
Algorithm
Dual Priority Queue
문제
이중 우선순위 큐(dual priority queue)는 전형적인 우선순위 큐처럼 데이터를 삽입, 삭제할 수 있는 자료 구조이다. 전형적인 큐와의 차이점은 데이터를 삭제할 때 연산(operation) 명령에 따라 우선순위가 가장 높은 데이터 또는 가장 낮은 데이터 중 하나를 삭제하는 점이다. 이중 우선순위 큐를 위해선 두 가지 연산이 사용되는데, 하나는 데이터를 삽입하는 연산이고 다른 하나는 데이터를 삭제하는 연산이다. 데이터를 삭제하는 연산은 또 두 가지로 구분되는데 하나는 우선순위가 가장 높은 것을 삭제하기 위한 것이고 다른 하나는 우선순위가 가장 낮은 것을 삭제하기 위한 것이다.
정수만 저장하는 이중 우선순위 큐 Q가 있다고 가정하자. Q에 저장된 각 정수의 값 자체를 우선순위라고 간주하자.
Q에 적용될 일련의 연산이 주어질 때 이를 처리한 후 최종적으로 Q에 저장된 데이터 중 최댓값과 최솟값을 출력하는 프로그램을 작성하라.
입력
입력 데이터는 표준입력을 사용한다. 입력은 T개의 테스트 데이터로 구성된다. 입력의 첫 번째 줄에는 입력 데이터의 수를 나타내는 정수 T가 주어진다. 각 테스트 데이터의 첫째 줄에는 Q에 적용할 연산의 개수를 나타내는 정수 k (k ≤ 1,000,000)가 주어진다. 이어지는 k 줄 각각엔 연산을 나타내는 문자(‘D’ 또는 ‘I’)와 정수 n이 주어진다. ‘I n’은 정수 n을 Q에 삽입하는 연산을 의미한다. 동일한 정수가 삽입될 수 있음을 참고하기 바란다. ‘D 1’는 Q에서 최댓값을 삭제하는 연산을 의미하며, ‘D -1’는 Q 에서 최솟값을 삭제하는 연산을 의미한다. 최댓값(최솟값)을 삭제하는 연산에서 최댓값(최솟값)이 둘 이상인 경우, 하나만 삭제됨을 유념하기 바란다.
만약 Q가 비어있는데 적용할 연산이 ‘D’라면 이 연산은 무시해도 좋다. Q에 저장될 모든 정수는 -231 이상 231 미만인 정수이다.
출력
출력은 표준출력을 사용한다. 각 테스트 데이터에 대해, 모든 연산을 처리한 후 Q에 남아 있는 값 중 최댓값과 최솟값을 출력하라. 두 값은 한 줄에 출력하되 하나의 공백으로 구분하라. 만약 Q가 비어있다면 ‘EMPTY’를 출력하라.
