오늘의 학습 리스트
-
K-means
- 분류 기준도 없을 때 그냥 k개로
sklearn.datasets.make_blobs()으로 데이터 생성
-
Eucledian Distance
- 피타고라스 정리를 이용하면 쉽게 알 수 있다.
- 이 거리를 이용하면 n차원의 특징을 갖는 데이터들 간 서로의 유사도도 구해볼 수 있다.
-
display()라는 함수도 있었다.- 기본적으로
object를 display해주는 함수란다.(print()같이) - stackoverflow에서의 설명은... "display is a function in the IPython.display module that runs the appropriate dunder method to get the appropriate data to ... display"
- 보니까 이번에도 중간에
print()역할 같이, 하지만 판다스 df를 출력해주기 위해 쓰였다. - df를
print()로 해보니 그냥 숫자만 정렬된 상태로 출력됐다.
- 기본적으로
-
K-means의 단점(혹은 군집화가 잘 안 되는 데이터 분포)
- k를 미리 정해야 하기 때문에 이에 대한 정보가 없다면 사용하기 어렵다.
- 유클리드 거리를 이용하기 때문에 해당 거리가 멀면서 연관 있는 데이터의 분포는 K-means로 군집되지 않는다.
-
이러한 단점을 극복하게 해준 게 DBSCAN 알고리즘
- Density Based Spatial Clustering of Applications with Noise
- 거리가 아닌 밀도를 기반으로 하고,
- 이는 일정 반경 안의 데이터 갯수를 말함
- k 값을 미리 지정하지 않아도 됨.
- 대신 지정해줘야 하는 파라미터들이 있음
- epsilon(반경)
- minPts(최소 포인트 갯수)
- 이를 토대로 한 점에서 시작해서 그 점의 주변을 봐서 cluster 조건을 만족하는지 보고 되면 cluster로 취급한다.
- 서로 다른 cluster였는데 한 cluster의 포인트가 다른 cluster에 들어간다면 둘을 하나의 cluster로 보고 묶는다
- 이렇게 모든 점들에 대해 판별하고,
- 이래도 안 들어오는 점은 noise로 간주
-
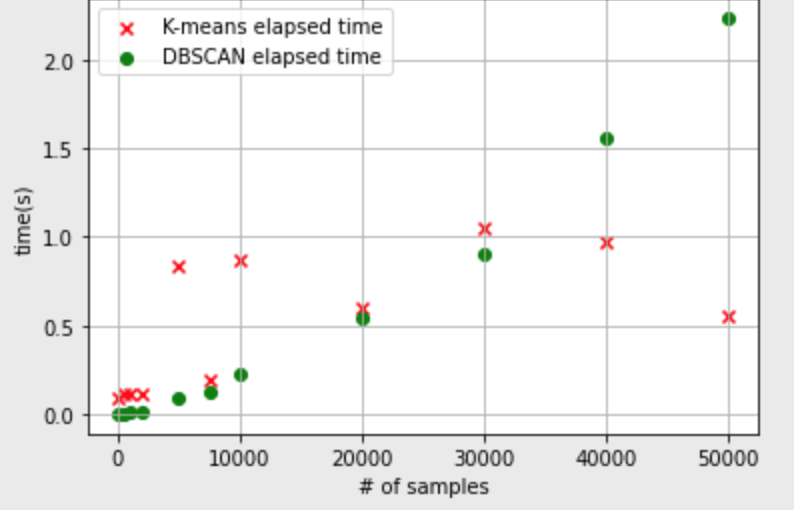
DBSCAN의 단점
- K-means에 비해 데이터 수에 따라 시간이 많이 걸리게 된다.
- 데이터가 적을 때는 K-means가 오래 걸리지만,
- 데이터 수가 누적될 수록 DBSCAN의 시간이 더 오래 걸리게 된다.
-
PCA
- 차원 축소(dimensionality reduction) 방법의 하나
- PCA를 통해 feature들 중 어떤 게 이 데이터를 가장 잘 represent하는 지 파악할 수 있음
- LMS에서는 유방암 데이터로 feature를 30개 -> 2개로 PCA한 결과를 PCA하지 않은 결과와 비교하는데 아래와 같다.
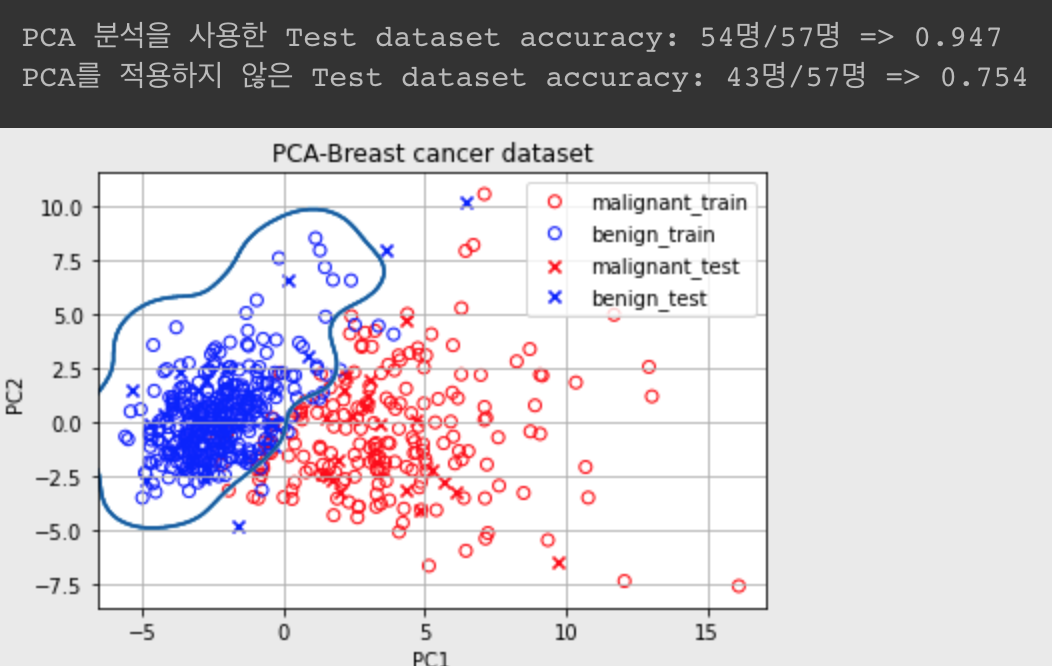
- PCA했을 때 SVM Classifier의 예측률이 더 높은데,
- 이유는 30개의 feature 중 악성/양성의 구분에 오히려 방해되는 feature가 있었기 때문으로 볼 수 있다.
