
HanBitN MSA?
한빛N MSA(Micro Seminar Assemble)는 한빛미디어 디지털콘텐츠개발연구소에서 준비한 세미나 시리즈다. 학교와, 학원 등에서 다루지는 않지만, 현업에서 일을 할 때 필요한 지식, 기술, 정보 등을 전달하는 걸 목표로 진행되는 세미나다.

정글에 와드는 열심히 박으면서, 왜 서버 모니터링은 안하나요?

서비스를 만들고 배포할때 어떤 크기로 배포해야하고, 고객이 늘어나면 어떻게 대응해야 하는지 고민이 생길 수 있다. 이때 필요한 것이 바로 모니터링이다. 모니터링을 단순히 관제한다는 개념으로 생각할 수 있지만, 이번 세미나에서는 모니터링을 통해 인프라의 사용량, 각 서비스간의 연관관계를 확인하는 '개발자의 도구'로서 활용할 수 있는 방법을 다뤘다.
본 게시글에 사용된 강의 자료는 한빛미디어의 지원을 받았습니다.
모니터링 도입이 어려운 이유
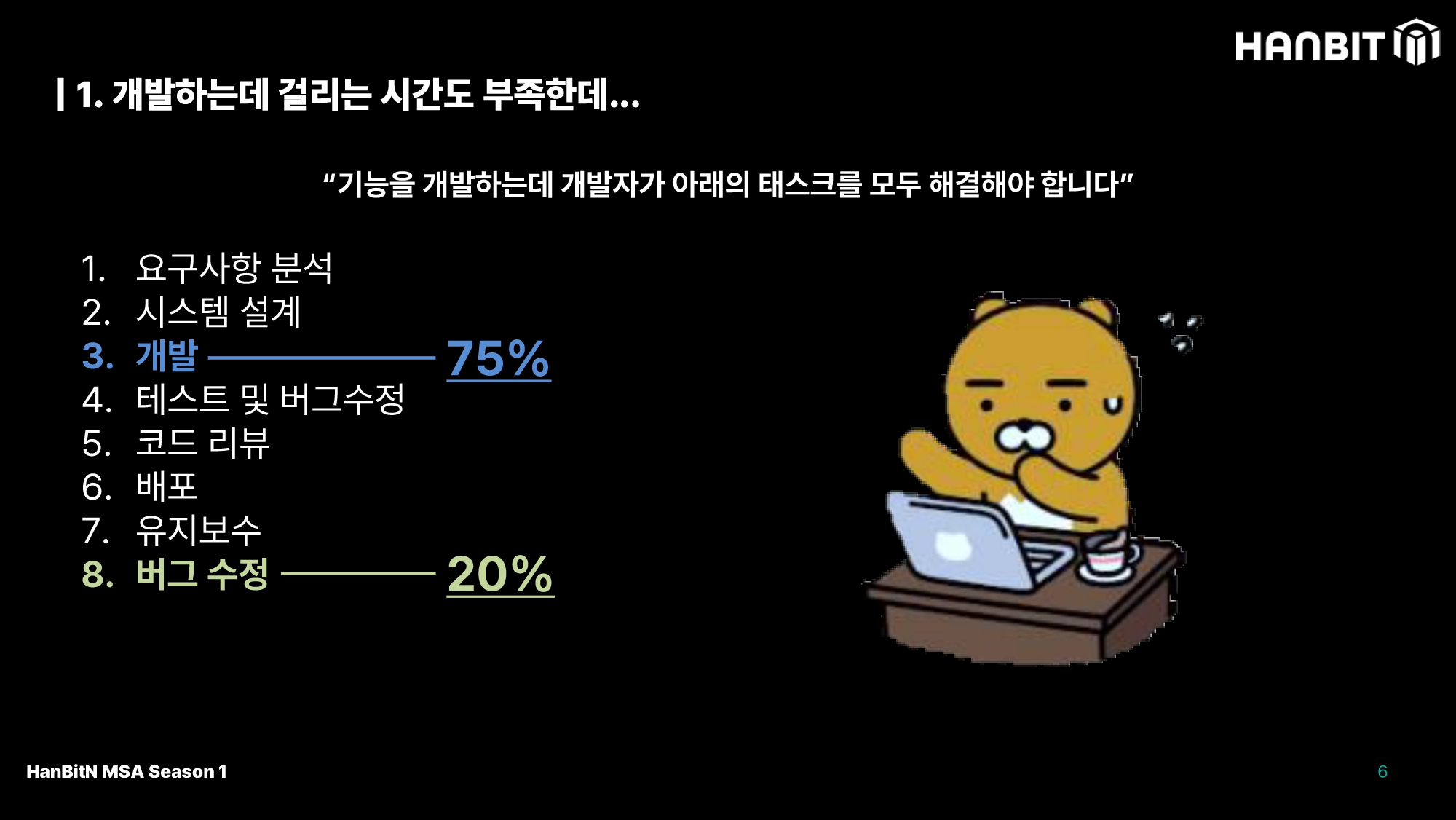
사실 개발자가 해야하는 일은 단순히 개발 하나만 있는건 아니다. 물론 코딩으로 기능을 구현하는 개발 단계가 대부분을 차지하지만, 요구사항 분석부터 시작해 최종적으로 버그 수정까지 사진에 보이는 것만 나열해도 8가지다. 이런 과정을 하면서 모니터링까지 하기엔 사실 시간이 부족할 수 밖에 없다.
