👉 오늘 한 일
- SMOTE 실습
- 딥러닝 기초
SMOTE 실습
🤔정확도로 제대로 된 모델의 성능을 측정을 하기 어려운 사례?
- 클래스가 불균형한 데이터일 때
- e.g.
- 금융 => 은행 대출 사기, 신용카드 사기, 상장폐지종목 여부
- 제조업 => 양불(양품, 불량품) 여부
- 헬스케어 => 희귀질병(암 진단여부)
- IT관련 => 게임 어뷰저, 광고 어뷰저, 그외 어뷰저
💡predict_proba
- 분류의 측정 지표. 0,1 등의 클래스 값이 아닌 확률값으로 반환
- 임계값(threshold)을 직접 정해서 True, False를 결정하게 되는데 보통 0.5 로 하기도 하고 0.3, 0.7 등으로 정하기도 함
np.argmax: 가장 큰 인덱스를 반환. predict_proba를 감싸서 클래스 예측하기 위해 사용- e.g.
y_pred_proba_class = np.argmax(y_pred_proba, axis=1)
- e.g.
💡colab에서 구글 드라이브에 마운팅하기
google colab 좌측 하단 코드 스니펫에 mount 검색하면 소스코드 뜸
- 구글 드라이브를 마운트하면 데이터를 매번 colab 에 업로드 하지 않아도 되며 데이터를 불러오는 속도도 더 빠름
from google.colab import drive
drive.mount('/content/drive') # 구글 드라이브의 데이터 경로 지정💡train_test_split()
- train_test_split은 sklearn에서 제공하는 데이터 분할 메서드
- 입력 변수와 목표 변수를 입력하면 데이터를 학습용 데이터와 검증용 데이터로 나눠줌
- 머신러닝에서 데이터를 학습용 데이터와 검증용 데이터로 나누는 것은 매우 중요함
- 두 데이터가 제대로 분리되지 않으면, 모델이 답지를 보고 예상하는 것이나 마찬가지이기 때문
- 이러한 상황을 데이터 유출(Data Leakage)라고 함
- tran_test_split은 기본적으로 데이터를 분할할 때 섞어서(shuffle) 분할하도록 되어있음
- 불균형 데이터에서 train_test_split을 실행시켰을 때, 한 쪽 데이터에 희소한 값이 몰릴 가능성이 있음
- stratify 파라미터는 원래 데이터의 값 비율대로 학습용 데이터와 검증용 데이터를 분할시켜줌
💡confusion matrix 구하기
# crosstab 이용
pd.crosstab(y_test, y_pred)
# sklearn api 이용
cf = confusion_matrix(y_test, y_pred)
# heatmap으로 시각화
sns.heatmap(data=cf, annot=True, cmap="Blues");
# sklearn api로 시각화
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay(cf).plot();💡classification_report(y_test, y_pred)
-
print()로 감싸서 출력해야 함
-
반올림한 값임
-
precision은 정밀도를 의미
from sklearn.metrics import precision_score
-
recall은 재현도를 의미
from sklearn.metrics import recall_score
-
f1-score는 f1 점수를 의미
from sklearn.metrics import f1_score
-
accuracy는 정확도를 의미
from sklearn.metrics import accuracy_score
-
support는 클래스의 실제 발생 횟수가 얼마인지 알려줌
- 따라서 support는 모델에 따라 달라지는 숫자가 아님
-
weighted avg는 가중 평균을 의미하고, macro avg는 가중되지 않은 평균을 의미함.
- macro avg는 각 레이블에 대한 측정항목을 계산하고 가중치가 적용되지 않은 평균을 찾음. 레이블 불균형은 고려하지 않음.
- weighted avg는 각 레이블에 대한 메트릭을 계산하고 지원(각 레이블에 대한 실제 인스턴스 수)별로 가중치를 부여한 평균을 찾음.
💡데이터 샘플링 - undersampling & oversampling
- 두 방법의 목적은 두 값의 비율을 비슷하게 맞춰주는 것
- under-sampling은 더 값이 많은 쪽에서 일부만 샘플링하여 비율을 맞춰주는 방법
- over-sampling은 더 값이 적은 쪽에서 값을 늘려 비율을 맞춰준 방법
- under-sampling은 구현이 쉽지만 전체 데이터가 줄어 머신러닝 모델 성능이 떨어질 우려가 있음
💡데이터 샘플링 - SMOTE
- SMOTE는 Synthetic Minority Over-sampling Technique의 약자로 합성 소수자 오버샘플링 기법.
- 적은 값을 늘릴 때, k-근접 이웃의 값을 이용하여 합성된 새로운 값을 추가함
- k-근접 이웃이란 가장 가까운 k개 이웃을 의미.
샘플링한 데이터를 X, y로 train-test(+validation) 셋으로 나눠줌
샘플링을 사용하지 않고 데이터를 나눠 학습했을 때와 비교해서
f1_score, precision, recall 값이 모두 높아짐
정답 클래스가 불균형하면 학습을 제대로 하기 어렵기 때문에 오버샘플링이나 언더샘플링으로 정답 클래스를 비슷하게 만들어 주면 좀 더 나은 성능을 냄
딥러닝 기초
머신러닝 : 인간이 직접 특징을 도출할 수 있게 설계해서 예측값 출력
딥러닝 : 인공지능 스스로 일정 범주의 데이터를 바탕으로 공통된 특징을 도출하고, 그 특징으로 예측값 출력
기울기 소실은 역전파 과정에서 발생하는 문제. 역전파도 딥러닝 학습과정 중 일부임. 다층 퍼셉트론 학습에 사용되는 통계적 기법
역전파 과정은 검산과정이라고 생각하기. 순전파 때 적용한 활성화함수의 결과를 검산하여 오차를 줄여주는 과정이기 때문에 역전파 과정에서는 따로 활성화함수를 사용하는 과정이 아님
오차를 최소화하기 위한 역전파 과정에서 미분 기법을 이용하게 됨. 하지만 활성화함수를 sigmoid와 tanh 함수로 설정하게 되면 이 미분과정에서 기울기가 0으로 수렴하게 됨. 따라서 점점 기울기가 사라지고 이에 따른 가중치와 편향 도출이 어려워지는 문제가 발생함
- 순전파 -> Input을 받고 다수의 hidden layer에서 활성화함수 적용을 통하여 output을 출력하는 과정
- 역전파 -> 순전파 과정에서 출력한 결과와 정답값의 오차를 측정하여 그 오차의 값을 최소화하기 위한 과정
🤔단층 퍼셉트론으로 구현하지 못하는 논리회로?
- XOR 게이트
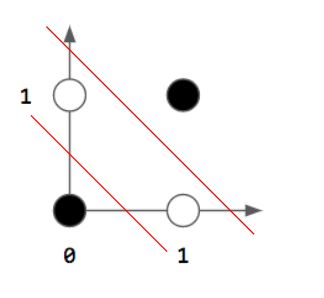
🤔XOR 문제를 해결한 방법?
- 다층 퍼셉트론
📌오늘의 회고
- 사실(Fact) : 신용카드거래데이터로 이진분류평가지표 실습과 성능향상을 위한 샘플링방법, 순전파, 역전파, 손실함수를 포함한 딥러닝 기초개념을 배웠다
- 느낌(Feeling) : 딥러닝 기초 개념의 양이 방대한 것 같다.
- 교훈(Finding) : 기초 개념을 확실하게 이해해보자.