예제 입력 1
2
7
I 16
I -5643
D -1
D 1
D 1
I 123
D -1
9
I -45
I 653
D 1
I -642
I 45
I 97
D 1
D -1
I 333예제 출력 1
EMPTY
333 -45코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class four7662 {
public void solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int testCases = Integer.parseInt(reader.readLine());
StringBuilder outBuilder = new StringBuilder();
for (int i = 0; i < testCases; i++) {
int commandCount = Integer.parseInt(reader.readLine());
// Collections.reverseOrder로 최대 힙
PriorityQueue<Integer> maxQueue =
new PriorityQueue<>(Collections.reverseOrder());
PriorityQueue<Integer> minQueue =
new PriorityQueue<>();
// MAP 만들기
// KEY: 입력 데이터, VALUE: 입력 데이터의 출현 횟수
Map<Integer, Integer> tracker = new HashMap<>();
int size = 0;
for (int j = 0; j < commandCount; j++) {
// I 숫자: 숫자를 삽입
// D 1: 최대 원소 제거
// D -1: 최소 원소 제거
StringTokenizer commandToken = new StringTokenizer(reader.readLine());
String command = commandToken.nextToken();
int number = Integer.parseInt(commandToken.nextToken());
if (command.equals("I")) {
// 두 우선순위 큐에 삽입
maxQueue.offer(number);
minQueue.offer(number);
// tracker 안에 number가 등장한 적 없었다면 0
tracker.put(number, tracker.getOrDefault(number, 0) + 1);
size++;
} else if (number == 1 && size > 0) {
// tracker에 키가 존재하는 원소가 나올 때까지 queue에서 poll
// tracker에 키가 없다는 것은 입력된 적 있지만 다른 큐에서 이미 빠져나갔다는 뜻
while (!tracker.containsKey(maxQueue.peek())) {
// 이미 뺐던 거니까
maxQueue.poll();
}
// 실제로 제거하는 애
int polled = maxQueue.poll();
// tracker 갱신
tracker.put(polled, tracker.get(polled) - 1);
if (tracker.get(polled) == 0) tracker.remove(polled);
size--;
} else if (number == -1 && size > 0) {
// tracker에 키가 존재하는 원소가 나올 때까지 queue에서 poll
// tracker에 키가 없다는 것은 입력된 적 있지만 다른 큐에서 이미 빠져나갔다는 뜻
while (!tracker.containsKey(minQueue.peek())) {
// 이미 뺐던 거니까
minQueue.poll();
}
// 실제로 제거하는 애
int polled = minQueue.poll();
// tracker 갱신
tracker.put(polled, tracker.get(polled) - 1);
if (tracker.get(polled) == 0) tracker.remove(polled);
size--;
}
}
if (size == 0) {
outBuilder.append("EMPTY\n");
} else {
while (!tracker.containsKey(maxQueue.peek())) {
// 이미 뺐던 거니까
maxQueue.poll();
}
while (!tracker.containsKey(minQueue.peek())) {
// 이미 뺐던 거니까
minQueue.poll();
}
outBuilder.append(maxQueue.poll())
.append(" ")
.append(minQueue.poll())
.append("\n");
}
}
System.out.println(outBuilder);
}
public static void main(String[] args) throws IOException {
new four7662().solution();
}
}강의실 배정
문제
수강신청의 마스터 김종혜 선생님에게 새로운 과제가 주어졌다.
김종혜 선생님한테는 Si에 시작해서 Ti에 끝나는 N개의 수업이 주어지는데, 최소의 강의실을 사용해서 모든 수업을 가능하게 해야 한다.
참고로, 수업이 끝난 직후에 다음 수업을 시작할 수 있다. (즉, Ti ≤ Sj 일 경우 i 수업과 j 수업은 같이 들을 수 있다.)
수강신청 대충한 게 찔리면, 선생님을 도와드리자!
입력
첫 번째 줄에 N이 주어진다. (1 ≤ N ≤ 200,000)
이후 N개의 줄에 Si, Ti가 주어진다. (0 ≤ Si < Ti ≤ 109)
출력
강의실의 개수를 출력하라.
예제 입력 1
3
1 3
2 4
3 5
예제 출력 1
2코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.StringTokenizer;
// https://www.acmicpc.net/problem/11000
public class five11000 {
public int solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int courses = Integer.parseInt(reader.readLine());
PriorityQueue<int[]> lectureQueue = new PriorityQueue<>(
Comparator.comparingInt(o -> o[0])
);
for (int i = 0; i < courses; i++) {
StringTokenizer courseToken = new StringTokenizer(reader.readLine());
lectureQueue.offer(new int[] {
Integer.parseInt(courseToken.nextToken()),
Integer.parseInt(courseToken.nextToken())
});
}
// 종료 시간을 정렬하기 위한 우선 순위 큐
PriorityQueue<Integer> roomQueue = new PriorityQueue<>();
// 모든 강의를 확인
while (!lectureQueue.isEmpty()) {
int[] nextLecture = lectureQueue.poll();
// 강의실이 비어 있고 마지막 강의 종료 시간이 현재 강의 시작 시간보다 작아서
// 지금 사용 중인 강의실 중 가장 빨리 비는 강의실이
// 나의 시작 시간보다 빨리 끝날 경우 해당 강의실 사용
if (!roomQueue.isEmpty() && roomQueue.peek() <= nextLecture[0]) {
roomQueue.poll();
}
// 나의 종료 시간 넣기
roomQueue.offer(nextLecture[1]);
}
return roomQueue.size();
}
public static void main(String[] args) throws IOException {
System.out.println(new five11000().solution());
}
}Dijkstra Algorithm
기존에 배운 다익스트라 알고리즘은 다음과 같다.
