오늘의 학습 리스트
- 챗봇의 역사...
- 알고보니 다 인공지능은 아니다.
- 트리형은 그냥 경우의 수에 맞게 답변을 달아놓은 것 뿐
- 인코더 <-> 디코더 모델
- 생각해 보니 그냥 RNN도 번역이 되는데 왜 인코더/디코더 구조가 아닐까?
- RNN으로 다음 단어를 예측하면서 문장 만들기
- 즉, RNN이 디코더일 때로 보면 됨
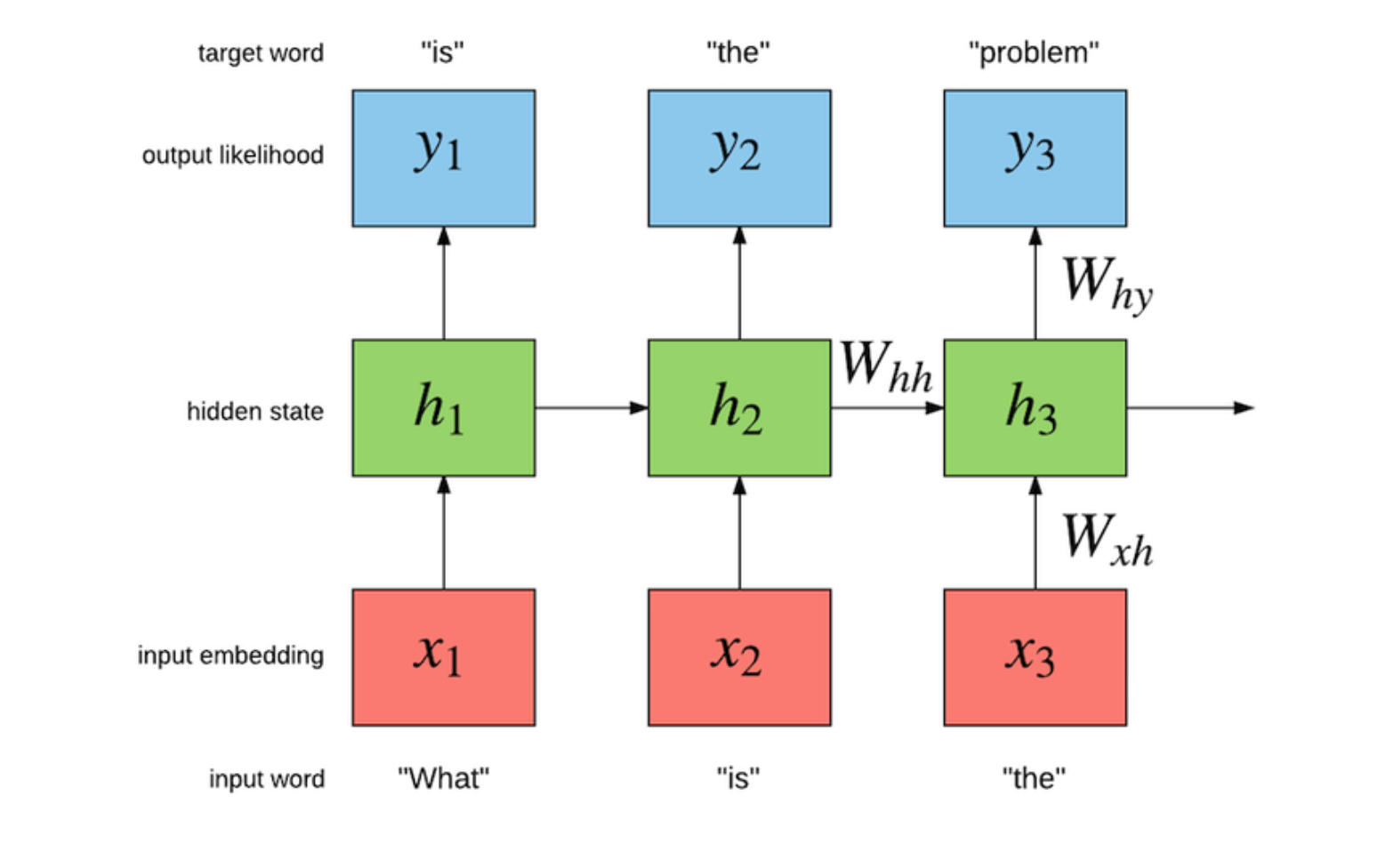
- RNN은 구조상 자신보다 앞에 있는 단어들만 참고해서 예측함
- 결론짓자면, 인코더 디코더는 보다 효율적인 번역 등의 작업, 즉 문맥 정보 같은 걸 최대화 하고자 한 것 같다.
- 인코더의 최종 결과로 나온 context vector를 갖고 디코더가 작업하는 건데, 그냥 RNN은 그런 최종으로 나온 context vector를 사용하는 게 아니니까
assert- debugging을 위해 사용된단다.
