검색어로 데이터베이스 필드를 조회할 때, Elasticsearch라는 검색엔진(NoSQL)을 활용하여 전문검색(full-text search)을 가능하게 할 수 있다.
해당 기술을 도입하는 과정에서 배운 내용들을 정리해보려 한다.
✅ Elasticsearch 도입 배경
✅ Elasticsearch의 기본 개념
✅ AWS Opensearch
Elasticsearch 도입 배경
MongoDB에서 string 필드에 대해 전문검색을 하고 싶은 경우, 해당 필드를 text로 인덱싱해야한다. 그 후 $text 오퍼레이터를 사용한 전문 검색이 가능하다. 그러나 다음과 같은 문제가 발생할 수 있다.
데이터베이스 부하로 인한 이슈
$text 오퍼레이터는 데이터베이스에 부담이 많이 간다. 검색해야할 문서 범위가 큰 경우 응답 시간이 길어지거나 Timeout 에러가 발생하는 케이스가 많다.
세부적인 검색 불가능
MongoDB에서 제공하는 text 인덱스는 한국어에 적합한 tokenizer를 지원하지 않는다. 띄어쓰기와 같은 기본적인 단위로 토큰을 생성하여 검색하기 때문에 원하는 세부적인 결과를 도출하는데 아쉬움이 있다.
👉 위와 같은 문제들을 Elasticsearch를 도입하여 한글 형태소 분석기 은전한닢 을 적용해서 보다 상세한 검색이 가능하도록 보완하였다. 또, Elasticsearch로 MongoDB의 document의 ID를 조회하고, 그 후 이를 기반으로 MongoDB를 조회하는 방식을 통해 MongoDB에 가해지는 부담을 낮출 수 있다.
Elasticsearch의 기본 개념
What is Elasticsearch?
Elasticsearch는 루씬을 코어로 이용하여 JSON 문서의 저장, 색인, 검색 등의 작업을 분산처리하는 검색엔진이다.
Elasticsearch는 다른 RDBMS나 경쟁 NoSQL에 비해 매우 강력한 검색 기능을 제공한다. 단순한 텍스트 매칭 검색이 아닌 본격적인 전문 검색(full-text search)이 가능하며 다양한 종류의 검색 쿼리를 지원한다. 검색 엔진이기 때문에 역색인을 사용하여 검색 속도도 매우 빠르다. 다양한 analyzer를 조합하여 여러 비즈니스 요구사항에 맞는 색인을 구성할 수 있고 형태소 분석도 가능하다.
- 아파치 루씬(Apache Lucene): 데이터 색인 및 검색 기능을 제공하는 검색 엔진의 코어 라이브러리
- 전문 검색(full-text search): 어떤 정보의 본문 내용 전체를 색인 형태로 제공함으로써 각종 데이터를 키워드로 빠르고 정확하게 검색하는 기법
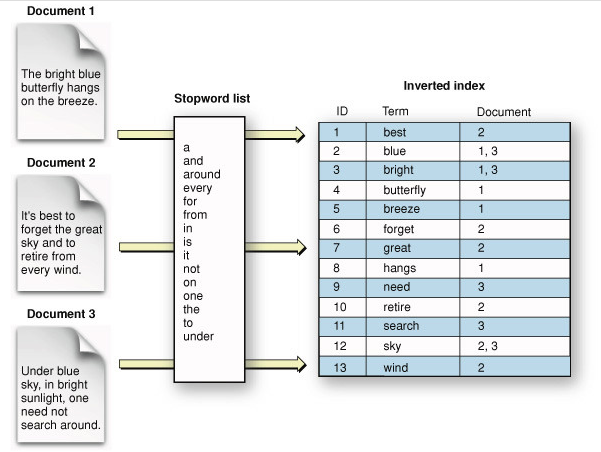
Features
기본적인 분산 처리, 고가용성, scale-out, 데이터 안정성 등의 기능을 모두 제공한다. 그 밖에 아래와 같은 특징이 있다.
