RAID 개념 및 종류
RAID(Redundant Array of Independent Disk &Redundant Array of Inexpensive Disk)
독립된 디스크의 복수 배열, 저렴한 디스크의 복수 배열
여러개의 디스크를 묶어 하나의 디스크처럼 사용하는 기술이다.
RAID를 사용했을때 기대 효과
- 대용량의 단일 볼륨을 사용하는 효과.
- 디스크I/O 병렬화로 인한 성능 향상(RAID 0 RAID 5 RAID 6등)
- 데이터 복제로 인한 안전성 향상(RAID 1)
RAID는 컴퓨터를 구성하는 부품들 중 기계적인 특성 때문에
상대적으로 속도가 느린 하드디스크를 보완하기 위해 만든 기술이다.
RAID LEVEL
구성하는 디스크의 갯수가 같아도, RAID의 구성 방식에 따라 성능, 용량이 바뀌게 된다.
STANDARD RAID LEVEL
기본적인 RAID LEVEL이다.
RAID 0 ~ RAID 6
💨 RAID를 구성하는 디스크의 종류와 크기는 같다고 가정한다.
💨 성능의 경우 RAID 컨트롤러의 연산으로 인한 성능 저하는 제외하고, Sequential I/O 시만 가정하겠습니다.
💨 RAID를 구성하는 디스크의 개수는 N으로 표현하겠습니다.
RAID 0 STRIPING
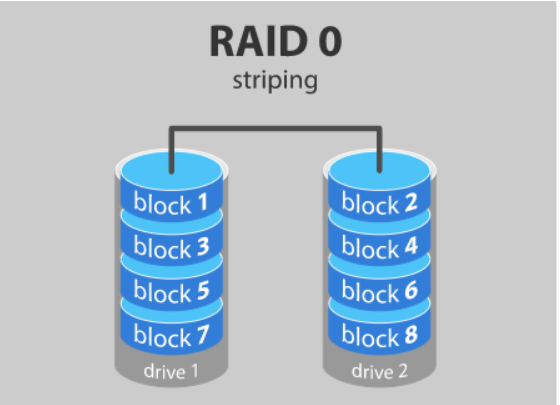
◻ RAID 0을 구성하기 위해서는 최소 2개의 디스크가 필요하며, 구성하는 모든 디스크에 데이터를 분할하여 저장합니다.
◻ 전체 디스크를 동시에 사용하기 때문에 성능은 단일 디스크의 성능의 N배이다.
◻ 용량역시 단일 디스크의 용량의 N배가 된다.
BUT
◻ 문제가 발생할경우 전체 RAID가 깨지는 상황이 발생한다.
◻ 안정성은 1/N으로 줄어든다.
=>실제 거의 사용하지 않음.
RAID 1 MIRRORING
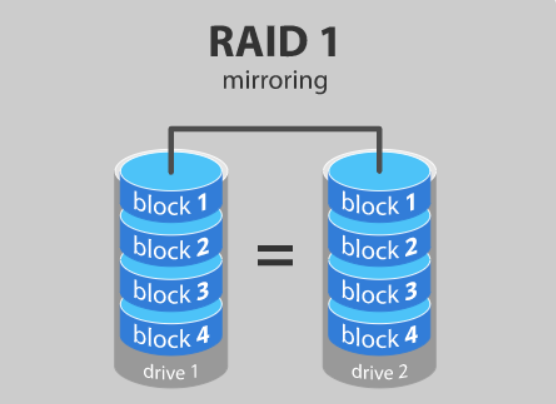
최소 2개 이상의 디스크가 필요하다.(MIN(N)==2)
◻ RAID 컨트롤러에 따라서 2개의 디스크로만 구성 가능할수도 있고, 그 이상의 개수를 사용하여 구성할 수도 있다.
◻ 모든 디스크에 데이터를 복제하여 기록하는데, 당연히 데이터의 중복이 있고 사용가능한 용량은 단일 디스크 용량과 같다.
◻ WRITE 시엔 데이터를 복제해서 기록하므로, 단일 디스크보다 성능이 낮을수도 있다.
◻ 하지만 READ시에는 N배의 성능이 나온다. 또한 안정성이 높다.
💨 비용 문제로 인해 잘 사용하지 않는다.