위 이유를 제쳐두고도 다음과 같은 이유로 모니터링 도입을 하지 않는다.
- 대부분 재시작으로 해결 가능한 문제 (특정 시점의 부하)
- 아직은 문제가 발생하지 않은 경우 (정확하지 않은 가용성 체크, 잠재 문제의 누적 등)
모니터링의 중요성

사전적 의미를 비틀어, 서버라는 매개체에서 진행하는 모니터링을 세미나에서 소개했다. 하지만 앞서 말했듯이 개발자들은 코드 볼 시간도 부족한 상황이다. 하루종일 대시보드만 보며 개발까지 하는건 사실상 불가능하다. 그럼에도 백엔드 개발자가 해야하는 모니터링이 있다면 무엇일지 알아보자.
📌 모니터링
1. 어플리케이션 모니터링(이하 APM): 주로 백엔드 모니터링을 담당함.
2. 인프라 모니터링: 가용성 체크를 위함.
3. 로그 모니터링: 비즈니스 히스토리를 기록하기 위함.
4. DB 모니터링: 부하 관점에서 파악 가능함.
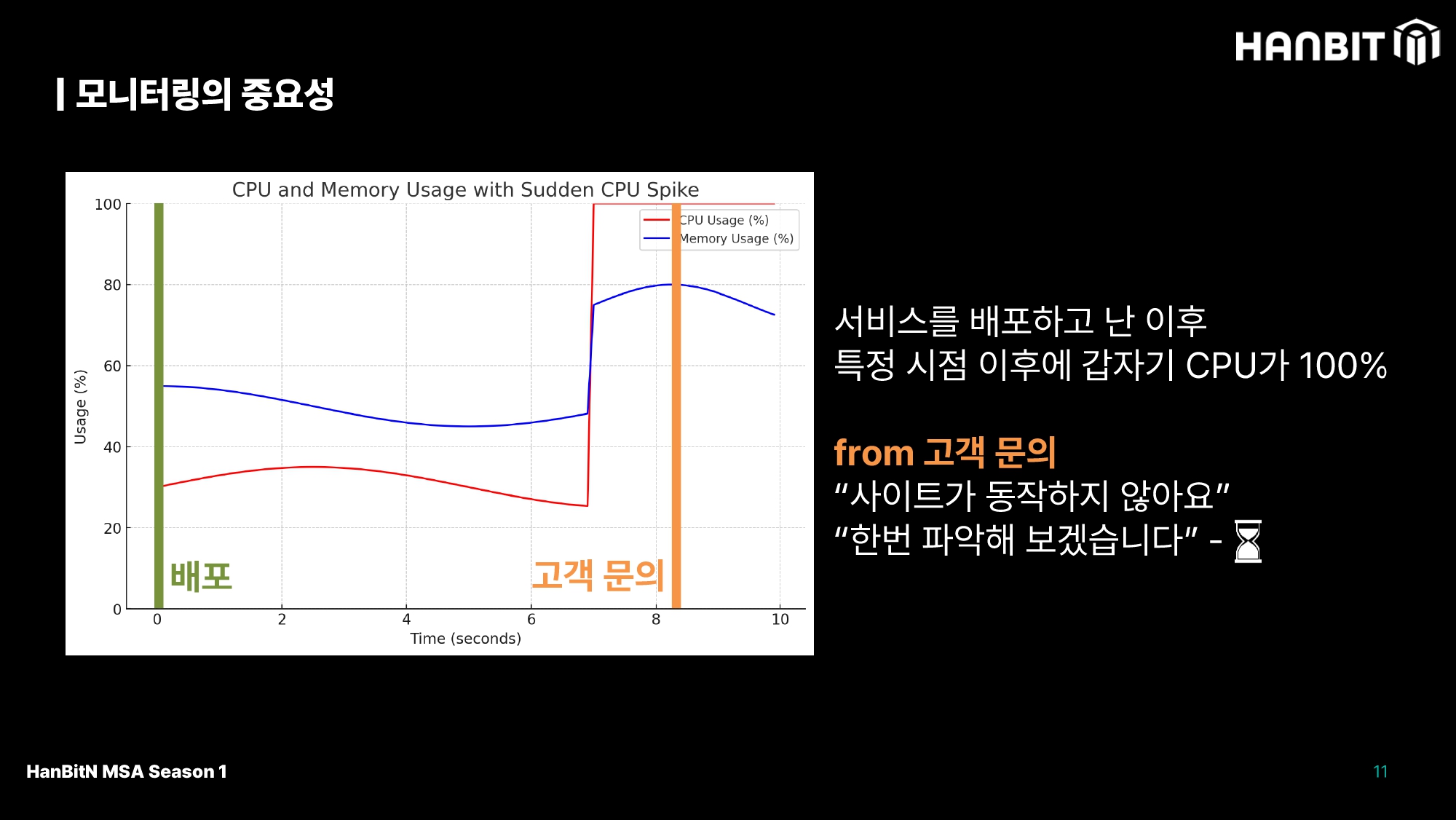
개발자가 서비스를 배포하고 나면, 특정 시점 이후로 CPU가 100%로 스파이크 치는걸 흔히 볼 수 있다. 만약 이 상황을 고객이 겪었다고 생각해보자. 아무래도 '고객의 소리' 페이지에 고객들의 불만이 한가득 모여있을게 뻔하다. 해당 이슈를 개발자가 접하기까진 생각보다 많은 시간이 걸리는데, 이런 상황에서 미리 모니터링을 적용했다면 어떻게 될까?