- 시작 정점을 결정하고 시작 정점과 그래프의 다른 모든 정점 사이 거리를 무한으로 초기화한다
- 아직 방문하지 않은 정점 중 현재 도달 가능한 가장 가까운 정점을 방문
- 방문한 정점에서 도달 가능한 주변 정점들까지의 거리를 갱신
- 현재 정점까지 최단 거리 + 주변 정점까지의 거리
- 현재 기록된 주변 정점까지의 거리 중 작은 것
- 모든 정점을 반복할 때까지 2~3 반복
기존의 다익스트라 알고리즘은 만큼의 시간 복잡도가 걸리지만 minHeap을 사용하면 만큼의 시간이 걸린다.
public class DijkstraHeap {
public static void main(String[] args) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer info = new StringTokenizer(reader.readLine());
int nodes = Integer.parseInt(info.nextToken());
int edges = Integer.parseInt(info.nextToken());
int start = Integer.parseInt(reader.readLine());
List<List<int[]>> adjList = new ArrayList<>();
for (int i = 0; i < nodes; i++) {
adjList.add(new ArrayList<>());
}
for (int i = 0; i < edges; i++) {
StringTokenizer edgeToken = new StringTokenizer(reader.readLine());
int from = Integer.parseInt(edgeToken.nextToken());
int to = Integer.parseInt(edgeToken.nextToken());
int cost = Integer.parseInt(edgeToken.nextToken());
adjList.get(from).add(new int[]{to, cost});
}
// 방문정보 visited
boolean[] visited = new boolean[nodes];
// 현재까지의 최서 거리 정보 dist
int[] dist = new int[nodes];
// 1. 모든 정점까지 아직 도달할 길이 없으므로, 무한대 (또는 최대)로 초기화
Arrays.fill(dist, Integer.MAX_VALUE);
// 2. 시작정점까지의 거리는 0
dist[start] = 0;
// 우선순위 큐 활용
PriorityQueue<int[]> minHeap = new PriorityQueue<>(
Comparator.comparingInt(o -> o[1])
);
// 처음 가는 곳은 시작지점
minHeap.offer(new int[]{start, 0});
// 우선순위 큐에 더이상 방문할 정점이 기록되지 않을때까지
while (!minHeap.isEmpty()) {
// 최소힙에서 꺼내면 도달 가능한 가장 가까운 지점
int[] current = minHeap.poll();
if (visited[current[0]]) continue;
visited[current[0]] = true;
// adjList.get(index): index 정점에서 뻗어나가는 간선들의 리스트
for (int[] neighbor: adjList.get(current[0])) {
int neighborVertex = neighbor[0];
int neighborCost = neighbor[1];
// 방문하지 않은 정점이고
// 현재까지 기록된 거리보다 새로 가는 거리가 더 짧다.