다양한 플러그인을 통한 기능 확장 지원
Elasticsearch는 다양한 플러그인을 사용해 기능을 확장하거나 변경할 수 있다. 핵심적인 기능들 역시 플러그인을 통해 제어할 수 있도록 설계되었다. Elastic이 공식적으로 제공하는 플러그인도 매우 많으며 커뮤니티에서도 다양한 서드파티 플러그인을 공개하고 있다.
준실시간 검색
Elasticsearch는 준실시간 검색(near real-time search)를 지원한다. 데이터를 색인하자마자 조회하는 것은 가능하지만, 데이터 색인 직후의 검색 요청은 성공하지 못할 가능성이 높다. Elasticsearch가 역색인을 구성하고 이 역색인으로부터 검색이 가능해지기까지 시간이 걸리기 때문이다. 기본 설정으로 운영할 경우 최대 1초 정도의 시간이 걸린다. 이런 특성을 바탕으로 서비스를 설계할 필요가 있다.
트랜잭션이 지원되지 않음
Elasticsearch는 RDBMS와 다르게 트랜잭션을 지원하지 않는다.
사실상 조인을 지원하지 않음
Elasticsearch는 기본적으로 조인을 염두에 두고 설계되지 않았다. join이라는 특별한 데이터 타입이 있지만 이는 굉장히 제한적인 상황을 위한 기능이며 성능도 떨어진다. 기본적으로 RDBMS와 다르게 데이터를 비정규화해야 하며 서비스와 데이터 설계에 있어 조인을 아예 사용하지 않는다고 생각해야 한다.
Data Structure
| Elasticsearch | RDBMS | MongoDB |
|---|---|---|
| Index | Database | Database |
| (Type) | Table | Collection |
| Document(JSON) | Row | Document(BSON) |
| Field | Column | Field |
| Mapping | Schema |
Index
Document를 모아놓은 단위이다. 클라이언트는 인덱스 단위로 Elasticsearch에 검색을 요청한다.
Type
ElasticSearch 6.0 이전 버전에서는 하나의 인덱스 안에서 여러개의 문서를 묶어서 Type이라는 논리 단위로 나눴다.
버전 6.0 이후로는 인덱스 하나에 타입 하나만 둘 수 있도록 제한되었고, 버전 7.0 이후부터는 해당 개념은 deprecated 되었다. 현재는 문서를 논리적으로 구분해야할 필요가 있다면 모두 별도의 인덱스로 독립시킨다.
Document
Elasticsearch가 저장하고 색인을 생성하는 JSON 문서를 뜻한다. 각 문서는 _id 를 가지고 있고 인덱스 + _id + 라우팅 값의 조합은 Elasticsearch 클러스터 내에서 고유하다.
라우팅: 인덱스를 구성하는 샤드 중 몇 번 샤드를 대상으로 작업을 수행할지 지정하기 위한 값으로 문서를 색인할 때 각 문서마다 지정 가능하다(default:_id). 색인 시 라우팅 값을 지정했다면 문서 조회, 업데이트, 삭제, 검색 등의 작업 시에도 똑같이 라우팅을 지정해야 한다.- 색인, 조회, 업데이트, 삭제 등의 작업이 모두 라우팅 수행 후 단일 샤드에 대해 이루어지기 때문에
_id값의 고유성은 샤드 단위로 보장된다. 이를 인덱스 전체 범위에 대해 고유하도록 유지하는 것은 사용자의 책임이다.
Index Design
다음과 같은 형태로 인덱스를 생성할 수 있다.
PUT [인덱스 이름]
{
"settings": {},
"mappings": {}
}Settings
인덱스 생성 시 settings 필드에 인덱스 동작에 관한 설정을 지정할 수 있다.
number_of_shards
해당 인덱스의 데이터를 몇 개의 샤드로 쪼갤 것인지 설정한다. 해당 값은 인덱스 생성 이후 변경 불가하여 신중한 설계가 필요하다. 버전 7.0부터는 디폴트 1개로 설정된다.
number_of_replicas
주 샤드 하나당 복제본 몇 개를 둘 것인지 설정한다. 이 값은 인덱스 생성 후에도 동적으로 변경 가능하다. 버전 7.0 이후로는 디폴트 1개로 설정된다.
refresh_interval
해당 인덱스를 대상으로 refresh를 얼마나 자주 수행할 것인지를 지정한다. 인덱스에 색인된 문서는 refresh 된 이후로 검색이 가능하기 때문에 중요한 설정이다. 디폴트 값은 1초이다.
