[AIFFEL] 22.Feb.03, Exploration - Deep_Learning_for_Medical_Image_Analysis
* 개인적으로 의학 관련 배경은 없지만, 인공지능을 배워서 가장 기여하고 싶은 분야가 바로 이런 공공기관 분야이다. 뭔가 흥미로울 것 같다.
오늘의 학습 리스트
-
의료 영상 분석으로서의 딥러닝
- 단점이 있다.
- 개인 데이터 privacy로 데이터 구하기 힘들다
- 희귀 질환이면 구하기 더 힘들다
- 라벨링 자체가 전문적 지식이 필요하고, 전문 인력의 필요는 곧 cost다
- 음성/양성 간 데이터의 imbalance가 심하다.
- 단점이 있다.
-
의료 영상 데이터 종류
- X-ray
- 방사선의 일종
- 잘 몰랐는데, 밀도가 낮은 건 쉽게 통과하고, 높은 건(예: 뼈) 통과하지 못한단다.
- CT(Computed Tomography)
- X-ray를 환자를 중심으로 빠르게 회전시켜서 3D 영상을 만드는 것
- 신체의 단면인 slice는 x-ray보다 더 자세한 정보를 포함한다.
- MRI(Magnetic Resonance Imaging(자기 공명 영상))
- 방사선을 사용하지 않는단다.
- X-ray
-
의료영상 관련 간단 설명 링크 -> (https://www.youtube.com/watch?time_continue=395&v=J_Owz3YBkD0&feature=emb_logo)
-
오늘은 x-ray 사진을 사용한다.
-
이 때 사진의 단면과
-
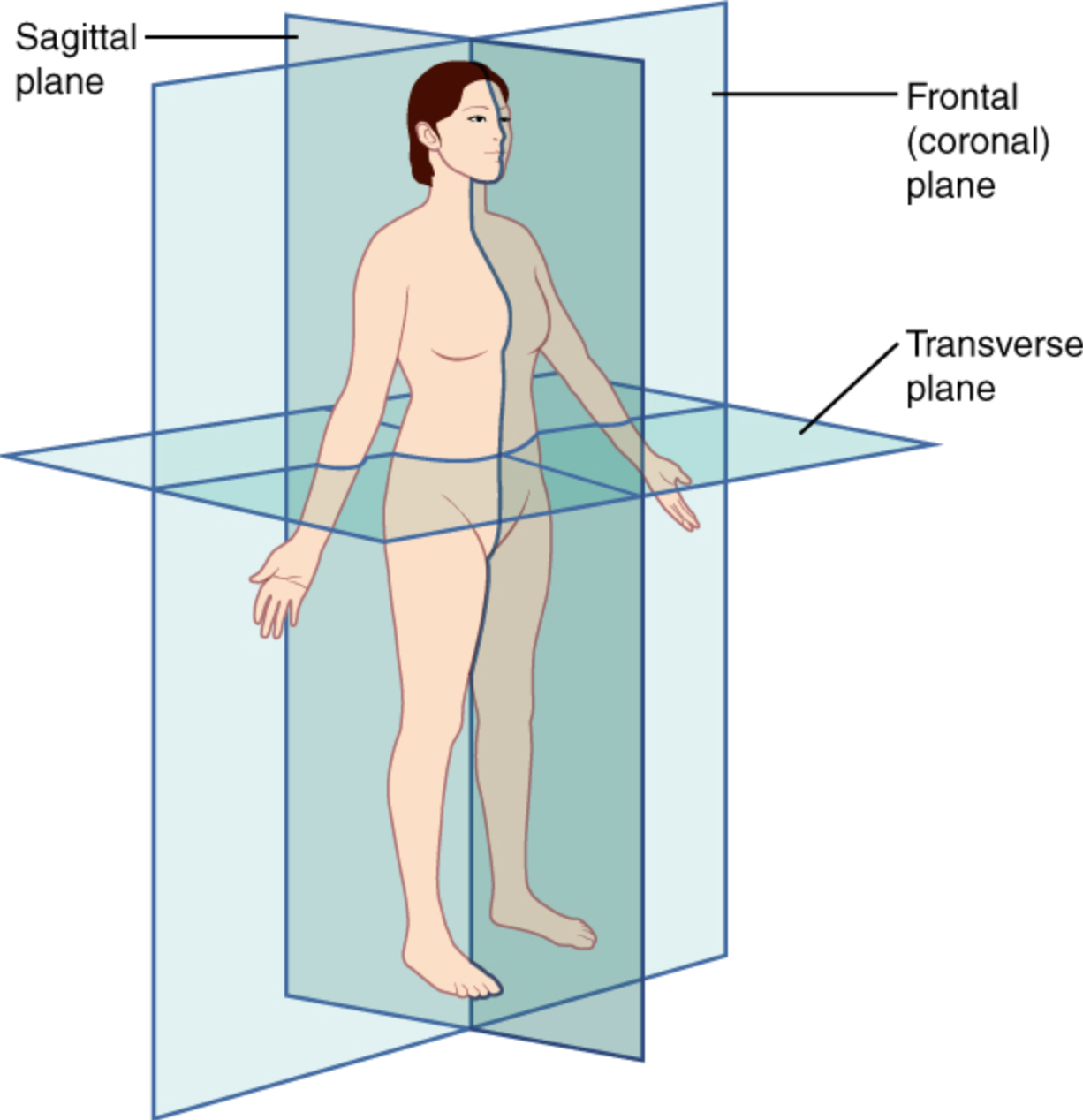
-