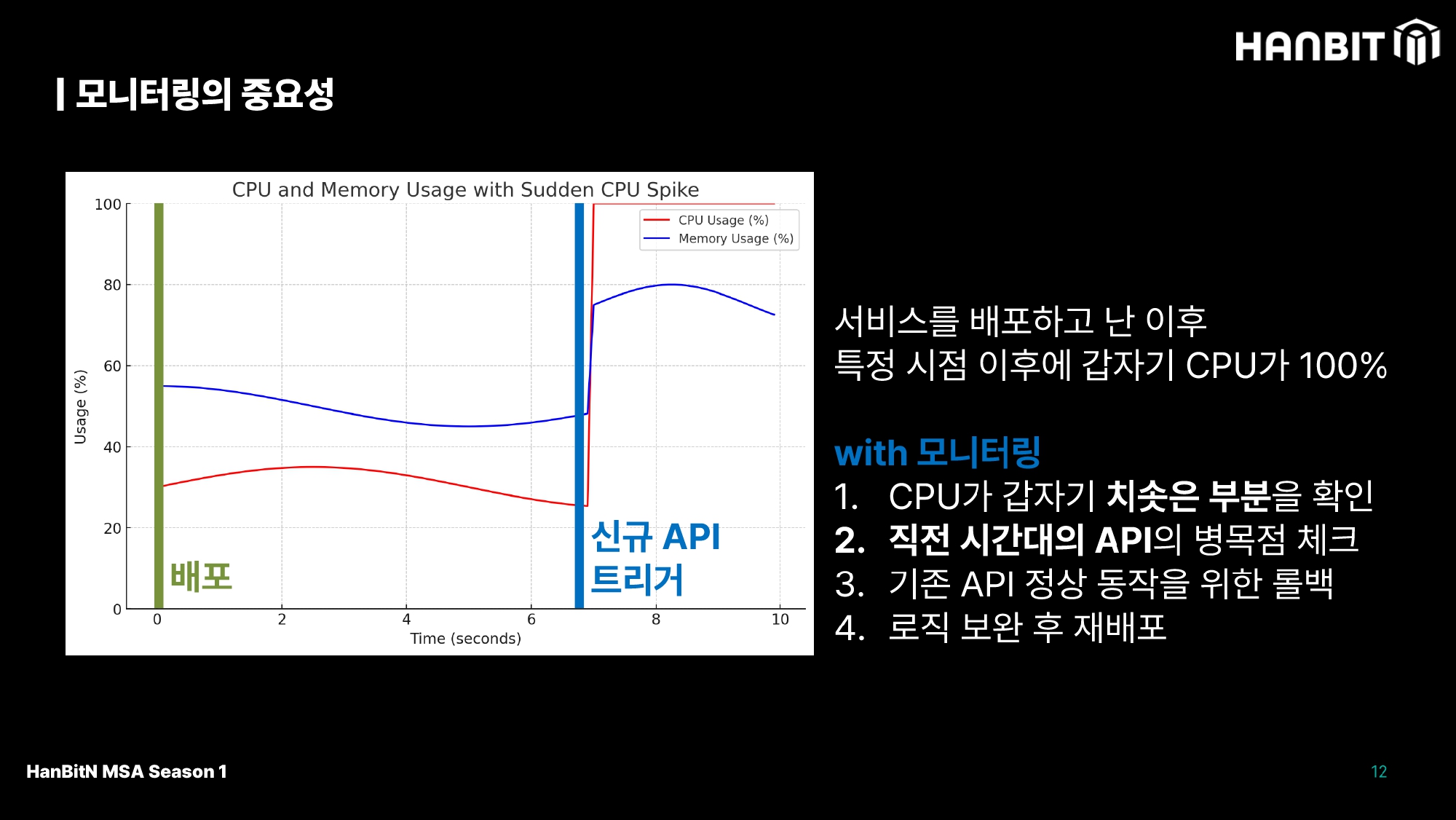
똑같이 배포한 이후에 모니터링을 진행한다. 갑자기 CPU가 100%를 치는 상황에서 메모리도 80%까지 올라가는걸 확인할 시점에 개발자는 우선 API나 추가 동작이 일어나는지 확인하고, 가장 유력한 부분을 찾아 재배포를 하게 된다.
