API 를 활용하여 Youtube채널 영상 데이터 가져오기
Colab Page
1. 활용 데이터
YouTube Data API v3
- 리소스
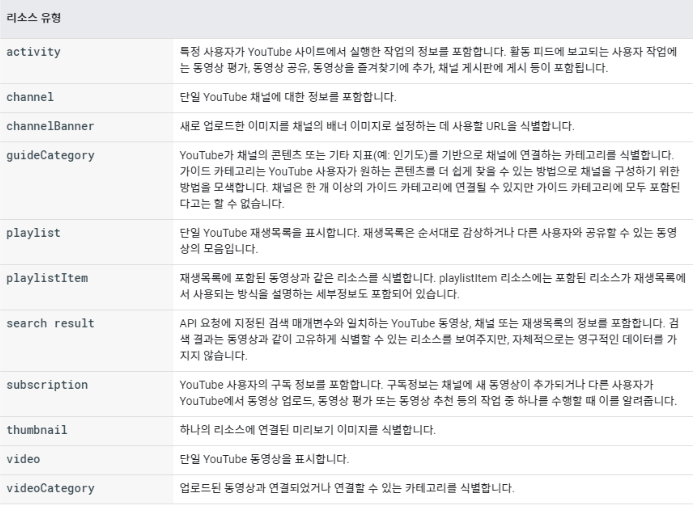
리소스 유형
기본 메서드

- YouTube Search API 리소스
| 속성 | 설명 |
|---|---|
| CommentThreads | 댓글 정보에 대한 스레드. topLevelComment 와 topLevelComment 의 댓글은 실제로 comment 리소스에 중첩된 commentThreads 리소스. 리소스에는 주석에 대한 모든 응답이 commentThreads에 포함되어 있지 않아도 되며 comments.list특정 주석에 대한 모든 응답을 검색하려면 이 방법을 사용해야 한다. |
| Comments | 단일 YouTube 댓글에 대한 정보. comment리소스는 비디오나 채널에 대한 댓글을 나타낼 수 있다. 주석은 최상위 주석 또는 최상위 주석에 대한 응답. |
| maxResults | 최대 호출 개수 |
| nextPageToken | pageToken 매개변수 값. 다음페이지를 검색할 수 있는 토큰 |
| snippet | 댓글에 대한 기본 정보 |
| textDisplay | 댓글의 텍스트 |
| authorDisplayName | 댓글 작성자 |
| publishedAt | 작성 시간 |
| likeCount | 좋아요 수 |
| topLevelComment | 스레드의 최상위 주석. 속성 값은 comment리소스 |
| totalReplyCoun | ‘topLevelComment’ 대한 응답으로 제출된 총 응답 수 |
| replies | 주석에 대한 응답 목록이 있는 경우 이를 포함하는 컨테이너 속성은 주석 목록 자체 .replies.comments |
참고자료 - Google Developers > YouTube Data API
https://developers.google.com/youtube/v3/docs/comments
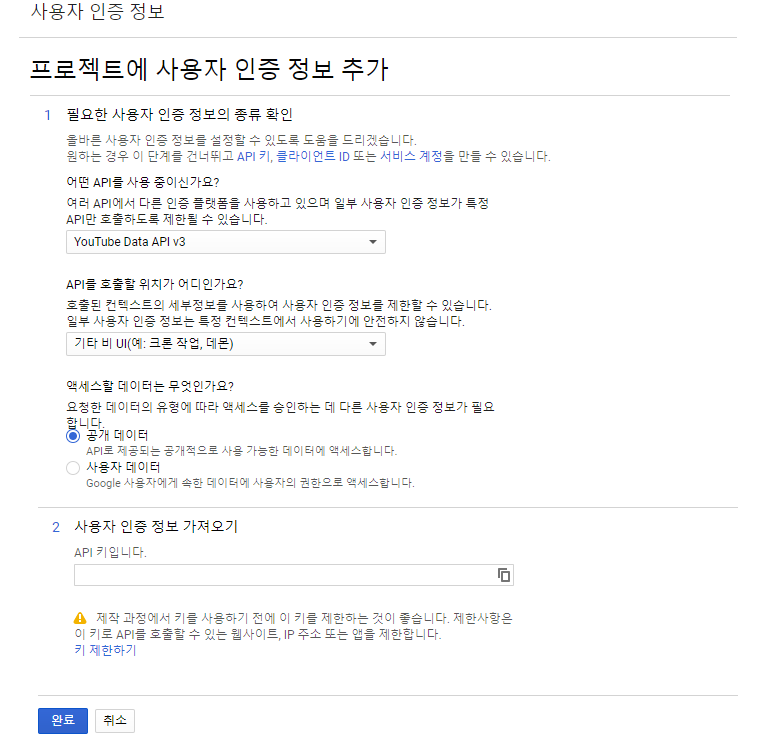
- YouTube API 발급 받기
-
Youtube Data API(v3) : 유튜브와 관련된 기본적인 API로, 동영상을 업로드하거나 재생목록을 관리하는 등의 가장 기본적인 기능 제공
-
Youtube Analytics API : 유튜브의 동영상 및 채널에 대한 시청 통계, 인기도 통계 등 검색
-
Youtube Livestreaming API : 유튜브 방송을 예약하고 , 라이브 스트림을 관리
⇒ 댓글 수집 및 자료 추출을 위해
Youtube Data API(v3)를 활용하였다.