if (!visited[neighborVertex] &&
dist[neighborVertex] > current[1] + neighborCost) {
dist[neighborVertex] = current[1] + neighborCost;
minHeap.offer(new int[]{ neighborVertex, dist[neighborVertex] });
}
}
}
System.out.println(Arrays.toString(dist));
}
}Spring Cloud
Cloud Service
Cloud Computing
어디에나 존재하고, 편리하고, 소비자가 필요한 곳에 존재하는 것을 가능하게 하는 네트워크 모델이다. 네트워크, 서버, 저장소, 앱 등으로 구성될 수 있는데, 이러한 요소들은 작은 단위의 서비스로 빠르게 공급되고 배포된다. 컴퓨터의 가상화를 통해 필요로 하는 컴퓨터 자원을 평범한 웹 서비스 사용하듯이 쉽고 빠르게 구비할 수 있도록 해 주는 기술의 총칭이다. 실제로 물리적인 컴퓨터를 가상화해서 쪼개는 것이기 때문에 정확하게 따르자면 There is no cloud이다.
Cloud Compution의 Five Essential Characteristic
- On-demand self-service 사용자는 서버 제공자 같은 인간의 개입 없이 자동적으로 서버나 네트워크 저장소 같은 컴퓨터 이용성을 일방적으로 공급받을 수 있다.
- Broad network access 스마트폰, 태블릿, 노트북과 같은 다양한 기기를 통해 네트워크에 접속할 수 있다.
- Resource pooling 제공자의 컴퓨터 자원은 multi-tenant (단일 소프트웨어 인스턴스로 서로 다른 여러 사용자 그룹에 서비스를 제공할 수 있는 소프트웨어 아키텍처) 를 사용하는 다양한 소비자들에게 그들의 요구에 따른 다양한 물리적, 가상적 자원과 동적인 할당을 제공하기 위해 통합된다. 여기에는 위치가 의존적이지 않다는 특징이 있는데, 위치 정보가 필요하더라도 넓은 범위 (국가나 지역) 단위로만 요구된다.
- Rapidly elasticity 이용성은 어떨 때는 심지어 자동적으로 빠르지만 소비자의 요구를 충족시키는 방향으로 탄력 있게 제공되고 배포된다. 사용자 입장에서 잦은 배포는 서비스가 제한적이지 않고 언제 어디서나 충분한 성능을 제공할 수 있다는 장점이 있다.
- Measured service 클라우드 시스템은 자동적으로 서비스의 유형에 적절한 수준으로 자원을 활용하고 측정해서 조절하고 최적화한다. 자원 이용량은 감시되고 제어되고 보고되고 투명하게 제공된다.
Service Models
- Software as a Service (SaaS) 사용자에게 제공자의 클라우드 인프라 안에서 실행 중인 애플리케이션을 사용할 수 있도록 하는 것이다. 사용자는 웹브라우저, 웹베이스 이메일로 이 애플리케이션을 사용할 수 있다. 사용자는 클라우드 인프라 밑에 있는 네트워크, 서비스, 운영체제, 저장소와 관련된 것들은 관리할 수 없고 제한적인 사용자 세팅만 관리할 수 있다.
- Platform as a Service (PaaS) 사용자가 프로그래밍 언어, 라이브러리, 서비스나 툴 같은 것들을 이용해서 클라우드 인프라 위에서 사용자가 애플리케이션을 제작할 수 있도록 하는 것이다. 마찬가지로 사용자는 클라우드 인프라 밑에 있는 네트워크, 서비스, 운영체제, 저장소는 관리할 수 없지만 애플리케이션 제작과 애플리케이션 호스팅 환경에 대한 몇몇 구성은 관리할 수 있다.
- Infrastructure as a Service (IaaS) 사용자에게 프로세스의 배급, 저장소, 네트워크 그리고 근간이 되는 컴퓨터 자원들까지 사용자가 임의의 소프트웨어를 배포하고 개발할 수 있도록 네트워크, 운영체제까지 관리를 허용하는 것이다. 사용자는 운영체제, 저장소, 허용된 범위의 네트워크 요소들은 관리할 수 있지만 클라우드 인프라 구조의 근본적인 부분은 관리할 수 없다.
Deployment Models
- Privatre cloud 여러 사용자로 구성된 단일 조직 (비즈니스 유닛) 에서 독점적으로 사용하는 클라우드이다. 이는 특정 집단에 의해서만 관리되고 작동될 수 있다.
