오늘의 학습 리스트
LMS
- 데이터 전처리.(어떤 데이터가 왔을 때 나도 이런 것을 먼저 생각할 수 있도록 머릿속에 심어보자)
- Missing data
# 컬럼별 결측치 갯수 확인하기
len(df) - df.count() # df.count()는 시리즈로 컬럼별 데이터 갯수 가져 옴
>>> Series 형태로 컬럼별 결측치 갯수 나옴-
Outliers
- 이상치를 제거하냐 마냐는 '데이터의 갯수'에 따라...
- 너무 적으면 이상치를 제거하지 않고 대체하는 게 좋단다.
- z-score : (값-평균) / 표준편차 -> 이 값이 특정 수준 이상이면 이상치로 판단
- z-score는 근데 한계점이 있다(평균, 분산이 들어가서 값 그 자체로 outlier의 영향을 받는...읔)
- IQR method(median을 중심으로 양쪽 25% percentile들 값의 차이값(75% 위치 값 - 25% 위치 값)
-np.percentile(array-like(데이터), float or array-like(몇분위))하면 ndarray로 반환됨
-
Duplicates
df.duplicated()
=> 중복된 row가 있는지 bool 값의 series로 반환df.drop_duplicates()하면 중복 row 없어짐
-
Normalization
- 컬럼별 값들 간에 차이가 클 때(이럴 때 clustering 같은 거 해서 데이터 간 거리를 재면 데이터 값이 큰거의 영향을 많이 받게 됨)- Linear Regression에서도 모델의 파라미터 업데이트 시 범위가 큰 컬럼의 파라미터만 집중적으로 업데이트함
- min-max scaling
- standardization
# 데이터 x를 Standardization 기법으로 정규화합니다. x_standardization = (x - x.mean())/x.std() x_standardization- min-max scaling은 모든 값으 0~1 사이로 만들어서 standardization 보다 분산이 좁다
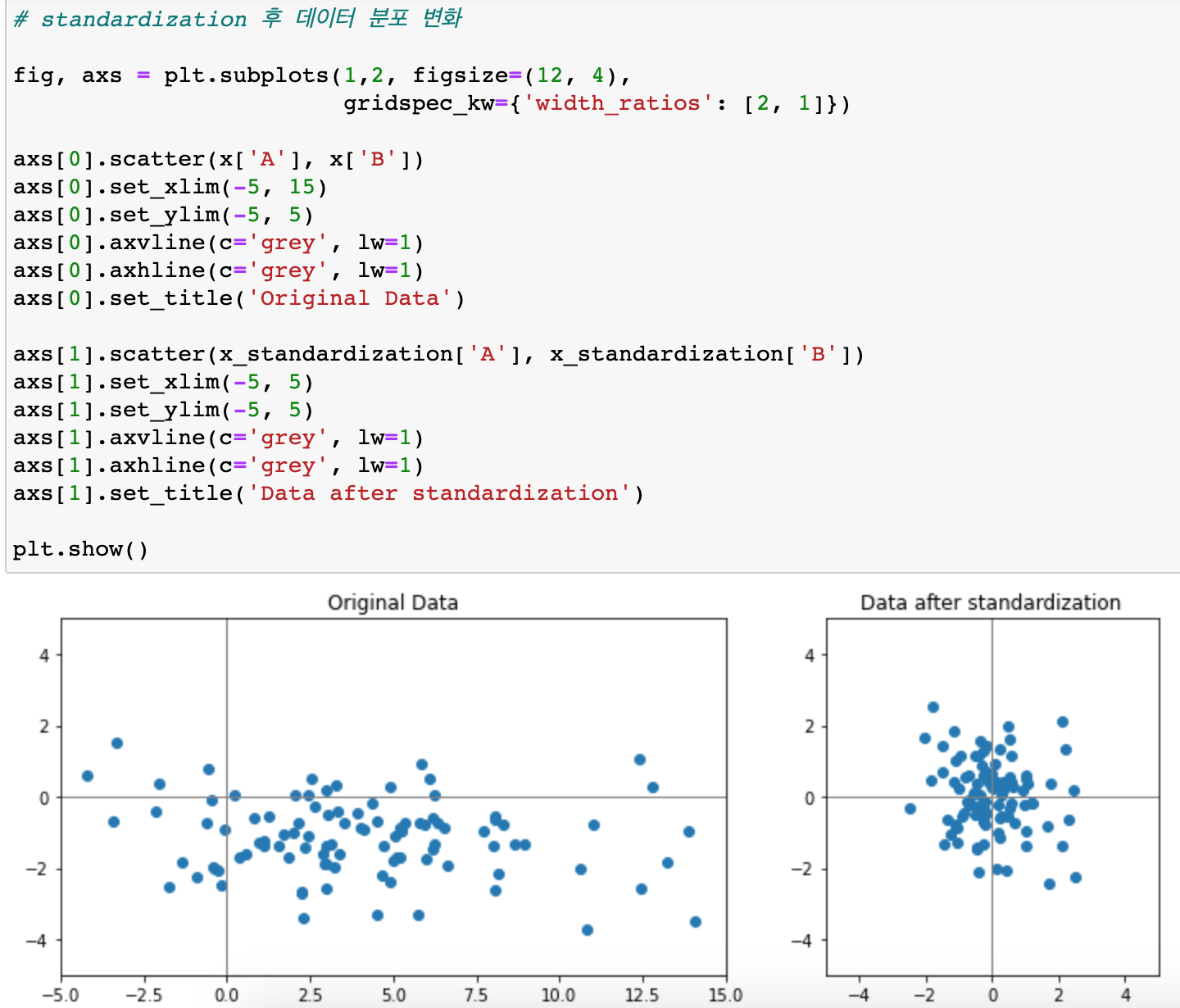
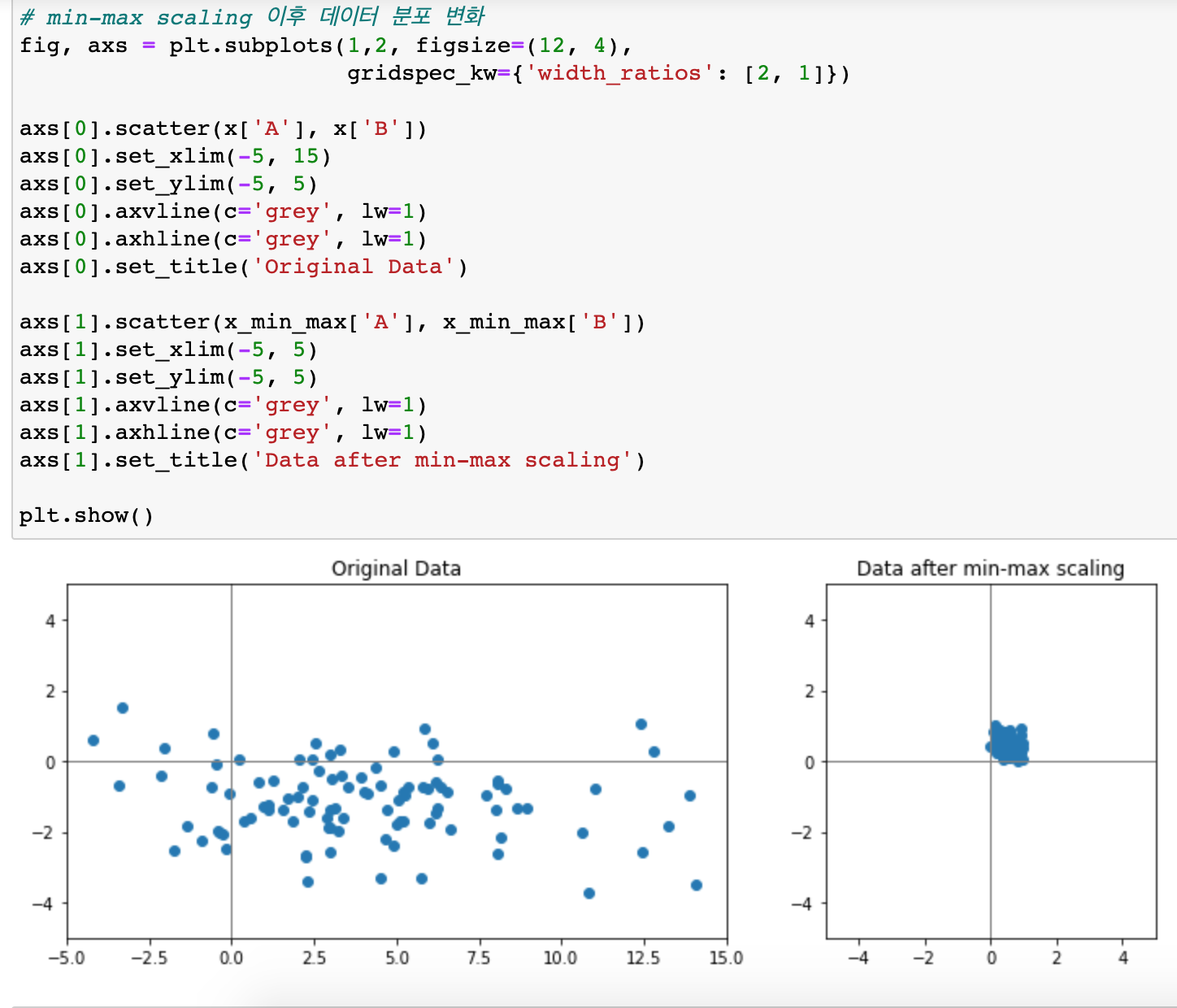
- Normalization은 왜 하냐...?
