sequence model
시퀀스 모델이란 시퀀스 데이터를 입력으로 받은 후 모델에서 연산을 거쳐 시퀀스 데이터의 결과를 생성하는 모델이다.
이러한 시퀀스 모델에는 LSTM, seq2seq 등이 사용되었는데, 해당 모델들은 모든 데이터를 한번에 처리하는 것이 아닌 시퀀스 포지션에 따라 순차적으로 처리가 된다. 따라서 길이가 긴 시퀀스 데이터를 처리하는 경우, 메모리에 큰 부담이 생길 수 있다.
model architecture
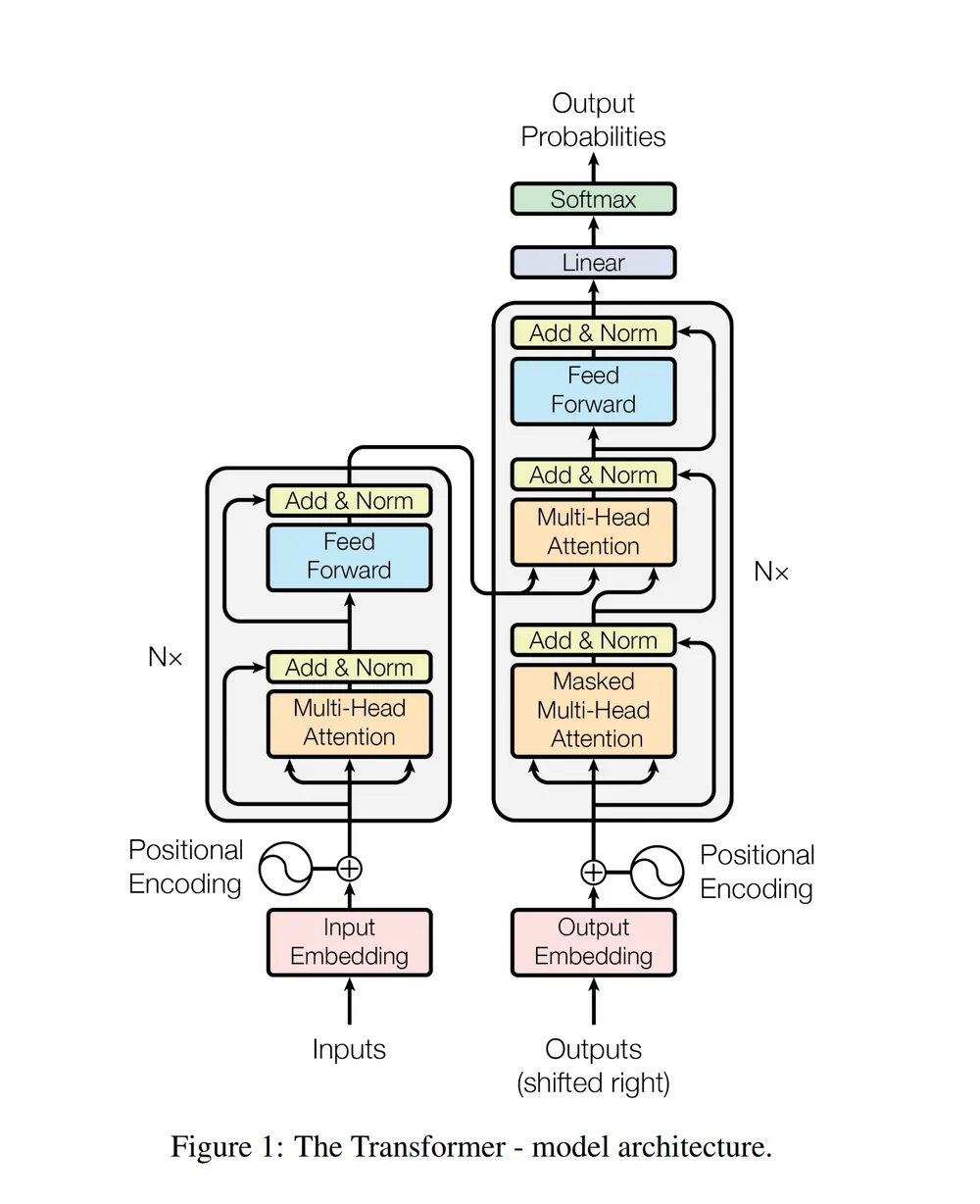
왼쪽의 큰 박스는 인코더로 1개의 multi head attention과 feed forward로 구성되어 있다.
오른쪽의 큰 박스는 디코더로 2개의 multi head attention과 feed forward로 구성되어 있다.
Attention
트랜스포머 모델은 어텐션을 이용하여 시퀀스 데이터를 처리한다.
어텐션이란 같은 문장 내에서 단어들 간의 관계를 나타내며, Q,K,V 를 이용해 어텐션 벨류를 구할 수 있다.
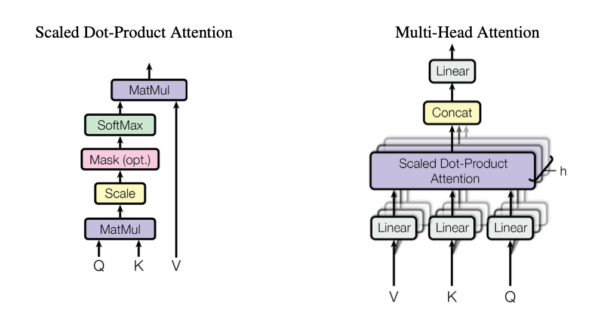
왼쪽 그림은 하나의 어텐션을 표현한 것으로 Q,K를 내적한 후 정규화, 소프트 맥스 등을 적용한 후 V과 내적을 하여 최종 결과를 도출한다.
오른쪽 그림은 multi head attention으로 용도에 따라 다르게 학습된 여러 어텐션을 합친 구조이다.
Positional Encoding
어텐션을 이용해 시퀀스 데이터의 유사도를 계산하고 결과를 도출할때, 어텐션은 시퀀스 데이터의 순서를 고려하지 않으므로 문제가 발생할 수 있다. 따라서 positional encoding을 사용하여 데이터에 순서를 부여한다.

@~@