
👉 오늘 한 일
- 미니 프로젝트_2 : 대중교통 및 따릉이 이용자 분석
미니 프로젝트
티머니 데이터와 merge
- 국도교통부 철도 데이터 포털 ⇒ 표준데이터 역사정보(전체 기관)
https://data.kric.go.kr/rips/M_01_01/detail.do?id=32&keywords=역사정보&page=1&lcd=&mcd=
위경도 데이터 결측치가 많아서 데이터 추가 탐색
- 서울교통공사_1_8호선 역사 좌표(위경도) + 9호선 정보
https://www.data.go.kr/data/15099316/fileData.do
https://www.data.go.kr/data/15041335/fileData.do
구글맵, 네이버, 카카오 api로 주소정보만 있으면 위경도 반환 가능
⇒ 지오코딩 (Geocoding)
⇒ 역지오코딩도 가능
네이버 api 사용
- 콘솔에 가서
AI, NAVER API사용, API 키 발급(결제수단 등록 필요)
- 테스트 코드 작성 후 geocode 요청

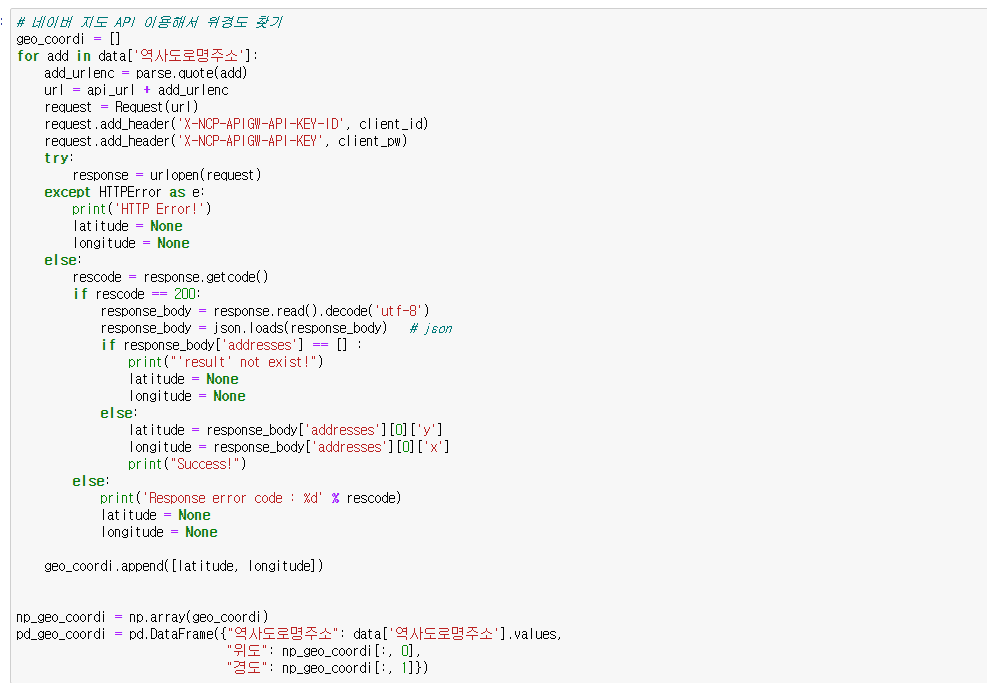

geocoding으로도 여전히 위경도를 불러오지 못함..