그 밖에도 analysis 필드에 이후 다룰 analyzer 와 tokenizer 에 관한 설정을 지정할 수 있다.
Mappings
인덱스 생성 시 mappings 필드에 JSON 문서가 인덱스에 어떻게 색인되고 저장될 지 지정할 수 있다.
필드 타입
-
매핑의 필드 타입은 한 번 지정되면 변경이 불가능하다.
타입 종류 숫자 타입 long, integer, short, byte, double, float, half_float, scaled_float date 타입 - format epoch_millis, epoch_second, date_time, strict_date_time, date_optional_time, strict_date_optional_time 계층 구조를 지원하는 타입 object, nested 문자열 타입 keyword, text 그 외 타입 geo_point, geo_shape, binary, long_range, date_range, ip_range, completion
-
scaled_float
부동소수점 수를 주어진 환산 계수로 스케일링해서 정수로 저장한다.
✔️ 예시실제 필드 값 환산 계수 인자 색인 결과 3.943 100 394 ⇒ 이후의 검색, 집계, 정렬 과정에서는 3.94 값을 가진 것처럼 동작한다.
⇒ 저장된 값의 정확도에서 손해를 보는 만큼 디스크 공간을 절약 가능하다. -
date타입
Elasticsearch의date타입은 인입되는 데이터의 형식을format이라는 옵션으로 지정 가능하다. 문서가 어떤 형식으로 들어오더라도 내부적으로는 UTC 시간대 epoch milliseconds로 변환되어long타입의 숫자로 저장된다.
-
배열
Elasticsearch에는 배열을 표현하는 별도의 타입이 없다. 예를 들면long타입으로 선언된 필드에는309라는 값을 넣을 수도 있고,[309, 221, 1599962]라는 값을 넣을 수도 있다.
-
계층 구조
계층 구조를 지원하는 타입으로는object와nested두 가지가 있다. 이 둘은 유사하지만 배열을 처리할 때의 동작이 다르다.✅
object: 배열을 구성하는 객체 요소를 서로 독립적인 데이터로 취급하지 않는다.
✅nested: 객체 배열의 각 객체 요소를 내부적으로 별도의 루씬 문서로 분리해 저장한다.✔️ 예시
예를 들어object타입으로 선언된spec필드와,nested타입으로 선언된spec필드에 아래와 같이 동일한 데이터를 담았다고 가정해보자.// document 1 { "spec": [ { "cores": 12, "memory": 128 }, { "cores": 6, "memory": 64 }, { "cores": 6, "memory": 32 } ] }object타입으로 선언한 경우 아래와 같이 평탄화한다.// document 1 { { "spec.cores": [12, 6, 6], "spec.memory": [128, 64, 32] } }nested타입으로 선언한 경우 각각의 별도 문서로 분리한다.// document 1 { "spec": { { "cores": 12, "memory": 128 } } }// document 2 { "spec": { { "cores": 6, "memory": 64 } } }// document 3 { "spec": { { "cores": 6, "memory": 32 } } }따라서, 만약 위와 같은 상황에서 "
cores가 6 이고memory가 128 인 문서를 찾는다"고 생각해보면,object타입으로 선언한 경우 해당 문서가 존재한다고 판단하여 결과로 반환하고,nested타입으로 선언한 경우 두 가지를 동시에 만족하는 문서가 없기 때문에 반환하지 않는다.이처럼 계층 구조의 데이터를 저장할 때 비즈니스 요구사항에 따라 적절한 타입을 선택할 필요가 있다.
nested타입의 경우 성능 문제가 있을 수 있기 때문에index.mapping.nested_field.limit(인덱스 당nested타입 개수 제한),index.mapping.nested_objects.limit(nested타입 당 객체 수 제한) 과 같은 설정이 존재한다. 각각 디폴트값은 50, 10000개이다.
-
문자열 필드 타입
문자열 자료형을 담는 필드에는keyword와text두 가지가 있다.
