
👉 오늘 한 일
- DNN
- 텐서플로우 튜토리얼
- PIMA 데이터셋 실습
DNN(Deep Neural Network)
💡머신러닝 vs 딥러닝
머신러닝 : 인간이 직접 특징을 도출할 수 있게 설계해서 예측값 출력
딥러닝 : 인공지능 스스로 일정 범주의 데이터를 바탕으로 공통된 특징을 도출하고, 그 특징으로 예측값 출력
🤔28x28 픽셀 이미지로 학습을 하는데 왜 입력에 784개가 들어갈까?
- Fully Connected Network 에는 1차원 형태로만 주입이 가능하기 때문에 2차원 배열을 1차원 형태로 만들어서(flatten. 평탄화) 네트워크에 데이터를 넣어주기 위해. 28x28 = 784개임
- CNN, RNN 에서는 전처리 레이어에서 데이터 전처리를 어떻게 해줄지를 정하고 마지막에는 Fully Connected Network 를 통과하게 됨
🤔Fully Connected Network 에는 1차원형태로 네트워크에 데이터를 주입해야 하는데 어떻게 비정형 데이터(표형태가 아니라 이미지, 음성, 텍스트 등)를 잘 다룰까?
- 전처리 레이어에서 이미지, 음성, 텍스트 등을 전처리 하는 기능을 따로 제공하기 때문
🤔활성함수로 sigmoid 의 단점은?
- 역전파 단계에서 기울기 소실(gradient vanishing) 문제가 발생함
- 이 문제를 보완하기 위해 ReLU, Leaky ReLU 함수 사용
- ReLU : 0보다 작은 값에서 모두 0을 사용함
- Leaky ReLU : Dying ReLU 현상(x가 0보다 작을 때 모두 0인 현상)을 해결하기 위해 나옴. 입력값이 음수일 때는 0이 아니라 0.001과 같은 매우 작은 수를 반환
🤔dropout이란?
- 일부 노드를 제거하고 사용하는 것. 과적합을 방지하기 위해 일부 노드를 제거함
💡기울기 소실
-
기울기 소실은 역전파 과정에서 발생하는 문제. 역전파도 딥러닝 학습과정 중 일부임. 다층 퍼셉트론의 학습에 사용되는 통계적 기법
-
역전파 과정은 검산과정이라고 생각하기. 순전파 때 적용한 활성화함수의 결과를 검산하여 오차를 줄여주는 과정이기 때문에 역전파 과정에서는 따로 활성화함수를 사용하는 과정이 아님
-
오차를 최소화하기 위한 역전파 과정에서 미분 기법을 이용하게 됨.
-
하지만 활성화함수를 sigmoid와 tanh 함수로 설정하게 되면 미분과정에서 기울기가 0으로 수렴하게 됨. 따라서 점점 기울기가 사라지고 이에 따른 가중치와 편향 도출이 어려워지는 문제가 발생함
- 순전파 -> Input을 받고 다수의 hidden layer에서 활성화함수 적용을 통하여 output을 출력하는 과정
- 역전파 -> 순전파 과정에서 출력한 결과와 정답값의 오차를 측정하여 그 오차의 값을 최소화하기 위한 과정(역전파 후 다시 순전파 과정을 통해 오차 감소 확인)
Tensorflow 튜토리얼
💡MNIST 실습
- 데이터셋 로드
# 255로 나눈 이유? => 0~1 사이 값으로 정규화하기 위해
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0tf.keras.Sequential 모델
- 층을 차례대로 쌓음
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # 1차원 벡터 형태로 만들기. 입력층 생성
tf.keras.layers.Dense(units=128, activation='relu'), # 은닉층 생성
tf.keras.layers.Dropout(0.2), # 노드 제거(과적합 방지). 노드 개수 * 0.2만큼 제거
tf.keras.layers.Dense(10, activation='softmax') # 출력층 생성
])
# optimizer(최적화 함수) : 오차(손실함수)가 최소가 되는 지점을 찾기 위해 가중치를 갱신하는 알고리즘. 기울기, 뱡향, learning rate를 고려
# loss : 손실율 측정
# metrics : 평가지표
model.compile(optimizer='adam', # 최적화 함수
loss='sparse_categorical_crossentropy', # loss function. 손실 함수
metrics=['accuracy']) # 모델 평가지표cross entropy : 손실함수 중 하나로 분류 결과의 품질을 측정
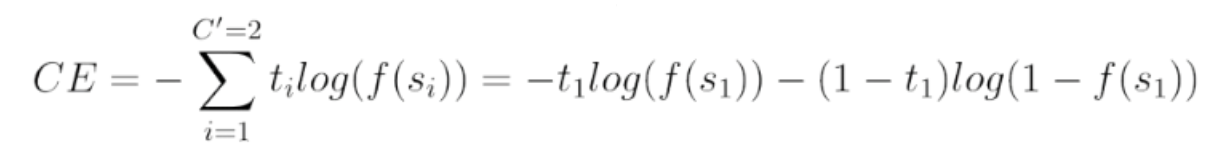
- 각 예시에서 모델은 각 클래스에 대해 하나씩, logits 또는 log-odds 스코어 벡터를 반환
# 첫 번째 이미지에 대한 예측값
predictions = model(x_train[:1]).numpy()
predictions
>>array([[0.30874717, 0.05911743, 0.07364181, 0.07375877, 0.07602702,
