
자료구조
트리(Tree)
트리의 개념
데이터의 상-하 관계를 저장하는 자료 구조
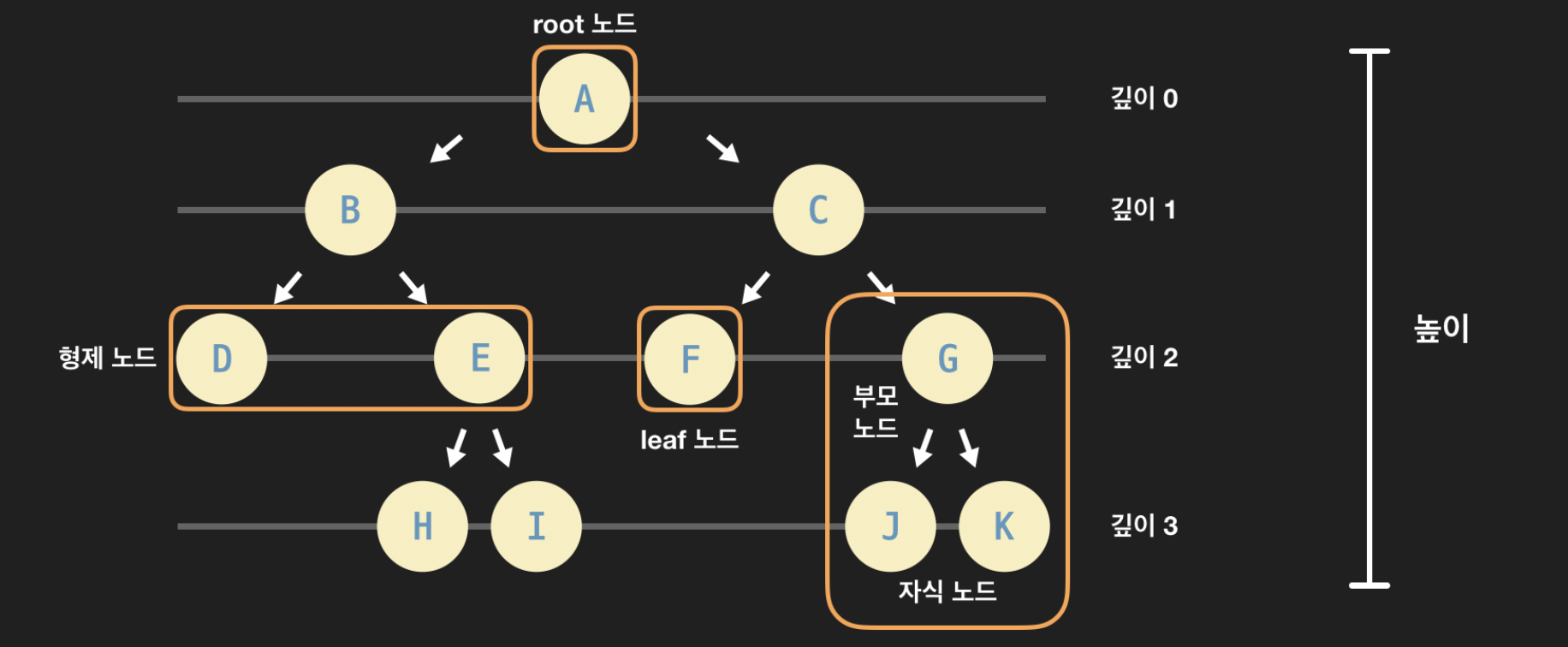
링크드 리스트가 앞-뒤 관계를 저장하듯이, 트리는 상-하 관계를 노드에 저장하여 부모-자식 관계를 설정한다. 링크드 리스트의 head노드와 같이 시작점이 되는 최상위 노드를 root 노드라고 한다.
-
leaf 노드 (잎/말단 노드): 자식 노드를 갖고 있지 않은, 가장 말단에 있는 노드. 트리의 끝에 있다고 해서 root(뿌리) 노드와 반대되는 표현으로 leaf(잎) 노드라고 함.
-
깊이: 특정 노드가 root 노드에서 떨어져 있는 거리. 깊이는 해당 노드로 가기 위해서 root 노드에서 몇 번 아래로 내려와야 하는지를 나타낸다. 예를 들어 위 그림에서 root 노드의 자식 노드인 B와 C는 깊이가 1이다. 즉, 특정 노드가 root 노드로부터 얼마나 멀리 떨어져 있는지를 나타낸다.
-
레벨: 깊이 + 1. 깊이랑 거의 똑같은 개념이지만 깊이에 1을 더한 값이다. 레벨 1에 있는 노드들, 레벨 2에 있는 노드들… 이런식으로 특정 깊이인 노드들을 묶어서 표현할 때 사용하는 용어입니다.
-
높이: 트리에서 가장 깊이 있는 노드의 깊이. 위 그림의 트리에서는 H, I, J, K가 가장 깊이 있는 노드들이고 그 깊이는 모두 3이다. 그래서 트리의 높이는 3입니다.
-
부분 트리 (sub-tree): 현재 트리의 일부분을 이루고 있는 더 작은 트리. 특정 노드를 root 노드라고 생각하고 바라본다면 여러 가지 부분 트리들을 발견할 수 있다. 하나의 전체 트리에 여러 부분 트리들이 존재한다.
