
👉 오늘 한 일
- house price 제출 이어서
- kaggle 벤츠 경진대회 실습
house price 제출
Review
💡왜도
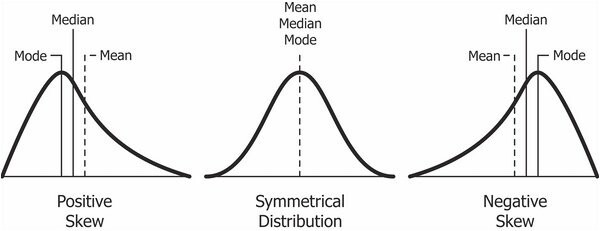
Positive Skewness는 오른쪽 꼬리가 왼쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 크는 것을 의미
Negative Skewness 왼쪽 꼬리가 오른쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 작는 것을 의미
🤔왜도, 첨도의 정확한 수치까지 알아야 할까?
- 비교해볼 변수가 많다면 전체적으로 왜도와 첨도의 수치가 높은 값을 추출해서 전처리할 수도 있음
- Anscombe's Quartet 데이터셋(기술통계값은 같으나 분포는 다른)을 생각해보면 요약된 기술통계는 데이터를 자세히 설명하지 못하는 부분도 있음
💡결측치
-
결측치가 많다고 삭제하는 것이 무조건 나은 방법은 아님
-
이상치, 특이값을 찾는다면 오히려 신호가 될 수 있음
-
범주형 값이라면 결측치가 많더라도 채우지 않고 인코딩하면 나머지 없는 값은 0으로 채움. 대신 희소 행렬이 생성됨
-
수치 데이터인데 결측치라면 잘못 채웠을 때 오해할 수 있으니 주의
💡상관관계, 수치형 변수 대체
- 다중공선성은 트리계열 모델에서까지는 고려할 필요 x
- 수치형 변수를 대체할 때는 원래 값이 너무 왜곡되지 않는지도 고려
이어서
💡log 변환
🤔plt.show()를 사용하면 가끔씩 그래프가 중복되서 나오는 이유?
- 기존 주피터 에서는 그래프를 보여주는게 기본값이 아닌데 마지막 줄에 그래프를 그리는 코드가 있다면 보여주는 것이 기본 값으로 변경이 됨. 그래서
plt.show()를 했을 때 주피터 버전에 따라 중복 출력이 될 수도 있는데 이때는plt.show()를 지우고 사용
💡squared features (Polynomials)
- uniform 한 분포에 사용
sklearn.PolynomialFeatures를 사용해도 되지만 직접 제곱해도 됨- house price 실습에서는 딱히 사용할만한 변수는 없음
💡범주형 변수 살펴보기
- 범주형 변수 중에 결측치가 있는지 확인을 해보고 어떤 범주형 변수를 사용할지 의사결정
- 범주형 데이터는 원핫인코딩 작업을 하기 때문에 결측치를 남겨두어도 상관은 없음
💡정리 - 수치형 변수 전처리
- 결측치 대체(Imputation)
- 수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지도 주의가 필요합니다.
- 중앙값(중간값), 평균값 등의 대표값으로 대체할 수도 있지만,
- 당뇨병 실습에서 했던 회귀로 예측해서 채우는 방법도 있습니다.
- 당뇨병 실습에서 했던 인슐린을 채울 때 당뇨병 여부에 따라 대표값을 구한 것 처럼
- 여기에서도 다른 변수를 참고해서 채워볼 수도 있습니다.
- 스케일링 - Standard, Min-Max, Robust
- 변환 - log
- 이상치(너무 크거나 작은 범위를 벗어나는 값) 제거 혹은 대체
- 오류값(잘못된 값) 제거 혹은 대체
- 이산화 - cut, qcut
등
💡정리 - 범주형 변수 전처리
- 결측치 대체(Imputation)
- 인코딩 - label, ordinal, one-hot-encoding
- 범주 중에 빈도가 적은 값은 대체하기
등
벤츠 경진대회
💡선형회귀
선형회귀 : 종속변수 y와 한 개 이상의 독립변수 X와의 선형 상관 관계를 모델링하는 회귀분석 기법
-
선형 예측 함수를 사용해 회귀식 모델링, 알려지지 않은 파라미터는 데이터로부터 추정
-
다른 모델들에 비해 단순, 빠름
-
조정할 파라미터가 적음
-
이상치 영향을 크게 받음
-
데이터가 수치형 변수로만 이루어진 경우, 경향성이 뚜렷한 경우 사용하기 좋음
선형회귀의 단점을 보완한 Lasso, Ridge, ElasticNet 과 같은 모델들이 있음
💡데이터 살펴보기
-
회사 보안상 이슈 문제 등으로 익명화된 데이터를 제공하기도 함
- 대략적인 정보는 주어짐
-
변수를 살펴보고 변별력이 없는 변수(단일한 값만 가지고 있는 변수)를 삭제
-
기술통계를 구했을 때 수치데이터가 너무 많다면 heatmap으로 시각화해서 볼수도 있음
- e.g.
sns.heatmap(train.select_dtypes(include=np.number).drop(columns="y"), cmap="Blues")💡JD
SQL 용량이 너무 크다면 데이터 파일형태로 추출해서 파이썬으로 분석하는 형태로 진행하기도 함
네카라는 옛말…개발자가 뽑는 '진짜' 신의 직장은 '몰두센'
https://n.news.naver.com/article/009/0004952030
JD의 GCP(Google Cloud Platform), AWS, MS Azure, ELK(Elasticsearch, Logstash, Kibana) 는 클라우드 제품군 이름으로 해당 제품군을 사용하는 회사라고 보면 됨
- 기본적인 SQL, Python 과 같은 취업을 위한 스킬에 필요한 것을 먼저 익히고 제품군은 실제로 취업해서 사용해 보면 더 잘 사용할 수 있음
- 클라우드에 데이터가 DB 혹은 파일 형태로 적재되어 있음
- 데이터 엔지니어 직군은 클라우드에 실제로 적재하는 업무를 하기 때문에 클라우드 제품군 이름이 들어가는 경우가 더 많음.
ETL
전통적으로 다양한 데이터를 추출(E)해서, 원하는 형식으로 변환(T)하여, 저장(L)하는 기술
- 데이터 웨어하우스에서 동작
ELT
ETL과 달리 데이터를 추출(E)한 이후에 변환없이 그대로 저장(L)한 후 원하는 방식으로 변환(T)하는 방식
- 데이터 레이크에서 동작. 더 높은 유연성
ETL vs ELT : 최근 트렌드 변화
https://blog.naver.com/freepsw/222276087707
클라우드 머신러닝 플랫폼 선택 기준 12가지
https://www.itworld.co.kr/news/160710
📌오늘의 회고
- 사실(Fact) : house price 베이스라인 모델을 제출해보고 벤츠 제조 경진대회 실습을 진행했다.
- 느낌(Feeling) : 피처가 많을수록 전처리 적용도 다양하게 해주어야 하고 피처에 대한 설명도 하나하나 읽어보는데 시간이 오래 걸려서 제법 까다로운 것 같다.
- 교훈(Finding) : 변수가 많은 데이터에 대한 분석도 연습해봐야겠다.
