
DB 동시성 문제
동시성이란?
사전적 의미는 하나의 CPU 코어에서 시간분할(Time sharing)을 통하여 여러 일을 처리하는 것 처럼 보여지게 하는 기법을 의미합니다.
하지만, 대중적으로 알려진 내용은 여러 요청이 동시에 동일한 자원(data)에 접근하고 변경해서 예상되는 결과값이 다르게 나오는 것을 의미합니다.
대용량 트래픽을 가정한 제 개인 프로젝트에서 스터디룸을 예약하는 기능에서 Reservation 엔티티를 create하는 작업단위(Transcation)를 실행해야 합니다. 이 기능에서 동시성 이슈가 생겨날 수 있다고 생각했습니다.
스터디룸 예약 등록 동시성 문제
예약한 시간(startTime ~ endTime)단위에 reservation이 있는지 check하고, reservation를 등록하는 아주 간단한 로직입니다.
// reservationId 검색 있을시, DUPLICATED_ENTITY 에러 발동
reservationRepository.findById(reservation.getId()).ifPresent( r -> {
log.error("Same reservationId is existing, can't make the reservation");
throw new WSApiException(ErrorCode.DUPLICATED_ENTITY, "The same reservation exists.");
});
하지만 만약 동시에 이런 작업단위(예약요청)을 하는 경우는 어떻게 될까요?
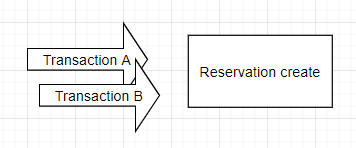
위 그림과 같이, 동시에 같은 방을 예약하는 사용자가 생겨나게 됩니다.
더블부킹(동시에 요청자가 예약)이 일어났을시, 같은 시간대, 같은 룸에 대한 정보가 테이블에 존재하게 되는 문제가 생기고 맙니다.
즉, 동시에 사용자가 같은 시간대, 같은 룸에 대해서 예약(Reservation)을 할 수 있는 상황에서 필드 내용이 중복이 되는 것입니다. DB의 정합성 문제가 발생하는 것입니다.
DB 동시성의 최대 문제는 바로 이런 것입니다.
데이터를 수정하여 저장했지만 다시 조회했을 때 다른 값이 반환되는 경우입니다. 이때 데이터의 무결성이 깨지고, 의도하지 않은 결과가 반환되는 것입니다.
DB의 필드내용과 함께 Atomic하게 insert, update 하는 방식을 생각해봐야 했습니다.
이를 어떻게 해결할 수 있을까요?
처음엔 Lock을 거는 방법으로 고려해보았습니다.
1) Synchronized
첫번째는 자바의 synchronized 키워드를 사용하는 방법이었습니다. synchronized를 사용함으로써 임계 영역을 지정할 수 있었습니다.
임계 영역이란 멀티 쓰레딩 환경에서 하나의 스레드만 접근할 수 있는 영역을 말합니다.
하지만 synchronized로 이 문제를 해결할 수 있지만 문제 해결 비용이 너무나 큰 게 문제였습니다.
왜냐하면, synchronized는 임계 영역에 접근하는 모든 예약 요청(Thread)들을 동기화하기 때문에 같은 방이 아닌 다른 방의 예약일지라도 Blocking이 발생하기 때문입니다.
이는 심각한 성능 저하로 이어질 수 있습니다.
예를 들어 10번 방, 20번 방을 동시에 예약하는 경우에도 Blocking이 발생할 수 있다는 것이죠.
데이터베이스 레벨에서 제어하기
코드상으로 구현하는 방법보단 DB에서 제어하는 방식도 생각할 수 있었습니다. Mysql에서 지원해주는 Lock 기능들을 생각한다면요.
이 방식은 현재 등록, 또는 수정하려는 데이터가 언제든 다른 요청에 의해 수정될 가능성을 고려하여 해당 데이터에 Lock을 거는 방식입니다.
lock을 거는 방식에는 크게 2가지가 존재합니다.
2) PESSIMISTIC(비관적) Lock
트랜잭션 간 lock이 발생할것이라는 관점이라서 비관적 lock 이라고 합니다.
mysql에서 ~~ for update와 같은 방식의 쿼리로 lock을 요청합니다.
배타적 잠금(exclusive Lock) 또는 비관적 잠금(PESSIMISTIC Lock)이라 불리는데, Write 작업뿐만 아니라 SELECT 구문조차 접근할 수 없는 레벨의 잠금입니다.
더 파고들자면, Where 조건절에 일치하는 레코드를 검색하기 위해 접근한 모든 레코드에 대해 배타적 넥스트 키 락을 걸게 됩니다.
