
👉 오늘 한 일
- 미드 프로젝트 발표
- ML 개요
미드 프로젝트 발표
발표 피드백
- Streamlit 에서 folium 렌더링 속도 개선하기
💡 팀에서 생각해 본 개선점
EDA
- 데이터셋을 추가해서 다양하게 분석해볼 수 있을 것 같습니다.
- 시각화 디자인을 조금 더 직관적으로 수정해볼 수 있을 것 같습니다.Streamlit
- 미니프로젝트 1, 2 모두 EDA 디벨롭해서 streamlit으로 정리해두면 좋을 것 같습니다.
- Intro.py 는 핵심 결과 위주로 페이지가 구성되도록 내용 개선 Github readme file
- 결과물 위주로 프로젝트의 전반적인 요약본을 추가할 수 있으면 좋을 것 같습니다.
- 마크다운을 좀 더 공부해서 예쁜 리드미를 만들어야겠습니다.
- PPT 를 png로 바꿔서 깃헙에 업로드 할 에정입니다. 다른 팀의 인사이트
- folium에서 circle 등 표시할 때 크기가 너무 크다면 제곱근을 씌워서 작게 만들 수 있고, 너무 작다면 제곱해서 키울 수 있음
발표 전 회고
눈 떠보니 마감일이군요🙄 정말 시간 가는 줄 모르고 몰입했던 프로젝트였습니다!
프로젝트 기간동안 ‘이 정도면 충분하지 않을까?’ 하는 안일한 생각이 들 때마다 새벽까지 열정과 체력을 갈아 넣는 팀원들을 보고 좋은 자극을 받았던 것 같습니다! 주제를 한 번 엎고 시작해서 고민이 많았을 때 멘토님들이 해준 조언도 큰 도움이 됐습니다 👍👍
협업 툴로 깃헙을 사용했는데, 불과 1~2년 전에 썼던게 기억이 하나도 안 나서 당황스러웠습니다… ㅋㅋㅋ 그래도 하면서 배워보자는 느낌으로 진행하니 비교적 원활하게 굴러갔던 것 같아요. 그리고 분석시간의 50 ~ 80%는 데이터 수집과 정제에 사용한다는 것을 몸소 체험했습니다. 이 과정에서 중간중간 방향도 잃고 원하는 분석 결과가 안나올까봐 꽤나 힘들더라구요…!
데이터 타입을 변경할 때 dtype은 변경되지만 실제 데이터는 변경이 안되는, 생전 처음 보는 오류도 마주했습니다. 데이터 정제 및 merge하는 과정에서 copy를 하지 않아서 생긴 것이라고 추측은 하고 있습니다만, 진행이 막히지는 않아서 정확한 원인은 밝히지 못하고 넘어가서 조금 아쉽습니다.
지금은 최종본은 아니지만, 점차 틀이 잡혀가는 모습을 보니 뿌듯합니다. 같은 데이터에 다양한 시각화 라이브러리도 적용해보고, 대시보드도 꾸미면서 소소한 재미를 느낄 수 있었습니다!
마지막으로, 팀장님과 팀원분들 모두 감사하고 고생 많으셨습니다!🤗발표 후 회고
맡은 역할과 본인이 생각하는 강점?
가설 한 개 주제 분석과 streamlit 일부 구현, github 관리, 보고서 정리 등의 업무를 맡았는데 분석 중 팀원들이 놓칠 수 있는 디테일적인 부분을 체크해주는 것이 강점이라고 생각했습니다.