0.07852488, 0.09194738, 0.08101318, 0.05992001, 0.09730238]],
dtype=float32)- tf.nn.softmax 함수는 다음과 같이 이러한 로짓을 각 클래스에 대한 확률로 변환
- softmax의 확률값을 다 더하면 1이 됨
np.argmax: 가장 큰 값의 인덱스를 반환
smax = tf.nn.softmax(predictions).numpy()
smax, f"softmax는 다 더했을 때 1이 됩니다 : {np.sum(smax)}", f"정답 클래스 : {np.argmax(smax)}"
>>(array([[0.12288869, 0.09574126, 0.09714198, 0.09715334, 0.09737397,
0.09761749, 0.0989366 , 0.0978607 , 0.09581812, 0.09946782]],
dtype=float32), 'softmax는 다 더했을 때 1이 됩니다 : 1.0', '정답 클래스 : 0')- fit과 evaluate
Model.evaluate메서드는 일반적으로 Validation dataset 또는 Test dataset에서 모델 성능을 확인함
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)- 모델이 확률을 반환하도록 하려면 다음과 같이 훈련된 모델을 래핑하고 여기에 소프트맥스를 추가함
- 확률값을 반환하는 것을 확인할 수 있음
probability_model = tf.keras.Sequential([
model,
tf.keras.layers.Softmax()
])
y_pred = probability_model(x_test[:5])
y_pred
>> <tf.Tensor: shape=(5, 10), dtype=float32, numpy=
array([[0.08533683, 0.08533683, 0.08533683, 0.08533751, 0.08533683,
0.08533683, 0.08533683, 0.23196772, 0.08533684, 0.08533685],
[0.08533674, 0.08533674, 0.23196921, 0.08533674, 0.08533674,
0.08533674, 0.08533674, 0.08533674, 0.08533677, 0.08533674],
[0.0853398 , 0.23192093, 0.08534036, 0.08533988, 0.08533984,
0.0853398 , 0.08533981, 0.08535478, 0.08534498, 0.0853398 ],
[0.23195776, 0.08533748, 0.08533873, 0.08533748, 0.08533748,
0.08533756, 0.0853411 , 0.08533749, 0.08533748, 0.08533748],
[0.08535367, 0.08535367, 0.08535367, 0.08535367, 0.23170134,
0.08535367, 0.08535367, 0.08535435, 0.08535367, 0.08546865]],
dtype=float32)>💡fashion MNIST 실습 - 의류 이미지 분류
- min-max scaling 해도 이미지에 손상이 가지는 않음
# 원본 데이터의 min-max
train_images[0].min(), train_images[0].max()
>> (0, 255)
# 스케일링
train_images = train_images / 255.0
test_images = test_images / 255.0
# 시각화
plt.figure()
plt.imshow(train_images[0]) # sns.heatmap과 유사
plt.colorbar()
plt.grid(False)
plt.show()
# 스케일링 이후 min-max
train_images[0].min(), train_images[0].max()
>> (0.0, 1.0)- 모델을 사용해 한 이미지에 대한 예측 진행
- tf.keras 모델은 한 번에 샘플의 묶음 또는 배치(batch)로 예측을 만드는데 최적화되어 있음. 이미지 예측을 위해 차원을 늘려줌
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
>> (28, 28)
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
>> (1, 28, 28)💡Loss function
loss 값을 보고 label 이 어떤 형태인지 알 수 있음. label 값이 binary, one-hot, oridinal encoding 이 되어있냐에 따라 loss 값을 지정해야 함.
