오늘의 학습 리스트
-
Text summarisation
- 포인트는 정보 손실이 최소화 되어야 한다는 것
- Extractive summarisation(추출적 요약)
- 문장에서 추출(예: 10개 단어 중 3개)
- 이들끼리의 연결은 자연스럽지 않을 수 있음
- TextRank 알고리즘이 이 방법 사용
- 대표 예는 네이버 요약봇
- 원문에 있는 것 중 중요한 것을 골라낸다는 점에서 Text Classification으로 볼 수도 있음
- Abstractive summarisation(추상적 요약)
- Generative 한 모델 사용
- 원문에 있지 않을 수도 있음
-
관련 딥러닝 모델로는
- vanila RNN
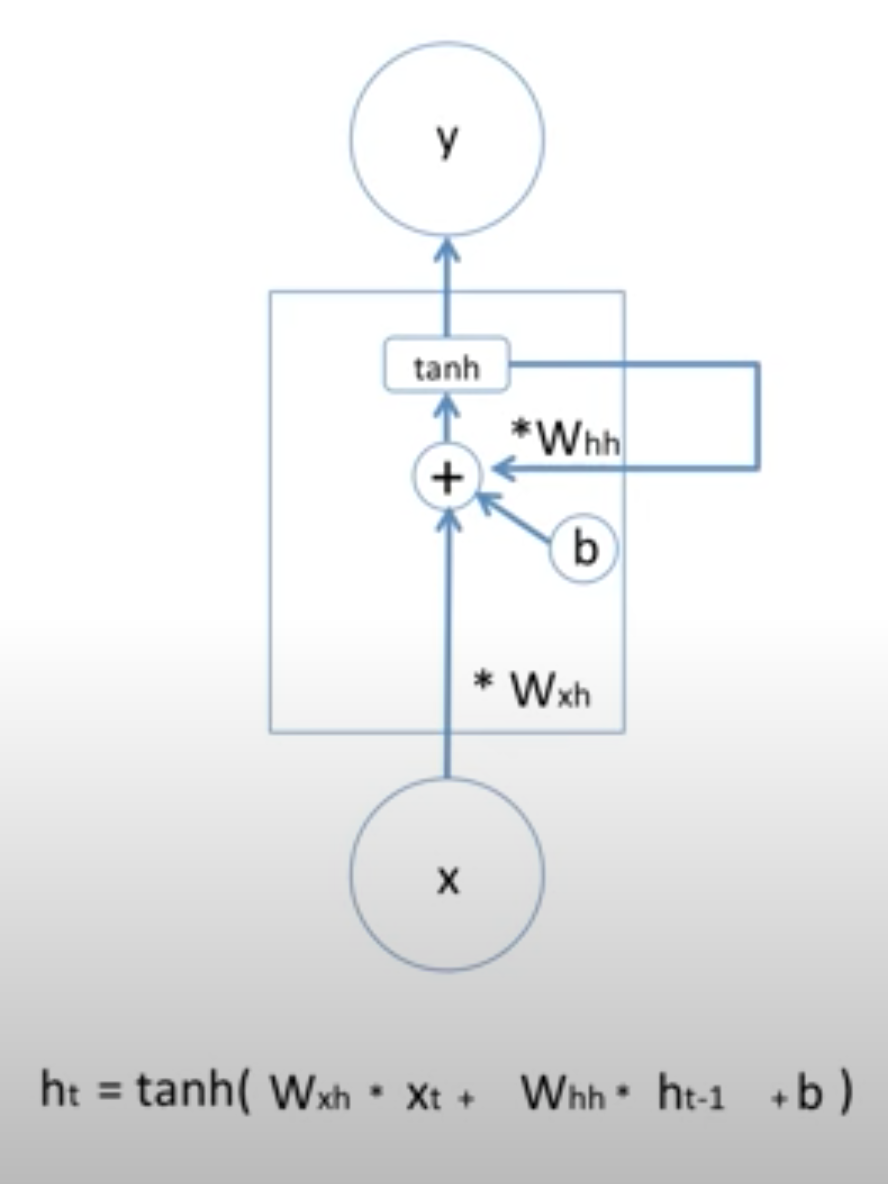
- 이론상으론 적절한 파라미터 조작을 통해 모든 past information을 기억할 수 있어야 하지만, 실제론 그렇지 못했다.