이진 트리
각 노드가 최대 2개의 자식을 갖는 트리
2개의 자식을 각각 왼쪽 자식 & 오른쪽 자식으로 부른다.
이진 트리는 트리에 대한 개념의 이해와 구현에 집중하는데에 도움이 된다.
class Node:
"""이진 트리 노드 클래스"""
def __init__(self, data):
"""이진 트리는 두 개의 자식 노드의 레퍼런스를 갖는다."""
self.data = data
self.left_child = None
self.rignt_child = None이진 트리도 여러 종류가 있다.
- 정 이진 트리(Full Binary Tree) : 모든 노드가 2개 혹은 0개의 자식을 갖는 이진 트리
- 완전 이진 트리(Complete Binary Tree) : 마지막 레벨을 제외한 모든 레벨이 노드로 채워져 있고, 마지막 레벨은 왼쪽에서 오른쪽 방향으로 노드가 채워져 있는 이진 트리
- 포화 이진 트리(Perfect Binary Tree) : 모든 레벨이 빠짐없이 노드로 채워져 있는 이진 트리
이 중에서도 특히 완전 이진 트리는 저장된 노드가 개라고 할 때, 높이가 항상 에 비례한다. 또한, 최소한 현재 노드 수보다 노드 수가 2배 이상 되었을 때, 높이도 +1 된다. 결과적으로 완전 이진 트리의 높이를 라고 할 수 있다.
완전 이진 트리를 파이썬 리스트로 구현하면 다음과 같다.
complete_binary_tree = [None, 1, 5, 12, 11, 9, 10, 14, 3, 7]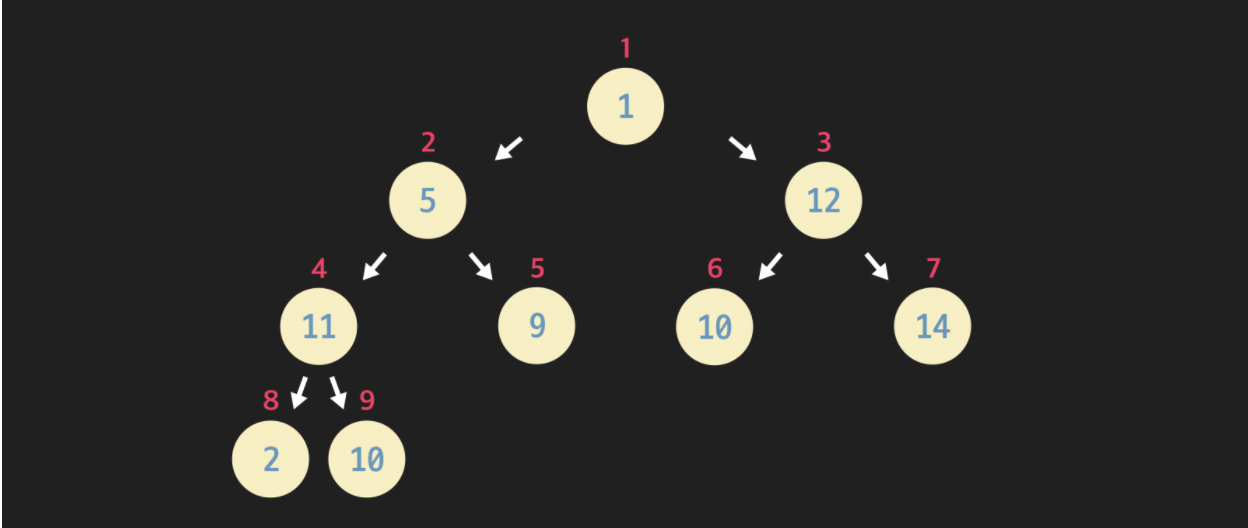
이 때, 자식 노드를 찾는 방법은 매우 간단하다. 부모 노드의 인덱스에 * 2 를 하면 왼쪽 자식노드가 되고 거기에 +1 을 하면 오른쪽 자식 노드가 된다. 반대로 부모 노드를 찾는 경우에는 자식 노드에서 / 2 를 하여 정수 부분만 가져오면 된다.
이는 완전 이진 트리의 성질 때문에 가능하다.
- 마지막 레벨 직전의 레벨까지는 노드들로 가득 차 있음
- 마지막 레벨은 왼쪽에서 오른쪽 방향으로 노드들로 가득 차 있어야 함
트리 순회
순회: 자료 구조에 저장된 모든 데이터를 도는 것
트리 순회는 재귀 함수를 사용한다. 순회의 기본 동작 순서에 따라 3가지 순회 방법이 있다.
- pre-order 순회: 현재 노드 출력 -> 재귀적 왼쪽 트리 순회 -> 재귀적 오른쪽 트리 순회
- post-order 순회: 재귀적 왼쪽 트리 순회 -> 재귀적 오른쪽 트리 순회 -> 현재 노드 출력
- in-order 순회: 재귀적 왼쪽 트리 순회 -> 현재 노드 출력 -> 재귀적 오른쪽 트리 순회
순회를 통해 계층적 데이터 사이에 선형적(순서) 관계가 생성된다.
