
Graph
Graph
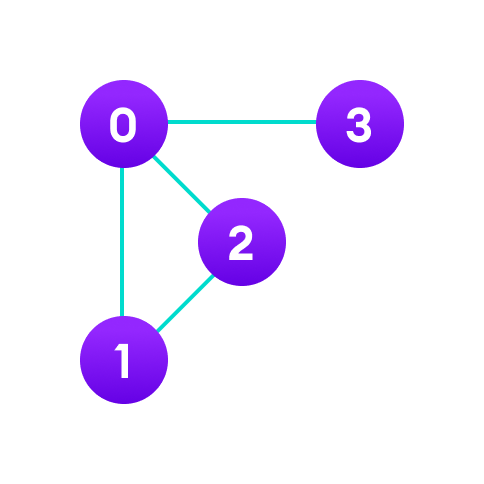
아이템 (사물 또는 추상적 개념)들과 이들 사이의 연결 관계를 표현한 자료 구조이다. 정점 (Vertex)의 집합과 이들을 연결하는 간선 (Edge)들로 구성되어 있다. 선형 자료 구조나 트리로 표현하기 어려운 M:N 관계를 표현하기 위해 주로 사용된다.
Vertex: 그래프의 데이터가 담긴 부분이다.Edge: 정점간의 연결관계이다.Adjacent: 정점과 정점을 연결하는 간선이 존재할 경우를 말한다.Degree: 하나의 정점에 연결된 간선의 개수이다.Path: 정점을 통해 연결되는 간선을 순서대로 나열한 것이다.
그래프의 종류에는 무향 그래프와 유행 그래프가 있다.
Undirected Graph: 양쪽 정점에서 간선을 통해 서로에게 도달이 가능한 그래프로 방향이 없다.Directed Graph: 한 정점에서 다른 정점으로는 도달 가능하지만 반대로는 불가능한 방향이 있는 그래프이다.Weighted Graph: 간선에 값이 추가된 형태로 해당 간선을 택할 때 드는 비용을 표현하기 위해 사용한다. 최단 거리, 최단 비용 문제에 사용된다.Complete Graph: 정점들이 가능한 모든 간선을 가진 그래프이다.
Adjacent Array
인접 행렬은 그래프의 간선을 표시하는 방법 중 하나이다. 정점의 개수를 V라고 할 때, V * V 크기의 2차원 배열을 활용한다. 행 번호와 열 번호를 각각 그래프의 정점에 대응하고 두 정점이 인접하면 1, 그렇지 않다면 0으로 나타내는 것이다.
| V | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 0 |
| 2 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 |
예를 들어 위의 인접 행렬은 노드 2와 노드 1이 연결되어 있음을 나타낸다. adjMax[i, j]로 표현하는데, 보통 i는 세로, j는 가로 index를 나타낸다. 하지만 인접 행렬은 보는 것처럼 빈 공간에 대한 공간 낭비가 심하다.
Adjacent List
공간 낭비를 최소화하기 위해 List로 구현된 배열을 사용해 간선을 표현하는 것이다.
!https://www.programiz.com/sites/tutorial2program/files/adjacency-list-graph.png
이렇게 각 정점마다 생긴 간선을 Linked List를 사용해 표현한 것이다. 이러면 간선의 개수 만큼만 공간을 사용하기 때문에 기존의 메모리 낭비에 대한 문제점을 어느 정도 해결할 수 있다.
Implement
public class AdjacentMatrix {
public void solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
// StringTokenizer: 입력받은 문자열을 띄어 쓰기 또는 지정된 delimiter를 기준으로 나누어서 한 단어씩 반환해 주는 도구
StringTokenizer graphTokenizer // 8 10 입력
= new StringTokenizer(reader.readLine());
// StringTokenizer.nextToken(): 다음 단어를 가져오기
int maxNode = Integer.parseInt(graphTokenizer.nextToken());
int edges = Integer.parseInt(graphTokenizer.nextToken());
// 인접 행렬: 2차원 배열
// 계산할 때마다 -1 을 해 주거나 인접 행렬을 하나씩 더 늘리거나
int[][] adjMatrix = new int[maxNode][maxNode]; // 0~ 7 까지 표현 가능한 인접 행렬
for (int i = 0; i < edges; i++) {
StringTokenizer edgeTokenizer
= new StringTokenizer(reader.readLine());
int startNode = Integer.parseInt(edgeTokenizer.nextToken()); // i 입력
int endNode = Integer.parseInt(edgeTokenizer.nextToken()); // j 입력
// 유향 그래프의 경우 이것만
adjMatrix[startNode][endNode] = 1;
// 무향 그래프의 경우에만 수행
adjMatrix[edges][startNode] = 1;
}
}
}Tokenizer: 입력받은 문자열을 띄어 쓰기 또는 지정된 delimiter를 기준으로 나누어서 한 단어씩 반환해 주는 도구이다.
public class AdjacentList {
public void solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
// StringTokenizer: 입력받은 문자열을 ' ' (또는 지정된 delimiter) 를 기준으로 나누어서
// 한 단어씩 반환해주는 도구
StringTokenizer graphTokenizer // 8 10
= new StringTokenizer(reader.readLine());
// StringTokenizer.nextToken(): 다음 단어를 가져오기
int maxNodes = Integer.parseInt(graphTokenizer.nextToken()); // 8
int edges = Integer.parseInt(graphTokenizer.nextToken()); // 10
// 안쪽의 List<Integer>가 maxNodes의 길이를 반드시 가지지는 않을 것이다.
List<List<Integer>> adjList = new ArrayList<>();
// 먼저 리스트의 내용물을 초기화 해준다.
for (int i = 0; i < maxNodes; i++) {
adjList.add(new ArrayList<>());
}
// 간선의 갯수만큼 반복해서 입력을 받는다.
for (int i = 0; i < edges; i++) {
// 다음줄을 단어 단위로 나눠주는 Tokenizer
StringTokenizer edgeTokenizer
= new StringTokenizer(reader.readLine());
// 입력 줄의 첫 숫자
int startNode = Integer.parseInt(edgeTokenizer.nextToken());
// 입력 줄의 두번째 숫자
int endNode = Integer.parseInt(edgeTokenizer.nextToken());
// adjList 의 startNode 번째 리스트에 endNode 를 첨부한다.
