오늘의 학습 리스트
-
활성화 함수의 목적 : 표현력 증가
- 표현력은 무엇일까...?
-
세포체도 입력 신호들의 합이 일정치 이상이면 활성화시키고, 아니면 그 신호를 무시한단다.
-
선형(Linearity)
- 가산성(additivity)
- 동차성(homogeneity)
- 두 개를 이용해서 어떤 식이 주어진 조건에 따라 두 특성을 만족하면 선형이라고 볼 수 있다.
-
선형 함수 여러 개를 연결 시켰을 때 선형이 되는지를 위의 조건들을 통해서 증명할 수 있단다.
- 이렇게 되면 각 층마다 가중치들이 각각 있어도 그 중 하나만 업데이트 잘 시킨 거랑 값이 똑같단다.(이 이유는 가 스칼라라는 전제란다)
-
선형 함수를 여러 개 합성시키면 그 함수도 선형이다.
-
위의 표현력 얘기
- 선형 함수는 결국 여러 개 연결시켜도 하나의 선형 함수가 되는데(위의 가산성, 동차성이라는 특성 때문에)
- 이러면 사실 선형적인 특성을 띄는 데이터만 예측할 수 있단다.
- 비선형적인 거는 모양 자체가 다른데 그 모양을 표현하지 못하니까...
-
np.ma.masked_where(condition, condition에 따라 마스크해서 내보낼 같은 shape의 어레이) -
ReLU가 0에서 미분이 안되는 이유
- 우미분, 좌미분
- 이때, 어떤 값 에 대해 함수 의 미분이 존재한다는 것은 그 값에 대한 함수의 우미분과 좌미분값이 같다는 것
- 근데 그게 다르면 그 함수는 그 값에 대해 미분이 불가능하다.
- ReLU는 0에서 딱 그렇다.
- 실제로 ReLU의 gradient를 구할 때 input으로 0이 들어 왔던 상황이면 0 혹은 1이 랜덤으로 주어진다고 한다.
-
ReLU 함수의 단점
- zero-centred가 아니다.
- ReLU를 겪은 인풋의 파라미터들은 gradient의 방향 업데이트가 동일해진다.
- Dying ReLU
- gradient가 0이 되면서 가중치 업데이트가 죽어버리는 노드가 발생할 수 있다.
- zero-centred가 아니다.
# PReLU 함수
def prelu(x, alpha):
return max(alpha*x,x)
# 시각화
ax = plot_and_visulize(img_path, lambda x: prelu(x, 0.1)) # parameter alpha=0.1일 때
ax.show()
- 윗 코드를 보면 엄청 헷갈린다...
- 원래는 prelu만 쓰면 되지만,
alpha라는 파라미터를 지정해줘야 하고, - 그러다 보면(
prelu=(alpha=0.01)같이 쓰면) x 파라미터도 missing이라고 뜬다. - 그래서 그것 때문에 x를 넣어주는 함수를 만들어서 합성함수 같이 만든 것 같다...
- 즉, f(prelu(x, alpha))... 맞나...?
- 원래는 prelu만 쓰면 되지만,
오늘의 코드
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def plot_and_visulize(image_url, function, derivative=False):
X = [-10 + x/100 for x in range(2000)]
y = [function(y) for y in X]
plt.figure(figsize=(12,12))
# 함수 그래프
plt.subplot(3,2,1)
plt.title('function')
plt.plot(X,y)