해부학적 위치를 알고 사진을 본다.
-
-
x-ray는 통과하고 남은 전자기파의 결과여서 흑백 명암으로 나타나고,
- 부위에 따라 명암이 다르다.
- 공기 : 검정
- 뼈 : 하얀색
- 근육 및 지방 : 연한 회색
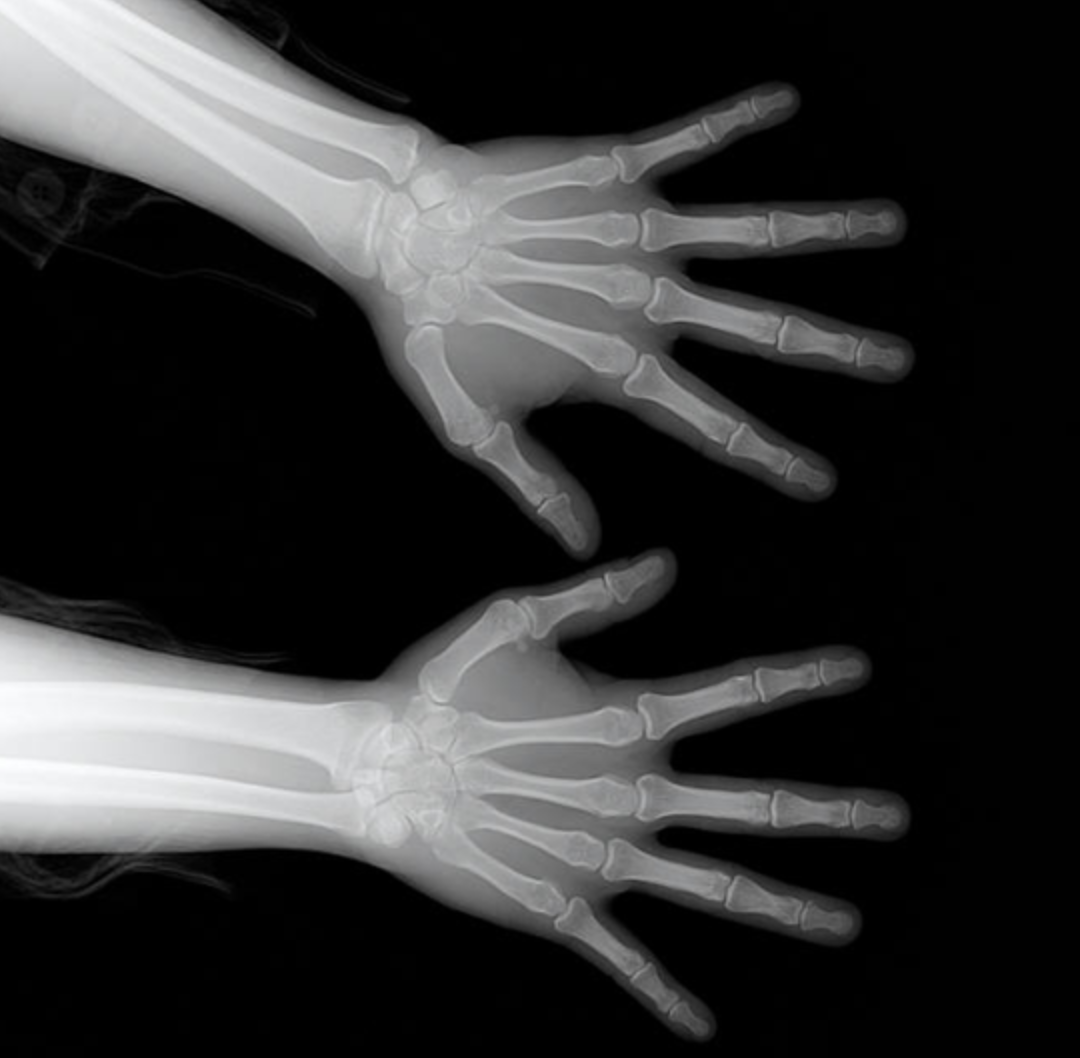 출처
출처
- 부위에 따라 명암이 다르다.
-
미니 배치 사용(SGD과 Full-batch의 중간으로 보자)
- 단점 : 풀배치보다 당연히 최적화된 값이 부정확할 수 있다.
- 장점 : (당연히)속도가 빠르고, 내가 새롭게 알게 된 점은 GPU 기반의 효율적인 병렬 연산이 가능해진단다.
-
tf.data에 대한 공부가 좀 필요한 듯하다.
- tf.data.experimental은 모듈이란다.
- tf.data.experimental.AUTOTUNE
- (https://www.tensorflow.org/guide/data) -> 이 링크 튜토리얼 해보자!
- tf.data.experimental.cardinality
- https://www.tensorflow.org/api_docs/python/tf/data/experimental/cardinality
- 데이터(그룹) 내 요소의 갯수를 반환한단다.
- 희한한 게
tf.data.Dataset.range(42)의 cardinality하면 42인데, tf.data.Dataset.range(42).repeat()의 cardinality는 무한대이고, 이건(cardinality == tf.data.experimental.INFINITE_CARDINALITY같은 걸 통해 확인할 수 있단다.
-
math.ceil()- Round a number upward to its nearest integer
math.ceil(1.4) >>> 2
-
BatchNormalization은 Dropout과 같이 regulirazation(규제)의 기법이다.
-
클래스의 불균형일 경우
- weight balancing이라는 기법을 쓸 수 있다.
- training에서 데이터마다 loss 값 계산 시 이는 특정 클래스의 Loss를 증가되도록 가중치를 부여하는 방법
keras.model.fit()에서class_weight파라미터로 조정 가능
-
with tf.device('/GPU:0'):를 통해 GPU 사용을 잠시동안만 할 수 있게끔 해줄 수 있나보다. -
steps_per_epoch파라미터는- steps_per_epoch: Integer. Total number of steps (batches of samples) to yield from generator before declaring one epoch finished and starting the next epoch. It should typically be equal to ceil(num_samples / batch_size).
- 이런 기본적인 걸 뭐하러 세팅하나 싶었지만,
- 링크를 보면 요긴하게 쓰일 경우가 있다.
- 뭔가 trick을 주어서 1 epoch가 finish하기 전에 그와 비슷한(?) 효과를 주기 위해서...?
- 궁금하면 링크를 보자...