- Vanishing Gradient 문제 때문에(혹은 Exploding)
- 사실 기억하지 못한다기 보다 가중치 업데이트가 중지되면서 학습이 되지 않았던 듯하다.
- LSTM
- cell-state와 hidden-state 두가지가 있다는 게 큰 포인트이다.
- 이를 통해 hidden-state에서 과거의 정보 기억률에 대해 조절할 수 있게 된다.(Vanila RNN은 단순히 특정 비율로 과거의 모든 정보들이 잔존하게 된다... 맞나..?)
- 이런 매커니즘을 갖고 여러 variants가 있다.
- forget gate와 input gate를 합친 거나
- gate들이 계산할 때 peepholes를 통해 cell-state 값도 가져오거나...
- GRU
- seq2seq
- 2개의 RNN을 사용(vanila도 사용 가능하지만, 오늘은 LSTM 사용)
- 1개는 Encoder(Context vector 반환)
- 1개는 Decoder(Context vector를 받아서 단어 생성)
- 시작 토큰(SOS)과 종료(EOS) 토근의 사용 그림 예시
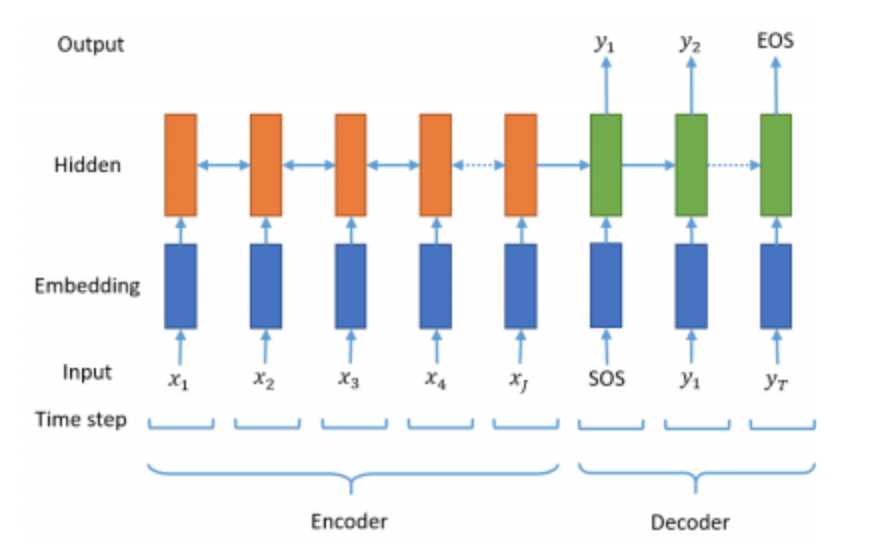
- 시작 토큰이 들어오면 생성 시작(기계 번역)
- Attention mechanism
- LSTM, GRU 등이 Long-term-dependency 문제로 인해 생겨났지만,
- 해당 모델들의 인코더가 만들어낸 context vector는 문제가 있었다.
- 바로 contexted vector의 fixed size.
- size는 나름 fix되어 있는데(결과론적인 이야기에서), 입력 갯수가 너무 많아지면 예전부터 입력된 cell-state가 오밀조밀하게 모여있게 된다.
- 추후 output으로 generate할 context와 별로 연관 없는 것들이 많다는 것이다.
- 그래서 attention은 이 fixed size 안에서 입력 순서로 있는 cell-state에 각각 다른 가중치를 준다.
- 그렇게 함으로써 그것을 필요한 때에(예 : POS tagging의 경우, 예측이 필요한 위치에서) 적절한 가중치를 매겨서 예측성을 높여준다.