사용법은 아래 쿼리처럼 작성되서 선언하는 꼴입니다.
SELECT reservation_id FROM reservation
WHERE room_id = 'roomA' AND start_time <= 'endTime' AND end_time >= 'startTime' FOR UPDATE
# FOR UPDATE : 배타적 락MySQL InnoDB에서는 레코드 기반의 잠금 기능을 지원하고 있습니다. (정확히는 인덱스의 레코드임)
따라서 위 쿼리는 만약 1번 방을 예약하는 경우에 1번 방에 대한 레코드들만 그리고 최소 영역의 시간 범위의 레코드 잠금이 자동 걸리게 됩니다.
첫번째 말한 synchronized를 사용해 모든 예약 요청에 잠금이 발생했던 것과는 달리, 이 방법은 Blocking으로 인한 성능 저하도 크지 않게 됩니다.
그리고 ✨ 여러 서버에서 동시에 중복 요청이 발생하더라도 결국에는 데이터베이스 레벨에서 제어하기 때문에 어플리케이션 서버의 수와 상관한 동시성 문제가 발생하지 않게됩니다.
- 실제 사용한 코드(JPA)
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select r.id from Reservation r left join fetch r.room where r.room.id = :roomId " +
"and r.startTime >= :sTime and r.endTime <= :eTime")
Optional<Reservation> findByIdLock(@Param("roomId") Long roomId,
@Param("sTime") LocalDateTime sTime,
@Param("eTime") LocalDateTime eTime);Serveice
reservationRepository.findByIdLock(roomId, sTime, eTime).ifPresent( r -> {
log.error("Same reservationId is existing, can't make the reservation");
throw new WSApiException(ErrorCode.DUPLICATED_ENTITY, "The same reservation exists.");
});
그외 Optimistic Lock은 테스트 결과 DeadLock 상황이 발생할 가능성이 있여 사용하지 못했습니다.
그러나...
예약하는 방에 대한 예약 레코드가 존재하지 않는 경우, 방에 대한 인덱스 레코드가 존재하지 않아 갭 락이 걸리지 않게 되고 그사이에 같은 Time, 같은 room을 예약하는 더블부킹이 발생할 수 있었습니다.
여기서 갭락 && 넥스트 키 락이란?
1) 갭락
- 갭락은 레코드 자체가 아니라 레코드와 바로 인접한 레코드 사이의 간격만을 잠그는 것을 의미.
- 갭락의 역할은 레코드와 레코드 사이의 간격에 새로운 레코드가 생성되는 것을 제어하는 것.
- 넥스트 키의 일부로 사용됨.
2) 넥스트 키 락
- 레코드 락과 갭 락을 합쳐 놓은 형태의 잠금을 넥스트 키 락
- innodb_locks_unsafe_for_binlog 파라미터가 비활성화되려면(파라미터 값이 0으로 설정되면) 변경을 위해 검색하는 레코드에는넥스트 키 락 방식으로 잠금이 걸림.
- InnoDB의 갭 락이나 넥스트 키 락은 바이너리 로그에 기록되는 쿼리가 슬레이브에서 실행될 때 마스터에서 만들어낸 결과와 동일한 결과를 만들어내도록 보장하는 것이 주 목적.
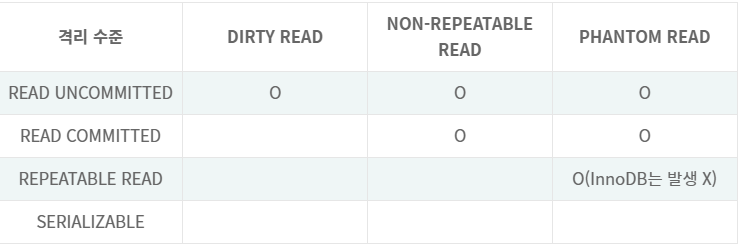
MySQL의 기본 격리 수준은 REPEATABLE READ고, 레코드가 정확히는 인덱스 레코드에 락을 겁니다.
REPEATABLE READ 격리 수준에서는 넥스트 키 락이 기본적으로 동작하고 해당 인덱스 레코드뿐만 아니라 사이의 갭까지 락을 거는 특성이 있습니다.
넥스트 키락이 갭에도 락이 걸어지기 때문에 의도치 않게 넓은 범위의 레코드에 락이 걸려 문제가 발생할 확률이 높아집니다.. 특히 저는 startTime, endTime 같은 예약시간안에서 reservation을 조회할 때 그럴 수 있었습니다. 이를 주의해서 최적화된 쿼리를 만들 수 있도록 해야 했습니다.
참고) 아래 격리수준을 나타내는 표입니다.