-
keras 모델링 시
padding='same'은 뭘까?padding='valid'도 있는데 그건 padding을 안 한다는 것이고(even하지 않으면 그냥 그 컬럼 drop)same은 zero-padding을 추가하고, even하지 않으면 오른쪽에 더 추가해서 same하게 만든단다.
-
keras.layers.SeparableConv2D가 나온다.- 이는 더 공부해야겠지만, traditional Conv2D와 다르게 작동한다.
- 이번에 Semantic Segmentation할 때 나온 개념이다.
미니프로젝트
x-ray 사진으로 폐렴 진단하는 딥러닝 모델 개발!
- 데이터 파악
- x-ray 사용 예정
- x-ray 사진의 분류
- 데이터 나누기
- 음성/양성의 비율 확인
- 이 때 CNN 모델의 경우 클래스별 balance가 좋을수록 training이 잘 됨
- 반면에 test와 val 데이터셋은 평가를 위한 것이니 학습과 관련이 없고, imbalance해도 상관 없음.(맞나...?)
- 여튼, 실습 시에는 train 데이터 내 클래스별 비율을 확인했고,
- 이를 토대로 이와 나름 반비례하게 적용되는 class_weigthts를 각각 클래스와 가중치가 연결되게
딕셔너리형태로 만들었다.(이는 추후model.fit()에 파라미터로 넣어주면 됨
- 데이터 전처리
- 음성/양성 라벨 넣기
- 이미지 사이즈 규격화(함수 제작 후 사용)
- 데이터 타입 변경
- 잘 됐는지 시각화로 확인
- 모델 설계
conv_block()함수로 CNN 만들고dense_block()함수로 FCN 부분 만들기- 이 때
BatchNormalization,Dropout을 통해 규제도 넣었는데, 이것은 선택사항
- 모델 훈련 및 시각화
- 모델 평가 및 개선
- 개선할 때는 data augmentation을 고려한다.
- 그런데 의료 데이터의 augmentation은 신중해야 한다.
- 미묘한 노이즈 추가가 오히려 방해가 될 수도 있다.
- 개선할 때는 data augmentation을 고려한다.
{kind=link}
헤맨 부분
-
데이터 가져오기
tensorflow에서 이미지를 가져 올 때는tf.io.read_file(path)로 가져온다.- 이 때 저렇게 넣어줄 path 모음은
tf.data.Dataset.list_files(TRAIN_PATH)해서 가져오면 뭔가 이상하다.- 이유는 반환 값이
<ShuffleDataset shapes: (), types: tf.string>인데, 이거를take(1)하면, tf.Tensor(b'/aiffel/aiffel/chest_xray/data/train/NORMAL/NORMAL2-IM-0812-0001.jpeg', shape=(), dtype=string)이렇게 뜰 뿐이다.- 결과적으로 저 string을 파일 경로로 쓰려니까 뭔가 어렵다.
Attempt to convert a value (<ShuffleDataset shapes: (), types: tf.string>) with an unsupported type (<class 'tensorflow.python.data.ops.dataset_ops.ShuffleDataset'>) to a Tensor.오류가 난다.- 제대로된 string 경로로 가져오려면
tf.io.gfile.glob(path)로 가져오면 된다.- 이러면
리스트형식으로 경로들을 긁어온다.
-
그냥 전반적으로
tf.dataset의 구조와 그것을 내가 원하는 방식으로 이끌어내는 방법에 대해서 많이 헤맸다... -
오늘의 핵심 포인트는
tf.dataset좀 다뤄보기...(개인적으로)- weight imbalance 해결해보기
더 공부할 것
- `tf.data.Dataset``
tf.data.experimentalmoduletf.keras.layers.BatchNormalization()- 딥러닝 클래스 불균형 다루기
- weight_balancing을 하면 trade-off가 생길까...?
- 원래대로 했을 때 클래스별 예측도에서 데이터 내 너무 많은 클래스의 정확도가 높았다면, weight_balancing을 하면 그 클래스의 정확도는 낮아지는 걸까...?
tf.iomodulekeras.layers.SeparableConv2D

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다