RAID 2
현재는 사용하지 않는 RAID LEVEL
◻ BIT 단위로 STRIPING을 하고 ERROR CORRECTION을 위해 Hamming code를 사용한다.
◻ m+1개의 데이터 디스크와 m개의 패리티 디스크로 구성된다.(최소 3개)
◻ 1개의 디스크 에러 시 복구 가능하다.(2개 이상은 복구 불가능)
RAID 3
현재는 사용하지 않는 LEVEL
◻ Byte 단위로 striping을 하고, error correction을 위해 패리티 디스크를 1개 사용한다.
◻ 용량 및 성능이 단일 디스크 대비 (N-1) 배 증가한다.
◻ Byte 단위로 striping 하기 때문에 너무 작게 쪼개져 현재는 사용하지 않는다
◻ 최소 3개의 디스크로 구성 가능하다.그리고 1개의 디스크 에러 시 복구 가능하다. (2개 이상의 디스크 에러 시 복구 불가능)
RAID 4
현재는 거의 사용하지 않는 RAID LEVEL
◻ Block 단위로 striping을 하고, error correction을 위해 패리티 디스크를 1개 사용합니다.
◻ 용량 및 성능이 단일 디스크 대비 (N-1) 배 증가하며, 최소 3개의 디스크로 구성 가능하다.
그리고 1개의 디스크 에러 시 복구 가능하다. (2개 이상의 디스크 에러 시 복구 불가능)
◻ Block 단위로 striping 하는 것은 RAID 5, RAID 6와 동일하지만,패리티 코드를 동일한 디스크에 저장하기 때문에,패리티 디스크의 사용량이 높아 해당 디스크의 수명이 줄어든다고 한다.RAID 4의 단점을 개선시킨 것이 RAID 5이다.
RAID 5
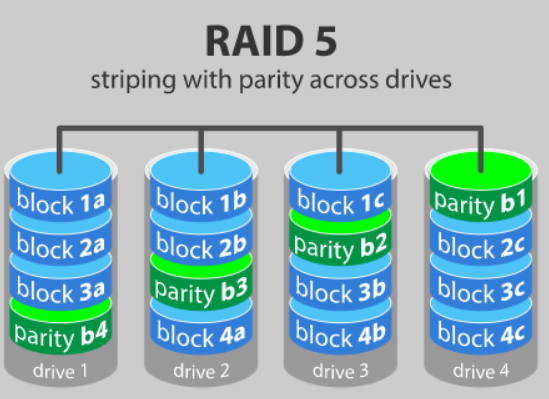
제일 사용빈도가 높은 RAID LEVEL
◻ Block 단위로 striping을 하고, error correction을 위해 패리티를 1개의 디스크에 저장하는데,패리티 저장 하는 디스크를 고정하지 않고, 매 번 다른 디스크에 저장한다.
◻ 용량 및 성능이 단일 디스크 대비 (N-1) 배 증가한다.
◻ 최소 3개의 디스크로 구성 가능하며, 1개의 디스크 에러 시 복구가 가능하다. (2개 이상의 디스크 에러 시 복구 불가능)
RAID 0에서 성능, 용량을 조금 줄이는 대신 안정성을 높인 RAID Level이다.
RAID 6
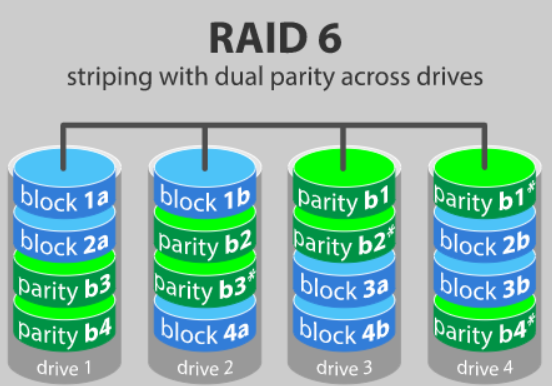
◻ RAID 5에서 성능, 용량을 좀 더 줄이고, 안정성을 좀 더 높인 RAID Level 이다.
◻ Block 단위로 striping을 하고, error correction을 위해 패리티를 2개의 디스크에 저장하는데,패리티 저장 하는 디스크를 고정하지 않고, 매 번 다른 디스크에 저장한다.