- 검증
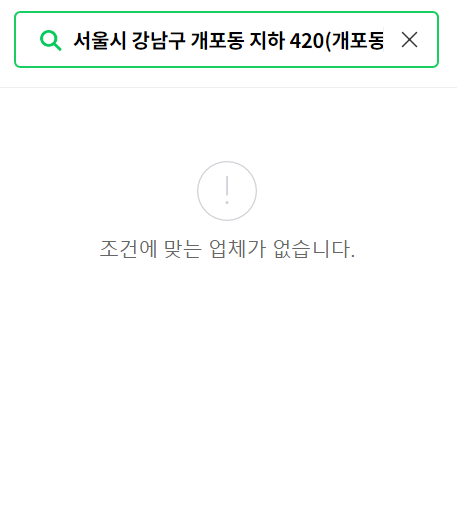
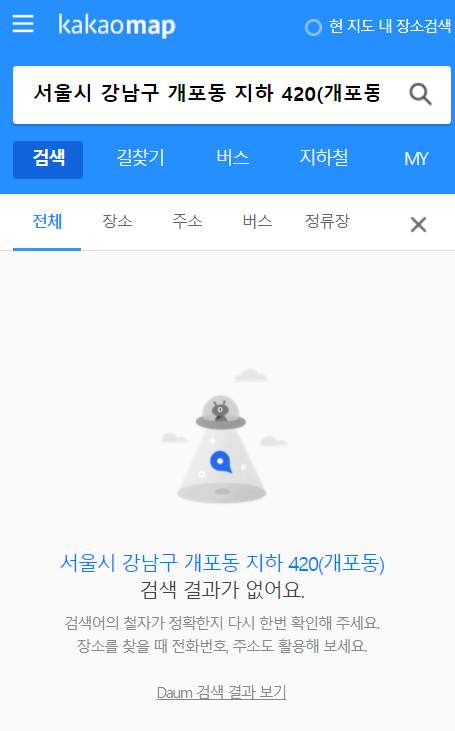
네이버, 카카오지도는 제공된 주소명으로 위치를 찾지 못함
구글은 찾긴 찾지만 명확하게 검색하지 못함
구글 api까지만 시도해보고 안되면 개인 블로그에서 깔끔하게 정리된 데이터 가져와서 써야할듯
구글 맵 api
Google Maps Platform - Location and Mapping Solutions
또또 결제 프로필 생성..
[API] 구글 지도(Google Map) 추가하기 (+ API Key 발급받기)
api 키 발급받는 법이 상세하게 나와있음
지오코드 포기 ⇒ 개인 블로그에서 깔끔하게 정리된 위경도 데이터 불러옴
출처 : https://ciy545.tistory.com/m/335
활용 데이터
지하철 위경도 및 티머니 concat한 데이터 사용함(2022_tmoney_subway.csv)
티머니 데이터와 merge
- 라이브러리 호출
import pandas as pd
import numpy as np- 데이터 로드
# 티머니 시간대별 승하차 데이터
tmoney = pd.read_csv("2022_tmoney_subway.csv", low_memory=False)
tmoney.shape
>> (264576, 8)
# 지하철 위경도 데이터
raw = pd.read_excel("지하철_위경도.xlsx")
raw.shape
>> (1058, 13)- 위경도 데이터 전처리
# 도시명이 서울에 속하는 것만 가져옴
raw = raw[raw["city_name"] == "서울"]
raw.shape
>> (767, 13)# 사용할 칼럼만 불러옴
raw = raw[["displayName", "point_x", "point_y"]]
raw# 칼럼 이름 지정
raw.columns = ["지하철역", "경도", "위도"]
raw# 환승역 때문에 지하철역이 중복되서 들어간 것을 확인.
# 이를 처리하기 위해 위경도의 평균값을 사용
raw = raw.groupby("지하철역", as_index=False).mean()
raw전처리된 raw 데이터
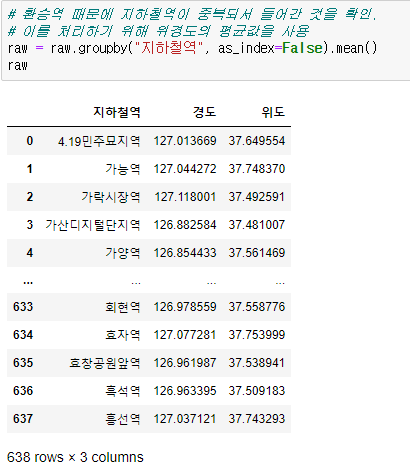
(767, 13) ⇒ (638, 3) 으로 데이터 shape 변함
- 지하철역 이름 전처리
# 불러온 두 데이터셋의 역사명이 서로 다르고 중구난방으로 되어있어 통일해주기
# 함수 정의
def preprocess_subway_name(data, col):
data[col] = data[col].replace('\([^)]*\)',"",regex=True)
data[col] = data[col].str.replace(" ", "")
data[col] = data[col].str.rstrip("역")
data[col]+="역"
# 함수 적용
preprocess_subway_name(tmoney, "지하철역")
preprocess_subway_name(raw, "지하철역")- 데이터 merge
원래는 시간대별 세부적인 승하차 인원을 분석할 생각으로 시간대별로 위경도 좌표를 전부 merge 했는데, 시간적 한계가 있어 의미가 없게 되었음..