이렇게 고객지원 이후 개발자에게 문의가 들어온 뒤에 대응하는 것과 다르게 모니터링을 하면 빠르게 지원이 가능하다.

이런 이유로 모니터링은 시스템의 효율성, 안정성 유지를 위해 필수적이다.
기본 지표 이해하기!

모니터링을 하며 보이는 기본적인 지표들은 다음과 같다. 이런 기본적인 지표들은 외운다기 보다는, 직접 모니터링 하면서 상황이 발생했을때 각 지표들을 비교하며 경험해보는게 더 중요하다고 소개해주셨다. 하나하나 이해하려고 애쓰지 말자.
- CPU 지표: CPU 사용률, CPU 평균 로드, CPU Idle 시간, Context Switch, CPU 인터럽트
- 메모리 지표: 총 메모리 사용량, 가용 메모리, 메모리 캐시, 스왑 사용량, page Faults
- 디스크 지표: 디스크 사용량, 디스크 I/O, 디스크 대기 시간, IOPS, 스루풋, 에러율
- 네트워크 지표: 대역폭 사용률, 트래픽 흐름, 지연 시간, 패킷 손실, 에러율, 연결 상태
각 지표들은 이렇게 활용할 수 있다.
- CPU 지표: 성능 저하의 원인 파악, 최적화
- 메모리 지표: 시스템의 접근 속도, 안정성 개선
- 디스크 지표: 파일 처리 성능을 유지하기 위해 필수적, 빠른 액세스 보장.