- 뭔가 condition으로 주어지는 게
False이면 AttentionError가 생긴단다.
x = "hello"
#if condition returns True, then nothing happens:
assert x == "hello"
#if condition returns False, AssertionError is raised:
assert x == "goodbye"
- LayerNormalization
- 이건 BN과 좀 다르다.
- 일단 개념적으로는 배치마다 하는 게 아니라 레이어에 대해(어찌 보면 activation map에 대해) 해준다는 것 같은데
- https://www.tensorflow.org/api_docs/python/tf/keras/layers/LayerNormalization
-
어텐션(attention) 도대체 어떤 메커니즘일까...? 아직도 헷갈린다. 오늘은 그것을 좀 더 파헤쳐봐야겠다.
- 기본적으로 디코더에서 예측하는 매 시점마다 인코더의 전체 문장을 확인한다.
- 근데 전체 문장을 동일한 비율로 보는 게 아니라 해당 time step과 연관 있는 단어 부분을 attention 해서 본다는 뜻
- 이게 어떻게 수학적으로 가능할까...?를 보면(꽤나 복잡한데..)
- 일단 어텐션 스코어를 구한다.
- 어텐션 스코어는 어떻게 구하냐?(방법마다 다르지만...)
- 디코더의 현재 스텝 t의 은닉층 값과
- 인코더의 모든 스텝에 대한 은닉층 값을 내적한다.(차원이 같다는 전제 + 디코더의 현재 스텝 t의 은닉층 값을 전치해서)
- 그러면 각각의 스텝마다 은닉층 값과 구한 어텐션 스코어(스칼라값)가 나오는데
- 직관적으로는 각각의 스텝 은닉층과 얼마나 유사한지 보여주는 값이라고 할 수 있다.
- 여튼 이 값의 모음을 softmax에 넣어서 전체에 대한 확률로 뽑아낸 attention distribution을 구한다.
- 그리고 이 attention distribution의 값들은(0 ~ 1 사이) 가중치(attention weight)로서 역할을 하게 되는데
- 이것을 다시 인코더 모든 time step마다의 은닉층과 곱해서 최종적으로 다 더한다.(즉 Weighted sum)을 만든다.
- 그리고 이것은 문맥을 포함하는 정보라고 하여서 context vector라고 부른단다.
- 그리고 이 context vector를 현재 디코더의 은닉층 벡터와 concatenate한단다.
- 논문에서는 여기서 또 다른 레이어를 지나서 비슷한 최종 벡터가 나오게끔 한다는데(그리고 또 weighted sum도 있는 것 같다)
- 결론은 이렇게 나온 벡터를 softmax에 집어넣으면 최종 예측 벡터가 나온단다.
- 근데 모든 인코더의 은닉층과 계산해서 더 큰 값이 나오는 것을 예측 단어로 뽑아낸다는 직관적인 이해는 가는데
- 도대체 어디서 수학적으로 그런 게 가능해지는지는 모르겠다...(그냥 Weighted sum만 하면 되는 건가...?)
- 이렇게 구한 어텐션 값을 디코더의 이전 출력 단어와 이전 은닉 상태에 다같이 더한다.
-
케라스에서 모델 설계 시 여러 개의 인풋이 있는데 그 중 몇 개가 모델 중간에 들어가는 거라면(예: 인풋의 아웃풋을 디코더 모델 중간에 넣을 때)
- 이렇게 넣는 인풋도
tf.kears.Input()을 통해 들어가서Input()의 아웃풋으로 반환되게끔 해줘야 하는 것 같다. - 그 후에 모델 중간에 사용할 수 있는 것 같다.
- 이렇게 넣는 인풋도
-
tf.data.DatasetAPI는 훈련 프로세스의 속도가 빨라지도록 입력 파이프라인을 구축하는 API -
Teacher Forcing(교사 강요)
- 테스트할 때말고, 훈련할 때 필요한 것 같은데
- 현 시점 단어 인풋에 따른 다음 단어 예측을 아웃풋으로 내는 모델일 때
- 훈련할 때는 이 모델이 아직은 멍청하게 예측을 내뱉을 수 있으니
- 현 시점 단어 인풋이 들어오면 실제 라벨이 아웃풋으로 오게끔 해서
- 훈련이 빠르게 진행되도록 한다.
-
RNN에서 이렇게 이전 시점 아웃풋이 현 시점 인풋이 되는 것도 어떻게 보면 시계열 데이터에서 쓰이는 auto-regressive 모델(AR모델)이다.
미니프로젝트
- 음... 어떻게 진행하는지 대략적으로 요약해보고 싶지만 오늘도 벌써 시간이 다 되어서 이만 pass...
- 대신 몰랐는데, 이번 노드와 거의 동일한 내용을 가진 wikidocs 책이 있다.(https://wikidocs.net/31379) <- 이거 보면서 하면 정리 잘 될듯

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다