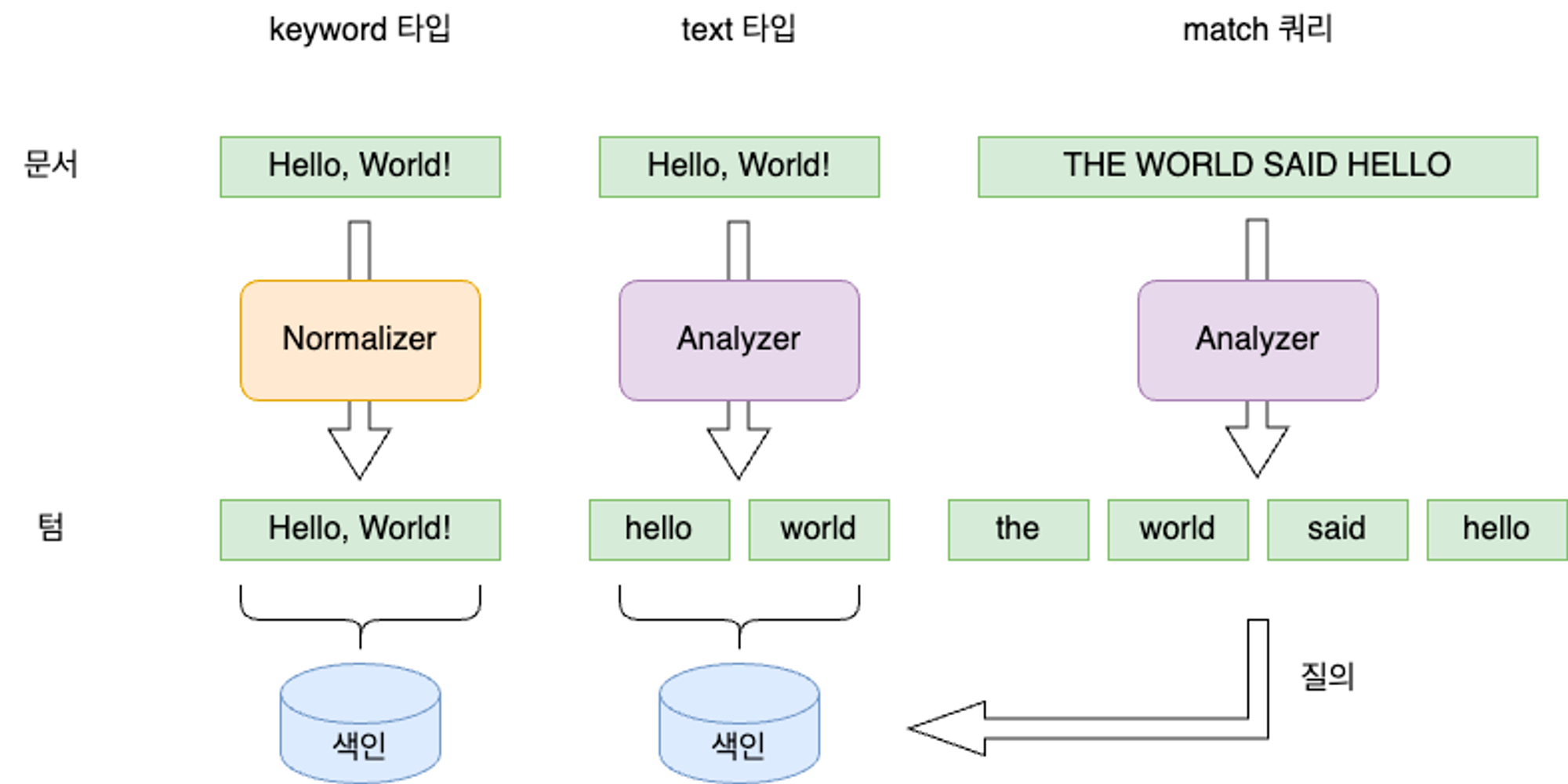
✅
keyword: 노멀라이저만 적용된 후 단일 term으로 역색인된다.
