
😵많아지는 데이터들..
최근에 데이터들이 굉장히 많아 지는것을 알수 있습니다.
통계적으로 봤을때 2013년에는 4.4제타바이트였던거에 비해서, 2020년은 10배 증가한 44제타바이트가 될것이라고 전망했습니다.
왜 그런것일까?
-
사진

그러한 이유는 자연스럽게 우리 주변에서 찾아 볼수 있습니다.
할아버지나 15년 전만해도 우리가 찍는 사진이 그렇게 크거나 고해상도가 아니다 보니 용량이 크지 않았습니다.
하지만 지금 시대에는 하나의 사진이 엄청난 고해상도 이거나 많은 정보를 가지고 있다보니 큰 용량을 가지고 있습니다.
- 일상 생활에서의 데이터 그리고 사진뿐만 아니라 컴퓨터를 통해서 개인이 만들어내는 전화, 이메일, 문서와 같은 개인의 데이터들이 한달에 1기가바이트에 달합니다.
- 기계에서 생산되는 데이터
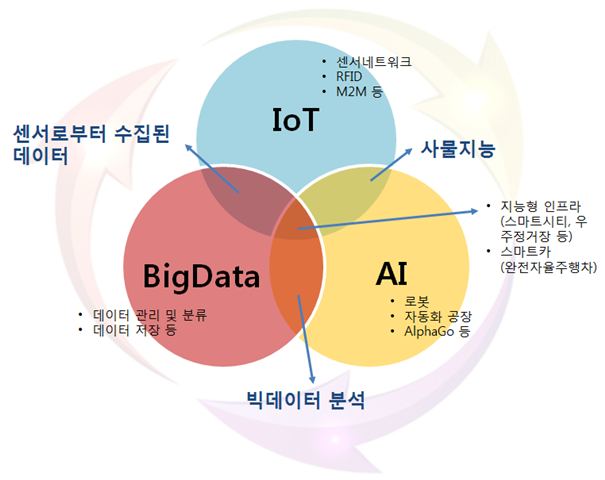
그리고 가장 중요한 사물인터넷의 일부인 기계에서 생산되는 데이터양이 눈에 띄게 증가했다는 것입니다.
기계로그, RFID 리더, 센서 네트워크, 차량 GPS궤적, 소매 거래 등은 데이터의 폭증을 가져왔습니다.
- 공개데이터의 증가
조직은 더 이상 자신의 데이터만 관리해서는 안됩니다. 미래의 성공은 다른 조직의 데이터에서 가치를 추출하는 능력에 달려 있기 때문입니다.
대표적으로 아마존 웹 서비스에서 공개한 데이터셋들을 무료나 유상으로 쉽게 내려받고 분석할 수 있는 ‘정보공유’의 장을 열었습니다.
이렇게 방대한 데이터와 활용등을 통해서 최근 가장 많이 발달하거나 관심이 가는것은 추천시스템이 있습니다.
과거의 선호도를 바탕으로 새로운 영화나 음악을 추천해주는 것과 같은 일부 문제에서 많이 하는 말은
“더 많은 데이터가 더 좋은 알고리즘보다 낫다.”
즉, 귀신같이 해결해주는 알고리즘이 있다고 하더라고 데이터가 충분히 많아야 쉽게 해결되는 경우가 가끔 있습니다.
좋은소식과 나쁜소식
- 좋은 소식 : 빅데이터는 우리 주변에서 많이 나온다
- 나쁜소식 : 이렇게 많은 데이터를 다루는것, 즉 저장하고 분석하는 것은 어렵다

DB 일기장