오늘의 학습 리스트
모델에 대해서 알아보자!
- LeNet
- 사실 오늘 아이펠 노드에는 안 나온다.
- 그렇지만 CNN의 조상격이라고 해서 한 번 관련 블로그를 보았고, 구조를 이해했다.
- 레이어마다 훈련되는 파라미터의 개수 산출을 통해 레이어가 어떤 수학적 역할을 하는지 이해하였다.
- AlexNet
- 2012년도 우승 모델
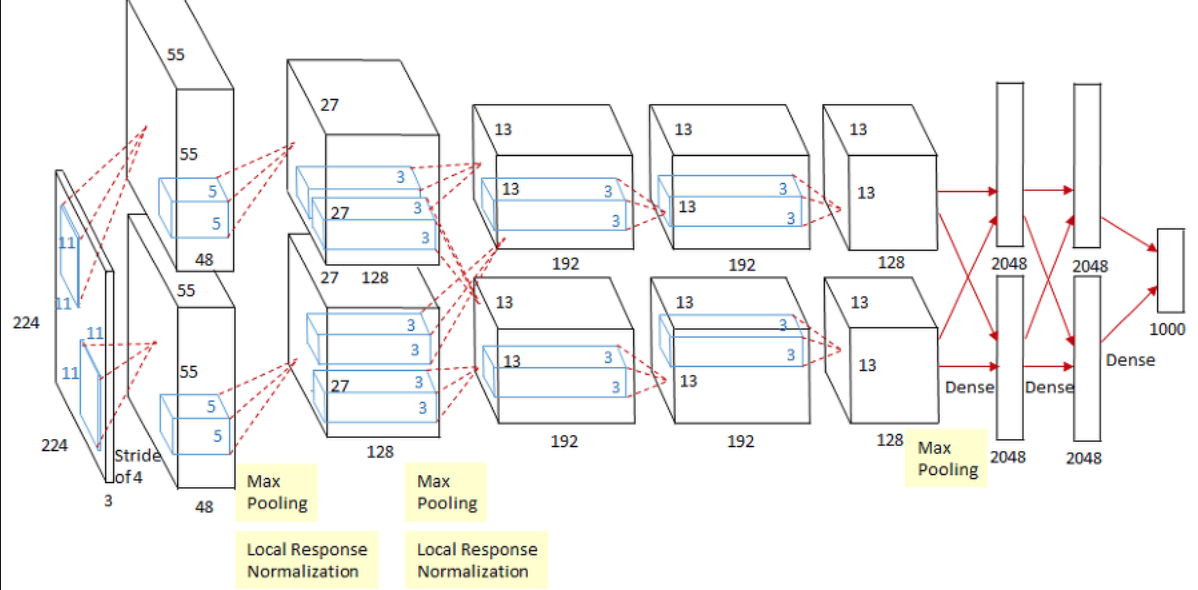
- 이 때 ReLU 활성화함수가 본격적으로 사용됐다고 한다.
- 이전 LeNet-5에서는 Tanh 함수였음
- 그런데 ReLU가 속도가 훨씬 빨랐단다.(물론 다른 장점도 있다.)
- 또한 FCN에서 Dropout을 사용하였다.
- 또한 LeNet-5에서는 Average Pooling이었으나, MaxPooling을 사용했고, 커널사이즈보다 stride가 작은 overlapping-pooling을 사용하였다.
- local response normalization이 사용됐다.
- 현재는 많이 사용하지 않는단다.
- 사용 원리를 설명하자면,
- ReLU는 특성상 양수가 출력값으로 나오고, 이 값이 너무 크면 그게 주변 뉴런에 영향을 크게 미치는데,
- 이것 때문에 영향을 미칠 주변의 다른 출력값들이 억제된단다.
- 그래서 수학적으로는,
- Activation Map에서 같은 위치에 있는 값끼리 정규화를 해준단다.
- VGG
- 2014년도 준우승 모델
- 목적은 '네트워크의 깊이가 성능에 어떤 영향을 미치는지' 확인하고 싶었단다.
- Convolutional Layer 커널 사이즈를 3x3으로 고정했고, 이를 통해 여러 효과를 보았다.
- 파라미터 수가 적어짐
- 7x7 이미지를 3x3으로 stride 1에 두 번 convolve하면 3x3 사이즈가 나온다.
- 7x7 이미지를 5x5으로 stride 1에 한 번 convolve하면 3x3 사이즈가 나온다.
- 하지만 훈련에 필요한 파라미터 개수는 전자가 더 적다.
- 그러면 연산량은 증가하는 게 아닐까?
- 그런데 논문에서는 별로 그렇지 않단다.
- 이러면 층이 많아질 수 있어서 비선형성이 증가하고 추출되는 특성이 더 풍부해짐
- 파라미터 수가 적어짐
- GoogLeNet
- 2014년도 우승 모델
- 중간에 Inception 모듈이라는 것들이 9개가 끼어있다.
- 개념적으로 기존의 CNN 모델과 달리 하나하나 activation map에 대해 다른 사이즈로 convolution 등을 한 것이다.
- 기존이 헷갈린다면... 기존에는 모든 activation map이 같은 사이즈로 쌓였다.
- 1x1 convolutional layer를 쓴다.
- 이는 특성맵의 갯수를 줄여주고,
- 약간
차원 축소스럽게 데이터를 변환해준다.
-> 장점은 이만큼 연산량도 줄어든다.
