상당히 오랜만에 주간학습정리 포스팅을 작성하는 것 같다.
대회 때문에 제대로 학습정리를 못올렸는데, 사실 변명 맞다. 그냥 게을렀고 시간 관리 똑바로 못한 것 같다.
이번 주부터는 도메인별로 강의가 나누어졌는데 NLP는 지금까지 나온 기초 이론들에 대한 강의로 이루어져있다. 사실 Word embedding, RNN, LSTM, GRU, Attention은 꽤 예전에 공부하기도 했고 어느정도 안다고 생각했는데 강의를 듣다보니 꼼꼼하게 공부하지 않았던 듯한 기분이였다.
1. Bag-of-Words
Bag-of-Words는 단어의 표현 방법 중 하나이다. 내 기억이 맞다면 word2vec이 나오고 나서는 쓰이지 않는 것으로 알고 있다.
Bag-of-Words representation을 만드는 방법은 다음과 같다.
- Corpus에서 unique한 단어들만을 모아 vocabulary를 구축한다.
- Vocabulary내 각 단어들을 one-hot vector로 encoding한다.
꽤 단순한 방법으로 만드는데, 이렇게 단어를 표현하면 몇 가지 문제가 발생한다.
단어간의 연관성 계산을 못한다. 보통 벡터로 나타낸 단어들 사이의 유사도를 계산할 때에는 내적을 이용해서 cosine similarity를 계산하는데, one-hot vector간 내적의 값은 모든 경우에서 0이 나온다. 그리고 두 단어 벡터간 유클리드 거리를 계산해보면 모든 단어는 서로 의 거리를 갖게된다. 이 결과들은 곧 "모든 단어는 서로 관련없다" 로 해석된다. 당연한 말이지만 단어끼리는 특정한 관계가 있어서 이 해석은 실제로 말이 안된다.
그래서 좀 더 좋은 word representation을 만들려는 노력이 있었고...
2013년 Word2Vec이라는 아주 유명한 논문이 발표된다.
2. Word Embedding
Word embedding은 짧게 설명하면 "단어를 벡터로 나타내는 것"이라고 할 수 있다. one-hot vector도 벡터긴 한데 어떤 점이 다르냐면, word embedding은 단어를 Distributed Representation으로 표현한다는 것이다.
Dense vector라고도 불리는 distributed representation은 원래 매우 고차원이지만 0이 아닌값이 거의 없는 one-hot vector같은 sparse vector의 문제를 해결하기 위한 표현법이다. 벡터내의 값들은 0이나 1이 아닌 실수값으로 꽉 채워져 있고, 보다 저차원으로 단어를 표현하게 된다.
Distributed representation을 쓰면 좋은 점은 앞서 말했던 one-hot vector의 연관성 포착 불가 문제를 바로 해결할 수 있다는 점과 저차원 벡터를 사용함으로 메모리 사용량이 줄어든다는 것이다.
2-1. Word2Vec
Word2Vec은 이런 distributed representation을 사용해 단어를 표현하는 방법이다. 논문의 저자는 비슷한 단어들은 가까운 거리에 두고자 했고, 벡터 표현 학습을 타겟 단어 주변 단어들을 이용해서 진행하고자 했다. 이는 Distributional hypothesis에 의해 고안되었다.

Word2Vec 모델의 구조는 간단하다. 위의 그림과 같이 hidden layer 한 층으로 이루어져있고 parameter라고 해봐야 두 개의 weight matrix밖에 없다.
학습은 dense vector로 표현된 단어 하나가 입력으로 들어오고 해당 단어를 이용해서 앞뒤 C개 단어를 예측하며 진행된다. 이는 Skip-gram 방식이라고 한다. 주변 단어들을 이용해서 타겟 단어 하나만을 예측하는 것을 CBOW라고 하지만 Skip-gram 방식의 성능이 더 좋아 Skip-gram 기준으로 설명했다.
