오늘의 학습 리스트
- 좌표 표현 방법
- 한 이미지의 좌표 표현 방법에 따라 bounding box 그릴 때 작성하는 값들의 순서가 달라진다.
- 예를 들어 (높이, 너비)로 이미지의 크기 표현 방법이 확정되면 좌표 표기는 (x, y)가 된다.
- 그러나 (너비, 높이)로 순서가 바뀌면 좌표 표기도 (y, x)가 된다.
- 그래서
[a, b, c, d]가 있을 경우 (y, x)로 쓰는 식이면,
tf.gather(params, indices)- https://www.tensorflow.org/api_docs/python/tf/gather?version=nightly
- 뭔가 slicing 비슷한데, Numpy의 list indexing(?) 같이 된다.
tf.TensorArray- https://www.tensorflow.org/api_docs/python/tf/TensorArray
- "Class wrapping dynamic-sized, per-time-step, write-once Tensor arrays."
- 뭔가 클래스 만들 때 안에서 time step에 따라 다르게 값이 나오는? 일회성(?) tensor인 것 같다.
논문 이해
Focal Loss for Dense Object Detection
-
Focal loss
- cross entropy 식 앞에 가 낮을 경우 더 낮은 값이 돼서 - 변환 시 더 큰 loss가 되도록 를 붙임.
- 즉, 가 되게 함.
-
주요 의의
- p 1. "the proposed focal loss enables training highly accurate dense object detectors in the presence of vast numbers of easy background examples."
-
제기하는 문제
- p 1. "one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause."
-
해결 방안
- (간략하게) p 2. "we identify class imbalance during training as the main obstacle impeding one-stage detector from achieving state-of-the-art accuracy and propose a new loss function that eliminates this barrier."
-
원리에 대한 이해
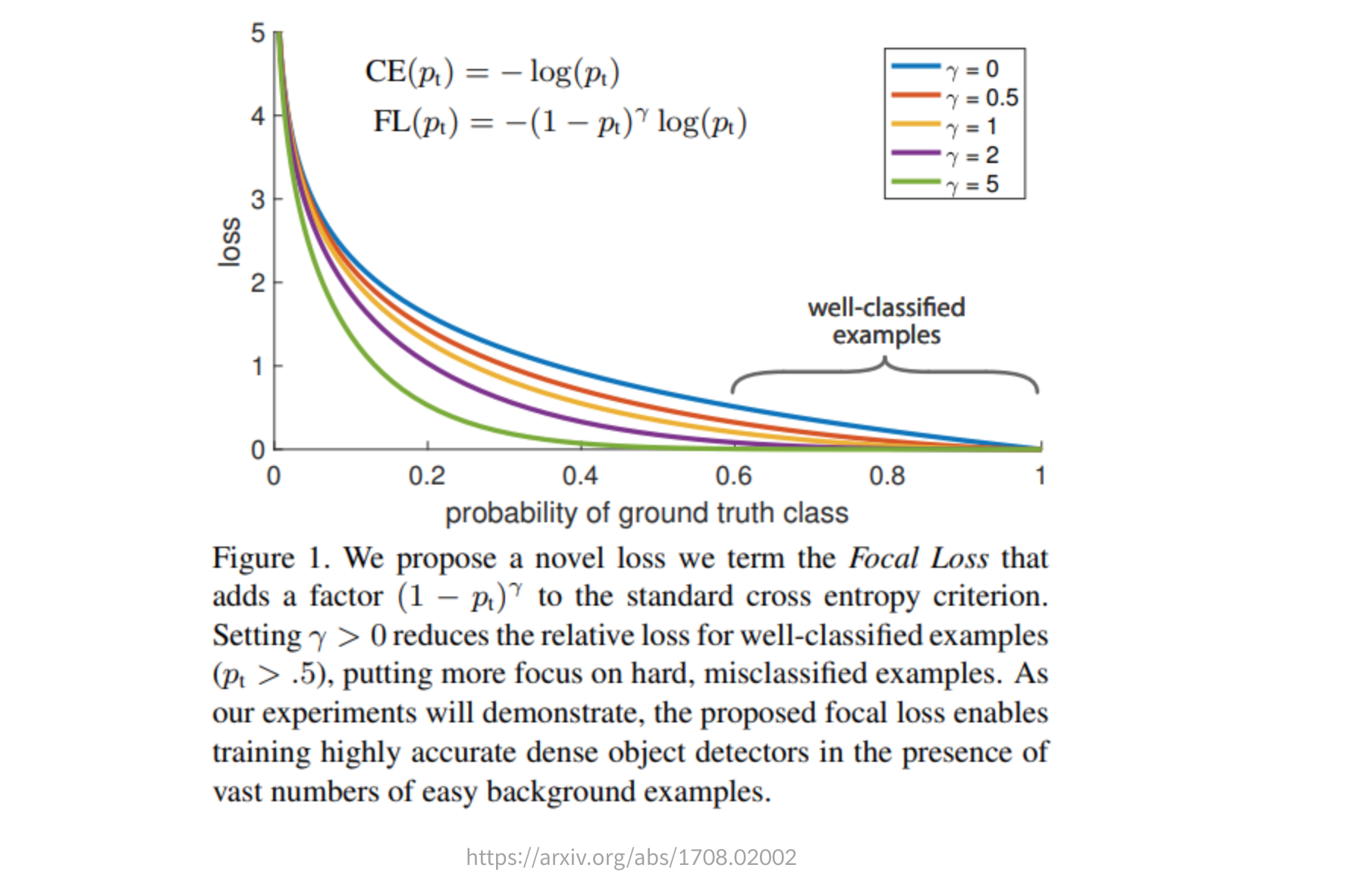
- p 3. "The CE loss can be seen as the blue (top) curve in Figure 1. One notable property of this loss, which can be easily seen in its plot, is that even examples that are easily classified (pt :5) incur a loss with non-trivial magnitude."
- 즉, class imbalance가 있는 상황에서 p가 굉장히 낮은 수치여서 class가 거의 없다고 추정되는 때에도 모델 입장에서는 loss가 크기 때문에 해당 데이터를 더 주의(?)하게 됨.
- 그래서 해당 loss가 줄어들도록 굳이 애써서 class가 없음에도 그거와 연관된 파라미터를 키우려 함.
- p 3. "The CE loss can be seen as the blue (top) curve in Figure 1. One notable property of this loss, which can be easily seen in its plot, is that even examples that are easily classified (pt :5) incur a loss with non-trivial magnitude."
더 공부할 것
-
Hard Exampling Mining
-
Bootstrapping in Object Detection

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다