
👉 오늘 한 일
- 머신러닝 개요
- 머신러닝 모델 학습과 예측 과정
- tree 계열 알고리즘
ML 개요
머신러닝 : 인공지능 분야의 범주
이미지 : 숫자의 배열 -> 숫자를 병렬처리함
분류 : label이 있는 데이터의 범주를 나눔
- e.g. 이미지 분류, 구매 예측, 약품 분류, 텍스트 분류, 이상 유저 분류 등
- 예측한 값이 실제 값을 맞추면 정답, 예측이 실제 값과 다르면 정답이 아닌 것
- 정답 == label == target. Nan 혹은 Null 이면 정답이 없는 것
회귀 : 숫자의 많고 적음을 예측
- e.g. 주가 예측, 주택 가격 예측, 제품 수율 예측, 기온 예측, 광고 클릭율 등
추천 알고리즘 -> 비지도 학습에 가까움
머신러닝 모델 학습과 예측 과정
머신러닝 파이프라인
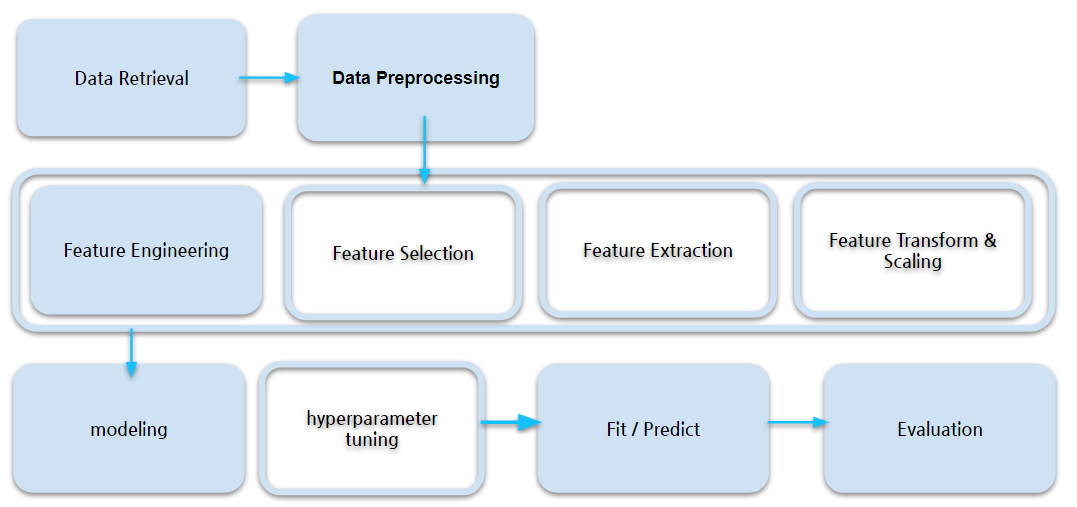
데이터 전처리 방법(data preprocessing)
- scaling
- normalization 등
- outliers 처리
- 결측치 처리
- imputation 등
- encoding
- one-hot encoding 등
train dataset으로 model fit(학습) -> test dataset으로 예측 -> metric(평가 기준)에 따라 evaluate(평가)
- fit -> predict -> evaluate
scikit-learn에서 X가 대문자이고 y가 소문자인 이유?
- 보통 X에는 2차원의 metrix 형태의 값이 들어가고 y는 1차원의 벡터 형태의 값이 들어가기 때문
- 강제는 아님. 관례적으로 사용
tree 계열 알고리즘
- 분류, 회귀에 모두 사용할 수 있는 알고리즘(CART. classification and regression tree)
- 최근 가장 인기 있는 알고리즘. 성능이 좋음(XGBoost, lightGBM 등)
decision tree
-
수치 자료와 범주 자료 모두에 적용할 수 있음. 다른 기법들은 일반적으로 오직 한 종류의 변수를 갖는 데이터 셋을 분석하는 것에 특화되어 있음. (일례로 신경망 학습은 숫자로 표현된 변수만을 다룰 수 있는 것에 반해 관계식(relation rules)은 오직 명목 변수만을 다룰 수 있음.