Skip-gram 방식이 좀 더 좋은 이유는 아마 task가 어렵기도하고 예측해야 할 값이 많아 좀 더 학습이 잘 되지않았나 생각한다. Skip-gram은 2C개 단어를 예측해야해서 학습 경우의 수가 많으나 CBOW는 여러 개의 단어로 하나의 출력만을 예측해서 훨씬 적은 수의 예측만을 진행한다.
그러면 이렇게 학습을 끝마치고 무엇을 이용해서 word embedding을 표현할까?
위의 그림을 다시 보게 되면 과 두 개의 weight가 있는데 이 중 하나를 Word2Vec의 word embedding으로 사용한다. (보통은 을 이용한다.)
Word2Vec의 특징으로는 vector간 덧,뺄셈으로 다른 단어를 표현할 수 있다는 점이다. 예를 들어 vec(king) - vec(Queen) = vec(Man) - vec(Woman)과 같은 관계가 성립한다.
이를 이용해서 word vector에 특정한 관계를 추가하거나 제거할 수 있다.
2-2. GloVe
GloVe 또한 Word2Vec과 같은 word representation 학습 방법 중 하나인데, Word2Vec과 비슷하게 단어들의 동시 등장 횟수를 이용해서 단어의 표현을 학습한다. 특정 크기의 window내의 단어간 동시 등장 빈도를 세고 이를 학습에 사용한다.
Word2Vec보다 좀 더 빠른 학습을 기대할 수 있고 더 적은 크기의 corpus에서도 꽤 괜찮은 성능을 나타낸다.
두 방법 모두 여러 NLP task의 발전에 큰 영향을 가져왔으나 단점도 존재한다. 둘 모두 동시 등장 빈도를 기반으로 하는 표현 방법이라 corpus의 크기가 충분히 거대하지 않다면 비슷한 맥락에서 등장하나 연관없는 단어들이 자칫 서로 높은 연관성을 갖도록 학습이 될 수도 있다.
3. Beam Search
Beam search는 자연어 생성 모델의 생성 문장 품질 향상을 위해 고안된 기법이다.
기본적인 자연어 생성 모델의 문장 생성은 매 time-step마다 확률이 가장 높은 단어를 선택하고 그 선택을 기반으로 다음 단어를 생성하는 Greedy decoding 방식을 사용한다. 이 방법은 문제가 하나 있는데, 생성 도중 단 하나의 단어라도 이상한 단어가 생성된다면 뒤의 내용은 아예 말이 안되는 문장이 완성될 가능성이 커지게 된다.
이를 막는 완벽한 방법은 모든 경우의 수에 대해 문장을 생성하고 완성된 각각의 문장에 대해 전체 생성 확률을 기준으로 가장 그럴듯한 문장을 선택하는 것이다. 하지만 이 방법은 문장 길이가 t일 경우 복잡도가 vocabulary 크기의 t제곱 () 으로 어마무시하게 커진다는 것이다.
그래서 절충안으로 고안된 방법이 Beam search이다.
Beam search는 매 time-step마다 단어 생성시 생성될 확률이 가장 높은 K개의 단어에 대해서만 생성을 진행해나가는 방식이다. 여기서 K는 beam size를 말한다.
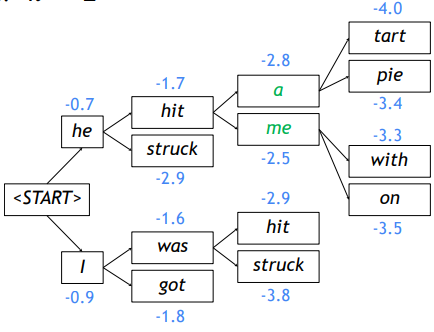
위 그림은 beam size가 2인 경우를 나타내며 매 time step마다 각 경우에서 2개의 경우에 대해 생성하고 각 생성 중 가장 확률이 높게 나타나는 2개의 경우에 대해서만 같은 과정을 반복한다.
Beam search를 사용하면 생성되는 K개의 경우가 서로 다른 길이의 문장을 가질 수 있는데, beam search는 n개의 문장이 <EOS> 토큰을 생성하거나 최대 time-step으로 설정한 time-step T에 도달하게 되면 search를 종료한다. 여기서 n은 미리 설정된 최대 문장 갯수이다.