개선할 점
분석 이전에 주제에 대한 참고 자료를 살펴보며 도메인 지식을 조금이나마 챙기고 시작하면 분석의 퀄리티가 올라갈 것 같습니다!ML 개요
kaggle survey
- 캐글은 매년 데이터 사이언스 관련 설문조사를 함(어떤 툴을 쓰는지 등등)
- autoML : 예측모델 성능이 뛰어나지만 지도학습, 비지도학습 등의 ML 기본 용어를 알지 못하면 사용하기 힘듦 -> ML 기초를 먼저 배워둬야 함
scikit-learn
- 오픈소스, 상업적으로 사용 가능(BSD 라이센스)
- numpy, scipy, matplotlib 기반으로 제작해 누구나 접근 가능하고 다양한 맥락으로 재사용 가능
- 예측 데이터 분석을 쉽고 효율적이게 해줌
- 딥러닝, 강화학습을 지원하지 않음
- matplotlib, plotly, numpy, pandas, scipy 등과 같은 다른 파이썬 라이브러리와 통합이 잘됨
scikit-learn의 주요 기능
-
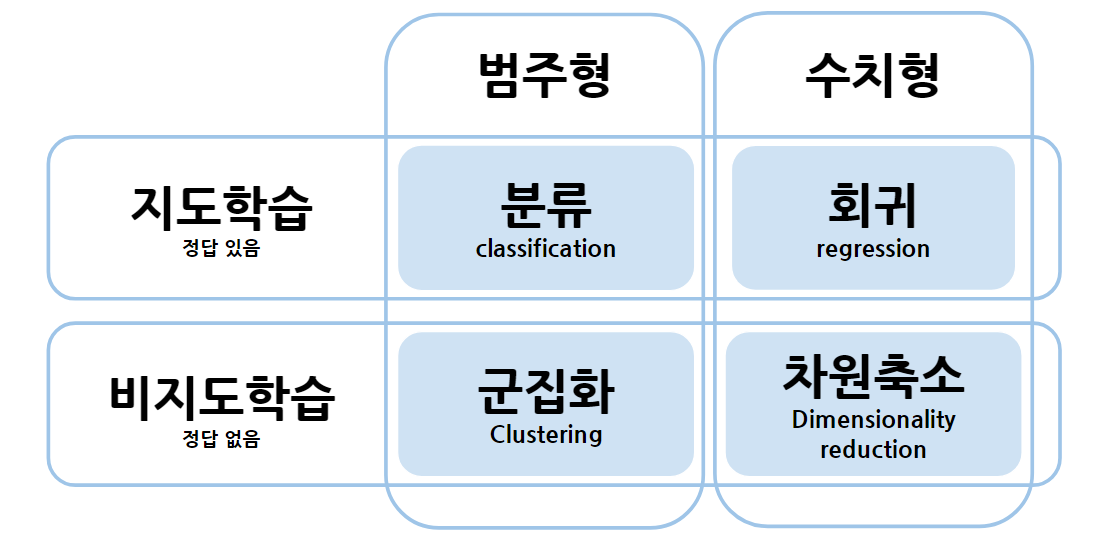
회귀 : 하나의 가설에 미치는 다양한 수치형 변수들과의 인과성 분석
- 개체와 연결된 연속된 값 속성 예측
- e.g. 약물 반응 수치 예측, 주가 예측
-
분류 : 범주형 데이터의 class를 나누는 것(지도학습)
- 개체가 속한 범주 식별
- e.g. 스팸 감지, 이미지 인식
-
군집화 : 유사도가 높은 범주끼리 모아줌(비지도학습)
- 유사한 개체를 세트로 자동 그룹화
- e.g. 고객 세분화, 실험 결과 그룹화
-
차원축소 : 고차원 데이터를 차원을 축소해서 한눈에 볼수있게 만들어줌
- 시각화, 파라미터 개수를 줄여 학습 속도를 개선하는데 적용
- 고려할 확률변수의 수를 줄임
-
모델 선택 : 모델마다의 옵션(파라미터)을 비교해 최적의 모델을 선택 -> 파라미터 튜닝
- 알고리즘을 통해 이루어짐 : 그리드 검색, 교차검증, 평가지표 등
-
전처리 : 피처 추출과 정규화 등의 기능
- normalize : 정규화. 데이터를 0~1 사이의 값으로 정리해 스케일이 다른 피처 비교 가능
핵심적인 알고리즘의 api 위주로 배울 것 -> 어떻게 하면 모델을 이용해 현실 세계의 문제를 해결할 것인가
XGBoost, LightGBM, catboost
- 트리계열 알고리즘
PyCaret : 추상화된, autoML에 가까운 라이브러리
- 최적 모델 추천
지도학습
- 회귀, 분류
비지도학습 - 군집화, 변환, 연관
강화학습
머신러닝과 딥러닝의 차이?
- 머신러닝이 딥러닝을 포괄하는 개념인데, 딥러닝은 신경망학습에 초점을 둔 머신러닝 기법임
머신러닝 알고리즘 유형
DL 개요
tensorflow
- 1.~ ver 2.~ ver의 차이 이슈
- 실제 비즈니스에서 아직 많이 사용(프로덕트 개선 등)
pytorch
- 이용자수가 점차 많아져 최근에는 tensorflow를 넘김
- 연구에서 많이 쓰임
fast.ai
- 파이토치를 벡엔드로 사용하는 라이브러리
- 접근성이 좋고 쉬워 교육용으로 많이 활용
- 내부 알고리즘보다는 구현하는데 중점을 두고 있음
- 데이터 윤리에도 중점을 두고 있음
그 외 caffe, DL4J, MXNET 등등 다양한 프레임워크가 있음
설명 가능한 인공지능(XAI)
scikit-learn의 순열 중요도
- 모델에 상관없이 예측에 가장 큰 영향을 미치는 피처 파악
ELI5(Explain Like I'm 5) : 5살 아기한테 설명하듯이 쉽게 설명하겠다

자라나라 새싹새싹🌱