- Youtube API 발급 받는 방법 참고 - https://joypinkgom.tistory.com/28
- 구글 계정 생성
- 구글 클라우드 플랫폼(GCP)에 프로젝트 등록하기 (https://console.cloud.google.com
) - 라이브러리에서 youtube api 검색 - youtube data api(v3)
- 사용자 인증 추가
- 완료 후 API key 확인하기
-
- 할당량 제한 안내 YouTube API는 무료이지만 할당량이 제한 되어 있어 요청을 보낼 때 마다 차감된다. (Qutoas) 일일 요청한도가 10,000 포인트, 1분당 요청한도 1,600 포인트로 설정되어있다.
- 하루에 영상을 100페이지 초과해서 데이터를 가져오거나, 1분 동안 동영상을 1개 초과해서 동영상을 추가할 수 없다.
- 예시

요청 한도를 초과한 후 요청을 보내면 아래와 같은 상태코드 403의 응답을 받게 된다.
{
"error": {
"code": 403,
"message": "The request cannot be completed because you have exceeded your <a href=\"/youtube/v3/getting-started#quota\">quota</a>.",
"errors": [
{
"message": **"The request cannot be completed because you have exceeded your <a href=\"/youtube/v3/getting-started#quota\">quota</a>.",
"domain": "youtube.quota",**
"reason": "quotaExceeded"
}
]
}
}- 요청별 할당량 테이블
https://developers.google.com/youtube/v3/determine_quota_cost
2. 코드 리뷰
Setting
라이브러리 불러오기
# 필요한 라이브러리 import
import numpy as np
import pandas as pd
import requests
import json
from datetime import datetime as dt
from tqdm import tqdm
import time
from googleapiclient.discovery import build
import os
import warnings # 경고창 무시
warnings.filterwarnings('ignore')
# 시각화를 위한 라이브러리
from wordcloud import WordCloud # 워드클라우드 호출
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter # 텍스트 및 빈도수 추출
**from konlpy.tag import Okt** # 한국어 형태소 분석 패키지
from PIL import Image # 워드클라우드 원하는대로 그리기 # 시각화를 위한 폰트 및 한국어 형태소 분류 모듈 설치
# !apt-get update -qq
# !apt-get install fonts-nanum* -qq
# !pip install konlpyAPI 요청 key 값 세팅
# 쿼리값 세팅
# 인증키는 보안의 문제로 “*” 처리하였습니다
API_KEY = "*"
DEVELOPER_KEY = API_KEY
YOUTUBE_API_SERVICE_NAME = "youtube"
YOUTUBE_API_VERSION = "v3"
youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY)
# csv 파일 생성 함수
# 수집할 채널 또는 영상의 이름과 현재날짜를 file_name으로 합니다.
def save_file(name, type_ ,df):
today = dt.today().strftime("%Y%m%d")
file_name = f'Youtube_{type_}_{name}_{today}'
# version 관리
version = 0
while os.path.isfile(f'./{file_name}_v{version}.csv'):
version += 1
df.to_csv(f'./{file_name}_v{version}.csv', index=False)YouTube Search API
- 영상 데이터 정보 수집하기
입력받은 유튜브 채널의 Id 를 가져오는 함수
# 한 횟수씩 데이터를 받아오는 함수입니다.
# 가져오는 반환 타입이 JSON, XML 일 경우로 나누어 데이터 프레임을 만듭니다.
# 만약 가져오는 데이터가 없을 시 빈 데이터 프레임 값을 넘깁니다.
def get_channel(channel_name, api_key):
global youtube
# 구글 Search API를 사용해서 입력한 채널의 정보를 가져온다.
# search_response dictionary 객체를 반환한다.
search_response = youtube.search().list(
q = channel_name,
order = "relevance",
part = "snippet",
maxResults = 50
).execute()
channel_Id = search_response['items'][0]['id']['channelId']
