
👉 오늘 한 일
- RNN 이어서 (1106. 텍스트 마무리)
RNN
RNN layer의 구성
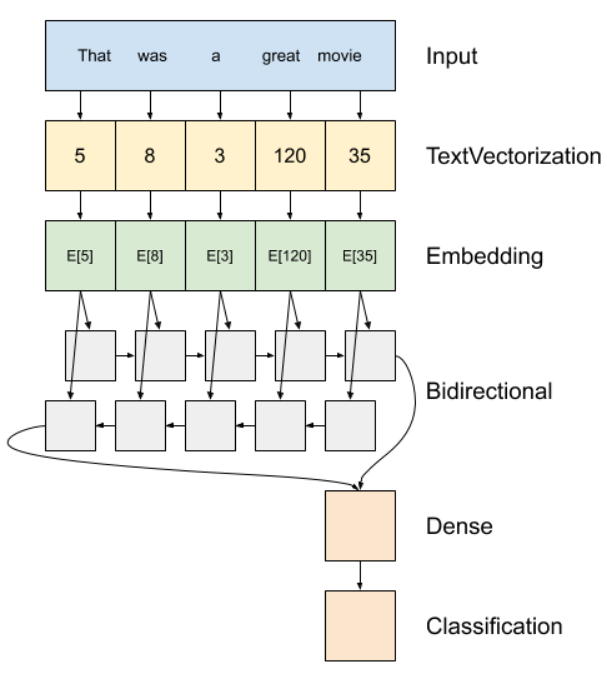
💡 ml, dl의 텍스트 데이터 인코딩 방식
-
머신러닝에서는 BOW, TF-IDF 인코딩 방식을 주로 사용하고 딥러닝에서도 사용하기도 함
-
RNN에서는 순차적으로 데이터를 인코딩해주는 시퀀스 인코딩 방식을 사용하면 좀 더 나은 성능을 내기도 함
💡padding 한 이후 train과 test의 결과 shape의 열 개수가 다르다면 maxlen으로 두 개가 같도록 맞춰줘야 함
💡RNN은 주로 시퀀스 데이터에 사용
- 시퀀스 데이터는 연관된 연속의 데이터로 순서가 있는 자료로, 시계열 자료나 텍스트 자료가 대표적
- 실제 사용하는 데이터들 중에는 시퀀스 데이터가 대부분을 차지(음성인식, 자연어, 주가 등)
- 연속된 데이터이므로 순서가 매우 중요하게 작용하며, 과거의 영향을 받기 때문에 과거 정보의 맥락을 고려하는 새로운 모델이 필요 => RNN 등장
🤔validation_split 을 사용하면 성능이 잘 안 나오는데 train_test_split 으로 train 을 train, valid로 나눠준 데이터를 사용하면 좀 더 나은 성능이 나오는 이유는?
- stratify 유무의 차이
💡RNN의 유형
입력 갯수와 출력 갯수에 따른 유형으로, 입력과 출력의 길이에 따라서 달라지는 RNN의 다양한 형태가 있음
-
One to one: 가장 기본적인 모델(simpleRNN)
-
One to many: 하나의 이미지를 문장으로 표현할 수 있음
- e.g.) 앉아있는 고양이 등
- 하나의 벡터를 반복적으로 입력하여 시퀀스를 출력
-
Many to one: 단어 시퀀스에 대해서 하나의 출력을 하는 구조
- e.g.) 감정 분류, 주가 등락을 통한 회사의 파산 여부 분류 등
- 시퀀스를 입력받아 단일 벡터를 출력
-
Many to many: 여러 개의 단어를 입력받아 여러 개의 단어로 구성된 문장을 명사, 동사, 형용사 등으로 구분 반환하는 번역기
- 입력 시퀀스가 다른, 시간 단계에서 비디오의 각 프레임의 기능 표현인 비디오 분류에도 사용
- 시퀀스를 입력받아 시퀀스를 출력 (주가 예측 등)
💡워드 임베딩
워드 임베딩이란 단어를 특정 차원의 벡터로 바꾸어 주는 것
텍스트를 벡터화하는 세 가지 방법
💡 1) one-hot-encoding
- 각 단어를 나타내기 위해 길이가 어휘와 동일한 0 벡터를 만든 다음 단어에 해당하는 색인에 1을 배치
- 희소벡터가 생성됨
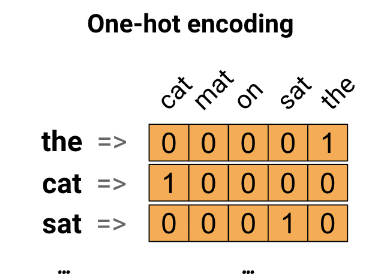
💡 2) 고유 번호로 인코딩
- 각 단어에 고유 번호를 부여해서 인코딩
- 조밀한 벡터가 생성되지만 고유 번호를 부여하는 것이 임의적이기 때문에 단어 간의 관계를 파악하기 힘듦
- 정수로 인코딩되기 때문에 모델이 해석하기 어려움
💡 3) word embedding(n-dimensional embedding)
- 유사한 단어가 유사한 인코딩(직접 지정 할 필요 없음)을 갖는 효율적이고 조밀한 표현(임베딩은 부동 소수점 값의 벡터)을 사용하는 방법을 제공
- 큰 데이터 세트로 작업할 때 작게는 8차원, 최대 1024차원의 단어 임베딩을 보는 것이 일반적이며, 더 높은 차원의 임베딩은 단어 간의 세분화된 관계를 캡처할 수 있지만 학습하는 데 더 많은 데이터가 필요함
RNN explainer
https://damien0x0023.github.io/rnnExplainer/
💡bidirectional network
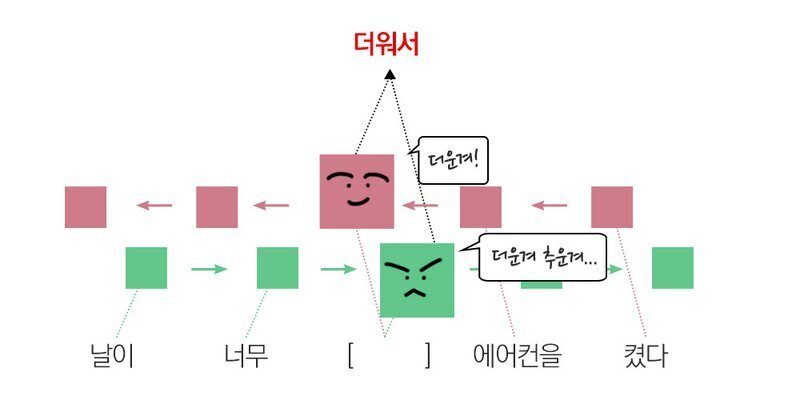
- 순차 RNN 학습 방향에는 한계가 있기 때문에 양방향의 학습을 통해서 해결하는 기법
- 순차 RNN으로만 하면 날이, 너무만 보고 날씨의 상태를 파악해야하지만 양방향 학습을 이용하면 켰다, 에어컨을 보고 날씨의 상태를 더 잘 유추할 수 있음