// 유향 그래프일 경우 아래 줄 만
adjList.get(startNode).add(endNode);
// 무향 그래프일 경우 아래 줄도 함께
adjList.get(endNode).add(startNode);
}
// 선택사항: DFS나 BFS를 할때 이왕이면 방문순서를
// '작은 숫자부터' 와 같은 조건을 붙이고 싶다면
// 정렬해야 한다.
for (List<Integer> adjRow: adjList) {
// 정렬해주는 Collections.sort 메소드
Collections.sort(adjRow);
}
for (List<Integer> adjRow: adjList) {
System.out.println(adjRow);
}
}
public static void main(String[] args) throws IOException {
new AdjacentList().solution();
}
}DFS
루트 노드에서 시작하여 한 방향으로 갈 수 있는 경로가 있는 곳까지 깊이 탐색하는 탐색법이다. 갈 곳이 없어지면 가장 마지막 갈림길로 돌아와서 다른 정점을 탐색한다. 가장 마지막에 만났던 갈림길로 돌아가기 때문에 후입 선출의 스택을 많이 활용한다. 함수의 호출과 복귀를 관리하기 위해서 컴퓨터는 시스템 스택을 활용한다. 따라서 재귀 함수를 사용하면 DFS를 구현할 수 있다.
public class RecursiveDFS {
public void solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
// StringTokenizer: 입력받은 문자열을 띄어 쓰기 또는 지정된 delimiter를 기준으로 나누어서 한 단어씩 반환해 주는 도구
StringTokenizer graphTokenizer // 8 10 입력
= new StringTokenizer(reader.readLine());
// StringTokenizer.nextToken(): 다음 단어를 가져오기
int maxNodes = Integer.parseInt(graphTokenizer.nextToken());
int edges = Integer.parseInt(graphTokenizer.nextToken());
// 인접 행렬: 2차원 배열
// 계산할 때마다 -1 을 해 주거나 인접 행렬을 하나씩 더 늘리거나
int[][] adjMatrix = new int[maxNodes][maxNodes]; // 0~ 7 까지 표현 가능한 인접 행렬
for (int i = 0; i < edges; i++) {
StringTokenizer edgeTokenizer
= new StringTokenizer(reader.readLine());
int startNode = Integer.parseInt(edgeTokenizer.nextToken()); // i 입력
int endNode = Integer.parseInt(edgeTokenizer.nextToken()); // j 입력
// 유향 그래프의 경우 이것만
adjMatrix[startNode][endNode] = 1;
// 무향 그래프의 경우에만 수행
adjMatrix[endNode][startNode] = 1;
}
boolean[] visited = new boolean[maxNodes];
List<Integer> visitOrder = new ArrayList<>();
recursive(0, maxNodes, adjMatrix, visited, visitOrder);
System.out.println(visitOrder);
}
// 목적: dfs를 했을 때 정점 방문 순서 기록
public void recursive(
// 다음 (이번 호출)에서 방문할 곳
int next,
// 원활한 순회를 위한 maxNodes
int maxNodes,
// 인접 정점 정보 (그래프 정보)
int[][] adjMatrix,
// 방문한 정점 정보
boolean[] visited,
// 방문 순서 기록을 위한 리스트
List<Integer> visitOrder
) {
visited[next] = true;
visitOrder.add(next);
for (int i = 0; i < maxNodes; i++) {
// 연결이 되어 있으며 방문한 적 없을 때 재귀 호출
if(adjMatrix[next][i] == 1 && !visited[i])
recursive(i, maxNodes, adjMatrix, visited, visitOrder);
}
}
public static void main(String[] args) throws IOException {
RecursiveDFS recursiveDFS = new RecursiveDFS();
recursiveDFS.solution();
}
}재귀 호출은 컴퓨팅 자원을 많이 소모하긴 하지만 코드 가독성이 좋고 문제 해결이 빠르기 때문에 선호된다. 함수를 호출하는 과정에서 스택 자료 구조를 쓰기 때문에 이를 이용해서 DFS를 구현하는 것이다.
BFS
루트 노드의 자식 노드 또는 인접한 정점들을 모두 차례로 방문한다. 방문했던 자식 노드들을 시작점으로 다시 인접한 정점들을 차례로 방문한다. 선입선출 형태의 자료 구조인 Queue를 많이 활용하고, 인접한 노드들부터 차례대로 방문을 하기 때문에 시작 정점과 끝 정점 사이의 최단 거리를 구하는 데 유용하다.
public class ListBreadthFirstSearch {
public void solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
// StringTokenizer: 입력받은 문자열을 ' ' (또는 지정된 delimiter) 를 기준으로 나누어서
// 한 단어씩 반환해주는 도구
StringTokenizer graphTokenizer // 8 10
= new StringTokenizer(reader.readLine());
// StringTokenizer.nextToken(): 다음 단어를 가져오기
int maxNodes = Integer.parseInt(graphTokenizer.nextToken()); // 8
int edges = Integer.parseInt(graphTokenizer.nextToken()); // 10
// 안쪽의 List<Integer>가 maxNodes의 길이를 반드시 가지지는 않을 것이다.
List<List<Integer>> adjList = new ArrayList<>();
// 먼저 리스트의 내용물을 초기화 해준다.
for (int i = 0; i < maxNodes; i++) {
adjList.add(new ArrayList<>());
}
// 간선의 갯수만큼 반복해서 입력을 받는다.
for (int i = 0; i < edges; i++) {
// 다음줄을 단어 단위로 나눠주는 Tokenizer
StringTokenizer edgeTokenizer
= new StringTokenizer(reader.readLine());
// 입력 줄의 첫 숫자
int startNode = Integer.parseInt(edgeTokenizer.nextToken());
// 입력 줄의 두번째 숫자
int endNode = Integer.parseInt(edgeTokenizer.nextToken());
// adjList 의 startNode 번째 리스트에 endNode 를 첨부한다.