힙(Heap)
힙의 개념
힙은 다음의 두 가지 조건을 만족하는 트리이다.
- 형태 속성: 힙은 완전 이진 트리이다.
- 힙 속성: 모든 노드의 데이터는 자식 노드들의 데이터보다 크거나 같다.
힙을 통해 해결할 수 있는 정렬 문제와 우선순위 큐에 대해 알아본다.
정렬: 데이터의 오름차순 혹은 내림차순으로 나열하는 것
이렇게 데이터를 재배치하는 구체적인 방법을 정렬 알고리즘 이라고 하며, 삽입 정렬, 선택 정렬, 퀵 정렬, 합병 정렬 등의 방법이 있다. 힙을 사용한 정렬 알고리즘을 힙 정렬이라고 한다.
힙을 만들 때, 힙 속성을 만족하지 않는 노드의 위치를 자식 노드와 바꿔줌으로서 힙 속성을 충족시키는 방법을 Heapify 라고 한다. 이 때의 시간 복잡도는 최악의 경우 root 부터 leaf 까지 타고 내려가는 경우이며, 시간 복잡도는 높이에 비례하는 이라고 할 수 있다.
재귀 함수를 활용한 Heapify 예시
def swap(tree, index_1, index_2):
"""완전 이진 트리의 노드 index_1과 노드 index_2의 위치를 바꿔준다"""
temp = tree[index_1]
tree[index_1] = tree[index_2]
tree[index_2] = temp
def heapify(tree, index, tree_size):
"""heapify 함수"""
# 왼쪽 자식 노드의 인덱스와 오른쪽 자식 노드의 인덱스를 계산
left_child_index = 2 * index
right_child_index = 2 * index + 1
# 코드를 쓰세요.
largest = index # 일단 부모 노드의 값이 가장 크다고 설정
# 왼쪽 자식 노드의 값과 비교
if 0 < left_child_index < tree_size and tree[largest] < tree[left_child_index]:
largest = left_child_index
# 오른쪽 자식 노드의 값과 비교
if 0 < right_child_index < tree_size and tree[largest] < tree[right_child_index]:
largest = right_child_index
if largest != index:
swap(tree, index, largest)
heapify(tree, largest, tree_size)
# 실행 코드
tree = [None, 15, 5, 12, 14, 9, 10, 6, 2, 11, 1] # heapify하려고 하는 완전 이진 트리
heapify(tree, 2, len(tree)) # 노드 2에 heapify 호출
print(tree) heapify 함수를 가장 아래 레벨의 노드부터 차례로 실행시키면 힙을 만들 수 있다. 이 때의 시간 복잡도는 특정 노드의 heapify 시간 복잡도가 이고, n개의 node에 모두 heapify 함수를 호출해야 하므로 총 의 시간복잡도를 갖는다.
힙 정렬
힙 정렬을 구현하기 위해서는 다음과 같은 과정을 거친다.
- 힙을 만든다.
- root 와 마지막 노드를 바꿔준다.
- 바꾼 노드는 없는 노드로 취급한다.
- 새로운 노드가 힙 속성을 지킬 수 있게 heapify 를 호출한다.
- 2~4 번째 과정을 반복한다.
힙 정렬의 결과는 오름차순으로 나타난다. 내림 차순으로 정렬하고 싶은 경우 부모 노드가 자식 노드보다 작다는 힙 속성을 적용해주면 된다.
힙 정렬의 시간 복잡도는 아래와 같다.
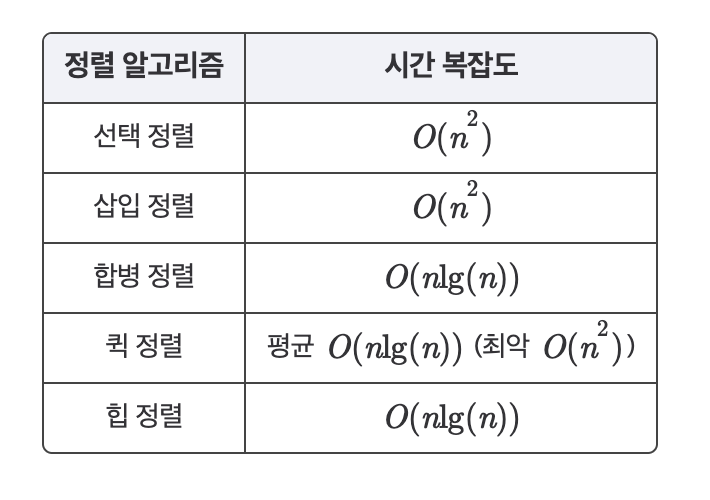
삽입, 선택 정렬에 비해 효율적인 것을 알 수 있다.
우선순위 큐(Priority Queue)
힙은 정렬과 우선순위 큐라는 추상 자료형을 구현하기 위해 많이 사용된다.
우선순위 큐: 저장된 데이터가 선입선출 방식이 아니라 우선 순위대로 나오는 추상 자료형
먼저, 힙에 데이터를 삽입하는 방법에 대해 알아야 한다.
- 힙의 마지막 인덱스에 데이터 삽입
- 삽입한 데이터와 부모 노드의 데이터를 비교한다.