# search_response dictionary 객체를 반환한다.
return channel_Id영상 수집 시 페이지를 넘기는 함수
# 한 횟수씩 데이터를 받아오는 함수입니다.
# 가져오는 반환 타입이 JSON, XML 일 경우로 나누어 데이터 프레임을 만듭니다.
# 만약 가져오는 데이터가 없을 시 빈 데이터 프레임 값을 넘깁니다.
# 모든 데이터 내용을 가져오는 함수
def scroll(channel_Id):
video_list = []
# 스크롤이 되지 않을 때까지 nextpageToken 무한 호출
try :
res = youtube.channels().list(id=channel_Id, part='contentDetails').execute()
# 플레이리스트 가져오기
playlist_id = res['items'][0]['contentDetails']['relatedPlaylists']['uploads']
next_page = None
# 영상 개수가 1000이 넘지 않도록 수집
while len(video_list) < 1000:
# print(len(video_list))
# 다음 페이지의 Token 반환
res = youtube.playlistItems().list(playlistId=playlist_id,part='snippet',maxResults=50,pageToken=next_page).execute()
video_list += res['items']
next_page = res.get('nextPageToken')
if next_page is None :
break
# 영상 JSON 데이터 리스트 반환
return video_list
except Exception as e:
print('API 호출 한도 초과') # API 할당량 초과 예외처리
return video_list입력받은 유튜브 영상의 Id 목록을 가져오는 함수
def get_video_id(channel_name, api_key):
global youtube
channel_Id = get_channel(channel_name, api_key)
video_list = scroll(channel_Id)
df_video = pd.DataFrame() 다시
for item in video_list:
item_dict = {}
# 제목과 video_key 반환
item_dict['video_id'] = item['snippet']['resourceId']['videoId']
df_video = df_video.append(item_dict , ignore_index = True)
# df 객체 반환
return df_video.to_list()입력받은 유튜브 채널의 영상 목록과 정보를 수집하는 함수
def get_channel_info(channel_name, api_key , name):
global youtube
df_video_info = pd.DataFrame()
df_url = get_video_id(channel_name, api_key)
url_list = df_url['video_id'].to_list()
try :
for video_id in url_list:
item_list = {}
res = youtube.videos().list(id = video_id, part='snippet,contentDetails,statistics').execute()
if res['items']:
item_list['video_id'] = video_id
item_list['title'] = res['items'][0]['snippet']['title']
# 'publishedAt': '2022-09-30T15:05:02Z'
item_list['date'] = res['items'][0]['snippet']['publishedAt'].split('T')[0]
# 통계지표 가져오기
# NaN값은 0으로 간주
item_list['view'] = int(res['items'][0]['statistics']['viewCount']) if 'viewCount' in res['items'][0]['statistics'] else 0
item_list['likecnt'] = int(res['items'][0]['statistics']['likeCount']) if 'likeCount' in res['items'][0]['statistics'] else 0
item_list['comment'] = int(res['items'][0]['statistics']['commentCount']) if 'commentCount' in res['items'][0]['statistics'] else 0
df_video_info = df_video_info.append(item_list, ignore_index = True).reset_index(drop=True)
# save data
df_video_info['channel_name'] = channel_name
save_file(name,'video', df_video_info)
return df_video_info
except Exception as e:
print('DataFrame 생성 에러')
return df_video_info💡 코드 실행 방법
# 공식 채널명
channel = ''
# 파일로 저장할 때 쓰일 채널네임
name = ""
df_channel_info = get_channel_info(channel, API_KEY, name)
df_channel_info
```
> **채널의 가장 인기있는 영상 TOP10**
>
>
> ```python
> df_channel_info.sort_values(by=["view","likecnt","comment"], ignore_index=True, ascending = False)[:10]- 영상 내 댓글 데이터 수집하기
입력받은 유튜브 영상 url을 활용하여 댓글 수집하기
# 영상 하나의 url에 대한 댓글 데이터를 모둗 받아오는 함수입니다.
# nextpageToken을 반환받아 다음 페이지를 계속 탐색합니다.
# 만약 가져오는 데이터가 없을 시 빈 데이터 프레임 값을 넘깁니다.
def get_comments(video_id, video_name ,API_key):
global youtube
comments = []
cnt = 0
comment_list_response = youtube.commentThreads().list(
videoId = video_id,
order = 'relevance',
part = 'snippet,replies',
maxResults = 100
).execute()
while comment_list_response:
for item in comment_list_response['items']:
comment = item['snippet']['topLevelComment']['snippet']
comments.append([comment['textDisplay'], comment['authorDisplayName'], comment['publishedAt'], comment['likeCount']])
if item['snippet']['totalReplyCount'] > 0:
for reply_item in item['replies']['comments']:
reply = reply_item['snippet']
comments.append([reply['textDisplay'], reply['authorDisplayName'], reply['publishedAt'], reply['likeCount']])
if 'nextPageToken' in comment_list_response:
comment_list_response = youtube.commentThreads().list(
videoId = video_id,
order = 'relevance',
part = 'snippet,replies',
pageToken = comment_list_response['nextPageToken'],
maxResults = 100
).execute()
cnt += 1
else:
break
comment_df = pd.DataFrame(comments, columns = ["comment", "author", "datetime", "like_count"]).dropna()
print(f"총 {cnt} page의 댓글을 수집했습니다.")
print(f"총 {len(comment_df)}개의 댓글을 수집했습니다.")