// 유향 그래프일 경우 아래 줄만
adjList.get(startNode).add(endNode);
// 무향 그래프일 경우 아래 줄도 함께
adjList.get(endNode).add(startNode);
}
// 선택사항: DFS나 BFS를 할때 이왕이면 방문순서를
// '작은 숫자부터' 와 같은 조건을 붙이고 싶다면
// 정렬해야 한다.
for (List<Integer> adjRow : adjList) {
// 정렬해주는 Collections.sort 메소드
Collections.sort(adjRow);
}
// BFS
// 다음 방문 대상 기록용 Queue
Queue<Integer> toVisit = new LinkedList<>();
// 방문 순서 기록용 List
List<Integer> visitedOrder = new ArrayList<>();
// 방문 기록용 boolean[]
boolean[] visited = new boolean[maxNodes];
int next = 0;
toVisit.offer(next);
// 큐가 비어있지 않은 동안 반복
while (!toVisit.isEmpty()) {
// 다음 방문 정점 회수
next = toVisit.poll();
// 이미 방문 했다면 다음 반복으로
if (visited[next]) continue;
// 방문했다 표시
visited[next] = true;
// 방문한 순서 기록
visitedOrder.add(next);
// 다음 방문 대상을 검색한다.
// adjList.get(next)에 담겨있는 미방문 요소들을 다 넣는다.
List<Integer> canVisitList = adjList.get(next);
for (Integer canVisit : canVisitList) {
if (!visited[canVisit])
toVisit.offer(canVisit);
}
// // 다음 방문 대상을 검색한다.
// for (int i = 0; i < maxNodes + 1; i++) {
// if (adjMap[next][i] == 1 && !visited[i])
// toVisit.offer(i);
// }
}
// 출력
System.out.println(visitedOrder);
}
public static void main(String[] args) throws IOException {
new ListBreadthFirstSearch().solution();
}
}In Real
실제 문제에서는 인접 행렬, 리스트 형태로 입력이 주어지지 않는 경우도 빈번하다. 미로 탐색이 그 예시이다. 인접 행렬을 열심히 찾기보다는 매 칸마다 다음에 도달 가능한 정점들을 판단하는 것이 중요하다.
즉 다음 방문 대상을 검색할 때 내 위치의 사방의 값 중 이동 가능한 지점을 넣으면 되는 것이다.
방문했다는 표시는 방문 유무를 저장하는 boolean[][]를 통해 저장하는 방법이 있다. 혹은 지나간 지점을 돌아갈 수 없는 경우는 이미 지나온 지점을 벽으로 치환해 버리는 방법도 가능하다.
Validation
유효성 검사
유효성 검사란 일반적인 서비스의 경우 사용자가 데이터를 입력할 때, 우리가 원하는 데이터를 입력했는지 검사하는 것이다. 즉 사용자가 입력한 데이터가 허용된 형태인지 검사하는 과정이다.
spring-boot-starter-validation
- Jakarta Bean Validation: 유효성 검증을 위한 기술을 명세한 것이다. 어떤 항목이 어떤 규칙을 지켜야 하는지를 표시하는 기준이다.
- Hibernate Validation: Jakarta Bean Validation을 기준으로 실제로 검증해 주는 프레임워크다
둘의 관계는 JPA와 Hibernate ORM과 유사하다.
UserDto를 만든다고 생각해 보자. 사용자의 정보 중 username은 절대로 공백이어서는 안 된다. 따라서 @NotBlank Annotation을 사용할 수 있다.
@Data
public class UserDto {
private Long id;
@NotBlank // 비어 있지 않음
private String username;
private String email;
private String phone;
}이후 확인을 위해 Controller를 만들어 보자.
@RestController
@Slf4j
public class UserController {
@PostMapping("/users")
public ResponseEntity<Map<String, String>> addUser(
// UserDto가 우리가 정의한 요구 사항을
// 지키고 있는지 유효성 검사
@RequestBody UserDto dto
) {
log.info(dto.toString());
Map<String, String> responseBody = new HashMap<>();
responseBody.put("message", "success!");
return ResponseEntity.ok(responseBody);
}
}Postman으로 요청이 가는지 확인해 보자.
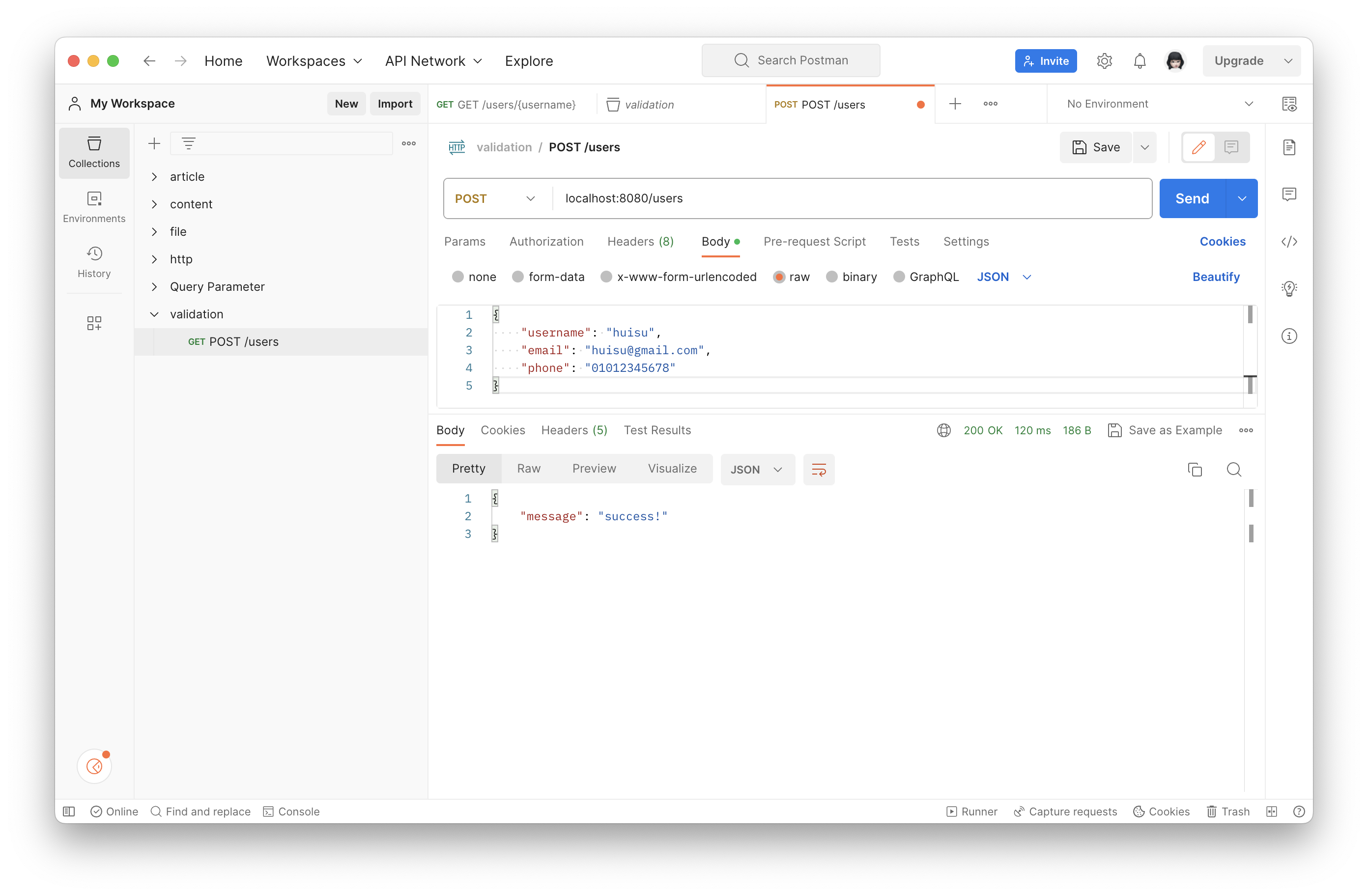
필수로 있어야 하는 이름을 지우고 보내 보자.

