
알고리즘 연습
퀵 정렬
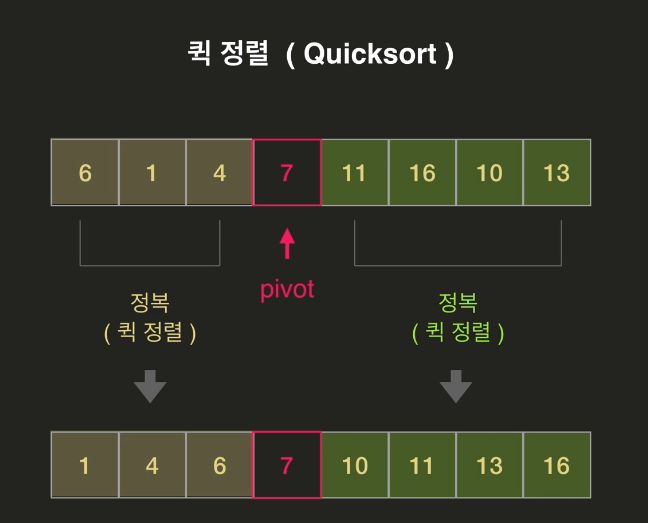
pivot(기준값) 을 중심으로 보다 작은 값들의 배열과 보다 큰 값들의 배열을 정렬하는 방식
pivot을 기준으로 나누는 것을 partition 이라고 한다. Divide and Conquer 의 Divide 단계이다.
pivot 의 양 옆에 값이 1개씩 있거나 혹은 없을 때까지 재귀적으로 반복한다.

실제 퀵 정렬의 partition 과정은 위와 같다.
가장 맨 앞의 인덱스부터 기준값과 값을 비교하여, b와 i의 인덱스를 움직인다.
비교값이 큰 경우에는 i만 움직이고, 반대의 경우에는 b,i 둘다 움직이는 동시에 서로의 인덱스를 바꾼다.
위와 같은 작업을 반복하고 i가 끝까지 오면 b와 pivot의 위치를 바꾼다.
# 두 요소의 위치를 바꿔주는 helper function
def swap_elements(my_list, index1, index2):
my_list[index1],my_list[index2] = my_list[index2],my_list[index1]
return my_list
# 퀵 정렬에서 사용되는 partition 함수
def partition(my_list, start, end):
p = end
b = start
i = start
while i < p:
if my_list[i] <= my_list[p]:
swap_elements(my_list, b, i)
b += 1
i += 1
swap_elements(my_list, b, p)
p = b
return ppartition 함수가 완성되면, 이를 바탕으로 퀵 정렬을 실행한다.
# 퀵 정렬
def quicksort(my_list, start=0, end=None):
if end is None:
end = len(my_list)-1
if end - start < 1 :
return
p = partition(my_list, start, end)
quicksort(my_list, start, p-1)
quicksort(my_list, p+1, end)
return
# 내가 착각해서 잘못 구현했던 부분
# left_list = my_list[:p]
# right_list = my_list[p+1:]
# quicksort(left_list, start, len(left_list)-1)
# quicksort(right_list, start, len(right_list)-1)처음 구현할 때는 기존 list를 left_list, right_list 로 각각 나눠서 다시 재귀적인 퀵 정렬을 시행하였다. 이렇게 하면 최초 하나의 리스트에서 정렬이 시행되는 것이 아니라 마치 각각이 다른 리스트인 것처럼 실행되어 잘못된 결과물이 나온다.
# 정답
[1, 5, 7, 9, 13, 15, 28, 30, 48]
# 오답
[13, 9, 1, 5, 7, 15, 30, 28, 48]위의 오답처럼 partition 으로 분할된 각각의 리스트만 정렬될 뿐, 전체 리스트의 정렬은 시행되지 않았다. 퀵 정렬은 새로운 리스트를 생성하지 않고 정렬만 한 상태로 함수가 종료되기 때문에 이를 반영해야 한다.

keep calm and carry on