- 전체 IT 인프라의 효율성, 안정성 개선
📌 예시
만약 CPU 사용량 지표가 높은 상황에서 배포를 진행한다면 배포 시간이 늘어나고 서버 리소스가 추가로 소모될 수 있다. 모니터링을 통해 이런 상황을 피할 수 있다.
모니터링 도구
이런 지표들을 시각화 해주는 모니터링 도구를 알아보자.

상용 모니터링 도구는 금전적인 대가를 지급하는 만큼 손쉽게 세팅해 모니터링 할 수 있다.

물론 무료(오픈소스)도 있다. 오픈소스 모니터링 도구의 경우 코드를 직접 빌드해야 하는 경우도 있으니 주의하자. 말 그대로 코드만 올라와있고, 실제 적용은 개발자가 스스로 해야하는 문제가 있어 팀원중에 오픈소스 모니터링을 직접한 경우가 없다면 크게 추천하진 않는다고 한다.
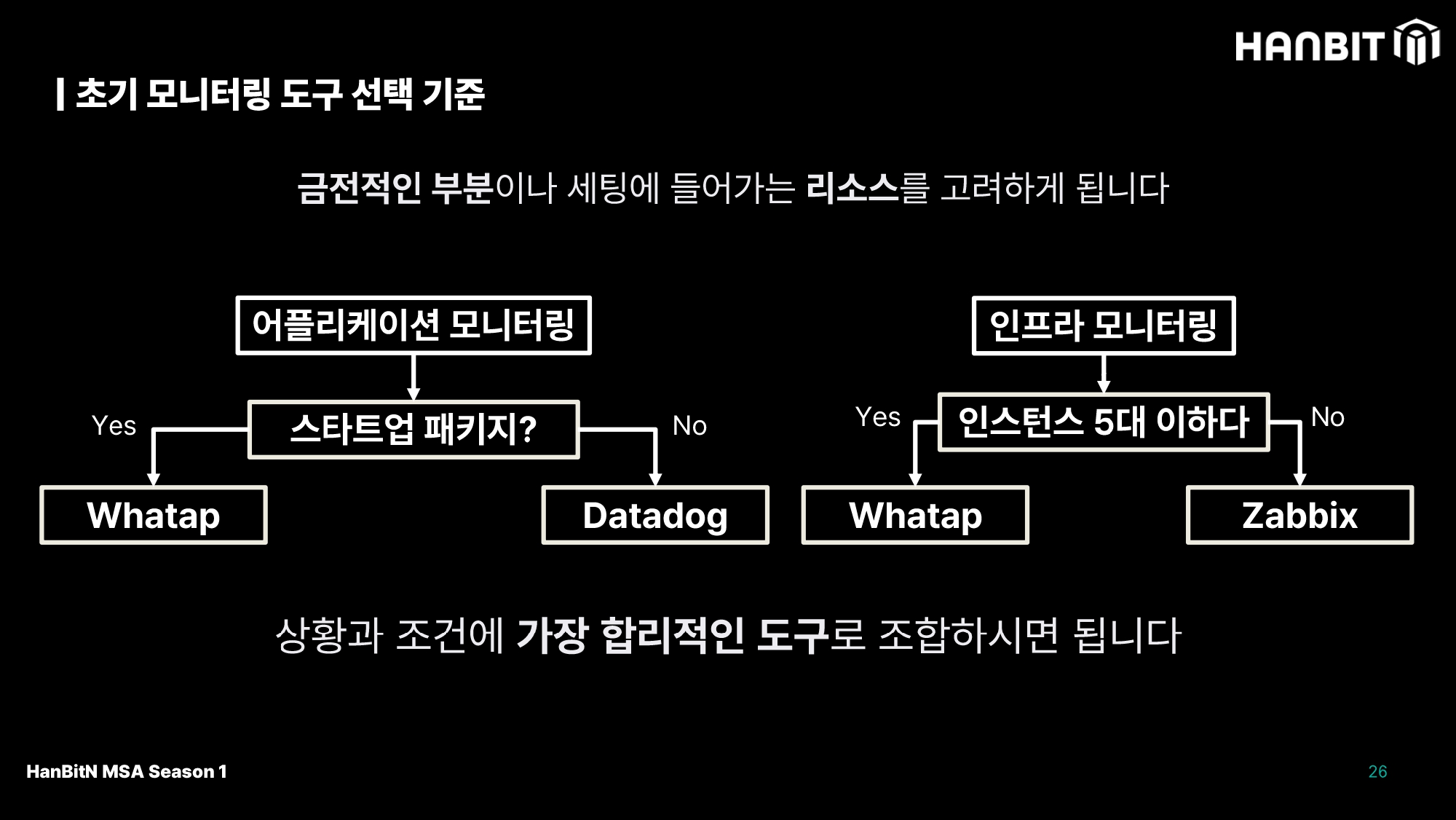
모니터링을 세팅하는 것 또한 업무 리소스를 쪼개 진행하는 작업이어서, 비용이나 시간적 리소스를 체크해야 한다. 처음에는 서비스를 모니터링에 사용하는 APM, 서비스 가용성 확인을 위한 인프라 모니터링 을 초기 세팅으로 잡는다.
물론 무료로 세팅할 수 있지만, 가성비 좋은 상용 모니터링 툴이 있다면 해당 툴로 시간을 단축하는것도 선택지로 두자. 사용하던 모니터링 툴이 다른 서비스로 이전하거나 갑자기 접을수도 있기 때문인데, 이런 관점에서 상용 모니터링툴을 빨리 교환해 적용하는게 중요하다 볼 수 있다.