더블 부킹(같은 룸, 같은 시간) 문제
갭락에 대한 중복문제... 그래서 테이블의 PK를 String으로 변환
저는 여기서 추가로 간단하게 테이블 설계 시 PK를 int였던 것을 varchar(char)로 변환해 reservationId의 유일성을 만들어 해결하게 되었습니다.
더블부킹(동시에 요청자가 예약)이 일어났을시, 같은 시간대, 같음 룸에 대한 정보가 테이블에 존재하게 되는 문제는 결국 pk인 reservation_id를 int type으로 되어 있는 게 문제였습니다.
DB PK 값에 Type을 Long(BigInt) 에서 String(Varchar)으로 바꿔주고 규칙을 삽입할 것
간단하게 해결 할 수 있을 거라 생각했습니다.
중복 제거를 위한 규칙을 문자열로 reservation_id에 변환해, PK의 unique한 성질을 유지함과 동시에 Lock을 자동으로 설정할 수 있는 대리키로 만드는 것입니다.
👀 그런데 대리키란 무엇일까요?
한마디로, Entity 의 식별자가 외부에 오픈되서 오용되지 않기 위해, 식별자가 아닌 키를 말한다. 대개 String 기반의 token 을 생성하고 unique index 로 설정한다.
성능적으로 이슈가?
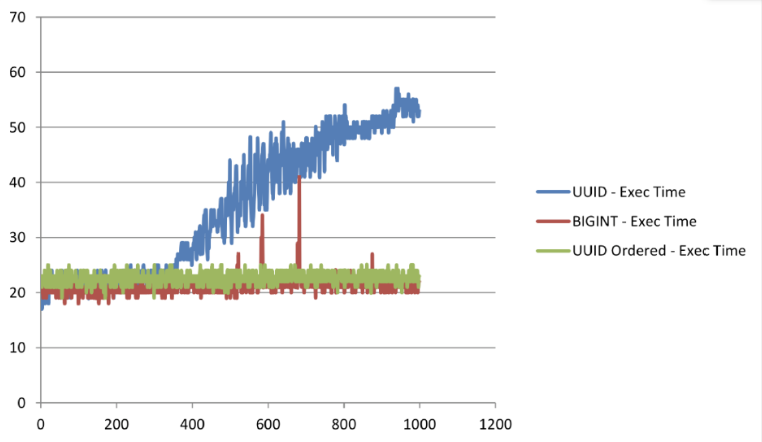
대리키로 String 값으로 하니 Number 타입의 키값보단 느릴 수 있다고 생각할 수 있습니다. 하지만 실제 성능적으로는 차이가 없었습니다. 만약 정렬된 규칙의 String 값이라면 말입니다.
아래 그림을 보시면 random한 UUID값이라면 성능 차이가 나지만 Ordered 즉, 정렬된 규칙을 가지고 있는 값이라면 Number 타입의 키 값 조회 성능은 차이가 없습니다.
다음 블로그를 보시면 참고할 수 있습니다.
https://velog.io/@mooh2jj/DB-대체키에-대하여
Entity pk와 동등하게 사용하는 대리키(Surrogate Key)로 처리하기
DB pk 필드값을 유니크하게 처리하기 위해 사용할 대리키에 중복(같은 룸, 같은 시간) 제거를 위한 정렬 규칙이 있어야 한다고 말했습니다. 그러기 위한 값 설정 규칙은 어떻게 했을까요?
규칙 : 등록한 roomId || 예약한 시작시간 으로 reservationId를 generate 해봤습니다.
// 실제 java로 구현한 reservationId generate 메서드
private String genReservationId(Room room, String startTime) {
return room.getId() + "||" + startTime;
} 예를 들면, reservation_id = 1||2022-04-12 10:00:00 는 2022년 4월 12일 10시 룸 1번 방으로 예약을 한다는 의미입니다.
실제 DB의 값들

이렇게 하면 일단은 숫자형태가 ||를 기준으로 앞과 뒤에도 있다보니 정렬할 수 있게 나열도 가능해집니다.
pk로서의 unique 성질과 정렬된 String 키값이 돼 레코드에 Lock이 걸려 중복예약(Duplicate booking)을 쉽게 막을 수 있게 됩니다.
그러면 statTime과 endTime 갭락에 대한 중복 예약 문제는 해결 되는 것이고 기존의 Pessmistic Lock 방식에 startTime과 endTime을 빼고 ReservationId만 where 조건절에서 간단하게 체크하면 되었습니다.