Flatten대신에Global Average Pooling을 썼다.Flatten은 (5*5*14)면 세 수를 다 곱한 (1, 1, 350)의 벡터를 만들어 내는데,GAP는 (5, 5)에서 평균을 구하고, 그 스칼라 값을 14개 넣는다.- 즉 (1, 1, 14)의 벡터를 만들어 낸다.
- 이외에 Auxiliary Classifier를 통해 vanishing gradient 문제를 해결하려 했다.
- 망 중간 중간에 AC를 놔둬서(훈련 때만 작동) 거기서 가중치가 vanish하지 않게 미리미리 조정..?
- ResNet
- 2015년도 우승 모델
shortcut혹은skip connection을 가진 게 특징- 요약하면, '더 깊어질수록 성능이 좋아지다가 안좋아지는 상황을 개선할 순 없을까?'에서 출발함.(test도 아니고 training error가 특정 시점부터 안 좋아지는 이유는 vanishing gradient)
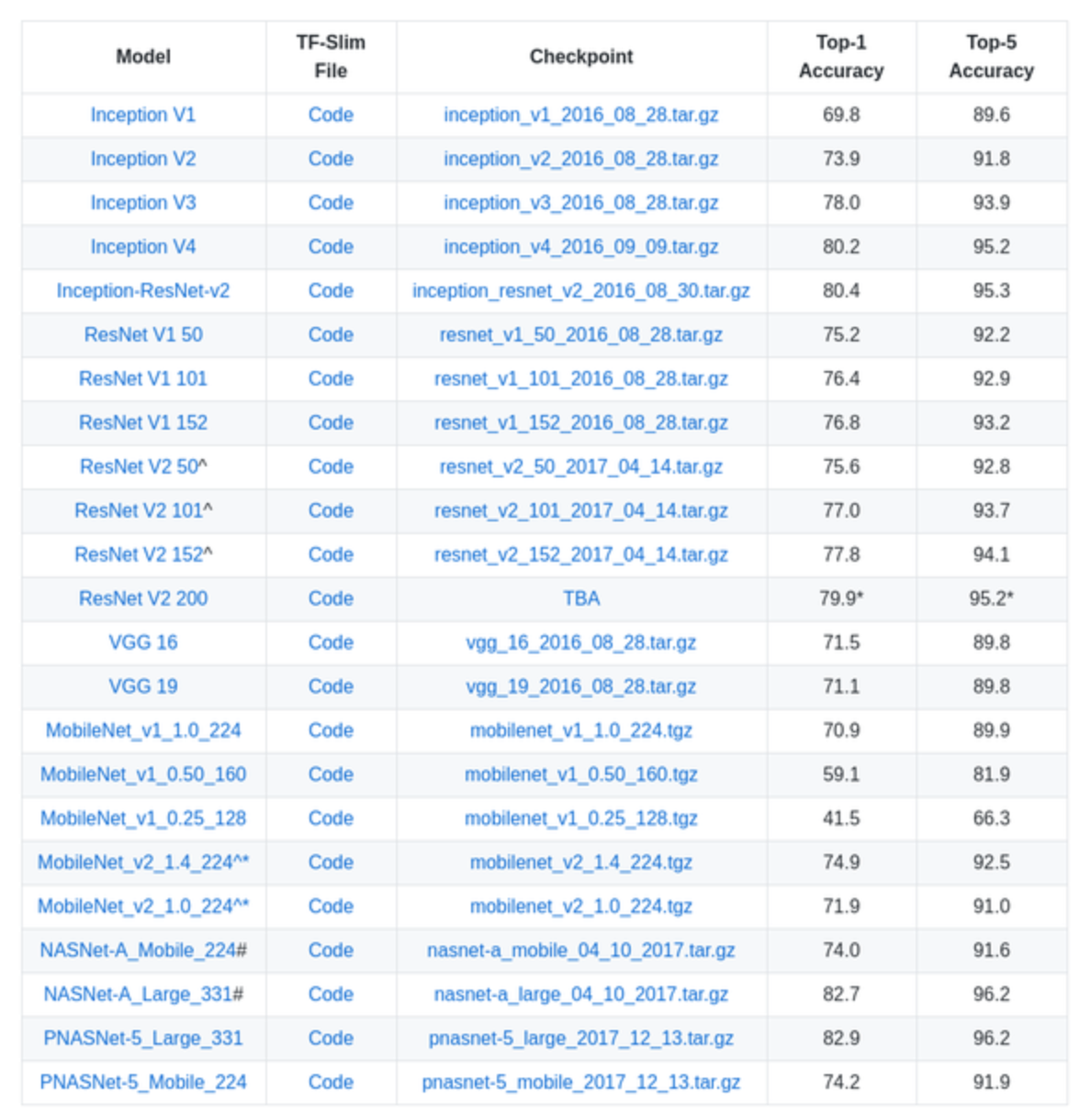
- 모델별
연산량/파라미터 수- 은근 헷갈리는데 둘이 다른 것 같다.
- 이번 실습시 제공된 자료를 통해 AI모델들이 실제로 어떻게 python code로 작성되고, 어디에 보관되는지 등을 알 수 있었다.
- 이렇게 실제 이용 환경을 알아간다는 게 너무 흥미롭고 재미있다.
- 예 : VGG-16 keras code 링크
- 다음에는 이런 모델들의 배포(?) 혹은 사용 방법 등에 대해 알아보면 흥미로울 것 같다.
더 공부할 것
- ResNet의 skip connection 무슨 원리인지 모르겠다... 뭔가 목적 함수를 바꾸니 마니 하는데... 그거랑 vanishing gradient랑 어떻게 연결되는 거고...

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다