- 부모 노드의 데이터가 더 작으면 둘의 위치를 바꿔준다.
- 삽입한 노드가 제 위치를 찾을 때까지 2~3번을 반복한다.
예시를 보면 아래와 같다.
def swap(tree, index_1, index_2):
"""완전 이진 트리의 노드 index_1과 노드 index_2의 위치를 바꿔준다"""
temp = tree[index_1]
tree[index_1] = tree[index_2]
tree[index_2] = temp
def reverse_heapify(tree, index):
"""삽입된 노드를 힙 속성을 지키는 위치로 이동시키는 함수"""
parent_index = index // 2 # 삽입된 노드의 부모 노드의 인덱스 계산
# 코드를 쓰세요.
if parent_index > 0 and tree[parent_index] < tree[index]:
swap(tree, parent_index, index)
reverse_heapify(tree, parent_index)
class PriorityQueue:
"""힙으로 구현한 우선순위 큐"""
def __init__(self):
self.heap = [None] # 파이썬 리스트로 구현한 힙
def insert(self, data):
"""삽입 메소드"""
# 코드를 쓰세요
self.heap.append(data)
reverse_heapify(self.heap,self.heap.index(data))
def __str__(self):
return str(self.heap)그 다음로는 힙에서 가장 우선 순위 노드를 추출하는 동시에 힙의 속성을 유지시키는 방법을 보자.
방법은 아래와 같이 정리할 수 있다.
- root노드와 마지막 노드를 서로 바꿔준다.
- 마지막 노드의 데이터를 변수에 저장한다.
- 마지막 노드를 삭제한다.
- root 노드에 heapify를 사용하여 힙 속성을 지킨다.
- 우선 순위 데이터를 리턴한다.
class PriorityQueue:
"""힙으로 구현한 우선순위 큐"""
def __init__(self):
self.heap = [None] # 파이썬 리스트로 구현한 힙
def extract_max(self):
"""최우선순위 데이터 추출 메소드"""
# 코드를 쓰세요
swap(self.heap, 1, len(self.heap)-1)
max_value = self.heap.pop()
heapify(self.heap, 1, len(self.heap))
return max_value부모와 자식 노드를 서로 바꿔주는 swap 이라는 메소드와 heapify를 실행해주는 heapify 라는 메소드가 있을 때, 위와 같이 우선 순위 데이터를 추출할 수 있다.
힙에 데이터를 삽입하는 것과 우선 순위 데이터를 추출하는 것에 대한 시간 복잡도는 모두 이다.
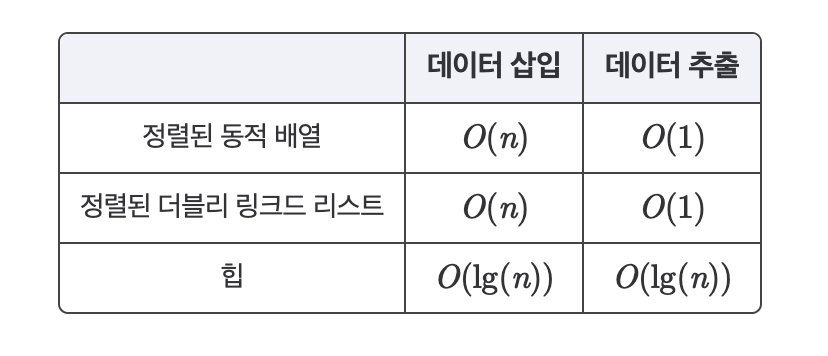
우선순위 큐를 힙이 아닌 동적 배열과 링크드 리스트로 구현하였을 때, 각각의 시간복잡도는 위의 표와 같다. 데이터의 추출은 동적 배열과 링크드 리스트가 보다 효율적인 반면, 데이터 삽입에는 힙이 시간 복잡도가 보다 효율적이다.
이진 탐색 트리(Binary Search Tree)
이진 탐색 트리는 이진 트리이면서 동시에 다음과 같은 속성을 갖는다.