모니터링 툴 각각 특화된 모니터링이 다르기 때문에, 어떤 것을 필요로 하는지 확인해 본인(팀)만의 선택 기준을 가지고 상황과 조건에 가장 합리적인 도구를 선택하자.
실시간 모니터링 전략
실제 근무 상황에서 언제 모니터링 하는게 효과적일지 알아보자.
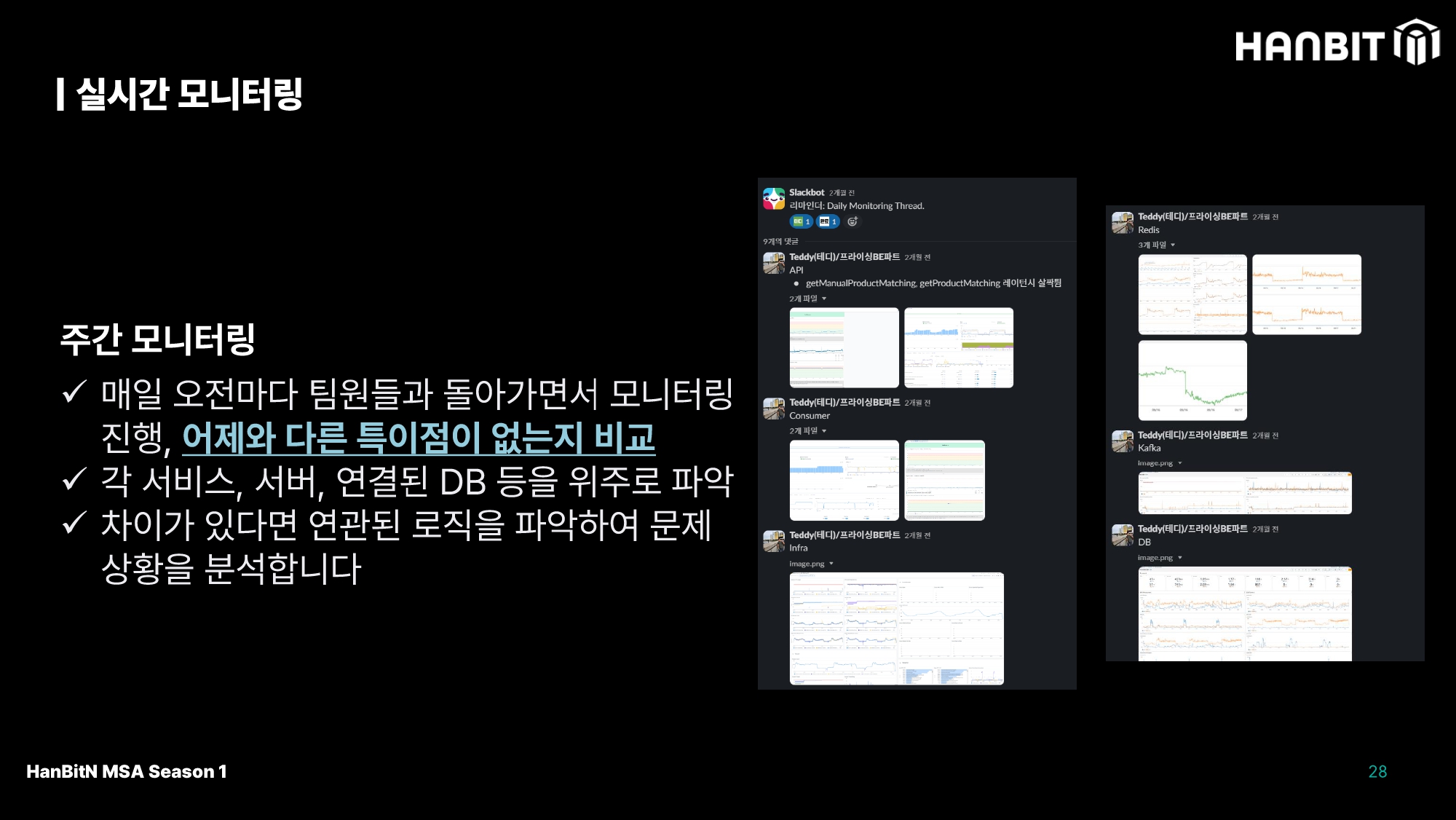
먼저 주간 모니터링이다. 운동을 하기 전에 스트레칭이나 런닝을 하며 워밍업을 하는 것 처럼, 개발에 바로 집중하기란 쉽지 않다. 어느정도 워밍업이 되어야 빠르게 투입할 수 있기 때문에 발표자 분께서는 매일 오전 팀원들과 모니터링하며 어제와 다른 특이점을 확인한다고 한다.
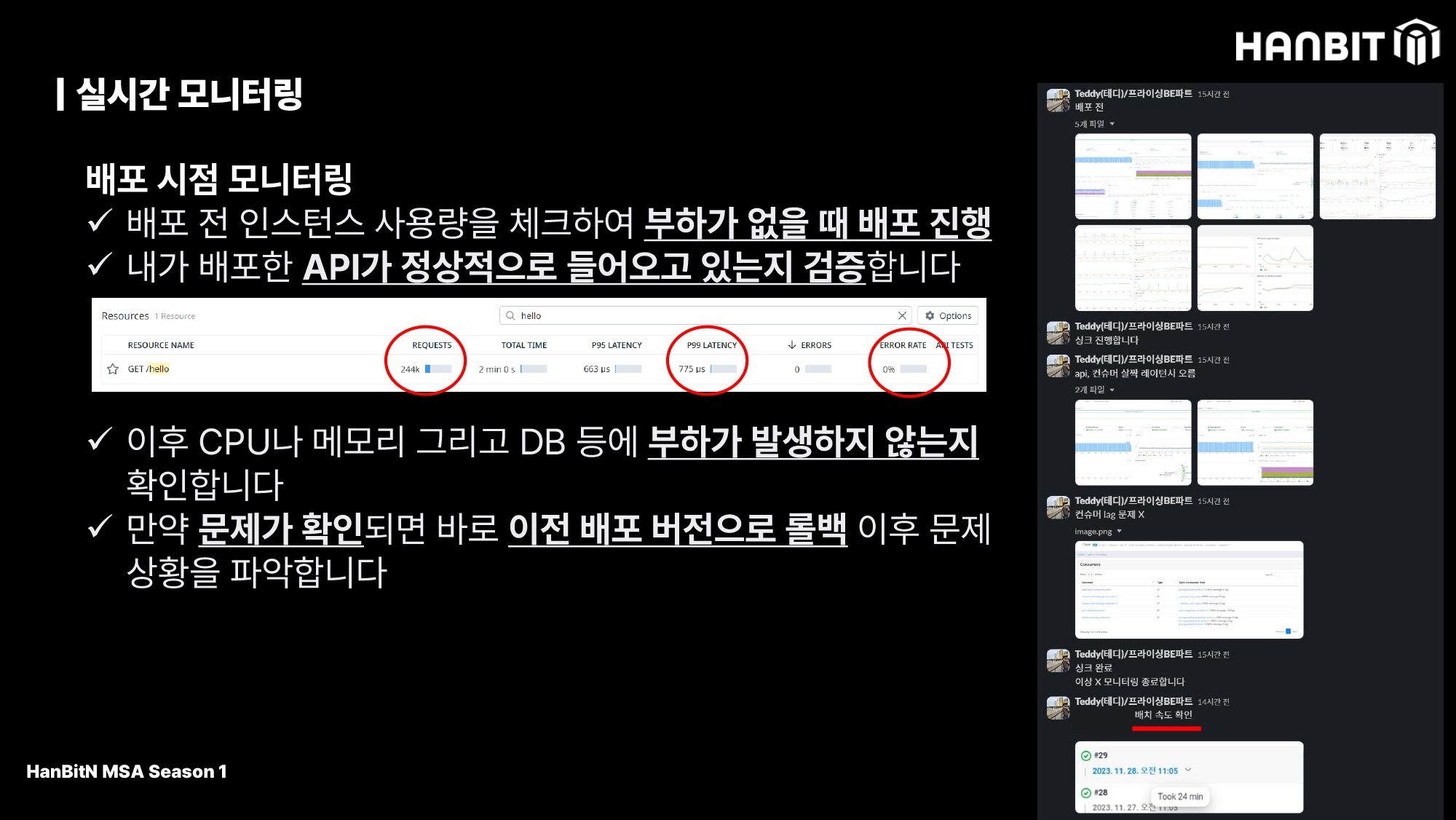
배포 시점에도 모니터링은 필요하다. 배포 직전에 서비스를 배포해도 되는지 한번 사용량을 확인하며 배포하며, 추가적으로 배포 이후에 기능이 정상적으로 돌아가는지 검증하고, 레이턴시나 에러케이스는 없는지 검증한다. 만약 문제가 있다면 피해를 최소화 하기 위해 롤백 후 문제 상황을 파악한다.