# 데이터 merge
df = tmoney.merge(raw, on="지하철역")
dfmerge한 데이터
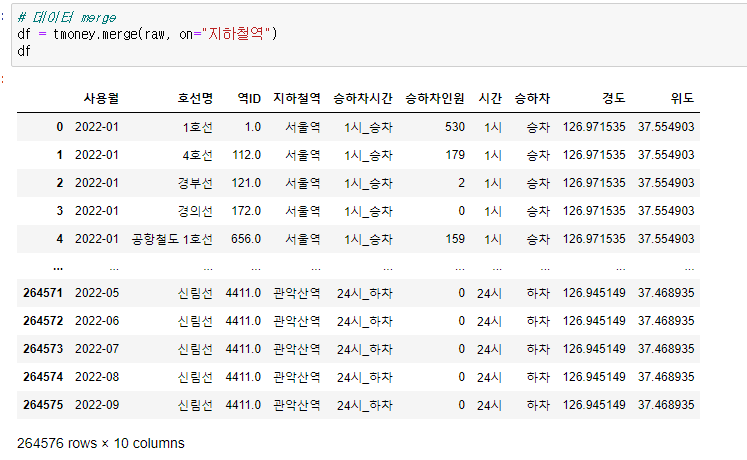
승하차인원 칼럼이 object 타입으로 나와서 int형으로 바꾸려고 하니 데이터에 “,”가 들어있다는 에러메세지 반환함 ⇒ 제거 후 처리
# 승하차인원 컬럼 숫자형으로 변환
df["승하차인원"] = df["승하차인원"].str.replace(",", "").astype(int)folium 시각화
- 역별 유동인구와 승하차 인원 시각화를 위해 전처리 후 merge
# 역사별 승하차인원에 위경도 데이터 merge
on_off = pd.pivot_table(df, index="지하철역", columns="승하차", values="승하차인원", aggfunc="sum")
on_off = on_off.merge(raw, on="지하철역")
on_off- folium으로 시각화
import folium
center = [37.563, 126.986]
zoom = 12
m = folium.Map(center, zoom_start=zoom)
for i in on_off.index:
m_name = on_off.loc[i, "지하철역"]
m_long = on_off.loc[i, "경도"]
m_lat = on_off.loc[i, "위도"]
m_on = on_off.loc[i, "승차"]
m_off = on_off.loc[i, "하차"]
radius = np.sqrt(np.sqrt(m_on + m_off)) - 30
tooltip = f"역사명 : {m_name}, 승차 : {m_on}, 하차 : {m_off}"
folium.CircleMarker([m_lat, m_long],
radius=radius,
fill=True,
tooltip=tooltip).add_to(m)