Beam search를 사용한다고 해서 반드시 가장 높은 확률의 문장을 생성해내지는 못한다. 하지만 greedy보다는 조금 더 최적의 답을 낼 수 있고, 전체 경우의 수를 전부 다 보는 경우보다 훨씬 효율적으로 더 좋은 답을 끌어낼 수 있게 된다.
4. BLEU
BLEU score는 자연어 생성 모델의 평가 척도이다.
BiLingual Evaluation Understudy의 약자인데, 주로 번역 모델에서 사용되는 평가 척도이다.
평가 방식은 precision을 기반으로 해서 점수를 계산한다.
위와 같은 수식으로 precision 점수를 계산하는데 해석하자면, 생성 문장과 정답 문장간 겹치는 단어 수를 생성 문장의 길이로 나누어 준 값이다. 하지만 그저 precision을 이용해서 성능을 평가한다면 문제가 하나 생긴다. 겹치는 단어의 수만을 기준으로 점수를 내기 때문에 단어의 순서가 바뀌어 문장이 말이 안되거나 의미가 완전히 달라지더라도 같은 점수가 계산된다.
이 문제를 처리하기 위해 BLEU는 겹치는 단어의 수가 아닌 겹치는 n-gram의 수를 이용해서 precision을 계산한다. 그리고 BLEU는 precision뿐만 아니라 recall도 어느정도 고려해서 계산하는데 여기서 recall은 전체 정답 문장 중에서 예측 문장이 포함하는 n-gram의 수를 이야기한다고 보면된다.
Recall은 주로 summarization task에서 ROUGE라는 평가 척도의 기반이 된다.
BLEU의 수식을 나타내면 아래와 같다.
수식 앞쪽의 min 부분을 brevity penalty 라고 부르며 이 부분이 recall 고려를 위해 만든 장치인 동시에 정답 문장보다 생성 문장의 길이가 짧을 경우 점수에 패널티를 주기 위해 사용된다. 그리고 뒤쪽의 항은 uni-gram부터 4-gram까지 precision들의 기하 평균을 계산한 값을 말한다.
5. 회고
5-1. 강의
이번주 강의는 대부분 NLP task에서 사용되는 기초 이론에 대한 내용이였다. Word2Vec이나 RNN계열 모델들에 대해서는 논문도 몇번 읽어보고 자주 접해와서 익숙한 내용이였다.
하지만 beam search는 처음 공부해보는 내용이였다. 이전에 집현전 스터디에서 다른 분이 발표하셨던 논문인 If Beam search is the answer, what was the question?이라는 논문에서 처음 beam search라는 것을 접하게 되고, 공부해야지라는 말만 반복하면서 제대로 공부하지 않았었는데 이 기회에 알게 되어서 좋았다. 논문이 제목으로만 봐서는 "Beam search가 좋다는 것은 인정하는데 그래서 왜 쓰는가?"에 대한 내용으로 유추돼서 주말에 시간이 된다면 한 번 읽어보고 정리해봐야겠다는 마음이 생겼다. (제발 지켜라 나야...)
5-2. 피어세션
이번에 Level2가 시작되고 새로운 팀원분들과 제대로 피어세션을 시작했다.
이전 팀에서 조금 아쉬웠던 부분이 피어세션에 은은하게 시간을 많이 낭비했던 것이였는데, 이번 팀에서는 첫날부터 피어세션의 진행방향을 정하고 앞으로 할 것들에 대해서 논의해서 좋았다.
그리고 무엇보다 피어세션동안 오디오가 안비었다는 점...! 사실상 공식적인 첫 만남이였지만 다들 이야기를 너무 잘해주셔서 즐거운 시간이였다.
팀 단위로 무엇인가를 할 때 소통이 가장 중요하다고 생각하는데 이정도로 다들 이야기를 잘해주셔서 나중에 있을 프로젝트가 너무 기대된다.