save_file(video_name, "comment" ,comment_df)
return comment_df💡 코드 활용 예시
특정 영상의 댓글 데이터 수집하기
# csv 파일 load
data =pd.read_csv(f'{파일명}.csv', dtype={"itemcode":"object"})
video_id = df['video_id'][0]
video_name = df['title'][0]
# video_id를 입력받아 댓글 데이터 수집하기
df_comment = get_comments(video_id, video_name ,API_KEY)Visualization
각 채널의 성장 지표 시각화
IT유튜브 채널 성장지표비교
CSV 파일 불러오기
# 시각화 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
df_no = pd.read_csv("./data/Youtube_scrap_노마드코더_2022-10-03_v0.csv")
df_dong = pd.read_csv("./data/Youtube_scrap_동빈나_2022-10-03_v0.csv")
df_saeng = pd.read_csv("./data/Youtube_scrap_생활코딩_2022-10-03_v0.csv")
df_jo = pd.read_csv("./data/Youtube_scrap_조코딩_2022-10-03_v0.csv")데이터프레임 합치기
df_all = pd.concat([df_no, df_dong, df_saeng, df_jo])
df_all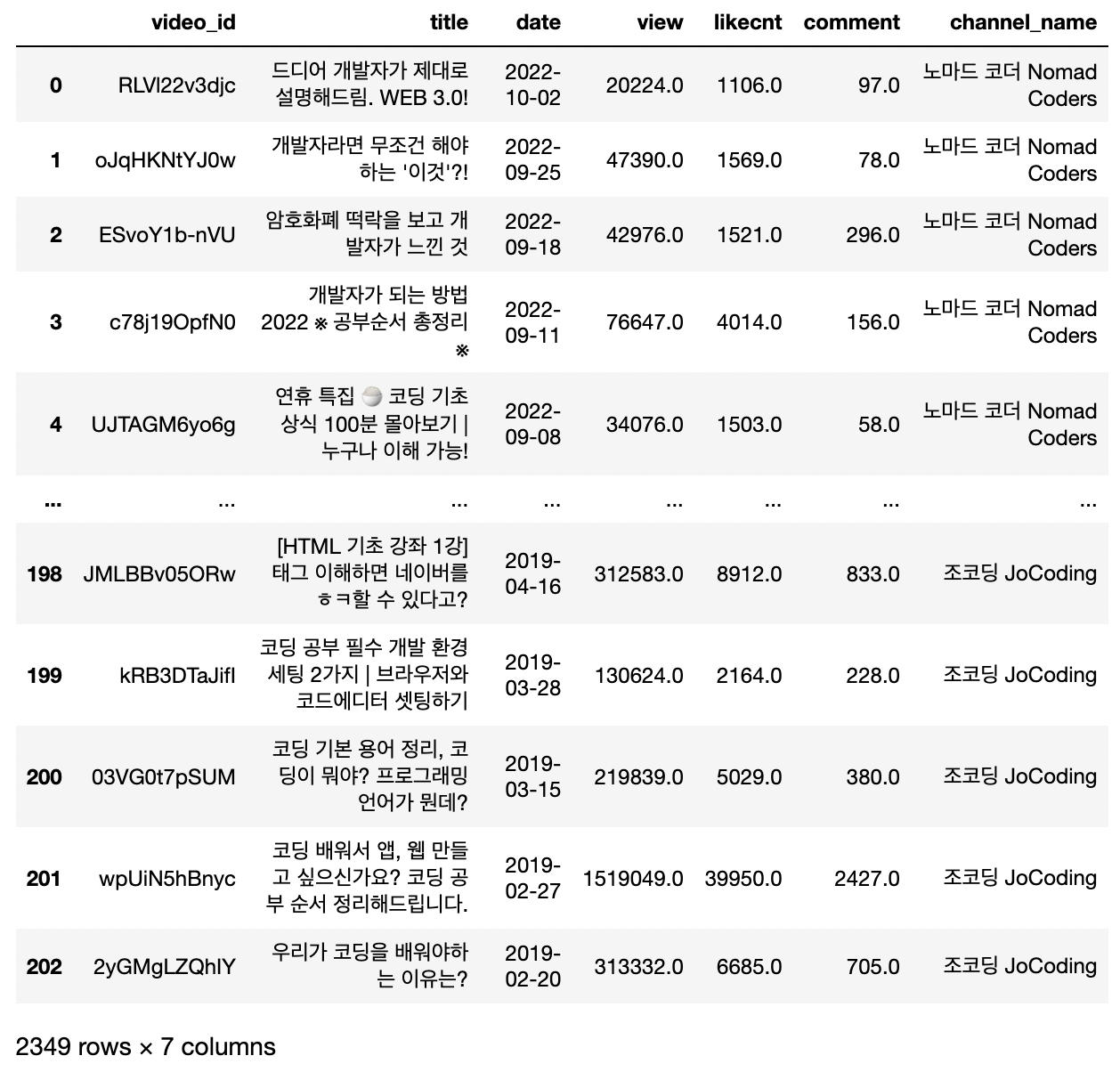
“date” 컬럼에서 파생변수 “year” 추출
# type을 object에서 datetime으로 변경
df_all["date"] = pd.to_datetime(df_all["date"])
# 연도 파생변수 추출
df_all["year"] = df_all["date"].dt.year
df_all.head(2)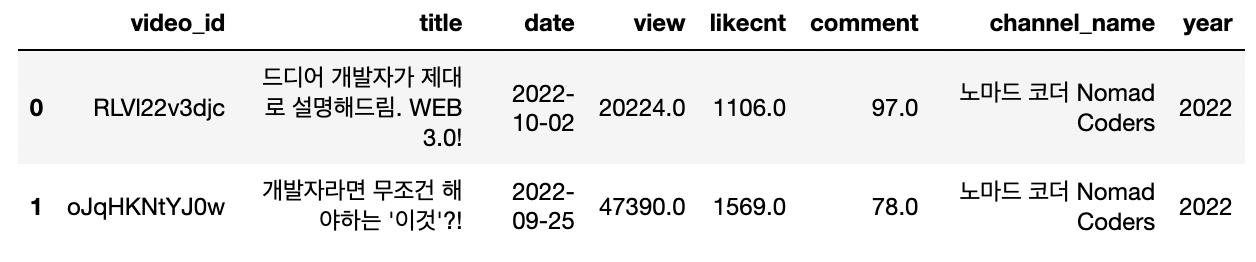
year, channel_name 기준 합계 그룹화
df_all_group = df_all.groupby(["year", "channel_name"]).sum()
df_all_group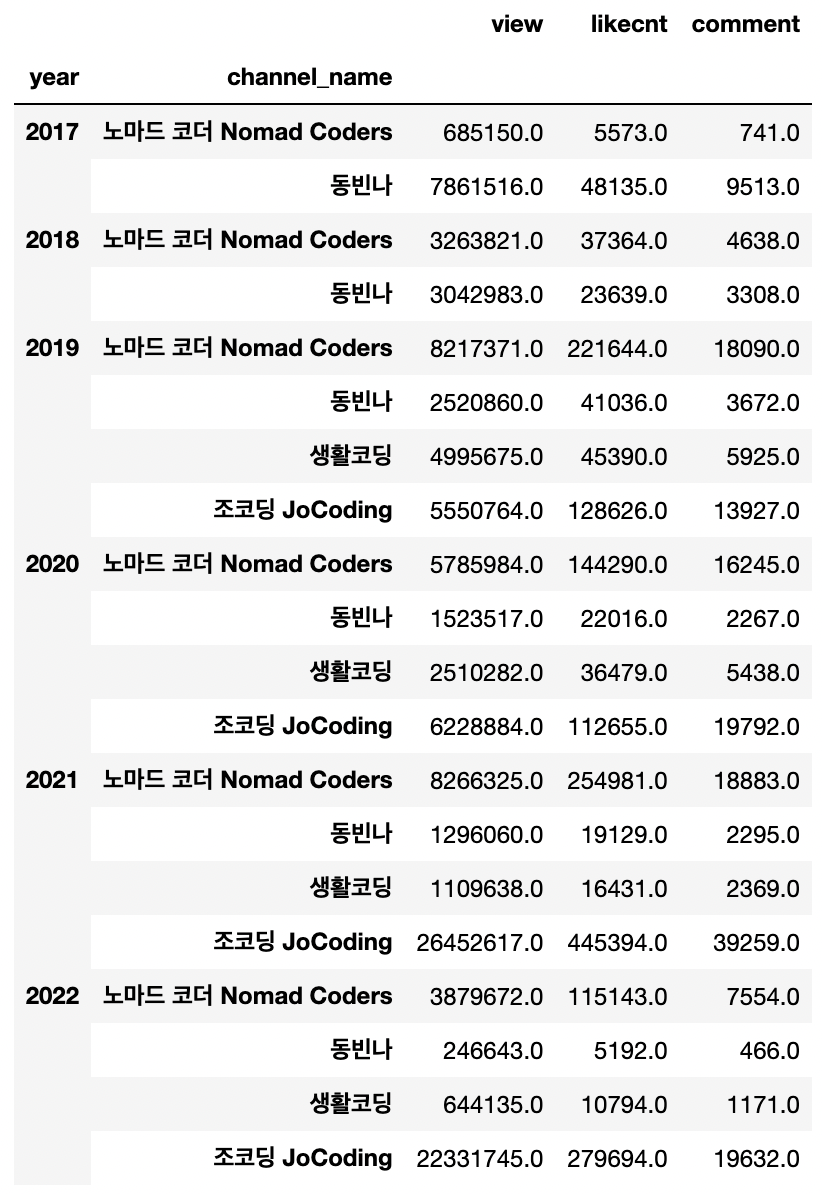
연도별 조회 수 시각화
sns.lineplot(data=df_all_group, x="year", y="view", hue="channel_name")연도별 좋아요 수 시각화
sns.lineplot(data=df_all_group, x="year", y="likecnt", hue="channel_name")연도별 댓글 수 시각화
sns.lineplot(data=df_all_group, x="year", y="comment", hue="channel_name")주요 키워드 워드클라우드 시각화
