
👉 오늘 한 일
- 벤츠 경진대회 이어서 -> 여러 모델 적용
벤츠 경진대회 - 선형회귀
💡Review
pd.concat() : 인덱스 값을 기준으로 합침
sklearn.OneHotEncoder()를 사용하면 반환값이 np.array 형태이기 때문에 인덱스 정보도 없고 데이터프레임으로 별도의 변환이 필요함. concat으로 합치기 위해 인덱스 정보도 맞춰줄 필요가 있음
- 사이킷런으로 인코딩 하는 과정이 좀 더 복잡함.
- 장점은 numpy와 pandas의 데이터를 다루는 연습을 해보기에 좋음
- 아직 인코딩은
pd.get_dummies()가 더 편함
💡holdout validation
-
검증을 위해 train 데이터셋에서 다시 validation을 나누어줌
-
x_train, x_valid, y_train, y_valid = train_test_split(data, target)
💡선형회귀
sklearn.linear_model.LinearRegression()은 선형회귀 모델을 구현한 라이브러리
- 시드 지정 파라미터가 없음
- r2 score 으로 모델 성능 측정
벤츠 경진대회 - 트리기반모델
회귀모델은 이상치에 민감하기 때문에 이상치가 너무 크다면 제거하고 사용하는 것도 방법
💡ExtraTree Model
-
랜덤 포레스트와 같이 배깅(bagging) 방식의 모델
-
엑스트라 트리 모델은 극도로 무작위화(Extremely Randomized Tree)된 모델임
-
랜덤 포레스트에서와 같이 후보 기능의 무작위 하위 집합이 사용되지만 가장 차별적인 임계값을 찾는 대신 각 후보 기능에 대해 임계값이 무작위로 그려지고 무작위로 생성된 임계값 중 가장 좋은 것이 분할 규칙으로 선택됨
-
이것은 일반적으로 약간 더 큰 편향 증가를 희생시키면서 모델의 분산을 조금 더 줄일 수 있음
주요 파라미터
- 이 클래스는 데이터 세트의 다양한 하위 샘플에 여러 무작위 결정 트리(추가 트리라고도 함)에 맞는 메타 추정기를 구현하고 평균을 사용하여 예측 스코어를 개선하고 과적합을 제어함
n_estimators : int, default=100- 숲에 있는 나무의 수
criterion : {“squared_error”, “absolute_error”}, default=”squared_error”- 분할의 품질을 측정하는 기능
max_depth : int, default=None- 트리의 최대 깊이
min_samples_split : int or float, default=2- 내부 노드를 분할하는 데 필요한 최소 샘플 수
max_features : {“auto”, “sqrt”, “log2”}, int or float, default=”auto”- 최상의 분할을 찾을 때 고려해야 할 기능의 수
💡Gradient Boosting Tree Model
- 부스팅 기법은 여러 얕은 트리를 연결하며 편향과 분산을 줄여 강력한 트리를 생성하는 기법임
- 이전 트리에서 틀렸던 부분에 가중치를 주며 지속적으로 학습
🤔Bagging과 Boosting의 차이?
Bagging : 데이터 셋 모델마다 독립적(병렬로 학습)
- 배깅은 훈련세트에서 중복을 허용해서 샘플링하여 여러개 모델을 훈련 하는 앙상블 방식. 같은 훈련 샘플을 여러 개의 모델에 걸쳐 사용해서 모든 모델이 훈련을 마치면 앙상블은 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 만들게 됨
Boosting : 앞 모델이 데이터 셋 정해줌(순차적 학습)
-
부스팅은 약한 모델을 여러개 연결해서 강한 모델을 만들어 내기 위한 앙상블 방식. 부스팅의 아이디어는 앞의 모델들을 보완해 나가면서 일련의 모델들을 학습시켜 나가는 것
-
이전 오차를 보완해서 순차적으로 만들기 때문에 랜덤 포레스트와 다르게 무작위성이 없음
- 부스팅에서 대표적인 모델 중 하나는 에이다 부스트(AdaBoost). 에이다 부스트는 앙상블에 이전까지의 오차를 보정하기위해 샘플의 가중치를 수정할 수 있도록 모델을 순차적으로 추가함
- 반면에 그래디언트 부스팅은 에이다 부스트와 달리 샘플의 가중치를 수정하는 대신 이전 모델이 만든 잔여 오차에 대해 새로운 모델을 학습시킴
- 최적화된 그래디언트 부스팅 구현으로 가장 유명한 것이 XGBoost
🤔기울기는 어떻게 사용할까?