=> 컬럼별 격차가 큰데 안 했을 경우... weight 업데이트할 때 gradient-descent할 등고선 모양이 좁고 길게 되는데, 이 경우 straight하게 빠르게 못 간다(모델의 학습이 어려워지고 느려진다). - one-hot encoding
- binning(이건 좀 생소하다)
- 이걸 어떻게 내가 생각할 수 있을지 순차적으로 정리하자.
1) 연속적인 숫자의 데이터가 있다.
2) 이것을 구간별로 나눠서 좀 분류하고 싶다
3) 히스토그램으로 보면 좋을 것 같다.(pd.Series.hist()가 좋을 듯)
4) 근데 보니까 구획이 엉망이다
5)bins파라미터에 들어갈 구간list를 만들어서pd.Series.hist(bins=)의 argument로 넣어주자 pd.cut은 세팅된 구간을 기준으로 나누고,pd.qcut균등한 분포를 기준으로 나눈다.
- 이걸 어떻게 내가 생각할 수 있을지 순차적으로 정리하자.
- Pandas의
boolean indexing의 원리를 알아냈다
=> boolean Series의 인덱스와 indexed object의 인덱스가 match 되어야 한단다. series(숫자형)-seiries(숫자형)orseries(숫자형)-scalar하면series로 반환된다(값 하나하나 for loop으로 꺼내지 않아도 되는 편리함...)DataFrame(+,-,*,/)DataFrame도 되나 보다...(position-wise로 사칙연산 함)
풀잎스쿨
- 클래스
isinstance(객체명, 클래스명)=> bool 값 반환--이렇게 붙은 method는 파이썬이 자동으로 호출해주는 method인데, special method 혹은 magic method라고 부름__init__
: instance가 생성될 때 자동으로 실행되는 초기화(?) 함수. 이를 통해 해당 instance가 사용할 attribute 등을 설정한다.- attribute와 method
: 둘 다.을 통해 접근할 수 있지만, attribute(속성)는 instance object의 특징 같은 것이고, method는 뭔가 함수 같이 액션을 취하는 것이다
- class, method를 백엔드에서 사용하는 예(패키지로 만든 것)
: 효민님의 `'인사과 사람들이 필요한 정보의 DB화 코드' - 프레임워크 vs 라이브러리 차이
: 프레임워크는 잘 모르지만, 정해진 틀이 있다.
: 라이브러리는 'user is in charge of the flow of the application'. - *args, **kwargs로 attribute의 갯수 및 키워드를 한정 짓지 않고 생성할 수도 있다
class Person:
def __init__(self, *args):
self.name = args[0] # 인덱싱으로 가져오면 됨
self.age = args[1]
self.address = args[2]
maria = Person(*['마리아', 20, '서울시 서초구 반포동'])
class Person:
def __init__(self, **kwargs): # 대신 이때는 key=value 형식으로 써야할 듯
self.name = kwargs['name']
self.age = kwargs['age']
self.address = kwargs['address']
maria1 = Person(name='마리아', age=20, address='서울시 서초구 반포동')
maria2 = Person(**{'name': '마리아', 'age': 20, 'address': '서울시 서초구 반포동'})-
instance 만들고 속성 추가해도 됨(그냥
‘변수명’.’속성명’ = 값으로 할당하면 됨) -
lambda
:(lambda x: len(x))([1,2,3,4]>>> 4 출력됨(x에 리스트 통으로 들어감
:some_list.sort(key=lambda x: len(x), reverse=True)>>> key 파라미터의 특성상 x로 리스트가 주어지면 리스트의 요소가 하나씩 들어가서len(x)가 나온다.
더 공부할 것
- abnomaly detection...(나중에 한번 찾아보자)
질문
- Normalization에서 train / test 데이터에 같은 기준을 적용해서 정규화해야 한다고 한다. min-max scaling은
test - train.min() / train.max() - train.min()을 하는 게 맞는 것을 이해하겠는데, standardization은 어떻게 기준을 똑같이 맞출까...?
=>test - train.mean() / train.std()혹은test - test.mean() / train.std()?
=> 정답은 test 데이터에도 같은 평균과 같은 분산을 사용하란다.
오늘의 코드
# 각각의 row 구하기
t1 = trade[(trade['기간'] == '2015년 04월') & (trade['국가명'] == '미국')]
t2 = trade[(trade['기간'] == '2016년 04월') & (trade['국가명'] == '미국')]
t3 = trade[(trade['기간'] == '2017년 04월') & (trade['국가명'] == '미국')]
t4 = trade[(trade['기간'] == '2018년 04월') & (trade['국가명'] == '미국')]
t5 = trade[(trade['기간'] == '2019년 04월') & (trade['국가명'] == '미국')]
# 합치기
us_df = pd.concat([t1, t2, t3, t4, t5])
# 수출금액 합계 및 평균 구하기
replacement = us_df['수출금액'].sum() / len(us_df)
# 값 할당하기
trade.loc[191, '수출금액'] = replacement
# 확인
print('value to be replaced :', replacement)
trade.loc[[191]]
- 윗 코드에서 기간을 반복문을 쓰거나 해서 구해보고 싶다...

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다