◻ 용량 및 성능이 단일 디스크 대비 (N-2) 배 증가하며, 최소 4개의 디스크로 구성 가능하다.
◻ 그리고 2개의 디스크 에러 시 복구 가능합니다. (3개 이상의 디스크 에러 시 복구 불가능)RAID 5에서 성능, 용량을 조금 줄이는 대신 안정성을 높인 RAID Level이라 보면된다.
◻ 조금 더 안정성을 높여야 하는 서버 환경에서 주로 사용합니다.
+@ Nested RAID (중첩 RAID)
Nested RAID는 Standard RAID를 여러개 중첩하여 사용합니다.
즉, 복수의 Standard RAID 를 또 RAID로 묶습니다.
2개의 RAID 0를 RAID 1로 묶습니다. (RAID 0+1 혹은 RAID 01)
2개의 RAID 1을 RAID 0으로 묶을 수도 있습니다. (RAID 1+0 혹은 RAID 10)
극단적으로 2개의 RAID 1를 묶은 RAID 0 2개를 RAID 0로 묶는 경우도 있는것 같다. (RAID 10+0)
+@ STRIPE SIZE
RAID 컨트롤러와 단일 디스크간의 I/O단위이다.
💨최적의 성능을 내기위해 고려사항.
64KB, 128KB, 256KB, 512KB, 1024KB 중 선택
+@ STRIPING
하나의 DISK에 모두 기록할 수 없는 DATA를 여러개의 DISK에 분배 기록할 수 있는 기술 큰 용량을 만들어 사용하는데 이용한다.
+@ MIRRORING
장애 발생요인을 거울처럼 하나의 DISK를 또다른 DISK에 동시에 기록하는 기술.
하나의 DISK가 FAULT가 되어도 미러된 DISK로 DATA를 안전하게 관리할 수 있다.
+@PARITY(패리티)
DATA의 오류검출 확인헤 사용되는 기술
파일시스템의 기능(목적) 및 종류
파일 시스템
- 컴퓨터에서 파일이나 자료를 쉽게 발견 할 수 있도록, 유지, 관리하는 방법이다.
즉, 저장매체에는 많은 파일이 있으므로, 이러한 파일을 관리하는 방법을 말한다.
-
사용자 영역이 아닌 커널 영역에서 동작
-
파일을 빠르게 읽기, 쓰기, 삭제 등 기본적인 기능을 원활히 수행하기 위한 목적
파일 시스템 특징
-
계층적 디렉터리 구조를 가진다.
-
디스크 파티션 별로 하나씩 둘 수 있다.
파일 시스템의 역할
-
파일관리 : 파일 저장, 참조, 공유
-
보조 저장소 관리 : 저장 공간 할당
-
파일 무결성 메커니즘 : 파일이 의도한 정보만 포함하고 있음을 의미
-
접근 방법 : 저장된 데이터에 접근할 수 있는 방법 제공
파일 시스템 개발 목적
-
HDD와 메인 메모리 속도차 줄이기
-
파일 관리 용이
-
HDD의 막대한 용량을 효율적으로 이용
주요 파일 시스템
Windows : FAT(FAT12/16/32,exFAT), NTFS
Linux : ext(ext2/3/4)
Mac OS : HFS, HFS+
Google : GFS
*GFS : Google File System으로 구글에서 사용하는 분산 파일 시스템
파일 시스템 구조
-
메타 영역과 데이터 영역 두가지 영역으로 구분이 된다.
-
메타 영역 : 데이터 영역에 기록된 파일의 이름, 위치, 크기, 시간정보, 삭제유무 등 파일의 정보
-
데이터 영역 : 파일의 데이터
- 윈도우 탐색기를 이용하여 검색할때 메타 영역을 탐색하면서 파일을 찾는다.
데이터의 계층구조
정의
- 필드(FIELD) 상호관련있는 문자들의 집합.
- 레코드(RECORD) 서로 관련이 있는 필드들의 집합.
->레코드 키 : 어떤 레코드를 다른 레코드로부터 식별하는데 사용되는 제어 필드- 파일(FILE): 상호 관련 있는 레코드들의 집합.
- 데이터베이스: 상호 관련 있는 파일들로 구성.
참고