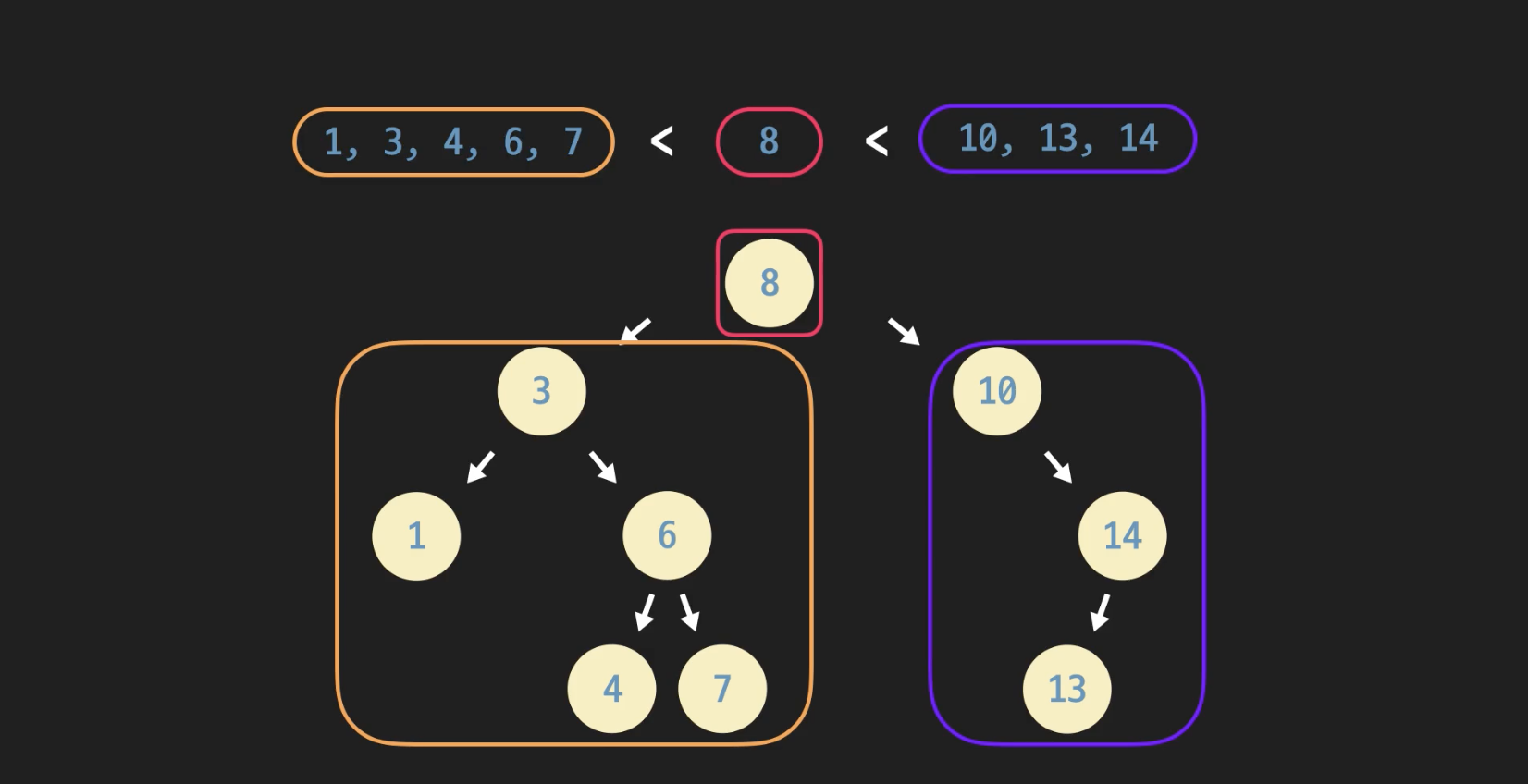
위의 그림을 보면 root 노드의 왼쪽 모든 노드의 데이터는 항상 8보다 작고, 오른쪽 노드의 모든 데이터는 항상 8보다 크다. 그리고 8의 왼쪽 자식인 노드 3의 왼쪽과 오른쪽 노드도 root 노드와 마찬가지의 특징을 갖는다. 이것이 바로 이진 탐색 트리의 속성이다.
이진 탐색 트리는 항상 완전 이진 트리는 아니다. 따라서 배열이 아닌 클래스 기반의 노드로 구현한다.
class Node:
"""이진 탐색 트리 노드"""
def __init__(self, data):
self.data = data
self.parant = None
self.left_child = None
self.right_child = None이진 탐색 트리의 노드는 앞서 봤던 이진 트리 노드에 parent 속성만 추가하면 된다.
이진 탐색 트리를 앞서 트리 순회와 관련하여 정의된 3가지 방법 중, in-order 방식으로 순회하면 저장된 데이터들을 정렬된 순서로 출력할 수 있다.
def print_inorder(node):
"""주어진 노드를 in-order로 출력해주는 함수"""
if node is not None:
print_inorder(node.left_child)
print(node.data)
print_inorder(node.right_child)
class BinarySearchTree:
"""이진 탐색 트리 클래스"""
def __init__(self):
self.root = None
def print_sorted_tree(self):
"""이진 탐색 트리 내의 데이터를 정렬된 순서로 출력해주는 메소드"""
print_inorder(self.root) # root 노드를 in-order로 출력한다이진 탐색 노드의 데이터 삽입은 다음과 같은 순서로 이루진다.
- 새로운 노드 생성
- root 노드부터 비교하여 저장할 위치를 찾음
- 찾은 위치에 노드 연결
트리의 높이가 일 때, 노드의 생성과 연결은 이 걸린다. 저장할 위치를 찾을 때, 최악의 경우 트리의 높이만큼 비교한 후 +1 만큼 더 내려와야 한다. 즉, 만큼의 시간 복잡도를 갖는다.