- 자주 나오는 단어를 통한 댓글 유형 파악
워드클라우드 형태로 주요 키워드 시각화
# comment 또는 title 같은 문자형 자료를 수집한 데이터를 탐색하여
# 주요 키워드를 빈도수에 따라 워드클라우드 형태로 시각화합니다.
# 한글 형태소 분석 패키지 konlpy를 사용하여 명사만 추출합니다.
def make_WordCloud(df, column_name):
texts = []
words = []
nouns_words_list = []
okt = Okt()
for i in range(len(df)):
texts.append(df[column_name][i])
for text in texts:
words = okt.nouns(text) # 명사만 추출
nouns_words = [n for n in words if len(n) > 1] # 단어의 길이가 1개인 것은 제외
for nouns_word in nouns_words:
nouns_words_list.append(nouns_word)
c = Counter(nouns_words_list)
font = '/usr/share/fonts/truetype/nanum/NanumGothicEco.ttf' #한글 폰트 반환
wc = WordCloud(font_path = font, width=1000, height=600, scale=2.0, max_font_size=300)
gen = wc.generate_from_frequencies(c)
plt.figure(figsize=(20,20)) # 사이즈 조절
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()💡 코드 활용 예시
조회수, 좋아요 수, 댓글 수를 기준으로 가장 인기 있는 동영상 추출