m시각화 결과
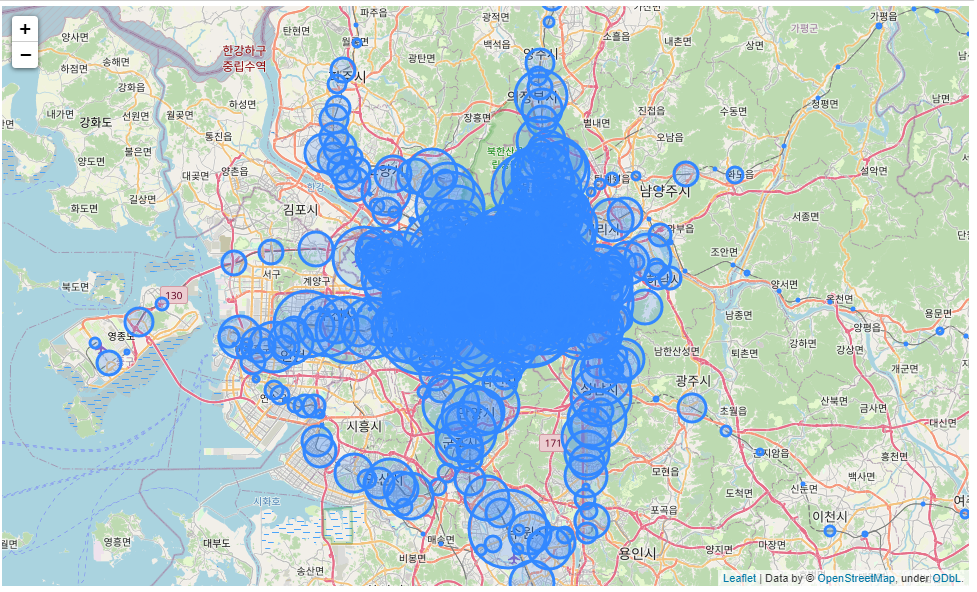
역이 너무 많아서 지저분함.. 유동인구 상위 30개역만 뽑아서 시각화
- 유동인구 상위 30개역 전처리
# 승하차 인원을 더한 유동인구 칼럼 생성
on_off["유동인구"] = on_off["승차"] + on_off["하차"]
on_off
# 유동인구 상위 30개역만 추출
top_30 = on_off.iloc[on_off["유동인구"].nlargest(30).index].reset_index(drop=True)
top_30- 최종 folium 시각화
center = [37.563, 126.986]
zoom = 12
m = folium.Map(center, zoom_start=zoom)
for i in top_30.index:
m_name = top_30.loc[i, "지하철역"]
m_long = top_30.loc[i, "경도"]
m_lat = top_30.loc[i, "위도"]
m_on = top_30.loc[i, "승차"]
m_off = top_30.loc[i, "하차"]
radius = np.sqrt(np.sqrt(m_on + m_off)) - 30
tooltip = f"역사명 : {m_name}, 승차 : {m_on}, 하차 : {m_off}"
folium.CircleMarker([m_lat, m_long],
radius=radius,
fill=True,
tooltip=tooltip).add_to(m)
m시각화 결과
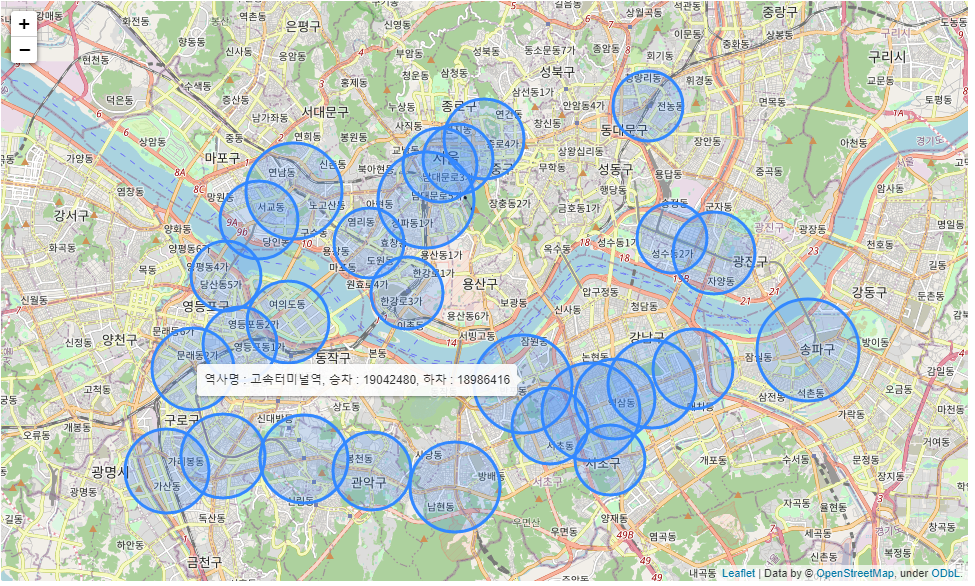
⇒ 유동인구에 따라 원 크기 조정 및 툴팁으로 승하차 인원 정보 제공
⇒ 1,2,7호선에서 유동인구가 많이 나타나는 것으로 확인됨
⇒ 노선 정보까지 merge해서 색을 나눠봐도 좋을듯.. 생각이 짧았다