파이썬 코드로는 아래와 같이 구현할 수 있다.
class BinarySearchTree:
"""이진 탐색 트리 클래스"""
def __init__(self):
self.root = None
def insert(self, data):
new_node = Node(data) # 삽입할 데이터를 갖는 새 노드 생성
# 트리가 비었으면 새로운 노드를 root 노드로 만든다
if self.root is None:
self.root = new_node
return
temp = self.root
while temp is not None:
if data > temp.data:
if temp.right_child is None:
temp.right_child = new_node
new_node.parent = temp
return
else:
temp = temp.right_child
else:
if temp.left_child is None:
temp.left_child = new_node
new_node.parent = temp
return
else:
temp = temp.left_child이진 탐색 트리의 탐색 연산은 root 부터 시작하여 value가 크고 작음에 따라서 좌,우로 나뉘어 찾을 때까지 내려간다. 시간 복잡도는 최악의 경우 root를 포함하여 높이 보다 +1 만큼 더 연산해야 한다. 따라서 의 시간 복잡도를 갖는다.
이진 탐색 트리의 탐색 연산은 아래와 같이 구현할 수 있다.
class BinarySearchTree:
"""이진 탐색 트리 클래스"""
def __init__(self):
self.root = None
def search(self, data):
"""이진 탐색 트리 탐색 메소드, 찾는 데이터를 갖는 노드가 없으면 None을 리턴한다"""
temp = self.root
while temp is not None:
if data == temp.data:
return temp
if data > temp.data:
temp = temp.right_child
else:
temp = temp.left_child
return None이진 탐색 트리의 삭제 연산은 여러 경우의 수로 구분할 수 있다.
- 지우려는 노드가 leaf 노드 일 때
- 지우려는 노드가 하나의 자식 노드만 가지고 있을 때
1번의 경우에는 부모 노드의 자식 레퍼런스를 None 으로 지정하면 된다.
2번의 경우에는 부모, 자식 노드에 대한 레퍼런스를 한 단계 건너 뛰고 지정하여, 트리에서 제외시키면 된다.
def delete(self, data):
"""이진 탐색 트리 삭제 메소드"""
node_to_delete = self.search(data) # 삭제할 노드를 가지고 온다
parent_node = node_to_delete.parent # 삭제할 노드의 부모 노드
# 경우 1: 지우려는 노드가 leaf 노드일 때
if node_to_delete.left_child is None and node_to_delete.right_child is None:
if self.root is node_to_delete:
self.root = None
else:
if parent_node.right_child == node_to_delete:
parent_node.right_child = None
else:
parent_node.left_child = None
# 경우 2: 지우려는 노드가 자식이 하나인 노드일 때:
elif node_to_delete.left_child is None: # 지우려는 노드가 오른쪽 자식만 있을 때:
# 지우려는 노드가 root 노드일 때
if node_to_delete is self.root:
self.root = node_to_delete.right_child
self.root.parent = None
# 지우려는 노드가 부모의 왼쪽 자식일 때
elif node_to_delete is parent_node.left_child:
parent_node.left_child = node_to_delete.right_child
node_to_delete.right_child.parent = parent_node
# 지우려는 노드가 부모의 오른쪽 자식일 때
else:
parent_node.right_child = node_to_delete.right_child
node_to_delete.right_child.parent = parent_node
elif node_to_delete.right_child is None: # 지우려는 노드가 왼쪽 자식만 있을 때:
# 지우려는 노드가 root 노드일 때
if node_to_delete is self.root:
self.root = node_to_delete.left_child
self.root.parent = None
# 지우려는 노드가 부모의 왼쪽 자식일
elif node_to_delete is parent_node.left_child:
parent_node.left_child = node_to_delete.left_child
node_to_delete.left_child.parent = parent_node
# 지우려는 노드가 부모의 오른쪽 자식일 때
else:
parent_node.right_child = node_to_delete.left_child
node_to_delete.left_child.parent = parent_node- 삭제하려는 노드가 두 개의 자식 노드를 가지고 있을 때
지우려고 하는 노드보다 큰 노드들 중에서가 가장 작은 값을 찾는다. 이를 지우고자하는 노드의 successor 라고 한다. 그리고 이 노드와 지우려는 노드의 데이터를 서로 바꾼 뒤, 지워주면 된다. successor 노드는 언제나 leaf 노드이거나 오른쪽 자식만 가질 수 있다.
leaf 노드이거나 하나의 자식만 가진 노드를 삭제하는 방법은 앞서 했던 방식과 동일하다.
else:
successor = self.find_min(node_to_delete.right_child)
node_to_delete.data = successor.data
if successor is successor.parent.left_child:
successor.parent.left_child = successor.right_child
else:
successor.parent.right_child = successor.right_child
if successor.right_child is not None:
successor.right_child.parent = successor.parent이 세 가지 삭제 연산에 대한 시간 복잡도는 아래와 같다.