잘 돌아가지만 log에서 null 값으로 들어가는 것을 볼 수 있다.
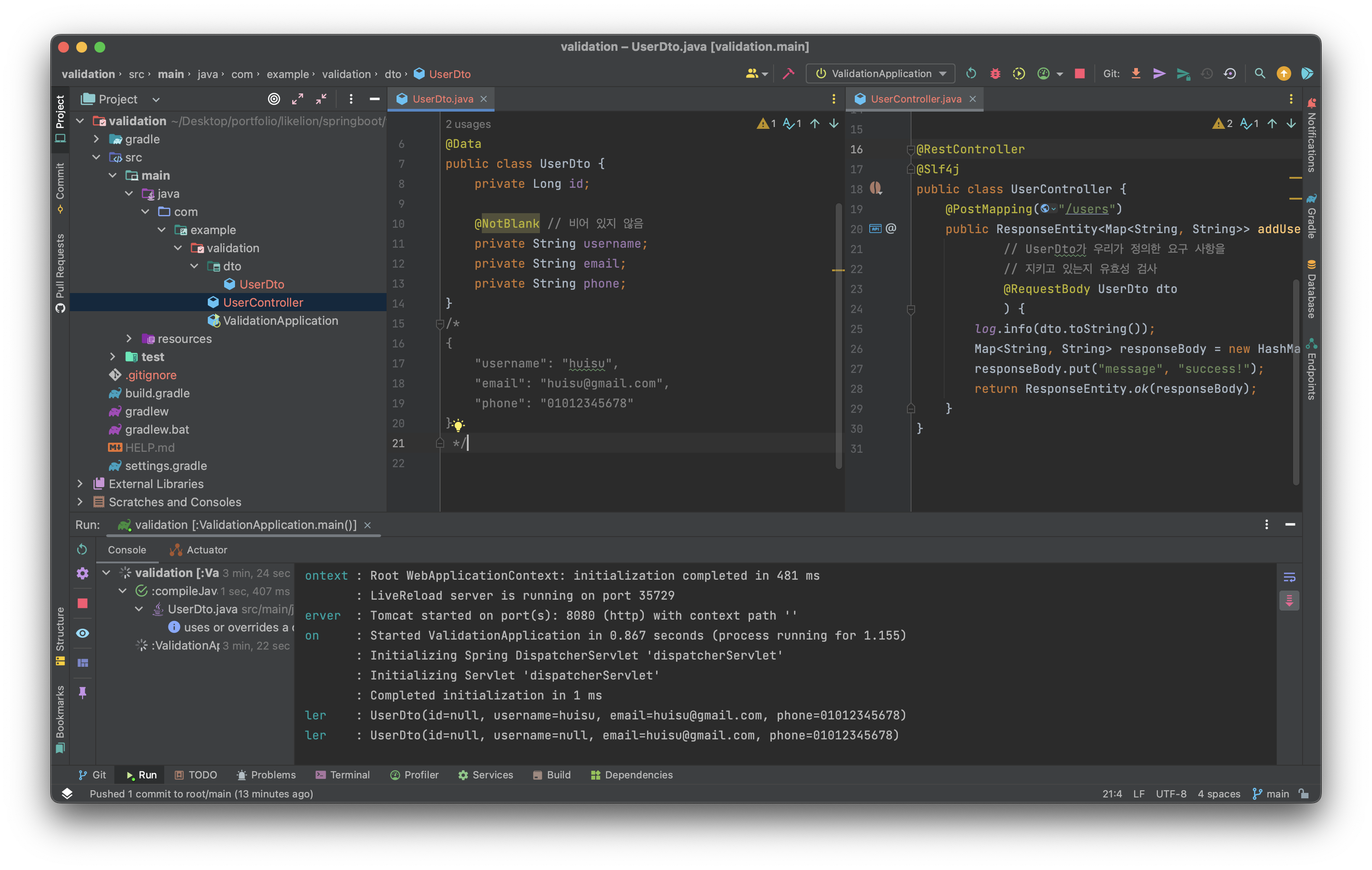
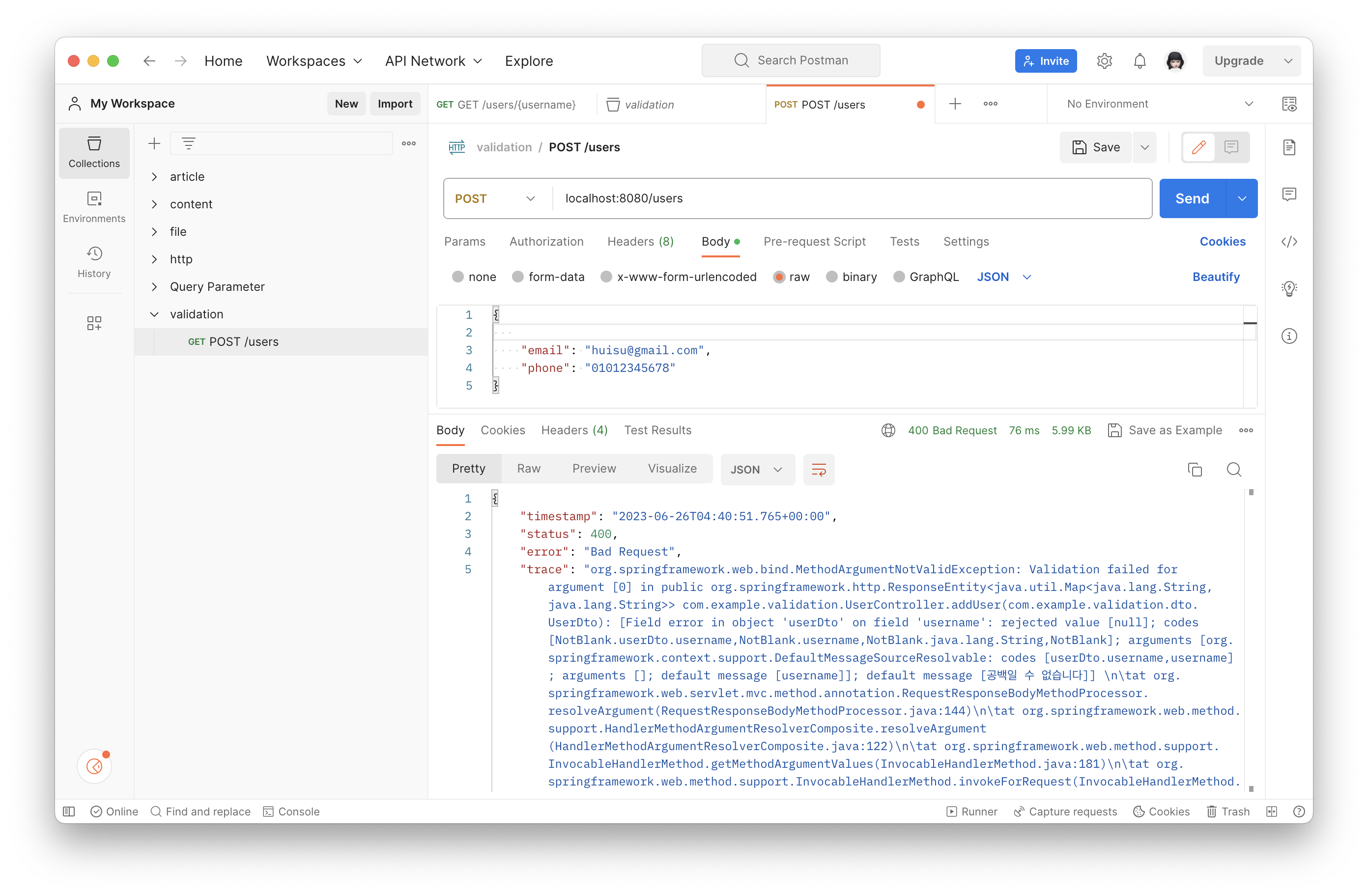
유효성 검사를 하기 위해 Controller에 @Valid Annotation 을 작성해 보자.
@RestController
@Slf4j
public class UserController {
@PostMapping("/users")
public ResponseEntity<Map<String, String>> addUser(
// UserDto가 우리가 정의한 요구 사항을
// 지키고 있는지 유효성 검사
**@Valid**
@RequestBody UserDto dto
) {
log.info(dto.toString());
Map<String, String> responseBody = new HashMap<>();