- 즉, "모든 hidden state가 동일한 비중으로 반영되는 것이 아니라, 디코더의 현재 time step의 예측에 인코더의 각 step이 얼마나 영향을 미치는지에 따른 가중합으로 계산"
- 이름하여 dynamic context vector
- vanila RNN
-
RNN 최적화는 단순히 backpropagation이 아니라 backpropagation through time(bptt)이라고 불리는데,
- 차이는 ...
-
kinda list comprehension에서 if가 많이 쓰인 예
tokens = ' '.join(word for word in sentence.split() if not word in stopwords.words('english') if len(word) > 1)-
앞에서부터(읽는 순서로) 조건이 시작되는 듯 하다.
-
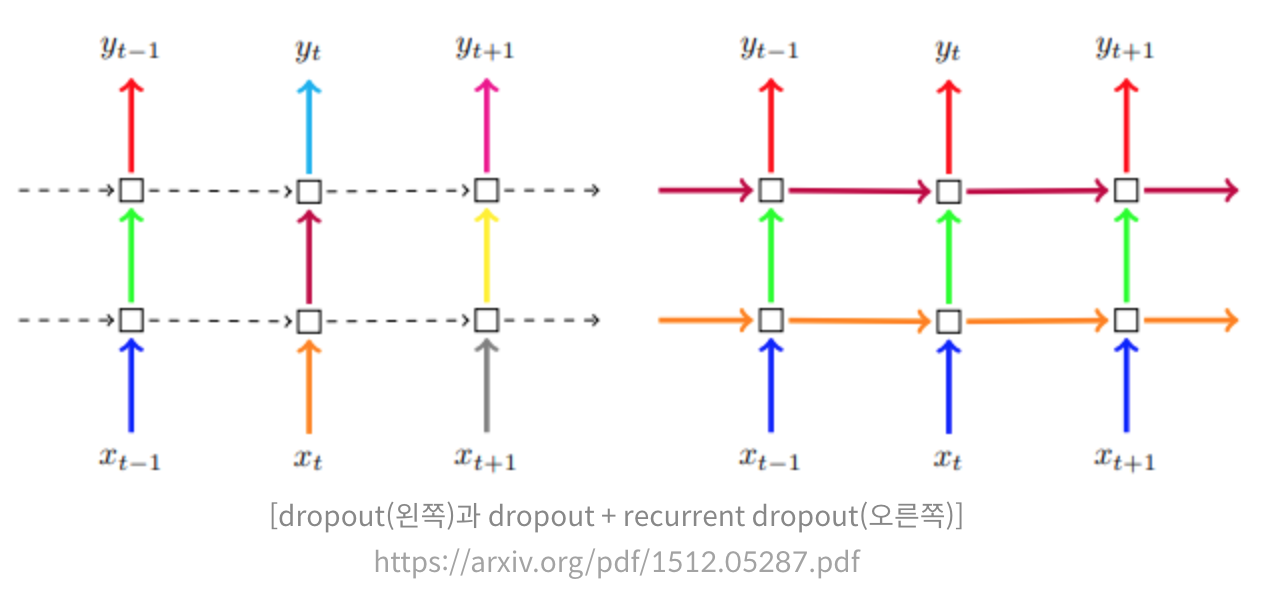
recurrent dropout이라는 파라미터가 있다.
- 일반적인 dropout을 레이어 단에서 랜덤하게 뉴런의 출력을 끄는 것으로 본다면
- recurrent dropout은 레이어마다가 아니라 time step마다 dropout을 해준다.
-
Functional API로 모델을 만든다면
- layer들을 만드는데,
- 각 layer마다 ()을 통해 전 층에서 나온 output을 call해준다
- 그리고
Model()을inputs과outputs를 파라미터로 넣어준다. - 그리고 decode LSTM을 만들 때는
intial_state=[state_h, state_c]같이 인코더의 hidden state와 cell state를 넣어준다.