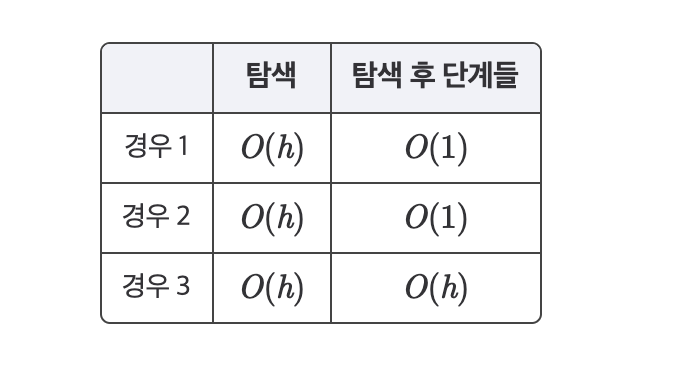
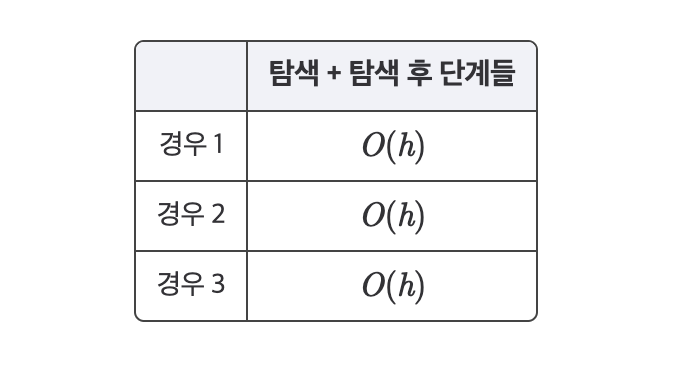
위의 표에서처럼 기본 연산(탐색, 삽입, 삭제)의 시간 복잡도는 모두 이다.
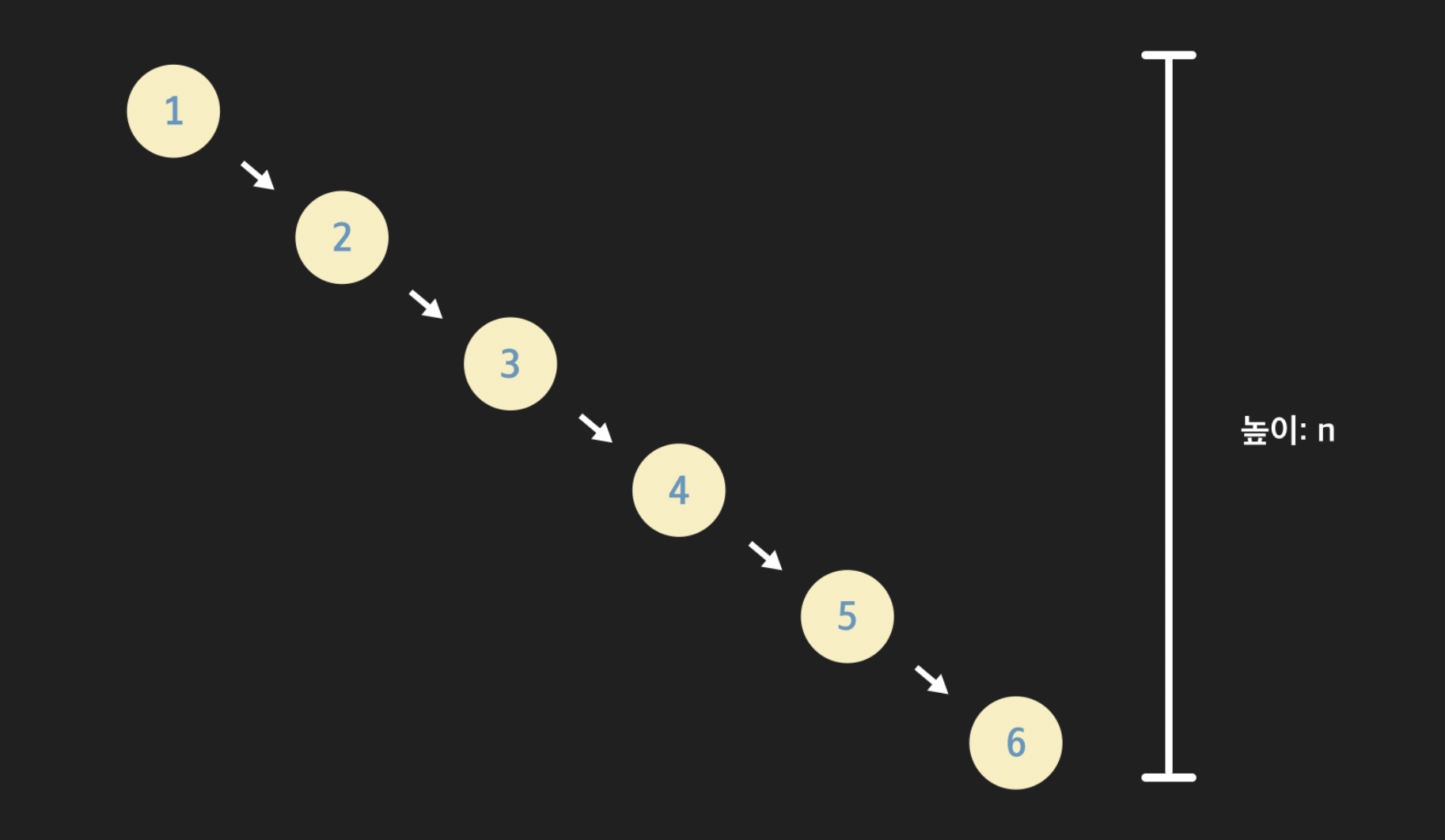
위와 같은 경우 노드 개수가 일 때, 트리의 높이도 이다.