- 그래서 PCA는 각 feature간 상관관계가 있고, 이 수를 줄이고자 할 때 쓰는 비지도학습 방법이다.
-
T-SNE(T-Stochastic Neibour Embedding)
- 시각화할 때 많이 쓰임
- 고차원 -> 저차원 시각화에 PCA면 다 될 것 같지만,
- PCA는 feature들이 선형적인 구조일 때 잘 됨.(이 때 정보 보존이 제일 잘 됨)
- 따라서 차원 축소의 목적에 따라
어떤 정보를 보존할 건데를 고려해야 함. 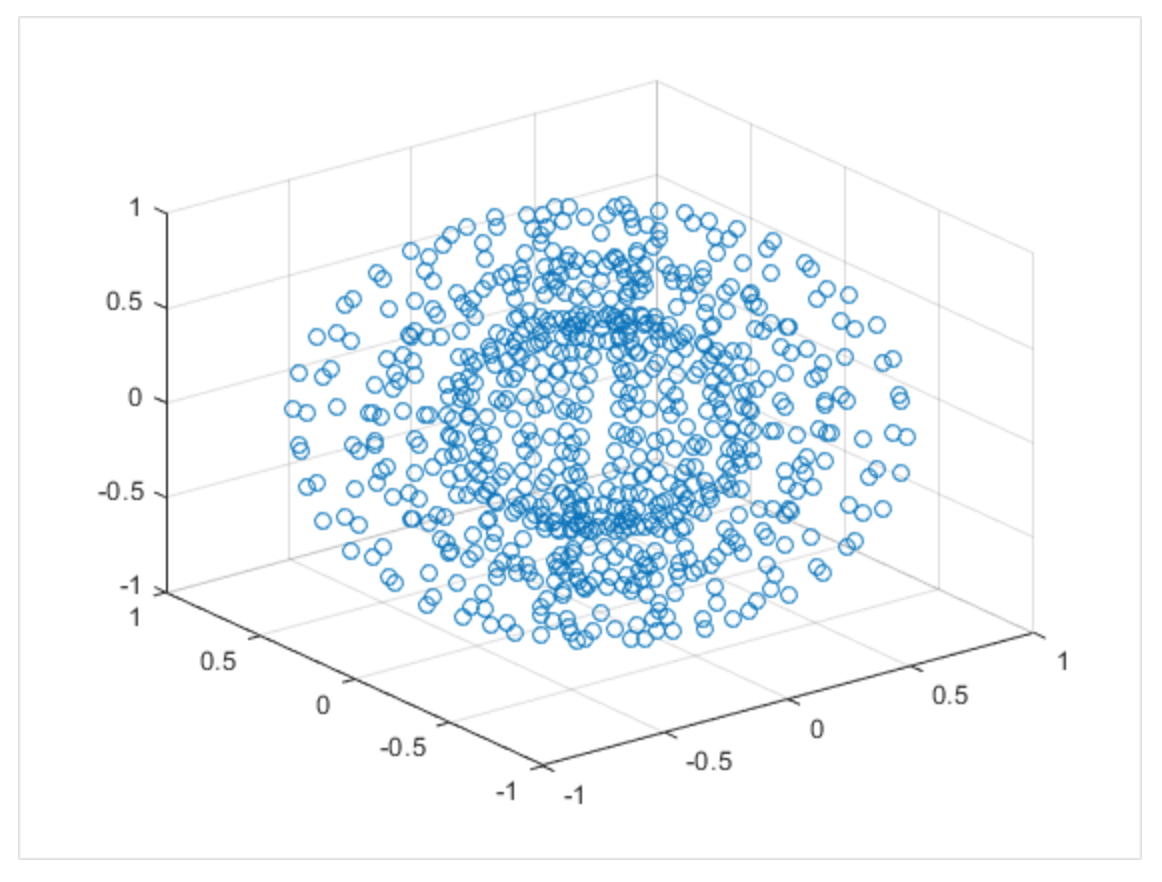
- 위의 그림처럼 비선형일 때는 PCA로 보존이 잘 안 됨.
- 왜냐하면 축으로 삼을 선형적인 직선을 잡기 어렵기 때문에
- 잘 모르지만, 위의 경우 멀리 있는 데이터가 가까이 오게끔 차원 축소가 이루어진다고 함.
- T-SNE는 기존 차원에서 가까이 있던 건 가까이 있게끔 해주는 알고리즘
요약해서 PCA는 데이터가 가진 고유한 물리적 정보를 유지하려 하지만, T-SNE는 데이터 간의 상대적 거리 보존에 중점을 둠
기타 개념
- np.c_
- 처음 봤다... 나중에 정리하자..
- np.r_
- 처음 봤다... 나중에 정리하자..
- keras optimizers 관련한 잘 정리된 글
- keras dropout 관련해서 수학적으로 풀어놓은 글

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다