🤔Bidirectional 과정에서 차원 축소 기능이 있을까?
- 차원 축소 기능은 없음
TF 공식문서
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Bidirectional
💡LSTM(Long Short-Term Memory)
-
RNN의 기울기 소실: RNN의 구조상 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우, 역전파하는 과정이 너무 길어져 기울기 값이 아주 작아져 소실되는 문제 발생(초기 입력이 잊혀져 예측 성능이 떨어짐)
- 입력의 길이가 길어져도 이전 정보를 더 오래 기억하는 학습 방법의 필요성
-
장단기 메모리(Long Short-Term Memory, LSTM)는 순환 신경망(RNN) 기법의 하나
-
메모리 셀, 입력 게이트, 출력 게이트, 망각 게이트를 이용해 기존 순환 신경망(RNN)의 문제인 기울기 소실 문제를 방지함
- 비교적 짧은 시퀀스에 대해서만 효과를 보이는 RNN의 단점인 장기 의존성 문제(the problem of Long-Term Dependencies)를 개선했음
-
LSTM 알고리즘은 Cell State라고 불리는 특징층을 하나 더 넣어 Weight를 계속 기억할 것인지 결정
-
셀 상태(Cell state)는 정보를 추가하거나 삭제하는 기능을 담당 >> LSTM은 과거의 데이터를 계속해서 업데이트
-
기존 RNN의 경우, 정보와 정보사이의 거리가 멀면, 초기의 Weight값이 유지되지 않아 학습능력이 저하됨
-
장점 : 각각의 메모리 컨트롤이 가능하고 결과값 컨트롤이 가능
-
단점 : 메모리가 덮어씌워 질 가능성이 있고 연산속도가 느림
📚Tensorflow api
tf.keras.layers.LSTM(
units, activation='tanh', recurrent_activation='sigmoid', use_bias=True, kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None,
recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0,
return_sequences=False, return_state=False, go_backwards=False, stateful=False,
time_major=False, unroll=False, **kwargs)💡 GRUs (Gated Recurrent Units)
-
LSTM을 변형시킨 알고리즘으로, Gradient Vanishing의 문제를 해결함
-
LSTM은 초기의 weight가 계속 지속적으로 업데이트되었지만, GRUs는
Update Gate와 Reset Gate를 추가하여, 과거의 정보를 어떻게 반영할 것인지 결정(GRU는 게이트가 2개, LSTM은 3개) -
Update Gate는 과거의 상태를 반영하는 Gate이며, Reset Gate는 현 시점 정보와 과거 시점 정보의 반영 여부를 결정
-
게이트 순환 유닛으로 장단기 메모리(LSTM)과 달리 출력 게이트가 없는 간단한 구조를 가짐
-
데이터 양이 적어 사용해야 할 매개변수의 양이 적다면 GRU를 사용하고, 데이터 양이 많으면 LSTM의 성능이 더 나음
- 장점 : 연산속도가 빠르고 LSTM처럼 덮어씌워 질 가능성이 없음
- 단점 : 메모리와 결과값 컨트롤 불가
📚Tensorflow api
tf.keras.layers.GRU(
units, activation='tanh', recurrent_activation='sigmoid', use_bias=True, kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None,
dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False, time_major=False, reset_after=True, **kwargs )📌summary
텍스트 데이터 벡터화 하는 방법?