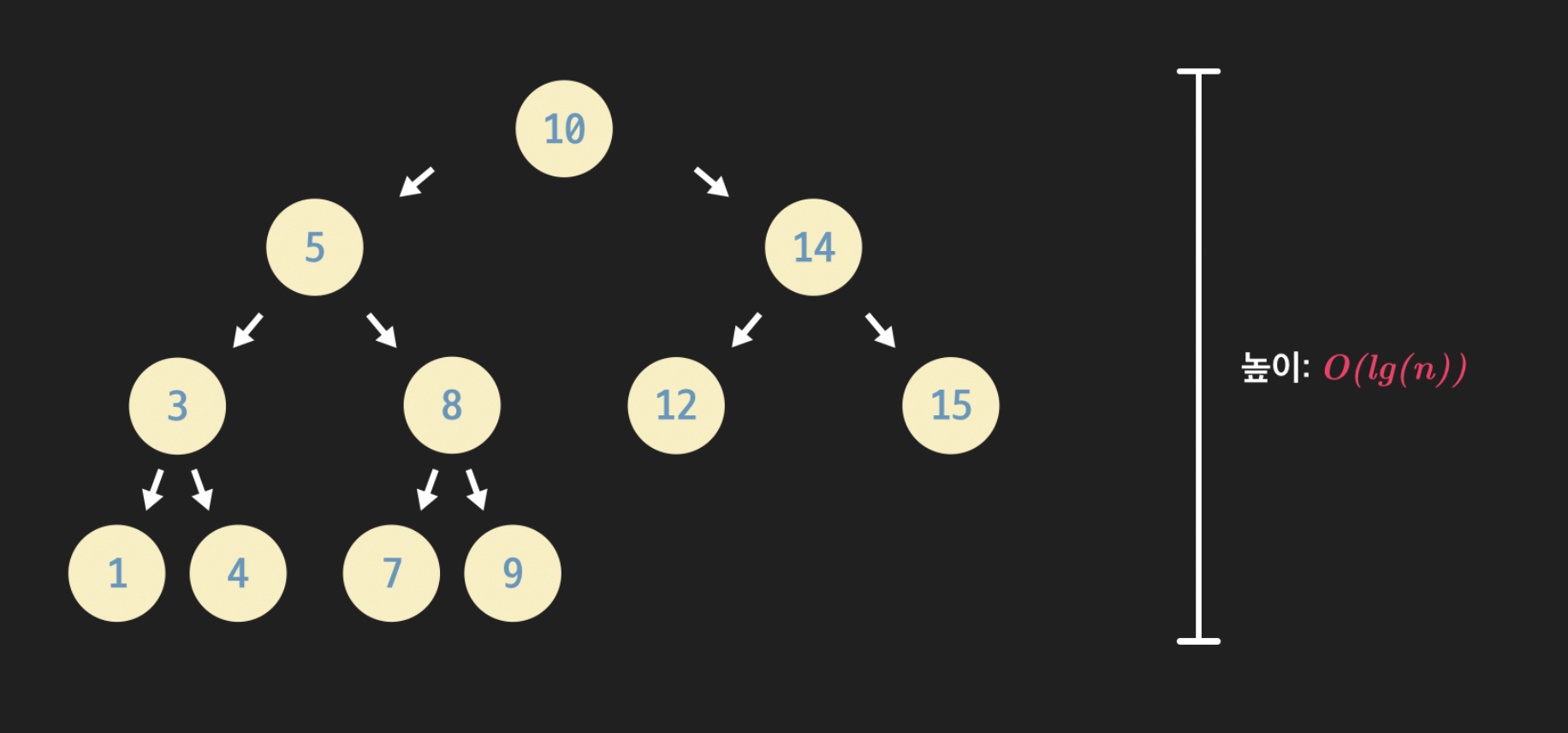
반면 위와 같은 경우는 균형 잡힌 트리다. 균형 잡힌 모양일수록 트리의 높이는 낮아지고 그만큼 연산이 효율적으로 이뤄진다.
평균적인 트리의 높이는 수학적인 계산에 의해 이며, 이를 정리한 표는 아래와 같다.
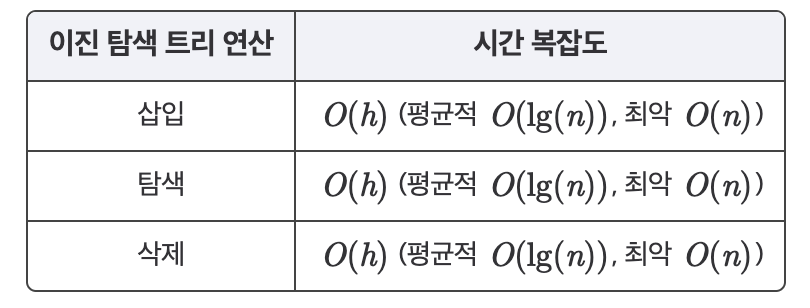
이진 탐색 트리를 사용하여 파이썬 추상 자료형인 세트(set)와 딕셔너리(dictionary)를 구현할 수 있다. 시간 복잡도는 해시 테이블보다 비효율적이지만 그럼에도 데이터 간의 순서에 의해 정렬된 데이터를 가져오고 싶거나 혹은 정렬하고 싶은 경우에는 이진 탐색 트리를 사용할 수 있다.