✅text: analyzer가 적용되어 토큰으로 쪼개진 후 여러개의 term으로 역색인된다.따라서,
keyword타입은 일치 검색에 주로 사용되고,text타입은 전문 검색에 적합하다.text필드에 대해match쿼리로 검색하는 경우, 검색 질의어도 동일한 analyzer로 분석된다.
동적 매핑 vs 명시적 매핑
이러한 mappings 는 인덱스 생성 시 명시적으로 지정도 가능하고, 지정되지 않은 필드가 들어오는 경우 Elasticsearch에서 동적으로 매핑을 생성한다. 이러한 매핑 타입은 한 번 지정되면 사실상 변경이 불가능하므로 동적 매핑에 기대기 보다는 명시적으로 지정해주는 것이 좋다. 예외적으로 이미 인덱스가 생성된 경우에도 신규 필드에 대해 매핑 정보를 추가하는 것은 가능하다.
Analyzer
text 타입 필드에 저장되는 데이터는 analyzer를 통해 여러 개의 term으로 쪼개져서 색인된다.
이러한 analyzer는 character filter, tokenizer, token filter 세 가지로 이루어지며, 여기서 tokenizer는 필수 요소이다.

1. Character Filter
인풋으로 들어온 텍스트를 character stream으로 받아서 특정한 문자를 추가, 변경, 삭제한다. 여러개의 character filter가 지정되었다면 순서대로 수행된다. 아래와 같은 내장 character filter가 있다.
| 종류 | 설명 |
|---|---|
| HTML strip | <b> 와 같은 HTML 요소 안쪽의 데이터를 꺼내고, HTML 엔티티를 디코딩한다. |
| mapping | 치환할 대상이 되는 문자와 치환 문자를 맵 형태로 선언한다. |
| pattern replace | 정규 표현식을 이용해서 문자를 치환한다. |
2. Tokenizer
character stream을 받아서 여러 token으로 쪼개어 token stream을 만든다. 하나의 analyzer에는 한 개의 tokenizer만 지정 가능하다. 아래와 같은 내장 tokenizer가 있다.
| 종류 | 설명 |
|---|---|
| standard | 디폴트 tokenizer이다. Unicode Text Segmentation 알고리즘을 사용하여 텍스트를 단어 단위로 나눈다. 대부분의 문장 부호가 사라진다. text 필드에 특정 analyzer를 지정하지 않으면 기본으로 standard analyzer가 적용되는데, 여기에 이용되는 tokenizer이다. |
| ngram | 텍스트를 min_gram 값 이상, max_gram 값 이하의 단위로 쪼갠다. 자동 완성 기능을 구현할 때 주로 사용된다(ex. text: “hello”, min_gram: 2, max_gram: 3 ⇒ token: [”he”, “hel”, “el”, “ell”, “ll”, “llo”, "lo"]). 긴 문장에서 공백이나 문장 부호 등 의미 없는 토큰이 추출되는 것을 피하기 위해 token_chars 라는 속성에 토큰에 포함시킬 문자 타입을 지정할 수 있다. |
| edge_ngram | ngram tokenizer와 유사하다. 하지만 모든 토큰의 시작 글자를 단어의 시작 글자로 고정시킨다는 점에서 차이가 있다. |
3. Token Filter
token stream을 받아서 token을 추가, 변경, 삭제한다. 여러개의 필터가 있는 경우 순차 적용된다.
| 종류 | 설명 |
|---|---|
| lowercase / uppercase | token의 내용을 소문자/대문자로 변경한다. |
| stop | the, a, an, in 등 불용어를 지정하여 제거한다. |
| synonym | 유의어 사전 파일을 지정하여 지정된 유의어를 치환한다. |
| pattern_replace | 정규식을 사용하여 토큰의 내용을 치환한다. |
| trim | token 전후에 위치한 공백 문자를 제거한다. |
이처럼 analyzer는 character filter, tokenizer, token filter 세 가지를 조합하여 구성된다. Elasticsearch에서는 미리 만들어진 다양한 analyzer를 제공한다. 그 외에도 사용 목적에 맞게 세 가지를 조합하여 커스텀 analyzer를 만들 수 있다.