- 토큰화(str.split()) => one-hot-encoding => bag of words(min_df, max_df, analyzer, stopwords, n-gram)
- => TF-IDF(너무 자주 등장하는 단어는 낮은 가중치, 특정 문서에만 자주 등장하는 단어는 높은 가중치)
- RNN 은 순서가 있는 데이터를 예측할 때 주로 사용하는데 BOW 순서를 보존하지 않음. 그래서 시퀀스 방식의 인코딩을 사용함.
- Embedding => 여러 각도에서 단어와 단어 사이의 거리를 봄. 가까운 거리에 있는 단어는 유사한 단어이고 거리가 멀 수록 의미가 먼 단어임.
- => 의미를 좀 더 보존할 수 있게 되었음.
텍스트 데이터 전처리 방법?
- 정규표현식 => 텍스트 정규화
- 불용어 => 나, 너, 그것, 이것, 저것 처럼 자주 등장하지만 큰 의미를 갖지 않는 단어 제외
- 형태소 분석 => 의미가 없는 조사, 어미, 구두점 등을 제외
- 어간추출(stemming 원형을 보존하지 않음), 표제어표기법(lemmatization, 원형을 보존)
RNN
- time-step 을 갖는 데이터에 주로 사용, 예) 자연어(챗봇), 음성, 시계열데이터(주가 데이터), 심전도 데이터
- RNN, LSTM, GRU
- BPTT
🤔텍스트 데이터 전처리는 보통 semantic한 내용만 남기는 게 목적인가?
- 불용어나 조사,어미,구두점 같은 형태소는 크게 의미를 가지지 않기 때문에 자연어의 의미(신호)를 모델에게 전달해 계산을 효율적으로 할 수 있도록 만들어주는 것이 주 목적
💡퀴즈 정리
-
return_sequences는 시퀀스 출력 여부로 레이어를 여러개로 쌓아올릴 때는 return_sequence=True 옵션을 사용한다.
-
Embedding layer을 통해 출력된 임베딩 벡터의 최종 차원은 (batch_size, vocab_size, embedding_dim)이 됨.
모델 구성층 중 각 단어의 유사도를 계산하여 주어진 배열을 정해진 길이로 압축해주는 층은?
- Embedding layer
각기 다른 문장(또는 문서)의 길이를 동일한 길이로 맞춰주어 모델에서 같은 길이의 문장에 대해서 하나의 행렬로 보고, 한꺼번에 묶어서 처리할 수 있도록 하는 방법은?
- Padding
딥러닝 모델에 자연어 데이터를 바로 넣는다면 인식하지 못하는 문제가 있어, 문자열 데이터를 숫자형으로 바꿔주는 작업(인코딩)을 위해 사용되는 방법은?
- Vectorizer
자연어 처리 중 주어진 코퍼스(corpus)에서 의미있는 단위로 나누는 작업을 위해 사용되는 방법은?
- Tokenizer
📌오늘의 회고
- 사실(Fact) : 서울시 다산콜센터 게시판 데이터를 통해 다양한 RNN 알고리즘을 학습했다.
- 느낌(Feeling) : LSTM과 GRU의 학습 속도가 simple RNN보다 빨라서 놀랐다.
- 교훈(Finding) : 조금 큰 텍스트 데이터를 사용해 텍스트 전처리부터 모델 구성까지 복습해봐야겠다.