responseBody.put("message", "success!");
return ResponseEntity.ok(responseBody);
}
}다시 시도해 보면 안 되는 것을 확인할 수 있다.
외에도 @Email (형식이 이메일이어야 하는 경우)등을 지정할 수 있다.
@Data
public class UserDto {
private Long id;
@NotBlank // 비어 있지 않음
private String username;
**@Email** // 형식이 이메일이어야 한다
private String email;
private String phone;
}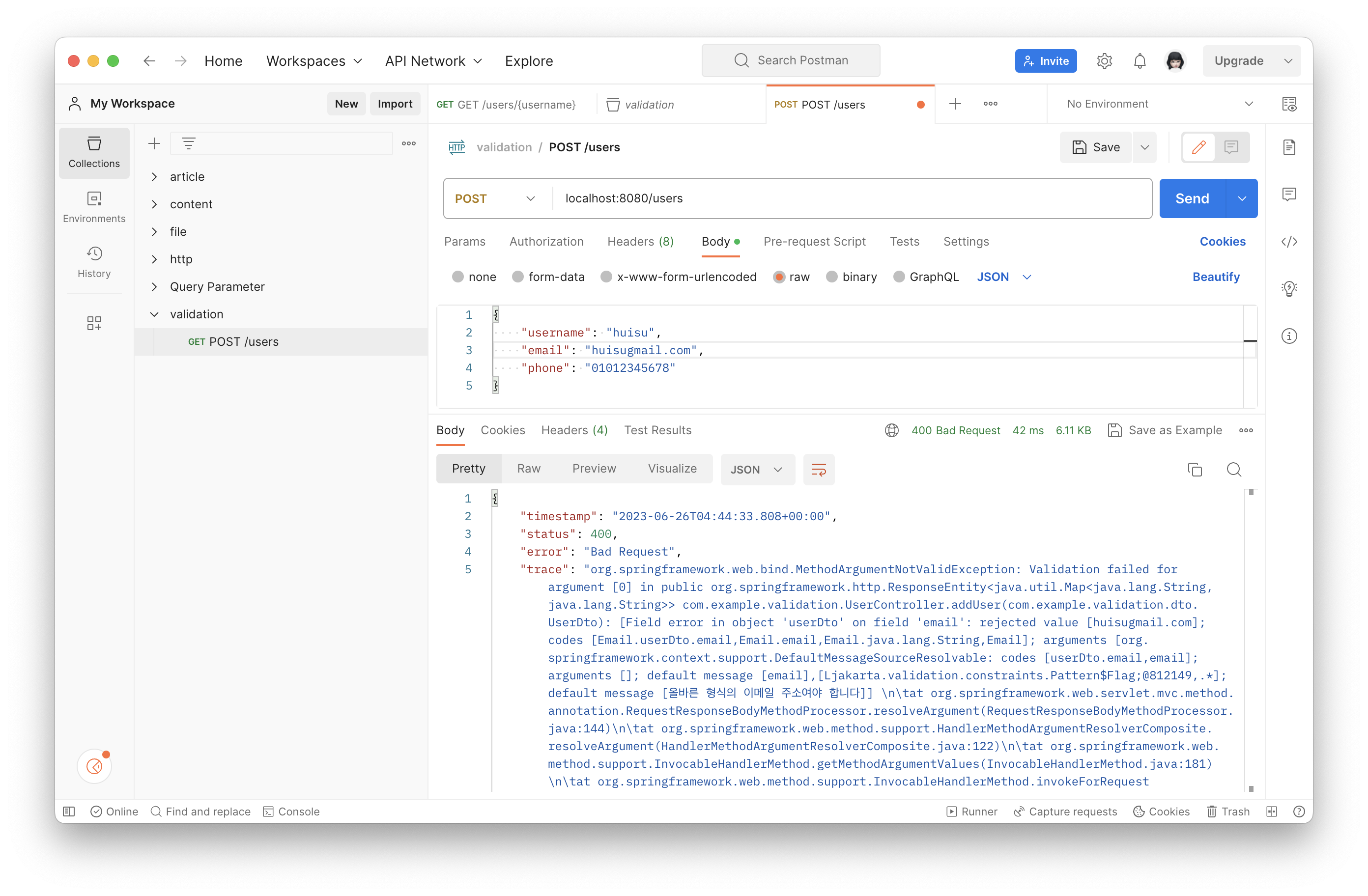
하지만 이 오류 응답은 기술 스택이나 기타 정보까지 유추하기 너무 쉽다. 즉 사용자에게 필요 이상의 정보를 노출시키고 있는 것이다.