- binary_crossentropy (이진분류)
- categorical_crossentropy (다중분류: one-hot-encoding)
- sparse_categorical_crossentropy (다중분류: ordinal Encoding)
🤔옵티마이저를 사용하는 이유?
- 모델이 인식하는 데이터와 해당 손실 함수를 기반으로 모델을 업데이트 하기 위해
📌Summary
1) 다른 데이터에 적용한다면 층 구성을 어떻게 할것인가? -> 입력-은닉-출력층으로 구성됨.
2) 예측하고자 하는 값이 분류(이진, 멀티클래스), 회귀인지에 따라 출력층 구성, loss 설정이 달라짐. 예제를 몇 개 연습해 보면서 익히기.
3) 분류, 회귀에 따라 측정 지표 정하기
4) 활성화함수는 relu 를 사용, optimizer 로는 adam 을 사용하면 baseline 정도의 스코어가 나옴
5) fit 을 할 때 epoch 를 통해 여러 번 학습을 진행하는데 이 때, epoch 수가 많을 수록 대체적으로 좋은 성능을 내지만 과적합(오버피팅)이 될 수도 있음.
6) epoch 수가 너무 적다면 과소적합(언더피팅)이 될 수도 있음.
Pima dataset 실습 - 분류
이진 분류는 하나의 출력층에서 더 높은 확률로 이진분류로 나눌 수 있음
- 다중 분류일 때: 활성화함수=softmax, 출력층 n개
- 이진 분류일 때: 활성화함수=sigmoid, 출력층 1개
💡실습
- 이진 분류 문제이기 때문에 flatten은 사용하지 않음
- 이진 분류 문제이기 때문에 출력층에서 sigmoid 함수 사용
- 이진 분류 문제이기 때문에 출력층의 노드 개수는 한개임
- 이진 분류 문제이기 때문에 loss function으로
binary_crossentropy사용
# tf.keras.models.Sequential 로 입력-히든-출력(sigmoid) 레이어로 구성
input_shape = X.shape[1]
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 모델 컴파일
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])# 에폭이 끝날 때마다 점을 표시해서 진행상황 표시
class PrintDot(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0:
print('')
else:
print('.', end='')
# var_loss 기준으로 값이 나아지지 않으면 멈춤
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
# 학습
history = model.fit(X_train, y_train, epochs=100, validation_split=0.2, callbacks=[early_stop, PrintDot()])tf.keras.callbacks.EarlyStopping
- 특정 값을 기준으로 몇 회 이상 지표가 개선되지 않으면 학습을 일찍 종료함
- 특정 값 : monitor, 몇 회 이상 : patience
🤔딥러닝 과정에서 부분적인 오차를 최저 오차로 인식하여 더이상 학습을 진행하지 않는 경우?
- local minima
📌오늘의 회고
- 사실(Fact) : 텐서플로우 튜토리얼과 pima 데이터셋으로 DNN을 실습했다.
- 느낌(Feeling) : 입력층, 은닉층, 출력층을 생성할 때, 모델을 컴파일할 때 알아 둬야 할 개념들과 새로운 함수들이 새롭게 느껴졌다.
- 교훈(Finding) : 미니 프로젝트를 통해 DNN의 다양한 기능들을 사용해봐야겠다.
