오늘의 학습 리스트
LMS
- Sparse Representation
- "Sparse representation (SR) is used to represent data with as few atoms as possible in a given overcomplete dictionary."
- 벡터의 차원마다 특징적 의미를 내포한다고 하고 벡터를 만든다.
- Distributed Representation
- 위와 같이 차원마다 특징이라고 칭하지 않고, 벡터 전체에(즉 차원 모두에) 단어의 의미가 골고루 퍼져 있다고 여긴다.
- 핵심적으로는
비슷한 문맥에서 동일한 위치에 나오는 단어들은 유사도가 있다!라는 distribution hypothesis를 따르는 것 - 벡터 전체에 의미가 있다고 볼 수 있어서 벡터 계산을 통해 유사도를 파악할 수 있다.
- Embedding layer
- One-hot encoding을 기반으로 한다.
- 순서대로 하자면,
- 1) 단어 사전의 형태 정의
- 2) 문장들 정수 인코딩
- 3) 문장들 단어마다 정수 인코딩 -> one-hot encoding
- 4) 그 아웃풋을 선형변환 시켜서 나름 의미를 가진 벡터로 만듦
- 주의할 점은 이 레이어는 미분이 안된단다.
- 단순히 단어들을 정수로 바꾸고, 그걸 또 0과 1로 바꾼 것이니...
- 그래서 신경망 중간에 못 쓰고,
- 입력층 바로 뒤에만 쓸 수 있다.
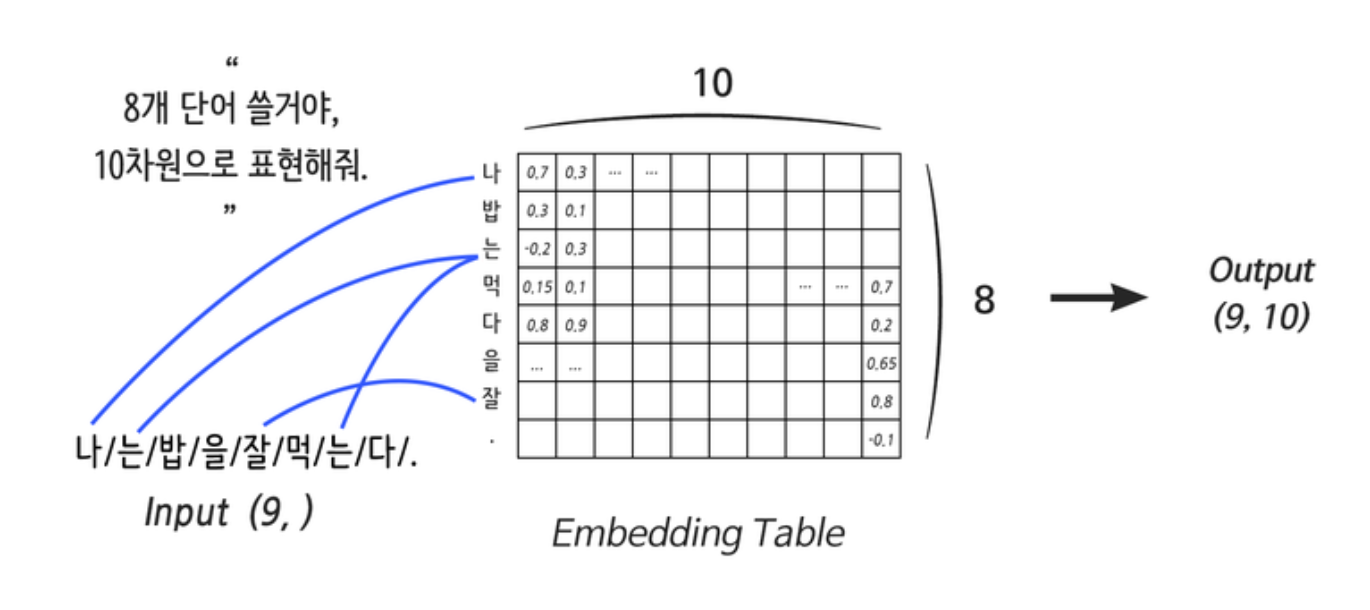
- Embedding 레이어에서 input과 output
- input은 내가 정의하는 단어 사전에서 단어의 갯수인 듯하다
- 이는 현재 내가 embedding에 넣으려는 문장이 가지는 단어 수와는 무관하다.
- 그리고 output은 단어의 갯수를 몇 차원의 벡터로 나타내고 싶은지를 뜻하는 것 같다.
- 임베딩 레이어의 weight(가중치) 갯수와 이것들이 어떻게 해서 output vector를 내는지 알겠다...(https://stats.stackexchange.com/questions/270546/how-does-keras-embedding-layer-work)
- 결과적으로 수학적 연산을 해서 output vector를 내는 게 아니란다.
- lookup table에서 가져오는 것
- input은 내가 정의하는 단어 사전에서 단어의 갯수인 듯하다
- 벡터 공간에 대한 새로운 생각(나에게는)
- "머신러닝 ・ 통계학을 공부하는 많은 사람들은 벡터 공간(vector space)을 기하적인(geometric) 의미로 인식한다. 하지만 굳이 자세히 보자면 벡터는 덧셈(addition)과 스칼라 곱(scalar multiplication)에 관한 몇 가지 규칙으로 정의된 대수적(algebraic)인 공간에 더 가깝다."
- "이처럼 다양한 개념을 벡터 공간으로 추상화하는 이유는 좌표 공간에서 주로 사용하던 선형대수 기법들을 손쉽게 적용할 수 있어서다."
- https://www.kakaobrain.com/blog/6
- RNN
- 중요한 개념은 하나의 파라미터 셋을 each timestep에 동일하게 적용하는 것!
- LSTM
- 더 알아보자...
- GRU
- 더 알아보자...
- Bidirectional RNN
- 더 알아보자..
오늘은 앞 부분 내용 어느 정도 아는 거여서 시간이 많이 남겠다 싶었는데 아니었다..... embedding 레이어가 갑자기 이상한 output.shape을 내놓는 것부터 시작해서 그럼 RNN은 어떤 연산을 하는 건지....
여튼 이러다가 시간이 다 갔다..ㅜㅜ
- 더 알아보자..
Deep ML
- backpropagation 헷갈린다...(loss값, gradient 둘 다 0이 되는 게 좋은 건가...?)
- Batch Normalization
- Conv에서는 activation map마다 평균이 하나란다.
- Xavier initialization
- 가중치 초기화에 신경써서 saturated 된 output(즉, 이 경우 gradient가 죽는...?)가 나오지 않게 하자는 게 목표
- 수식이 잘 이해가지 않았었는데, 아래 링크의 설명을 보니까 조금 이해 간다.
- 링크(https://nittaku.tistory.com/269)
- Weight initialization은 결국 초기화 되는 가중치도 중요하지만, 중간에 레이어마다 있는 activation function의 종류도 중요한 것 같다.(이에 따라 더 좋은 초기화 방법이 달라진다)

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다