영상 클릭을 유도하는 주요 키워드 시각화
# 파일 불러오기
df = pd.read_csv('Youtube_동빈나_video_20221003_v0.csv', dtype={"itemcode":"object"})
# 인기도 순 (조회수, 좋아요수, 댓글 수 기준 내림차순) 정렬
df = df.sort_values(by=["view","likecnt","comment"], ignore_index=True, ascending = False)
# comment가 가장 많이 달린 영상 Id 추출
df_top_cmt = df.sort_values(by=['comment'],ascending = False)
video_id =df_top_cmt['video_id'][0]# video_id를 통해 comments 수집
df_comment = get_comments(video_id, video_name ,API_KEY)
# 워드클라우드로 'comment' 주요 키워드 시각화
make_WordCloud(df_comment,'comment')
# 조회수가 평균 이상인 영상 목록의 타이틀 주요 키워드 시각화
df = df[df['view'] > 20000]
make_WordCloud(df,'title')3. 수집한 데이터 및 결과 도출
수집한 데이터 csv 파일
video csv
Youtubescrap노마드코더_2022-10-03_v0.csv
Youtubescrap생활코딩_2022-10-03_v0.csv
Youtubescrap판교뚜벅쵸_20221003_v0.csv
Youtubescrap조코딩_2022-10-03_v0.csv
Youtubescrap동빈나_2022-10-03_v0.csv
