
- 행기반 데이터베이스
- 열기반 데이터베이스
데이터베이스를 공부하다보면 위처럼 두가지 종류의 데이터베이스를 만나게 됩니다.
처음 이 개념을 접했을때 관계형 데이터베이스에서의 행과 열은 알겠는데 이거들을 기반으로 하는 데이터베이스는 무엇일까 라는 궁금증이 있었습니다.
👉🏾 행기반 데이터베이스
행기반 데이터베이스는 우리가 일반적으로 사용하는 MySQL, Oracle, PostgreSQL과 같은 전통적인 관계형 데이터베이스를 말합니다.
-
기간계 시스템이라고 부르는 OLTP 환경(Insert, Update, Delete 작업이 빈번한 환경)에서 유리하게 작용합니다.
-
데이터를 행단위로 추가하며, 레코드 단위로 읽고 쓰기에 최적화 되어있습니다.
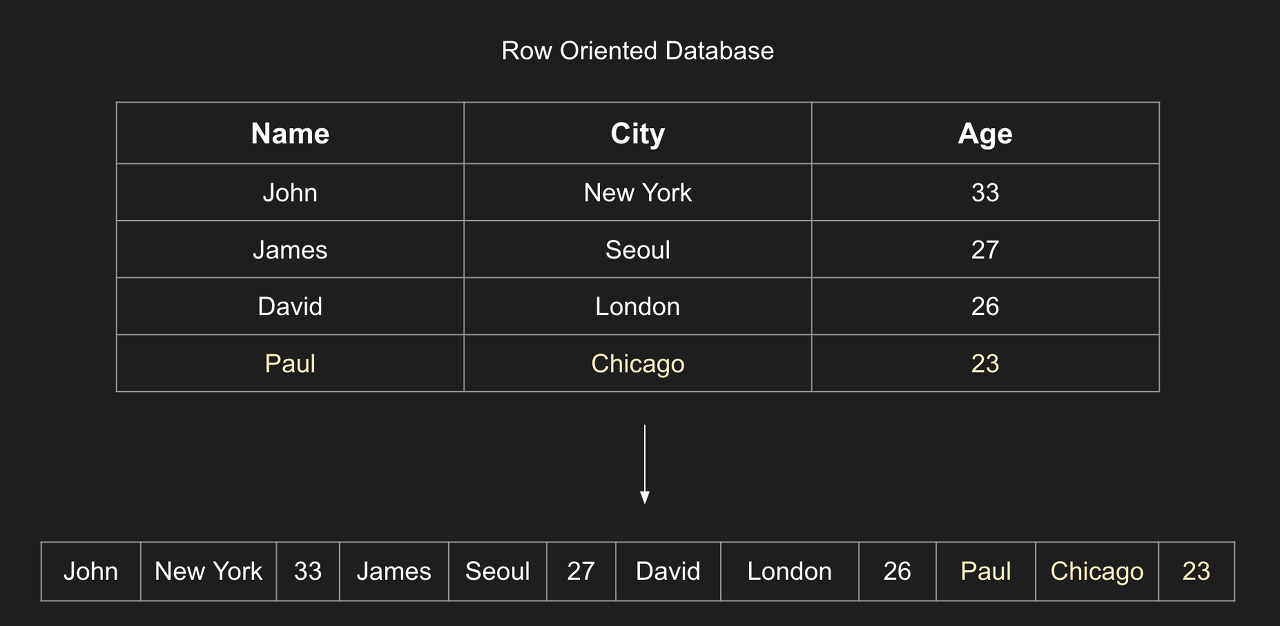
-
데이터의 검색 속도를 향상시키기 위해서 인덱스를 사용하곤 합니다. 인덱스가 없다면 모든 레코드를 불러와야 하고 그러면 데이터의 I/O가 많아져 성능저하가 오게됩니다.
-
데이터를 불러오는 과정에서 기본적으로 레코드 단위로 데이터가 저장되어있기 때문에 불러올때도 필요없는 데이터도 같이 불러오기 때문에 I/O를 잘생각해야합니다.
-
데이터를 저장하게 되면 디스크의 마지막에 추가가 됩니다.
👇🏾 열기반 데이터베이스

열지향 데이터베이스라고 불리고, 데이터 마트의 역할로 많이 사용합니다.
-
분석계 시스템이라고 부르는 OLAP 환경(Select 작업이 빈번한 환경)에서 유리하게 작용합니다.
-
빅데이터로 취급되는 데이터의 대부분은 디스크 상에 있고 쿼리에 필요한 최소한의 데이터만 가져오면서 지연을 줄일수 있습니다.
즉, 이를 위해서는 '컬럼단위로 데이터 압축'이 필요합니다. -
컬럼 단위로 데이터 로드가 가능하기 때문에 디스크의 I/O를 줄이고 높은성능을 가지고 있습니다.
-
데이터 추가할때 Column별로 추가되어야할 자리를 찾는 과정이 필요합니다.
-
조회작업의 성능은 행 기반 데이터베이스에 비해 높은 반면에 값을 삽입, 수정, 삭제하는 과정에서는 레코드의 수도 많고, 이에 따라 인덱스가 리빌드 되어야하는 과정이 포함되어 있어 성능이 현저하게 낮습니다.
🔗 https://chaarlie.tistory.com/674
책 : 빅데이터를 지탱하는 기술
