
👉 오늘 한 일
- RNN 이어서(1101 ~ 1103)
RNN
🤔왜 fit은 train 에만 해줄까?
- 현실 데이터는 알 수 없기 때문에
- 텍스트 데이터를 train, test에 각각 fit을 하게 되면 다른 단어사전으로 전처리 되어 기준이 다르게 됨
💡 모델의 성능과 상관없이 속도를 개선하기 위해
- 가장 간단한 방법이 max_features 를 작게 조정하는 것
- 비지도학습의 차원축소를 사용해서 데이터를 압축해 사용할 수도 있음
- 차원축소 과정에서도 메모리 오류가 발생할 수도 있음. 이 때는 max_feature를 먼저 조정해주기
- 조금 더 조정한다면 min_df, max_df, stop_words 등을 조정해 볼 수 있음
💡기초 데이터셋
이미지 : MNIST, FMNIST, cifar10
텍스트 : IMDB, 영화리뷰 데이터셋, 네이버 영화리뷰 데이터셋
💡TF-IDF
💡TF(단어빈도, Term Frequency)
- TF(단어 빈도, term frequency)는 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값으로, 이 값이 높을수록 문서에서 중요하다고 생각할 수 있음.
💡DF(문서 빈도, document frequency)
- 특정 단어가 등장한 문서의 수
- 단어 자체가 문서군 내에서 자주 사용되는 경우, 이것은 그 단어가 흔하게 등장한다는 것을 의미
💡IDF(역문서 빈도, inverse document frequency)
-
한 단어가 문서 집합 전체에서 얼마나 공통적으로 나타나는지를 나타내는 값
-
전체 문서의 수를 해당 단어를 포함한 문서의 수로 나눈 뒤 로그를 취함
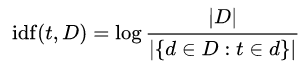
- : 전체 문서의 수
- 분모 : 단어 가 포함된 문서의 수. 단어가 전체 말뭉치 안에 존재하지 않을 경우 0이 됨. 이를 방지하기 위해 1을 더해주는게 일반적
-
DF의 역수로 DF에 반비례하는 수
-
IDF 값은 문서군의 성격에 따라 결정됨.
- e.g. '원자'라는 낱말은 일반적인 문서들 사이에서는 잘 나오지 않기 때문에 IDF 값이 높아지고 문서의 핵심어가 될 수 있지만, 원자에 대한 문서를 모아놓은 문서군의 경우 이 낱말은 상투어가 되어 각 문서들을 세분화하여 구분할 수 있는 다른 낱말들이 높은 가중치를 얻게됨
💡TF-IDF
-
TF와 IDF를 곱한 값
-
특정 문서 내에서 단어 빈도가 높을 수록, 그리고 전체 문서들 중 그 단어를 포함한 문서가 적을 수록 TF-IDF값이 높아짐
- 따라서, 이 값을 이용하면 모든 문서에 흔하게 나타나는 단어를 걸러내는 효과를 얻을 수 있음
-
IDF의 로그 함수 안의 값은 항상 1 이상이므로, IDF값과 TF-IDF값은 항상 0 이상이 됨
- 특정 단어를 포함하는 문서들이 많을 수록 로그 함수 안의 값이 1에 가까워지게 되고, 이 경우 IDF값과 TF-IDF값은 0에 가까워지게 됨
💡TfidfVectorizer
-
문서 모음을 TF-IDF 기능의 매트릭스로 변환함.
-
tf-idf를 사용하는 목표는 주어진 말뭉치에서 매우 자주 발생하고 따라서 훈련 말뭉치의 작은 부분에서 발생하는 특징보다 경험적으로 덜 유용한 토큰의 영향을 축소하는 것.
-
API documentation : https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
-
TfidfVectorizer는 사이킷런에서 TF-IDF 가중치를 적용한 단어 벡터를 만들 수 있는 방법임.- norm='l2' 각 문서의 피처 벡터 정규화 방법
- L2 : 벡터의 각 원소의 제곱의 합이 1이 되도록 만드는 것이고 기본 값
- L1 : 벡터의 각 원소의 절댓값의 합이 1이 되도록 크기를 조절
- smooth_idf=False
- 피처를 만들 때 0으로 나오는 항목에 대해 작은 값을 더해서(스무딩을 해서) 피처를 만들지 아니면 그냥 생성할지를 결정
- sublinear_tf=False
- use_idf=True
- TF-IDF를 사용해 피처를 만들 것인지 아니면 단어 빈도 자체를 사용할 것인지 여부
- norm='l2' 각 문서의 피처 벡터 정규화 방법
💡문자 전처리
- 숫자 제거
re.sub이용
import re
df["title"].map(lambda x : re.sub("[0-9]", "", x))str.replace이용
df["title"].str.replace("[0-9]", "", regex=True)- 특수문자 제거
-
특수 문자 사용시 정규표현식에서 메타 문자로 특별한 의미를 갖기 때문에 역슬래시를 통해 예외처리(escape)를 해주어야 함
-
특수문자 제거 시 구두점 참고
string라이브러리의string.punctuation
df["title"].str.replace("[!\"\$\*\.]", "", regex=True)- 대문자 -> 소문자 변경
- 대소문자를 다른 문자로 보기 때문에 하나로 처리하기 위해
df["title"].str.lower()
- 한글, 영문과 공백만 남기고 모두 제거
df["title"].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣A-Za-z ]", "", regex=True)
- 공백 여러 개는 하나로 처리
df["title"].str.replace("[\s]+", " ", regex=True)- 이를 이용해서 중복되는 문자열을 하나로 처리할 수 있음
re.sub("[ㅋ]+", "ㅋ", "ㅋㅋㅋㅋㅋ")
- 불용어 처리
- 불용어는 직접 지정해서 사용
- 워드클라우드
- 워드클라우드로 만들기 위해 시리즈 형태에서 하나의 문장으로 만들어줘야 함
"".join(df['title'])