-
classification tree는 예측된 결과로 입력 데이터가 분류되는 클래스를 출력함
-
regression tree는 예측된 결과로 특정 의미를 지니는 실수 값을 출력함 (e.g. 주택의 가격, 환자의 입원 기간)
-
-
결과를 해석하고 이해하기 쉬움. 간략한 설명만으로 결정 트리를 이해하는 것이 가능
-
자료를 가공할 필요가 거의 없음.다른 기법들의 경우 자료를 정규화하거나 임의의 변수를 생성하거나 값이 없는 변수를 제거해야 하는 경우가 있음
-
화이트박스 모델을 사용함. 모델에서 주어진 상황이 관측 가능하다면 불 논리를 이용하여 조건에 대해 쉽게 설명할 수 있음.
-
안정적임. 해당 모델 추리의 기반이 되는 명제가 다소 손상되었더라도 잘 동작함.
-
대규모의 데이터 셋에서도 잘 동작함. 방대한 분량의 데이터를 일반적인 컴퓨터 환경에서 합리적인 시간 안에 분석할 수 있음.
당노병 예측 실습
label : outcome
정해진건 없지만 통상적으로 train : test = 8 : 2로 보통 나눔(train은 test보다 항상 더 많아야 함)
DecisionTreeClassifier() : decision tree 분류기 생성
- max_depth : 트리의 최대 깊이 설정
- max_features : 분지할 때 고려할 피처 개수
- int로 넣으면 개수, float은 비율, 그 외 sqrt 등등..
- random_state : 시드값 설정. 같은 조건에서 같은 결과가 나오도록 함
- 보통 가장 중요한 피처를 기준으로 먼저 분지함
- 하이퍼파라미터튜닝으로 모델 성능 올리기 가능
plot_tree() : decision tree 시각화
- plt.figure(figsize)로 그래프 크기 설정
- max_depth : 트리의 최대 깊이 설정
- feature_names : 피처 이름을 지정해줌. 지정하지 않으면 X[1], X[2] 이런식으로 출력
- filled : 클래스별로 색상을 구분해줌
ipython 코드블럭에서 중간 코드 출력하기
- 데이터프레임은
print로 출력하면 제대로 출력되지 않음 - e.g.
display(X_train.head())
분지 속성 선정 기준
- 불순도
- 높은 불순도 : 노드 내의 class들이 부모 노드와 비슷한 분포
- gini계수, entropy
- gini계수가 낮을수록 불순도가 낮음
피처의 중요도 측정 및 시각화
model.feature_importances_
sns.barplot(x=model.feature_importances_, y=model.feature_names_in_)
정확도 측정
직접 구하기
(y_test == y_predict).mean()
- y_test : 실제값
- y_predict : 예측값
함수로 구하기
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)혹은
model.score(X_test, y_test)과적합과 과소적합
과소적합 : 모델 학습이 너무 안됨
과적합 : 학습 데이터를 너무 많이 학습해 학습 데이터에는 성능이 좋지만 실제 데이터에 대한 예측 성능은 떨어지고 일반화하기 어려움
최적화 : train과 test에서 모두 좋은 성능이 나오는 지점을 찾음
feature engineering
수치형 변수를 그대로 안 쓰고 범주형 변수로 바꿔 쓰는 이유?
-
머신러닝 알고리즘에 힌트를 주거나(이렇게 범주를 나누면 label이 조금 더 명확하게 나타난다) 조건을 덜 나눠 오버피팅 방지 가능
-
이 방법으로 꼭 성능이 개선되는 것은 아님. 이런 기법을 사용해볼 수도 있다~
-
수치형 변수를 범주형으로 인코딩하는 것
Job Description
8퍼센트 : P2P 금융
회사와의 fit
- 학습을 통해 성장하는 사람 => 학습을 통한 성장, 성장을 통해 회사에 기여
커뮤니케이션 : 협업 및 소통이 원활한 사람 - 팀과 함께 성과를 낼 수 있는 사람. 기술 + 커뮤니케이션 등의 소프트 스킬
엔트리 -> 주니어 -> 시니어