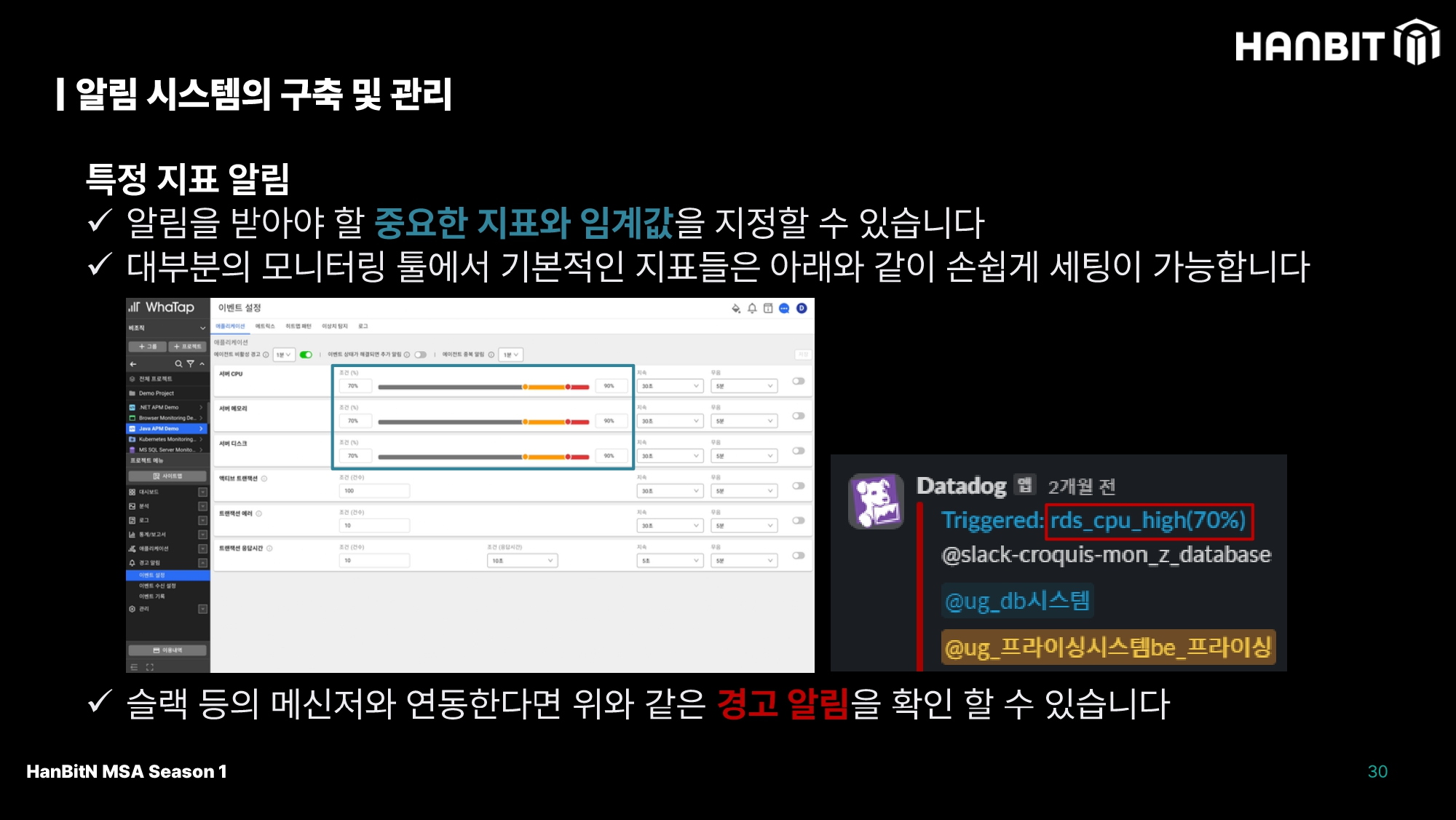
개발자가 매일 관제를 하지 않더라도, 문제가 생기면 바로 알고 있어야 한다. 모니터링의 기본 알림기능을 활용하면 관제라는 부분 없이 장애 상황에 대해 대응할 수 있는 프로세스를 구축할 수 있으니, 위처럼 특정 지표와 임계값을 잡아 경고 알람을 띄우게 설정하자.