- service
reservationRepository.findByIdLock(roomId, sTime, eTime).ifPresent( r -> {
log.error("Same reservationId is existing, can't make the reservation");
throw new WSApiException(ErrorCode.DUPLICATED_ENTITY, "The same reservation exists.");
});- 바꾼 코드
// startTime과 endTime where절에서 제거
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select r from Reservation r where r.id = :reservationId")
Optional<Reservation> findByIdLock(@Param("reservationId") String reservationId);
🍀 대리키, 하지만 완전한 대리키가 아님
대리키는 arrange한 random 값으로서 pk int 값을 대체한 키라고 합니다. 하지만 저는 uuid값을 생성하는 식으로 식별하지는 않았습니다. 단지 기존의 startTime과 reservationId 합친 String타입으로 대체했을 뿐입니다.
고로, pk의 레코드당 잠금기능으로 동시성 제어와 대리키의 unique한 성질로 중복(Duplicated 예약)막기 위해 각자의 장점을 취합했던 것입니다.
그리고 pk로서의 역할같이 하는 키로 두었습니다.
사실 대리키를 쓰는 이유 중에 하나가 외부에 노출되도 상관없는 stateless한 값이기 때문에 Number 타입의 pk키를 대리했던 것입니다.
제가 만든 String 타입의 규칙은 상당한 정보가 있기때문에(stateful) 외부노출을 하면 안되는 값이었습니다.
현재 개선 상황
지금 상황에서 개선한 점은, 중복예약은 DB단이 아닌 비즈니스 로직에서, exceptionHandler를 이용한 예외처리로 validation을 하고
String 타입의 random 대리키와 number 타입의 pk 둘다 가지게 구현해보았습니다. 향후 외 / 내부에서 쓰이는 pk 규칙을 모두 다루기 위함입니다.
외부에서 보낼 때는 노출해도 상관없는 UUID 키의 String unique 값을 보내주고 내부에서 사용할 때는 pk를 사용하는 식으로 진행할 수 있도록 한 것입니다. (2022-11-28)
pk와 unique 인덱스 설정 후 조회성능이 얼마나 이루어지는지 다름 블로그에서 참고할 수 있습니다.
https://velog.io/@mooh2jj/MySQL-실행계획으로-성능-측정하기인덱스-설정-이후
다른 방법은?
1) 유니크 복합키
유니크 인텍스 DML작업(insert, update, delete)시 데드락(DeadLock)이 자주 발생해 위험하다 판단했습니다.
2) 직렬성 격리
직렬성 격리는 가장 강력한 격리 수준입니다. 여러 트랜잭션이 병렬로 실행되더라도 최종 결과는 동시성 없이 한 번에 하나씩 직렬로 실행될 때와 같도록 보장합니다. 즉, 데이터베이스가 발생할 수 있는 모든 경쟁 조건을 막아줍니다.
일반적으로 InnoDB에서는 넥스트 키 락(갭 락 + 레코드 락)을 통해 REPETABLE READ 격리 수준에서도 팬텀 리드가 발생하지 않아 SERIALIZABLE 격리 수준을 사용할 일이 없습니다.
현재 상황처럼 인덱스 레코드가 존재하지 않아 갭 락을 걸 수 없는 특별한 상황이니 쓸 수 있는 겁니다.
MySQL InnoDB에서는 2단계 잠금 구현을 통해 직렬성 격리 수준을 구현하고 있습니다. MVCC와 2단계 잠금 구현의 차이는 MVCC의 경우 읽기 트랜잭션이 쓰기 트랜잭션을 막지 않고, 쓰기 트랜잭션도 읽기 트랜잭션을 막지 않지만, 2단계 잠금 구현의 경우 쓰기 트랜잭션은 다른 쓰기 트랜잭션뿐만 아니라 읽기 트랜잭션도 막으며, 읽기 트랜잭션도 쓰기 트랜잭션을 막는 것에 있습니다.
방법)
격리 수준을 SERIALIZABLE로 변경하고, 기존에 FOR UPDATE 구문을 삭제직렬성 격리도 마찬가지로 잠금을 획득하고 해제하는 오버헤드도 존재, 그르고 더 큰 문제는 동시성이 줄어드는 것입니다. 물론 REPETABLE READ 수준에서도 Deadlock이 발생할 수 있지만, 직렬성 격리 수준에서 데드락이 훨씬 더 많이 발생하게 됩니다.
참고

글 잘 읽었습니다! 👍👍
그런데 궁금한 점이 있습니다. 같은 방을 같은 시간에 예약한 내역이 있는지 체크하고 없다면 예약을 insert하는데 만약 이 validation과 insert사이에 다른 쓰레드가 validation을 진행하는 상황은 생길 수 없는 건가요? 그렇게 되면 중복예약이 되는게 아닌가해서요!