
👉 오늘 한 일
- 의약품처방 EDA 복습
- downcast 실습
- parquet 실습
의약품처방 복습
왜 로컬 서버를 사용하지 않고 클라우드 환경을 사용하는가?
- 투자 비용 절감과 개발 환경을 구성하는 시간 단축
- 생산성 증대와 자원의 유연성 향상
코랩 -> 인터넷 연결이 안되어있으면 작업 불가
주피터 -> 인터넷 연결이 안되어있어도 작업 가능
vscode -> .py파일을 편집하기 위해 사용
주피터는 vscode의 익스텐션보다 jupyter notebook을 사용하는 것을 권장
django, flask <=> streamlit
웹상에서 데이터 시각화와 대시보드 작성
히스토그램에서 어떻게 범주형인지 수치형인지 구분해 볼 수 있을까?
- x축의 연속성
plotly 에서 sns.barplot 처럼 연산을 할 수 있는 그래프는?
- px.histogram
- histfunc 옵션을 이용
downcast
데이터를 불러올 때 메모리 부담을 줄이기
=> 데이터 타입의 변경
- e.g. 최솟값은 666668, 최댓값은 999987 이고 앞으로 음수는 사용하지 않는다고 가정할 때 어떤 데이터 타입을 사용하면 적절할까?
- => uint32
데이터를 불러올 때 컴퓨터 RAM 용량만큼 불러올 수 있는데 더 많은 데이터를 불러와서 분석하거나 모델을 만들기 위해서는 메모리를 효율적으로 사용할 수 있어야 함
downcast : 조건을 만족하는 최소 사이즈의 데이터 타입으로 변경함
- pd.to_numeric()에서 사용
object와 category
-
범주형일때는 category 로 지정하면 메모리를 좀 더 효율적으로 사용할 수 있는데, 이 때 범주의 수가 너무 많다면 적합하지 않음
-
게시글 내용과 같이 범주형이 아닐 경우는 적합하지 않음
dtype을 불러올 때 df[col].dtypes.name 으로 불러오는 이유?
- dtype에서 name값을 가져와 처리하기 위해
- e.g.
df.dtypes[0]=> dtype('uint16')df.dtypes[0].name=> 'uint16'
데이터 타입에 따라 downcast 진행
for col in df.columns:
dtype_name = df[col].dtypes.name # name값을 가져와서 startwith 사용
if dtype_name.startswith("int"):
if df[col].min >= 0:
df[col] = pd.to_numeric(df[col], downcast="unsigned")
else:
df[col] = pd.to_numeric(df[col], downcast="integer")
elif dtype_name.startswith("float"):
df[col] = pd.to_numeric(df[col], downcast="float")
elif dtype_name == "bool":
df[col] = df[col].astype("int8")
elif dtype_name == "object":
df[col] = df[col].astype("category")DB에서는 스키마에 지정을 해서 용량을 관리할 수 있지만 불러온 CSV 파일에는 데이터 형식이 없음
CSV(comma seperated values) : 콤마로 구분된 값
TSC(tab seperated values) : 탭으로 구분된 값
parquet 실습
csv 와 parquet 의 차이점?
- csv : csv는 데이터를 ,으로 데이터를 구분해서 행단위로 저장
- parquet : parquet은 데이터를 열단위로 구분해서 저장
- 열 값은 동일한 데이터 타입이기에 압축에 유리하다 => 저장공간을 효율적으로 사용 가능
- 로그파일은 parquet 형식으로 많이 저장함
- 메타데이터를 포함하기 때문에 데이터 용량이 적으면 오히려 csv보다 용량이 커질 수 있음
메타데이터 : 데이터에 관한 구조화된 데이터로, 대량의 정보 가운데에서 확인하고자 하는 정보를 효율적으로 검색하기 위해 Raw data를 일정한 규칙에 따라 구조화한 정보
압축 효율(read performance)
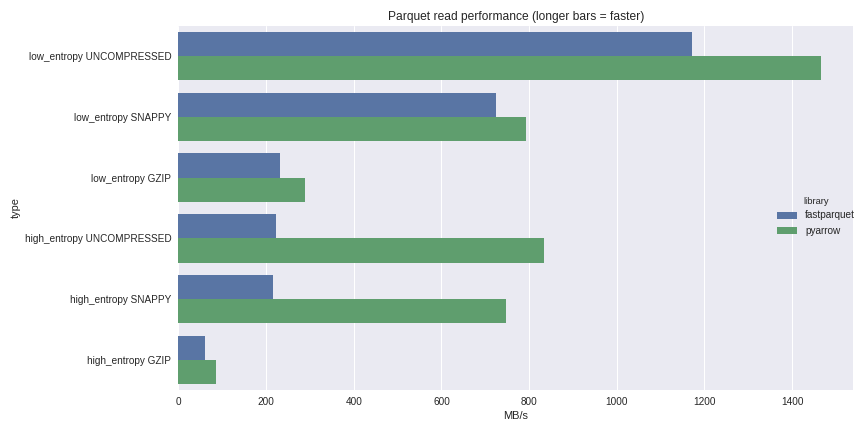
사진 출처 : https://wesmckinney.com/blog/python-parquet-update/
- 어떤 데이터 형식이 들어가냐에 따라서도 압축 효율이 달라짐
- 파일 크기를 다루는 것이기 때문에 불러왔을 때 메모리는 동일함
~막간질문~
선형대수와 지수미분 등 수학적 지식을 얼마나 알고 있어야 하는가?
=> 추상화된 라이브러리들을 사용하기 때문에 깊게 알 필요는 없다(어떤 의미를 가지는지 정도)
원래는 spark를 사용하려면 따로 문법을 배워야 했지만, pyspark를 통해 판다스 문법을 사용할 수 있음