- 가중치 업데이트 시 경사하강법 사용
- 예측값과 정답값간의 차이인 손실함수 그래프에서 값이 가장 낮은 지점으로 경사를 타고 하강. 이를 반복하며 기울기를 최소화하는 지점의 파라미터를 찾음
Learning Rate(학습률) == 보폭(step)
- 보폭이 너무 크면 대충 찾기 때문에 최소점을 지나칠 수도 있음. 그래서 최소 지점을 찾지 못하고 아래 그래프처럼 발산을 하기도 함
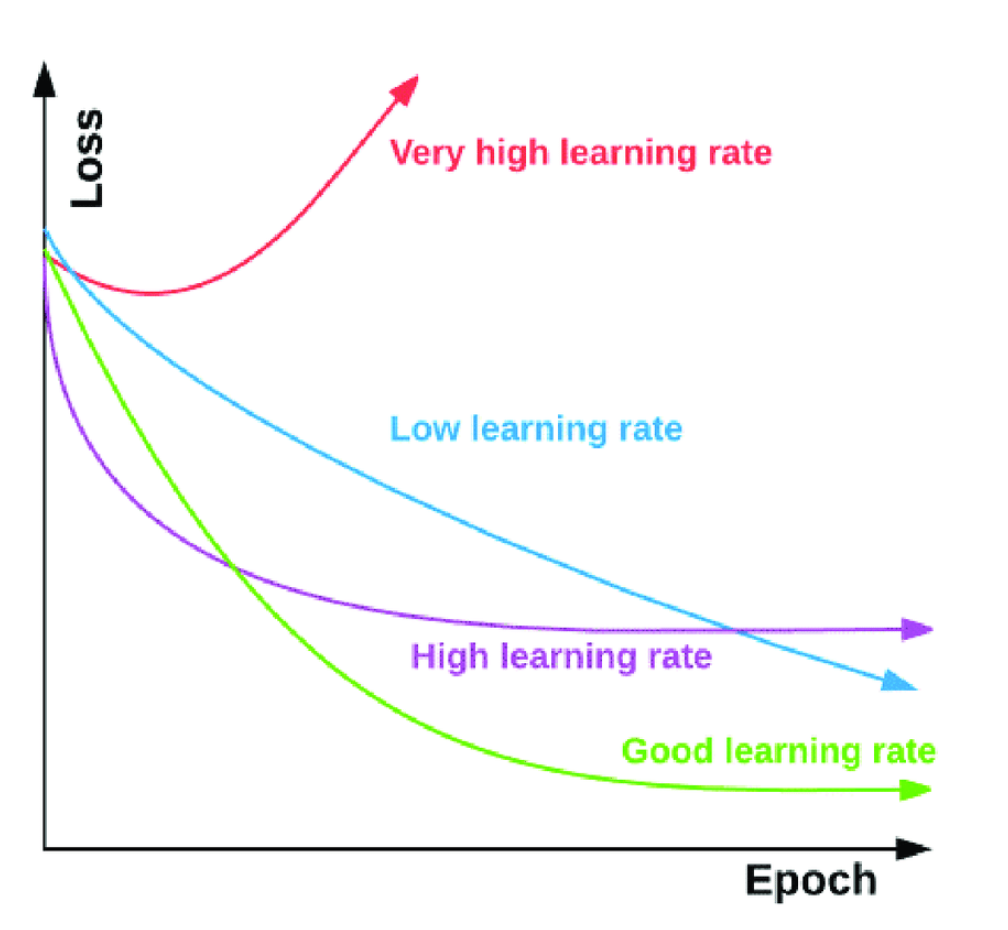
파이썬 라이브러리를 활용한 머신러닝(번역개정2판)
https://preview2.hanbit.co.kr/books/rzmj/#p=1
🤔성능과 관계없이 GBM 에서 훈련시간을 줄이려면?
- learning_rate 를 올리면 학습시간은 줄어들지만 제대로 된 loss(손실)가 0이 되는 지점을 제대로 찾지 못할 수도 있음
🤔손실함수로 absolute loss보다 squared loss 를 더 많이 사용하는 이유?
- absolute loss는 기울기가 +, - 방향에 따라 같은 기울기가 나오기 때문에 방향은 알 수 있지만 기울기가 같아서 미분을 했을 때 방향에 따라 같은 미분값이 나와서 기울기가 큰지, 작은지 비교할 수 없음. 그래서 squared loss 를 더 많이 사용
벤츠 경진대회 - 부스팅 계열 모델
🤔(설치가 잘 되기도 하지만)왜 가끔씩 부스팅 계열 모델이 설치에 실패하는 경우가 생길까?
- 부스팅 계열 모델은 다른 언어로 작성되었는데 파이썬
wrapper API를 제공함 - 구동하려면 다른 언어 환경이 함께 필요한 경우가 많음. 기존에 다른 도구를 설치하다가 해당 언어 환경 도구를 설치해 놨다면 비교적 잘 설치가 되지만, 처음 설치할 때는 실패하는 경우가 많음
- conda 는 비교적 패키징이 잘 되어 있어서 관련된 환경을 잘 구성함. 그래서 되도록이면 conda 로 설치해야 스트레스를 덜 받을 수 있음
💡부스팅 계열 모델 - XGBoost, LightGBM, CatBoost
- GBT에서 단점을 보완하고 개선한 모델들
- 앞서 배운 DT, RF, GBT보다 비교적 최근에 등장
- XGBoost => LightGBM => CatBoost 순으로 등장
- 하지만 무조건 이 모델들을 대체하지는 못함. 상황에 따라 적절한 모델을 선택해야 함
- 배깅 방식은 부트스트래핑을 해서 트리를 병렬적으로 여러 개 만들기 때문에 오버피팅 문제에 좀 더 적합함
- 개별 트리의 낮은 성능이 문제일 때는 이전 트리의 오차를 보완해 가면서 만들기 때문에 부스팅이 좀 더 적합함
💡XGBoost
- xgboost는 GBT에서 병렬 학습을 지원하여 학습 속도가 빨라진 모델임
- 기본 GBT에 비해 더 효율적이고, 다양한 종류의 데이터에 대응할 수 있으며 이식성이 높음
- 캐글 등 머신러닝 경연 대회에서 우승 후보들이 사용하는 도구로 성능이 아주 좋음
📌오늘의 회고
- 사실(Fact) : 벤츠 경진대회를 통해 여러 회귀 모델을 적용해보았다.
- 느낌(Feeling) : 비록 베이스라인 모델이지만 선택한 모델에 따라 성능이 크게 차이가 날 수 있다는 것을 확인했다.
- 교훈(Finding) : 주요 파라미터들을 다시 체크해보면서 복습해야겠다.
