서 계산 결과가 틀려지는 현상입니다. - 해결책: Mutex나 Semaphore 같은 동기화 객체를 써야 하는데, 이걸 잘못 쓰면 데드락(Deadlock, 교착 상태)에 걸려 프로그램이 멈춥니다.
B. 디버깅의 지옥 (Non-deterministic)
- 설명: 프로그램 실행 순서가 OS 스케줄러 기분에 따라 매번 바뀝니다.
- 현상: "어제는 에러가 났는데, 오늘 로그를 찍으니까 에러가 안 나요." (하이젠버그).
- 이유: 타이밍 문제로 발생하는 버그는 재현하기가 매우 어렵습니다.
C. 안정성 취약 (All or Nothing)
- 설명: 프로세스 하나가 죽으면 그 프로세스만 꺼지면 되지만, 쓰레드 하나가 불법 연산(Segfault)을 하면 프로세스 전체가 죽습니다.
- 비유: 배(Process)에 탄 선원(Thread) 한 명이 구멍을 뚫으면 배 전체가 침몰합니다.
D. 단일 프로세서에서의 오버헤드
- 설명: CPU 코어가 1개인데 쓰레드만 100개 만들면?
- 비효율: 실제 병렬 처리는 안 되면서, 쓰레드끼리 자리 바꾸는 비용(Context Switching)만 들어서 오히려 느려집니다.
2-2) POSIX 표준화 (역사적 배경)
리눅스 시스템 프로그래밍에서 pthread가 왜 표준인지에 대한 배경입니다.
- 춘추전국시대: 과거에는 Solaris 쓰레드, HP-UX 쓰레드 등 벤더마다 함수 이름과 사용법이 다 달랐습니다. (이식성 0점).
- 통일 (POSIX 1003.1c): IEEE가 나서서 "API 이름이랑 동작 방식을 통일하자"고 만든 것이 Pthreads (POSIX Threads)입니다.
- 리눅스의 수용: 리눅스는 이 표준을 강력하게 지원하는
NPTL (Native POSIX Thread Library)을 탑재하여, 어느 리눅스 배포판에서도 동일한 코드로 쓰레드를 짤 수 있게 되었습니다.
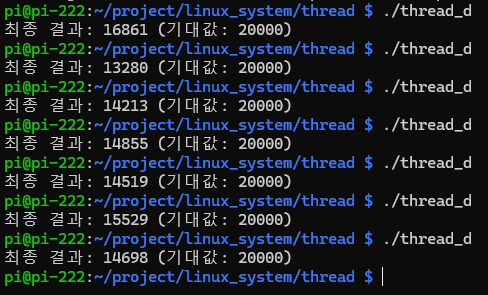
2-3) 실습: "쓰레드의 단점 증명" (Race Condition)
동기화 처리를 안 했을 때 어떤 사단이 나는지 보여주는 코드입니다.
20000이 나와야 정상이지만, 실행할 때마다 이상한 숫자가 나옵니다.
#include <stdio.h>
#include <pthread.h>
// 공유 자원 (전역 변수)
int g_counter = 0;
void* worker(void* arg) {
// 10000번 더하기 시도
for (int i = 0; i < 10000; i++) {
// [위험] Lock 없이 접근! (Race Condition 발생)
g_counter++;
}
return NULL;
}
int main() {
pthread_t t1, t2;
// 두 개의 쓰레드가 동시에 g_counter를 마구 증가시킴
pthread_create(&t1, NULL, worker, NULL);
pthread_create(&t2, NULL, worker, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
// 기대값: 20000
// 실제값: 15432, 19800 등 매번 다름 (데이터 손실)
printf("최종 결과: %d (기대값: 20000)\n", g_counter);
return 0;
}
터미널에서는 20000이라는 값이 안 나오고 실행할 때마다 달라지지만, vscode 상에서는 잘 나온다?
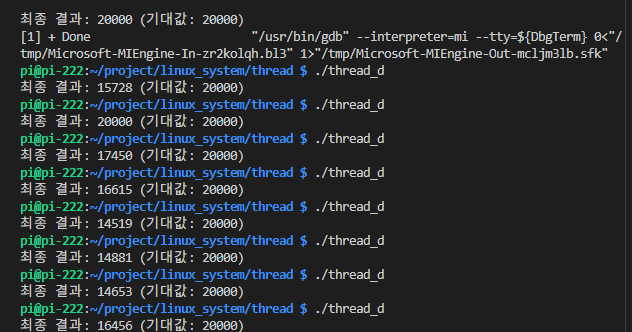
아닙니다 초반 디버그 모드만 그렇습니다. 결과가 다른 이유는 다음과 같습니다.
1. VSCode에서 실행
- 디버그 모드로 실행되면 최적화 꺼짐 (-O0)
코드 실행 속도가 느려짐 - 스레드 간 타이밍이 달라져서 운 좋게
Race Condition안 생김
2. 터미널에서 실행:
- 최적화 켜진 상태로 컴파일됨 (-O2 또는 -O3)
- 코드가 빠르게 실행되어 스레드 충돌 확률 증가
->Race Condition더 자주 발생

임베디드 개발자가 되기 위해 공부중입니다!