언제 알림을 받아야 할까? (임계갑 설정, 조정)
세미나에서는 (평소 상황+10~20%를 더한 값) ~ (70%)를 임계값으로 잡으면 된다고 소개됐는데, 어떤 서비스를 운영하는지에 따라 다르게 적용되어야 하니 어디까지나 참고로 하자.
로그 모니터링의 중요성

일반적인 CPU, MEM, Network 지표에서는 비즈니스 로직을 검증하기 어렵다. 실제로 CPU 지표를 안다고 해서 내가 만든 로직이 정상적으로 동작하는지 알 방법이 없기 때문에, 별도로 로그 내역을 기록해 알림을 받아야 한다. 로그는 로그 레벨을 통해 중요도를 지정할 수 있는데, 일반적으로는 debug를 사용한다.
주의할게 있다면, 차츰 기능이 늘어감에 따라 처리량도 많아지게 되면 로그량도 그에 비례해 늘어나기 때문에 로그 저장소의 용량 관리가 필수적이다. 추가적으로 로그에 접근할 수 있는 사람들에게 개인정보, 시스템 주요 정보가 노출되지 않도록 핵심 부분에 마스킹하는 것도 중요하다.

로그 관리에 있어서 중요한 전략이 시간과 로그 레벨을 포함해 기록하는 것이다.
-
프로덕션 데이터 디버깅
프로덕션한 데이터를 디버깅할때 모든 로그가 debug level로 기록됐다면 오류 부분을 파악하는데 있어 파악하기 어렵다. 이는 저장소 관련 측면이나, 필터링 부분에서도 비효율적이다.
이 경우 팀원, QA 멤버, VoC 인입등에 대해서만 debug level을 로깅하도록 설정하자. 이런 설정만으로도 로그 총량은 최소화 하고, 추가적으로 배포하지 않더라도 문제 상황에 대해 파악할 수 있다. -
Exception 로그
동일한 관점에서 Exception 로그도 비슷하게 필요한 부분만 기록하는게 중요하다. 실제로 에러가 발생하면 비즈니스 레벨의 중요도를 체크해 슬랙으로 알림을 받도록 활용하고 있다고 한다.EX. 이메일 validation과 같은 일반적으로 발생하는 에러는 기록X
EX. 송금을 10000원 했는데 1000원이 가는 경우엔 기록O

로그 세팅을 위한 Logback도 간단히 소개됐다.
모니터링의 실제 적용

세미나에서는 WhaTap, Datadog에 대해 모니터링을 실제로 어떻게 적용하는지 알아봤다. 상용 모니터링 툴이라 그런지, 생각보다 쉽게 세팅할 수 있었다. 이런 기본 세팅만으로 기존에 사용하던 인프라 양을 예측해 장애 예방을 한다던지, 낭비되는 리소스를 체크해 비용을 줄이는 효과를 얻을 수도 있다.
마무리

처음 모니터링을 도입하기까지 설득도 힘들고, 세팅하는데 모니터링 툴이 오픈소스면 시간적 비용도 있고,, 신경써야 할 부분이 많지만 한 번 모니터링이 세팅되어 있으면 개발자가 한눈에 파악할 수 있도록 돕는 효과적인 역할을 한다. 가장 앞서서 모니터링을 주도하는 개발자가 되보자.
후기
몇 시간동안 모니터를 쳐다보는 일이 얼마나 고역인지는 군생활을 통해 많이 경험해서 잘 알고 있다. 언제 CPU/MEM 비율이 임계치를 초과할지 몰라 밤새 쳐다보면서 비몽사몽한 상태로 특이사항을 보고 하는건 썩 좋은 경험은 아니었다.
내가 했던 모니터링은 어디까지나 임계치를 확인하는 것이라 단순했지만, 실무에서의 모니터링은 더 복잡하고 중요도가 높다는걸 알았다. 그렇다고 모니터링만 할 수 없는 노릇이기에, 세미나를 듣는 내내 조금 더 의미있는 작업을 하며 중요한 특이사항만 확인할 수 있도록 모니터링 세팅을 잘 하는게 중요하다고 생각했다. 백엔드 개발자를 희망한다면 꼭 공부해보면 좋을 것 같은 내용이었다.
이번 리뷰글에서 모니터링 활용과 관련해 언급하지 않은 부분(보안, AIOps 등)이 있는데, 위 내용과 더불어 참가자들의 질문들이 궁금하면 한빛미디어에서 제공하는 VOD를 확인해보자.