Exception Handler
validation 에러는 보통 사용자의 입력값이 잘못되어서 발생하는 경우가 많다. 따라서 개발자가 하나하나 제어하기란 어렵다. 따라서 @ExceptionHandler를 사용한다.
@RestController
@Slf4j
public class UserController {
@PostMapping("/users")
public ResponseEntity<Map<String, String>> addUser(
// UserDto가 우리가 정의한 요구 사항을
// 지키고 있는지 유효성 검사
@Valid
@RequestBody UserDto dto
) {
log.info(dto.toString());
Map<String, String> responseBody = new HashMap<>();
responseBody.put("message", "success!");
return ResponseEntity.ok(responseBody);
}
**@ExceptionHandler(MethodArgumentNotValidException.class)
@ResponseStatus(HttpStatus.BAD_REQUEST)
// 이 메소드에 대해서 상태 코드가 bad request로 고정
public Map<String, String> handleValidationException(
MethodArgumentNotValidException exception
) {
Map<String, String> errors = new HashMap<>();
for (FieldError error: exception.getBindingResult().getFieldErrors()
) {
errors.put(error.getField(), error.getDefaultMessage());
}
return errors;
}**
}확인해 보면 메시지가 잘 나오는 것을 확인할 수 있다.
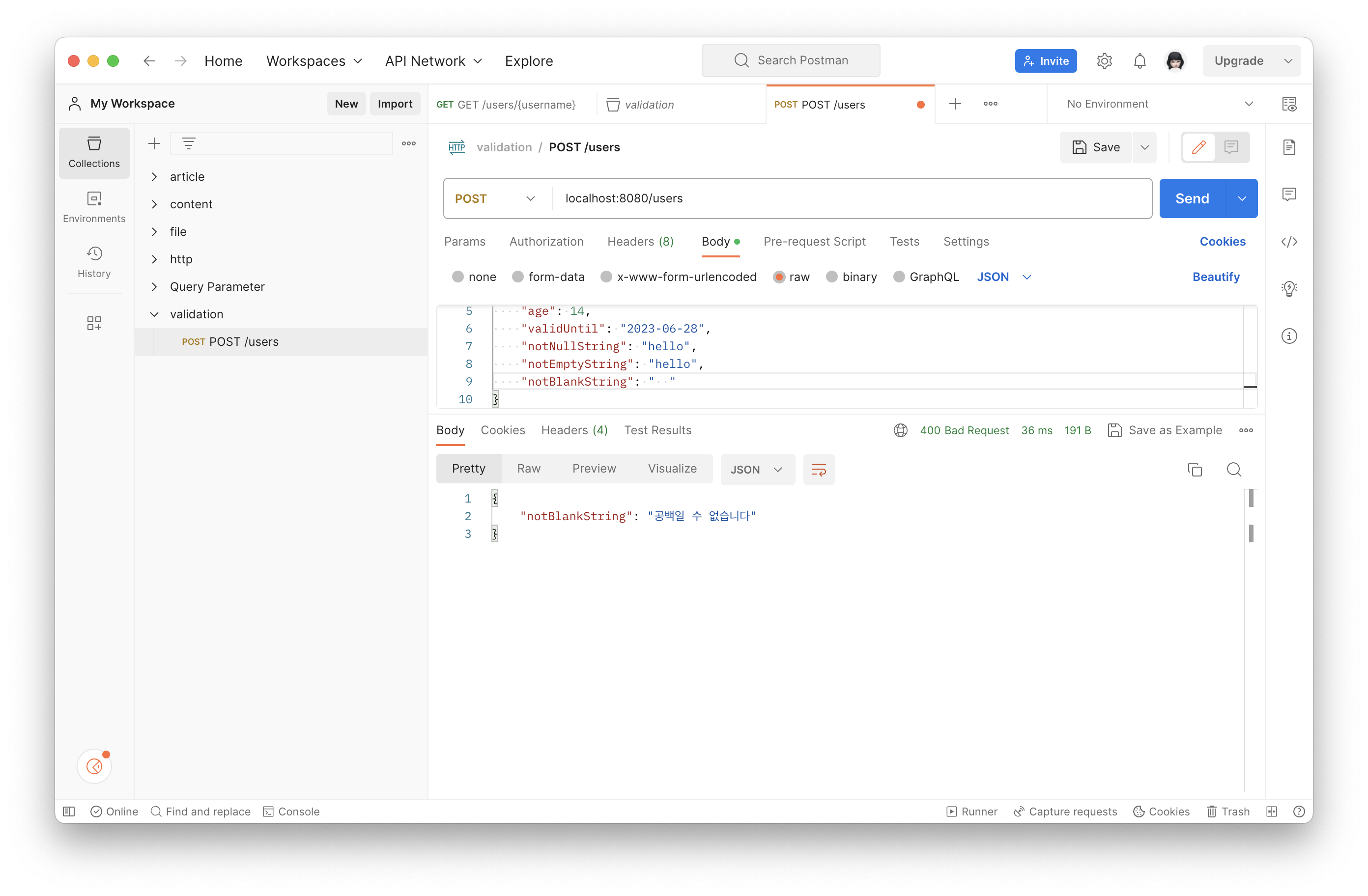
이 메시지도 내가 마음대로 바꾸고 싶다면 UserDto에서 전해 줄 수 있다.