프로젝트 트러블 슈팅
관악02번 버스 노선에 노천강당 정류장이 검색되지 않음해결- 서울대생 피셜, 9월까진 잘다니다가 최근 정차를 하지 않음(일시적으로 추정)
- 해당 정류장이 중앙도서관을 가는데 들리는 정류장이라 승하차 인원이 많은 편
- 버스 일별, 시간대 데이터가 있으면 좋을 것 같은데 아직 데이터셋을 구하지 못했음 ㅠㅠ 일별데이터라도 ,,,,
지하철 시간대 / 상 하행 으로 컬럼 나누기해결
- 승/하차 총 승객수
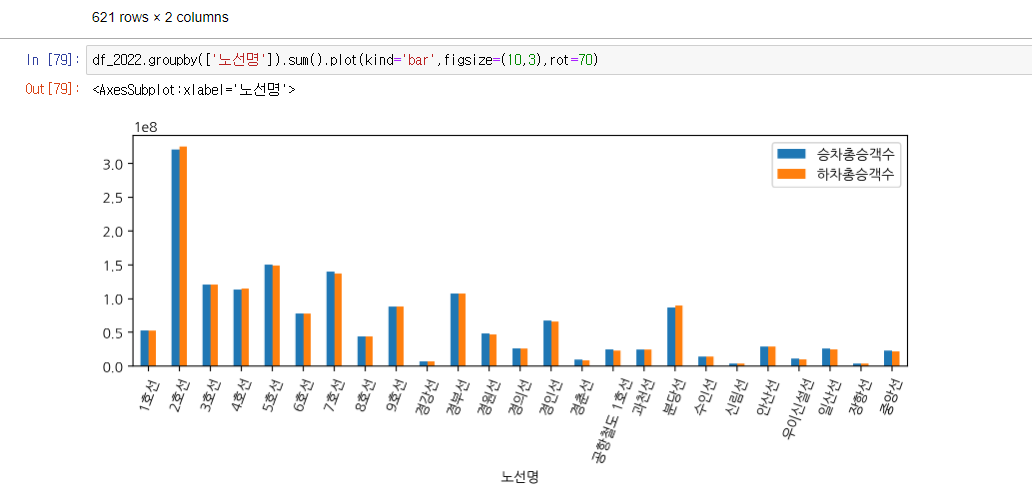
- 아무래도 타는사람이 있으면 내리는 사람도 있겠지만 두 데이터가 비슷비슷하게 나오는데 승차승객수로만 계산을 해도 되겠죠 ?
- 프로젝트의 방향성에 대한 고민 이 데이터들로 뭘 할 수 있을까에 대해 생각해보니 딱 떠오르는 주제가 많지가 않네요 … ㅠㅠ
- 시각화 seaborn barplot 내림차순으로 정렬?
#07~08시 출근 피크 타임 호선명별 하차인원 barplot
ride=pd.pivot_table(df, index = ["호선명","지하철역"], values = "07시-08시 하차인원", aggfunc = np.sum)
.reset_index().sort_values("07시-08시 하차인원",ascending=False)
plt.figure(figsize=(27,15))
sns.barplot(data=ride, x="호선명", y="07시-08시 하차인원",ci=None)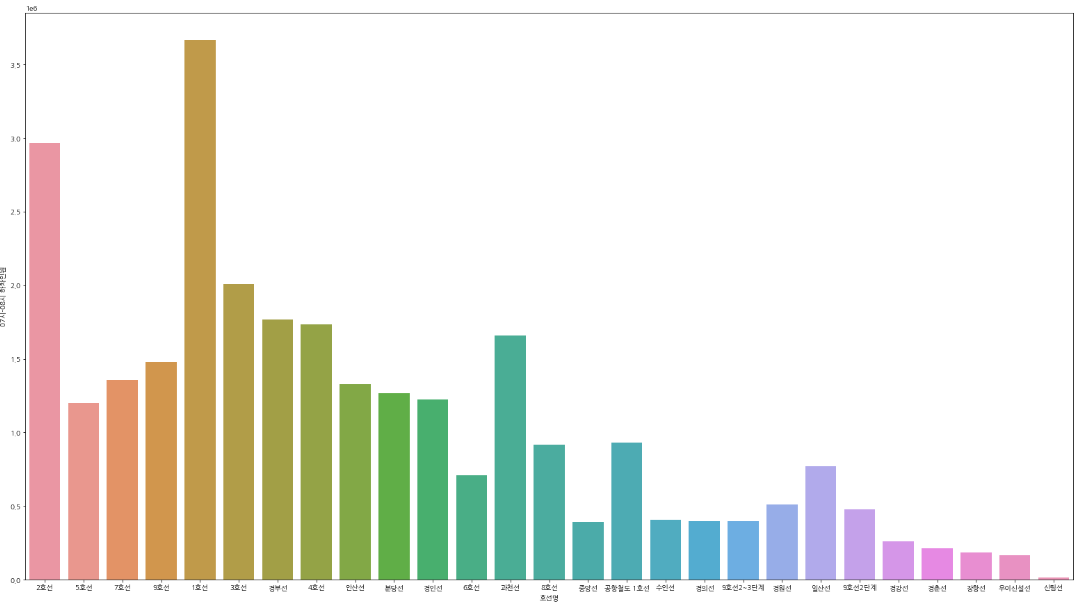
pivot_table =sort_values(”values값”,ascending=False) 요렇게는 구현이 안되는걸까요..? 해결
프로젝트 보고서

노션 링크
https://www.notion.so/2ND-77c44a6313ae41228e0541fe7caebe4a