# 함수의 미분 그래프
plt.subplot(3,2,2)
plt.title('derivative')
if derivative:
dev_y = [derivative(y) for y in X]
plt.plot(X,dev_y)
# 무작위 샘플들 분포
samples = np.random.rand(1000)
samples -= np.mean(samples)
plt.subplot(3,2,3)
plt.title('samples')
plt.hist(samples,100)
# 활성화 함수를 통과한 샘플들 분포
act_values = [function(y) for y in samples]
plt.subplot(3,2,4)
plt.title('activation values')
plt.hist(act_values,100)
# 원본 이미지
image = np.array(Image.open(image_url), dtype=np.float64)[:,:,0]/255. # 구분을 위해 gray-scale해서 확인
image -= np.median(image)
plt.subplot(3,2,5)
plt.title('origin image')
plt.imshow(image, cmap='gray')
# 활성화 함수를 통과한 이미지
activation_image = np.zeros(image.shape)
h, w = image.shape
for i in range(w):
for j in range(h):
activation_image[j][i] += function(image[j][i])
plt.subplot(3,2,6)
plt.title('activation results')
plt.imshow(activation_image, cmap='gray')
return plt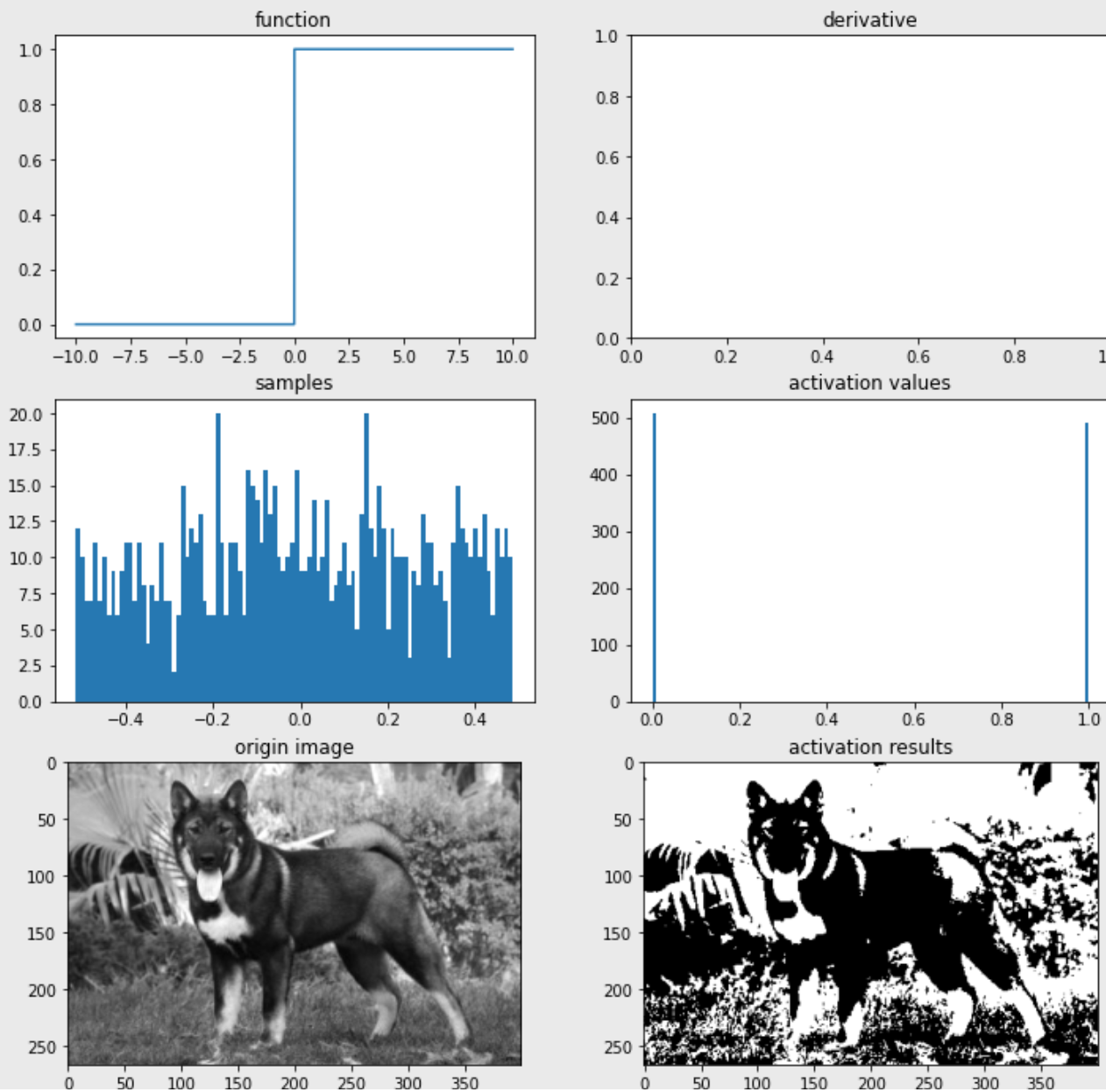
- 몰랐는데
plt.figure()로 만들고서 변수명을 할당 안 했다 했을 때return에plt만 써도 그 객체가 pointing 되나보다. np.random.normal은 그냥 정규분포이고,np.random.randn을 표준정규분포에서 난수 추출인 것 같다.
Deep ML
-
Dropout의 test phase
- 아직도 잘 헷갈리지만, 여튼 요약한 문장으로는
- "hence, to get the same output in the testing as the expected output of the training, we can scale the weights of each neuron in testing phase by p. This method is called weight scaling inference"
- weight에 p(keeping unit)을 각각 곱해준단다.
-
transfer learning
- 벌써 가중치가 많이 학습되어 있으니, learning rate 작게 해도 됨(훈련할 경우)
오늘 cs231n lecture 7의 optimization 부분의 발표자로 뽑혔었다. 덕분에 optimizer들 중 momentum(방향)과 AdaGrad(divide learning rate(보폭) by gradient accumulation) 계열에 대해 좀 더 깊게 알 수 있어서 좋았다.
헷갈린다면 발표 자료에서 찾아보자. 비공개여서 나만을 위한 링크

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다