- layer들을 만드는데,
-
보니까 Sequential API에서는 Embedding 레이어를 첫번째로 넣을 수 있었는데, Functional API에서는 Input 레이어를 쓰고, 그 출력값을 Embedding 레이어에 넣으면서 구조를 짜는 것 같다.(Embedding은 결국 두번째 레이어)
프로젝트 진행 순서
-
데이터 불러오기
- csv로서 Pandas 사용
-
데이터 전처리
- null 값 제거
- 중복값 제거
- 의미상 중복어 정규화(text normalisation)
- 링크 참조함
- stopwords 제거
- 대문자 -> 소문자
- 섞여있는 html 태크 정리
- ReGex 활용해서 특수문자 정리
-
데이터 전처리(2)
- 샘플 길이 정하기
- 길이 분포 그래프로 확인하기
- 샘플 길이에 데이터셋 맞추기
- 전체 살리면서 긴 건 자르던지
- 긴 건 그냥 제외하든지
- decorder 시작, 종료 토큰 들어간 column 각각 만들기
- 시작 토큰 + 타겟 메시지
- 타겟 메시지 + 종료 토큰
- train, test로 나누기
- 샘플 길이 정하기
-
데이터 전처리(3)
-
단어 사전 만들기
tensorflow.keras.preprocessing.text.Tokenizer()사용Tokenizer객체.fit_on_texts(corpus)
-
정수 인코딩
- 역시 keras tokenizer로 함께 진행됨
- Tokenizer.texts_to_sequences(corpus)
-
여기서 또 단어 사전상 빈도 수가 적은 거는 걸러내기
Tokenizer.word_index,Tokenizer.word_counts활용근데 이렇게 num_words를 설정해서 자꾸 단어들을 날리면, 단어 사전에 없는 단어를 가진 원본 텍스트는 정수 인코딩 후에 empty로 되어 있을 수 있다.
-
그래서 empty가 됐을 것들을 찾아내서 걸러준다
- 여기선 요약문에서 길이가 1인 것들(시작 혹은 종료 토큰은 빈도수상 남아 있을 수 밖에 없으니)을 찾아서 그것들의 index를 저장하고
- 그 인덱스에 포함되지 않은 인덱스만 골라서 다시 저장했다.
-
-
모델 설계하기
-
keras의 Functional API를 사용했다.
-
이 때 인코더, 디코더 각각 RNN이 들어간다.
-
훈련할 때는 인코더 + 디코더 모델 1개로 가능한데,
-
예측할 때는 구조가 달라서 인코더 모델 1개 + 디코더 모델 1개, 총 2개로 설계해야 한단다.
-
이유는...
-
seq2seq는 훈련할 때와 실제 동작할 때(인퍼런스 단계)의 방식이 다르므로 그에 맞게 모델 설계를 별개로 진행해야 한다는 것, 알고 계시나요?
훈련 단계에서는 디코더의 입력부에 정답이 되는 문장 전체를 한꺼번에 넣고 디코더의 출력과 한 번에 비교할 수 있으므로, 인코더와 디코더를 엮은 통짜 모델 하나만 준비했습니다.
그러나 정답 문장이 없는 인퍼런스 단계에서는 만들어야 할 문장의 길이만큼 디코더가 반복 구조로 동작해야 하기 때문에 부득이하게 인퍼런스를 위한 모델 설계를 별도로 해주어야 합니다. 이때는 인코더 모델과 디코더 모델을 분리해서 설계합니다. -
그리고 attention mechanism이 사용된 디코더를 만들어서 사용할 수도 있다.
-
기타
-
추출적 요약을 쓰는
summa패키지 사용- summa.summarizer.summarize()의 파라미터 설명
text (str) : 요약할 테스트.
ratio (float, optional) – 요약문에서 원본에서 선택되는 문장 비율. 0~1 사이값
words (int or None, optional) – 출력에 포함할 단어 수.
만약, ratio와 함께 두 파라미터가 모두 제공되는 경우 ratio는 무시한다.
split (bool, optional) – True면 문장 list / False는 조인(join)된 문자열을 반환
-
끝으로 추상적요약 vs 추출적 요약의 비교
추상적 요약은 표현력이 좋아지지만, 구현하는 난이도가 높다.
반대로 추출적 요약은 비교적 난이도가 낮고 기존 문장에서 문장을 꺼내오는 것이므로 잘못된 요약이 나올 가능성이 낮다.