@Data
public class UserDto {
private Long id;
@NotBlank // 비어 있지 않음
private String username;
@Email // 형식이 이메일이어야 한다
private String email;
@NotNull
private String phone;
@NotNull
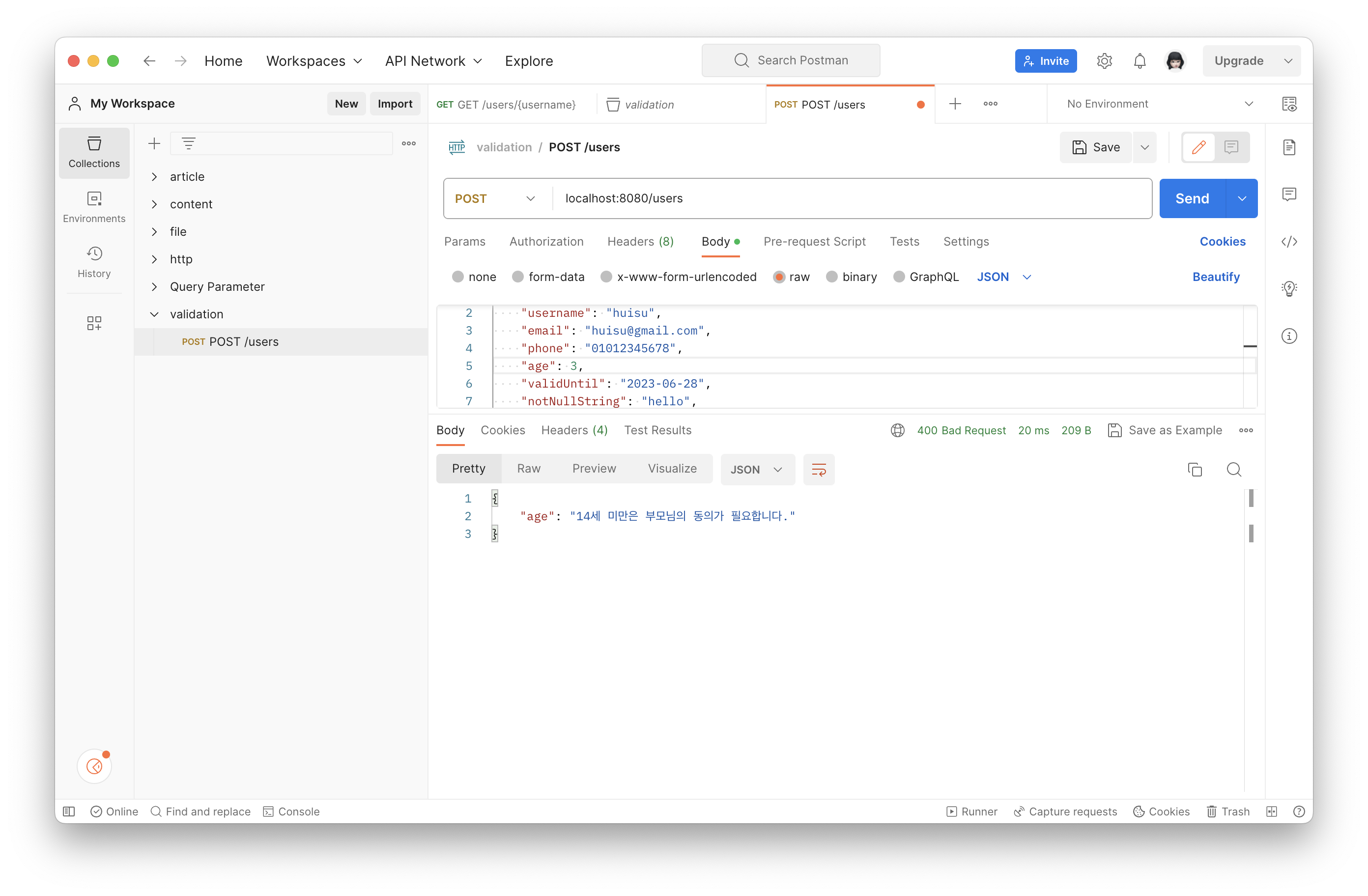
@Min(value = 14, **message = "14세 미만은 부모님의 동의가 필요합니다."**)
private Integer age;
@Future
private LocalDate validUntil;
@NotNull // null이 아닌지만 검증
private String notNullString;
@NotEmpty // 길이가 0이 아닌지만 검증, String 이외에도 사용 가능
private String notEmptyString;
@NotBlank // 공백 문자로만 이루어졌는지 검증, 문자열에서만 사용 가능
private String notBlankString;
}
문제가 발생할 때마다 보내는 것이 아닌, 발생한 문제를 모두 종합해서 하나의 메시지로 전송한다. 또한 요청을 보낼 때마다 오류 순서가 다르게 나타나는데, JSON 자체가 순서가 없는 데이터 구조이니 key 값으로 구분해야 한다. Dto에서 정의한 순서대로 실행될 것이라고 기대하지 않는 것이 좋다.
Advanced…
이메일이 지정된 도메인 @gmail.com 등이도록 하는 어노테이션을 만들어 보자.
어노테이션을 만들고 누가 검사를 하는지 class를 만드는 것이 중요하다. constraints → annotaion 폴더 아래에 annotation을 만들어 보자.
이후 Annotaion을 만들면 된다.
@Target: 어노테이션을 붙일 수 있는 위치를 나타낸다.@Retention: 실행하고 있을 때 사라지면 안 된다는 뜻이다.- lombok 어노테이션은 빌드할 때만 필요하기 때문에 실행 중에는 필요 없어서 실행 중에 Retention이 필요하지는 않다.
- 데이터가 들어오는 시점에서 사용자의 데이터를 판별해야 하기 때문에 RUNTIME에 어노테이션을 보고 검증을 해야 한다.