그 외에 외부 플러그인을 설치하는 방식도 있다. 대표적인 한국어 형태소 분석기로는 nori와 은전한닢이 있다.
nori는 Elasticsearch가 공식 제공하는 플러그인으로, AWS Opensearch의 경우 버전 1.3 이상에 대해 nori 플러그인을 설치할 수 있다. 현재는 Opensearch 버전 1.2에서 지원되는 은전한닢 analyzer를 적용했다.
은전한닢을 사용하는 경우 아래와 같이 세부적인 속성을 지정할 수 있다.
{
"index-name" : {
"aliases" : { },
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer" : "seunjeon" // 은전한닢
}
},
"settings" : {
"index" : {
"analysis" : {
"analyzer" : {
"seunjeon" : { // 은전한닢을 custom analyzer로 추가
"type" : "custom",
"tokenizer" : "seunjeon_tokenizer"
}
},
"tokenizer" : {
"seunjeon_tokenizer" : {
"index_eojeol" : "false", // 어절 추출
"index_poses" : [ "UNK", "EP", "I", "M", "N", "SL", "SH", "SN", "VCP", "XP", "XS", "XR", "V" ], // 추출할 품사
"decompound" : "false", // 복합명사 분해
"pos_tagging" : "false", // 키워드에 품사를 붙여서 토큰 추출
"type" : "seunjeon_tokenizer",
"deinflect" : "false" // 활용어의 원형 추출 (* true일 경우 버그있음)
}
}
}
}
}
}
}Search by Query DSL
Elasticsearch에서 쿼리를 사용하는 방법은 ‘쿼리스트링’과 ‘쿼리 DSL’ 두가지가 있다.
✅ 쿼리 스트링 : REST API의 URL 주소에 쿼리문을 작성하는 방식
✅ 쿼리 DSL : Elasticsearch에서 제공하는 쿼리 전용 언어
간단한 요청을 제외하고는 주로 쿼리 DSL로 REST API의 요청 본문 안에 JSON 형태로 쿼리를 작성하여 검색을 수행하게 된다.
Elasticsearch는 검색을 위해 크게 리프 쿼리와 복합 쿼리를 지원한다.

Leaf Query
특정 필드의 값을 찾는데 사용한다. match, term , range 쿼리 등이 있다.
match query
전문 검색(full-text query)를 수행하기 위한 표준 쿼리로 지정한 필드의 내용이 질의어와 매치되는 문서를 찾는다. 필드가 text 타입인 경우 질의어도 analyzer로 분석된다.
GET index-name/_search
{
"query": {
"match": {
"title": "맛있는 사과"
}
}
} title 필드가 standard analyzer를 사용한다면 질의어는 '맛있는', '사과' 두 개의 토큰으로 분리된다. 그 후 색인된 문서의 title을 분석해서 만든 역색인에서 이 2개의 텀을 찾아 매치되는 문서를 반환한다. 기본 동작은 or 조건으로 동작한다. 다음과 같이 operator를 and로 지정하여 변경할 수 있다.
GET index-name/_search
{
"query": {
"match": {
"title": {
"query": "맛있는 사과",
"operator": "and"
}
}
}
} term query
지정한 필드의 값이 질의어와 정확히 일치하는 문서를 찾는다.
GET index-name/_search
{
"query": {
"term": {
"deleted": "false"
}
}
} terms query
term 쿼리와 유사하게 질의어와 정확히 일치하는 필드를 찾는다. 대신 질의어를 여러 개 지정할 수 있고, 하나 이상의 질의어가 일치하면 결과에 포함된다.
GET index-name/_search
{
"query": {
"terms": {
"userId": [1, 2, 3]
}
}
} range query
지정한 필드의 값이 특정 범위 내에 있는 문서를 찾는다.
GET index-name/_search
{
"query": {
"range": {
"createdAt": {
{ "lt": "2023-01-21T00:00:00Z" }
}
}
}
} exists query
지정한 필드를 포함한 문서를 검색한다.