Youtube_video_total_20221003_v0.csv
Youtube_김달_video_20221003_v0.csv
comment csv
Youtubecomment일반인이 생각하는 프로그래밍 vs 현실 프로그래밍 #Shorts_20221003_v1.csv
Youtubecomment(JPN SUB) 내가 좋아하는 사람이 나를 좋아하게 만드는 방법_20221003_v0.csv
시각화
Seaborn
- IT 유튜브 채널 성장지표 비교
연도별 조회 수 변화
sns.lineplot(data=df_all_group, x="year", y="view", hue="channel_name")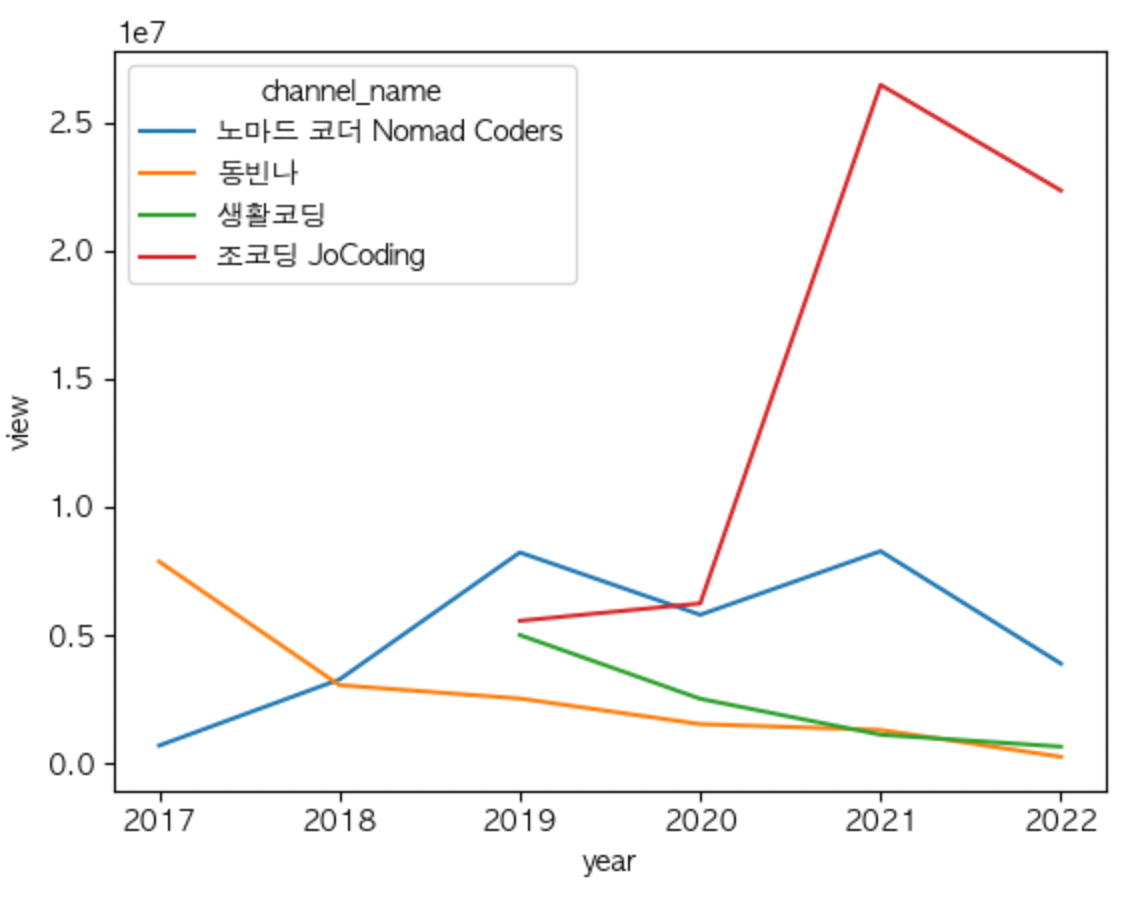
연도별 좋아요 수 변화
sns.lineplot(data=df_all_group, x="year", y="likecnt", hue="channel_name")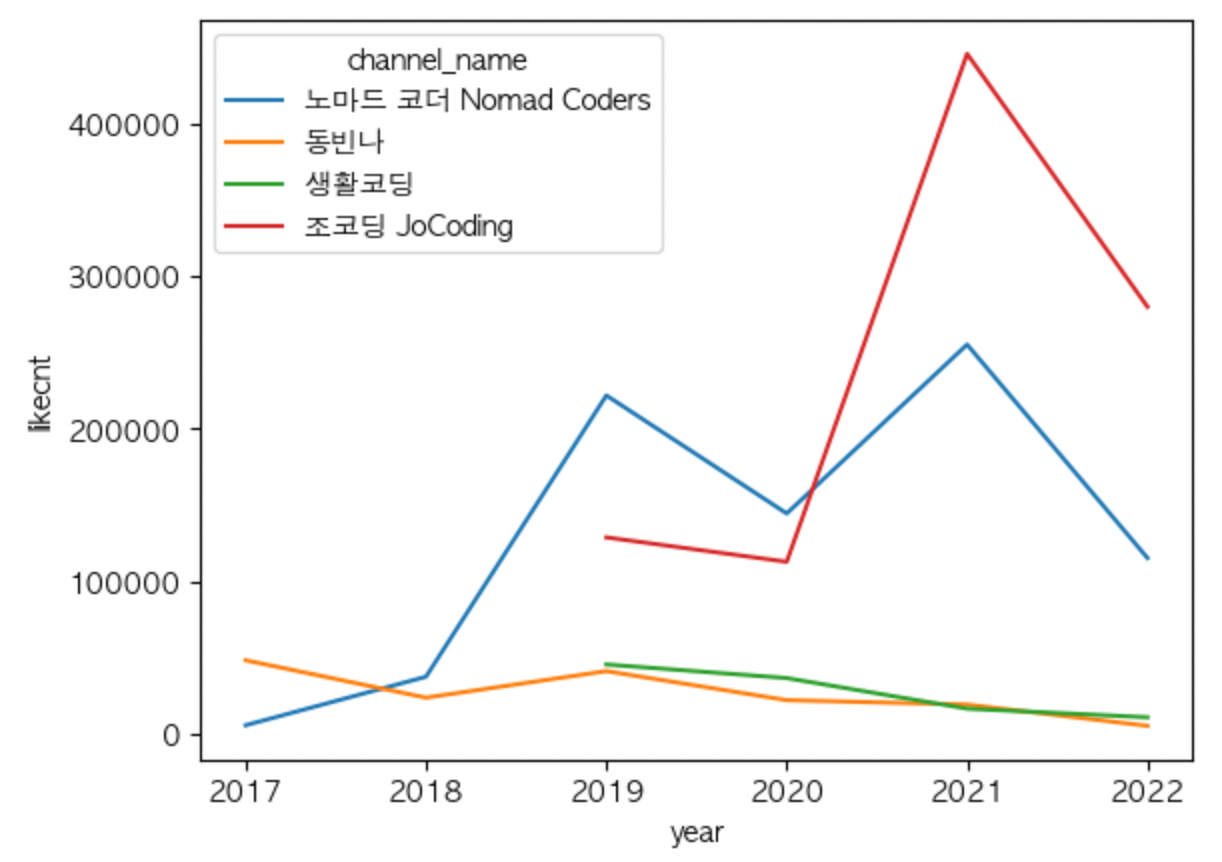
연도별 댓글 수 변화
sns.lineplot(data=df_all_group, x="year", y="comment", hue="channel_name")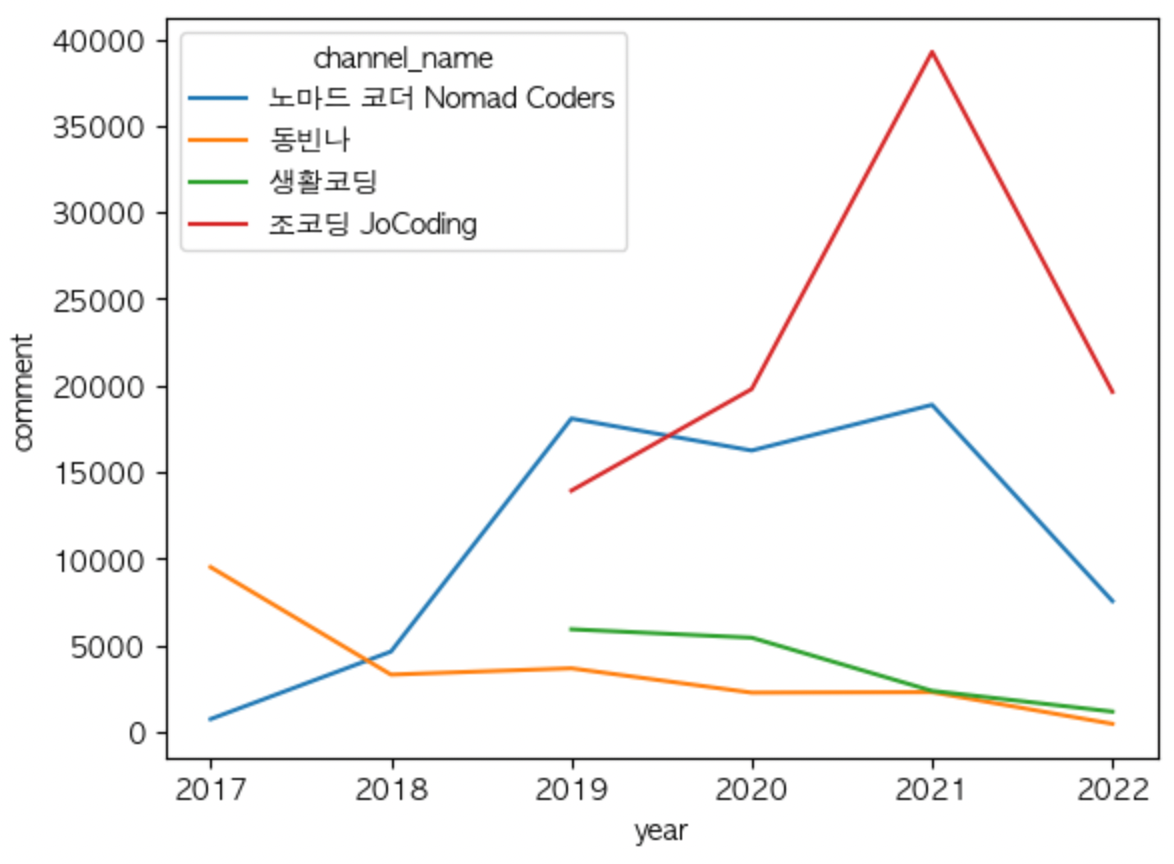
Word Cloud
조은 강사님 채널 오늘코드 💖
- 주요 댓글 키워드

- 조회수 1등 공신! 주요 타이틀 키워드

동빈나 유튜브
- 주요 댓글 키워드
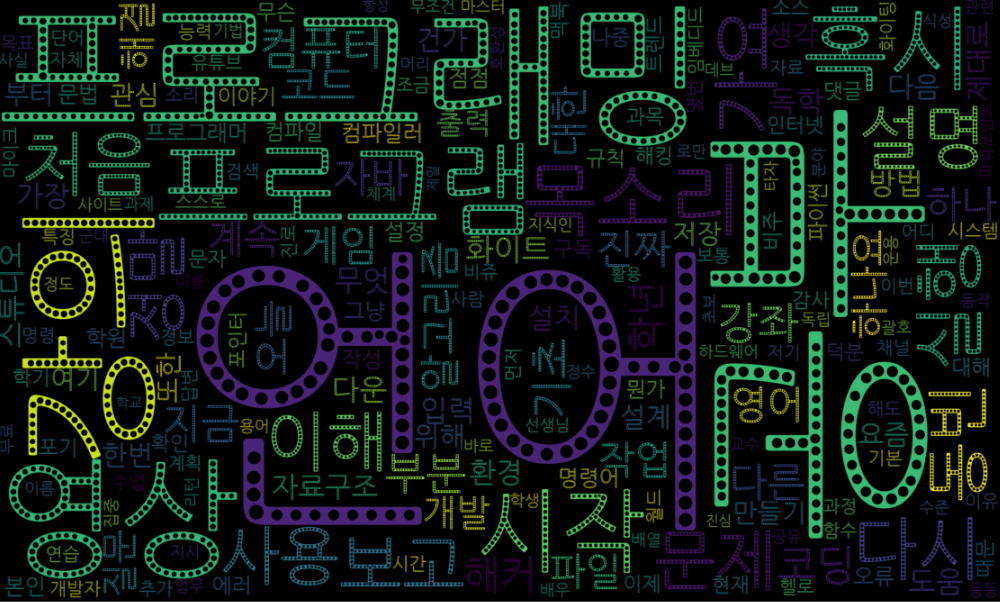
- 조회수가 평균 이상인 영상들의 타이틀 키워드 시각화
make_WordCloud(df[df['view'] > 20000],'title')


유튜브 api 관련해서 찾고 있었는데 도움이 많이되었습니다 ㅎㅎ