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface EmailWhiteList {
}이후 이 Annotation을 사용하기 위해 구현 기능을 작성할 클래스를 정의한다. 수동 사용자 지정 유효성 검사를 위해 구현해야 하는 인터페이스인 ConstraintValidator<쓸 어노테이션, 검증을 적용할 데이터의 타입> 인터페이스의 구현체이다.
public class EmailWhiteListValidator
// 수동 사용자 지정 유효성 검사를 위해 구현해야 하는 인터페이스
// <쓸 어노테이션, 검증을 적용할 데이터의 타입>
implements ConstraintValidator<EmailWhiteList, String> {
private final Set<String> whiteList;
public EmailWhiteListValidator() {
this.whiteList = new HashSet<>();
this.whiteList.add("gmail.com");
this.whiteList.add("naver.com");
}
@Override
public boolean isValid(String value, ConstraintValidatorContext context) {
// 유효한 값일 때 true를 반환
String[] split = value.split("@");
String domain = split[split.length - 1];
return whiteList.contains(domain);
}
}다음에 만든 Annotation에도 내가 이 기능을 어디에 구현해 놓았다고 알려 줘야 한다. 또한 에러가 발생했을 때 반환할 annotation element도 작성해 준다.
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME) // 어노테이션이 언제까지 유지될 것인지
**@Constraint(validatedBy = EmailWhiteListValidator.class)**
public @interface EmailWhiteList {
// annotation element
String message() default "email not in whitelist";
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default {};
}이후 해당 Annotaion을 사용할 수 있다.
@Data
public class UserDto {
private Long id;
@NotBlank // 비어 있지 않음
private String username;
@Email // 형식이 이메일이어야 한다
**@EmailWhiteList**
private String email;
@NotNull
private String phone;
@NotNull
@Min(value = 14, message = "14세 미만은 부모님의 동의가 필요합니다.")
private Integer age;
@Future
private LocalDate validUntil;
@NotNull // null이 아닌지만 검증
private String notNullString;
@NotEmpty // 길이가 0이 아닌지만 검증, String 이외에도 사용 가능
private String notEmptyString;
@NotBlank // 공백 문자로만 이루어졌는지 검증, 문자열에서만 사용 가능
private String notBlankString;
}사용했을 때 우리가 만든 Annotation이 잘 작동하고 있음을 알 수 있다.
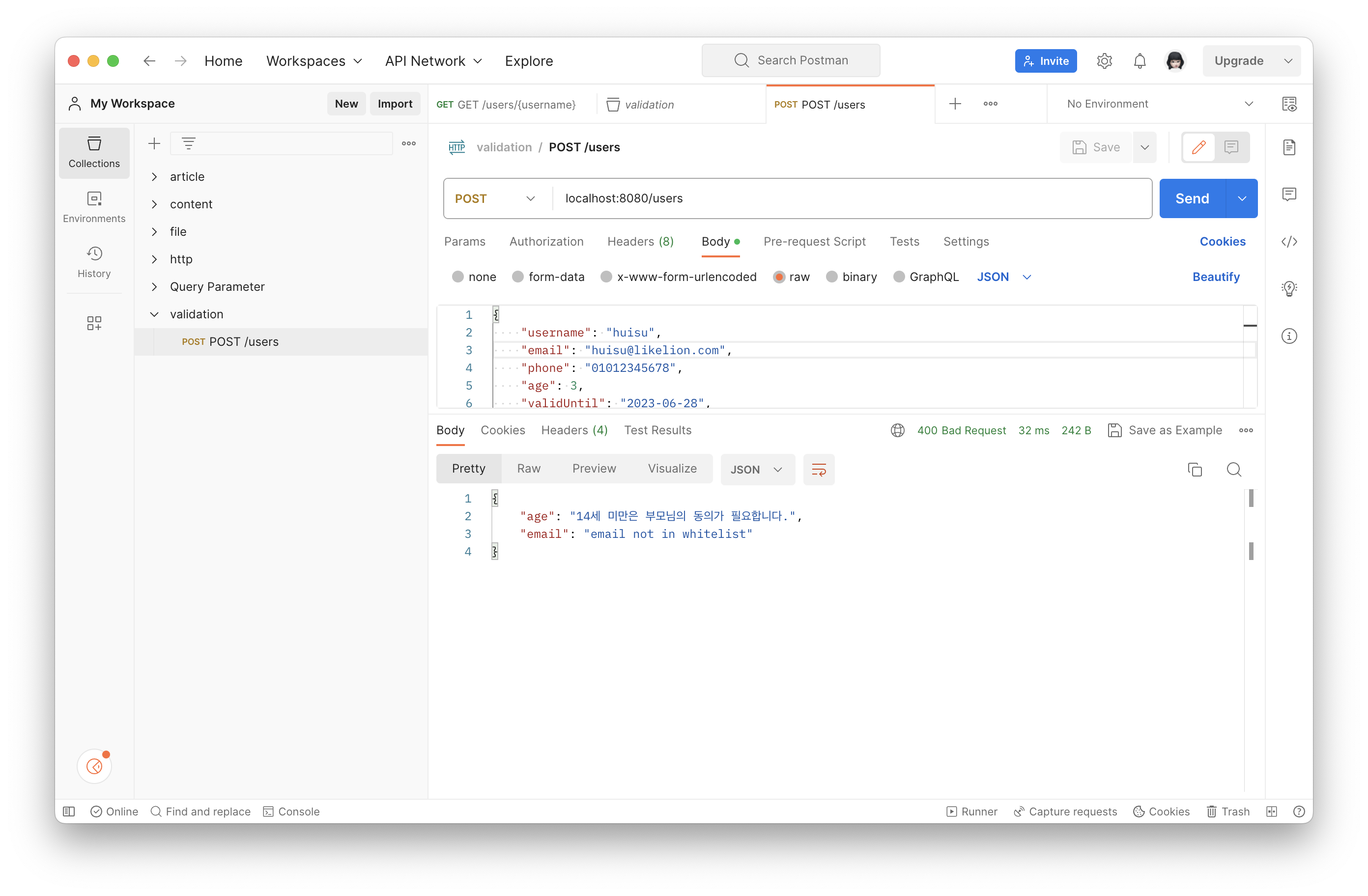

{kind=link}