GET index-name/_search
{
"query": {
"exists": {
"field": "deleted"
}
}
}Compound Query
다른 리프 쿼리나 복합 쿼리를 감싼 형태로 여러 개의 쿼리를 결합하는데 사용된다. bool, dis_max , constant_score 쿼리 등이 해당된다.
bool query
여러 쿼리를 조합하여 검색한다. must, must_not, filter, should 4개의 조건절 내에 다른 쿼리를 조합하여 사용한다.
GET index-name/_search
{
"query": {
"bool": {
"must": [
{ "term": { "deleted": "false" } }
],
"must_not": [
{ "term": { "deleted": true } }
],
"filter": [
"terms": { "userId": [1, 2, 3] }
],
"should": [
"match": { "title": "맛있는 사과" },
"match": { "content": "맛있는 사과" }
],
"minimum_should_match": 1
}
}
}must:and조건으로 모두 만족해야 검색 결과에 포함된다.filter:and조건으로 모두 만족해야 검색 결과에 포함된다. 결과의 스코어를 계산하지 않는다.must_not: 해당 조건을 만족하는 문서는 최종 결과에서 제외된다.should:minimum_should_match에 지정한 개수 이상의 하위 쿼리를 만족하는 문서가 최종 결과에 포함된다.
⇒minimum_should_match의 디폴트값은 1이고, 이 경우or조건으로 검색하는 것과 동일하다.
4개의 조건절을 모두 사용할 필요는 없고 필요한 것만 적용할 수 있다.
Others
script
그 밖에도 sciprt를 활용해 보다 복잡한 조건으로 검색할 수 있다. Elasticsearch의 자체 스크립트 언어인 painless를 이용한다.
GET index-name/_search
{
"query": {
script: {
script: {
source:
"doc['tags'].size() != 0 && ((doc['tags'].value != params.tag && doc['tags'].size() > 0) || doc['tags'].size() > 1)",
lang: 'painless',
params: {
tag: "과일",
},
},
},
}
}Query Context & Filter Context
Elasticsearch는 기본적으로 검색 결과를 해당 문서가 얼마나 질의와 잘 일치하는지를 나타내는 관련성(정확도) 점수(relevance score)에 따라 정렬한다. 검색 과정에서 이러한 스코어를 계산하는 지 여부에 따라 쿼리 문맥과 필터 문맥으로 나뉜다.
Query Context
문서가 주어진 검색 조건을 얼마나 더 잘 만족하는지에 따라 유사도 점수를 매긴다.
match/term쿼리,bool쿼리의must/should조건절 등이 해당된다.
Filter Context
문서가 주어진 검색 조건을 만족하는지 여부만을 참과 거짓으로 따진다.
exists/range쿼리,bool쿼리의filter/must_not조건절 등이 해당된다.
조건을 만족하는지 여부만이 중요하고 최종 검색 결과에서 랭킹에 영향을 주기 위해 유사도 점수를 매길 필요가 없는 경우는 필터 문맥으로 검색해야 성능상 유리하다. 점수를 계산하는 비용을 아낄 수 있고, 내부적으로 검색 결과가 쿼리 캐시에 저장되어 재활용 가능하다.
AWS Opensearch
AWS로 배포환경을 구성하는 경우 AWS Opensearch를 사용하여 배포할 수 있다. Opensearch는 Elasticsearch 라이센스 문제로 인해 Elasticsearch 7.1 버전에서 Fork되어 나온 프로젝트이다.
Opensearch 버전에 따라 지원하는 플러그인에 차이가 있어서 사전에 배포 환경을 확인하고 개발할 필요가 있다. Amazon OpenSearch Service의 엔진 버전별 플러그인
| 플러그인 | 필요한 최소 Opensearch 버전 |
|---|---|
| Seunjeon 한국어 분석 | 1.0 |
| Nori 한국어 분석 | 1.3 |
기존의 MonggoDB에 document가 insert되거나 update되면, 내부 CDC 핸들러에서 해당 데이터를 카프카 메세지 payload로 전달하여 Elasticsearch에 싱크하는 방식으로 운영 가능하다.
References
엘라스틱서치 바이블
역색인(Inverted indexing)
Elasticsearch: Software Engineer, You’ve Got to Master Analysis.
[MLOps] Elasticsearch 쿼리 DSL (1) - Leaf Query(full text, term, range)