- Community cloud 같은 관심을 가진 사용자들이나 집단에 의해 사용되는 클라우드이다. 지역 사회나 허너 이상의 단체 혹은 팀에 의해 소유되고 관리되고 작동할 수 있다.
- Public cloud 일반적인 대중이 사용할 수 있는 클라우드다. 이는 경제, 학술, 정부 조직이나 그들의 조합에 의해 소유되고 관리되고 작동할 수 있다.
- Hybrid cloud 하나 이상의 다른 클라우드의 조합이다. 이는 이동성을 지원하는 기술에 의해 데이터나 애플리케이션이 통합된다.
만약 클라우드 서비스를 이용하지 않는다면 배포는 어떻게 할까? 적당한 성능의 컴퓨터를 구비하고 컴퓨터에 개발한 웹 서비스를 실행하고 해당 컴퓨터를 인터넷에 연결한 뒤 사용자가 이 컴퓨터를 찾을 수 있도록 방화벽이나 포트포워딩으로 환경을 조성한다. SEO, DNS 등 구축이 매우 어렵다. 따라서 클라우드 컴퓨팅 서비스를 사용해 Infrastructure as Code를 지향하는 것이 편리하다.
클라우드를 활용하여 개발하게 되면 자유롭게 분배가 가능한 컴퓨터 자원을 바탕으로 분산된 시스템을 구성하는 경우가 많다. 컴퓨터 자원을 쉽게 늘리고 줄이기 때문에 작은 단위의 서비스를 여럿 만들어 확장성 확보가 용이하다. 에러 상황을 작은 서비스 단위로 격리하여 안정성도 확보할 수 있다.
API Gateway
Micro Service Architecture에서 언급되는 개념이다. 분산된 시스템은 서로 다른 서비스가 상호작용하고, 각각의 서비스는 별도의 Endpoint를 구성한다. **API Gateway는 분산된 Endpoint에 대한 요청을 한 곳에서 받아 다양한 서비스로 전달**한다. API Gateway는 메시지를 만들지 않고 전달하는 주체라고 생각하면 된다.
Gateway
새로운 프로젝트를 만들어 준다.

이후 준비된 Skeleton이 있는 폴더에 위치시킨다.
gateway 서버는 들어오는 요청을 변형하지 않고 요청을 해석한 뒤 적절한 백엔드 서버인 article, auth 로 전달해 주는 서버이다.
이때 요청의 응답을 기다리지 않고 계속 들어오는 요청을 받아들이기 위해 tomcat이 아닌 반응형인 natty를 사용한다.
gateway는 controller를 만들지 않고 RoutingConfig인 설정을 통해서 진행한다. 어떤 식으로 요청을 사용자에게서 다른 서버로 잘 보낼 것인지를 정의한다. 서버까지 가기 위한 길을 정해 준다고 보면 된다.
@Configuration
public class RoutingConfig {
@Bean
public RouteLocator gatewayRoutes(RouteLocatorBuilder builder) {
return builder.routes().build();
}
}이때 http://localhost:8080/articles/** 로 오는 요청은 모두 article 서버로 보내고 싶다. 이에 대한 설정을 다음과 같이 진행할 수 있다.
@Configuration
public class RoutingConfig {
@Bean
public RouteLocator gatewayRoutes(RouteLocatorBuilder builder) {
return builder.routes()
.route("articles", predicate -> predicate
**.path("/articles/**")
.uri("http://localhost:8082"))**
.build();
}
}리다이렉트랑은 다르다. 클라이언트가 서버 1에게 요청을 보내면 서버 1에서 서버 2의 경로로 리다이렉트를 보내고 클라이언트가 서버 2로 다시 접속하는 것이다. 게이트웨이는 클라이언트가 게이트웨이에 요청을 보내면 게이트웨이에서 서버 n으로 요청을 보내고 응답을 받아서 클라이언트에게 보내 주는 것이다.
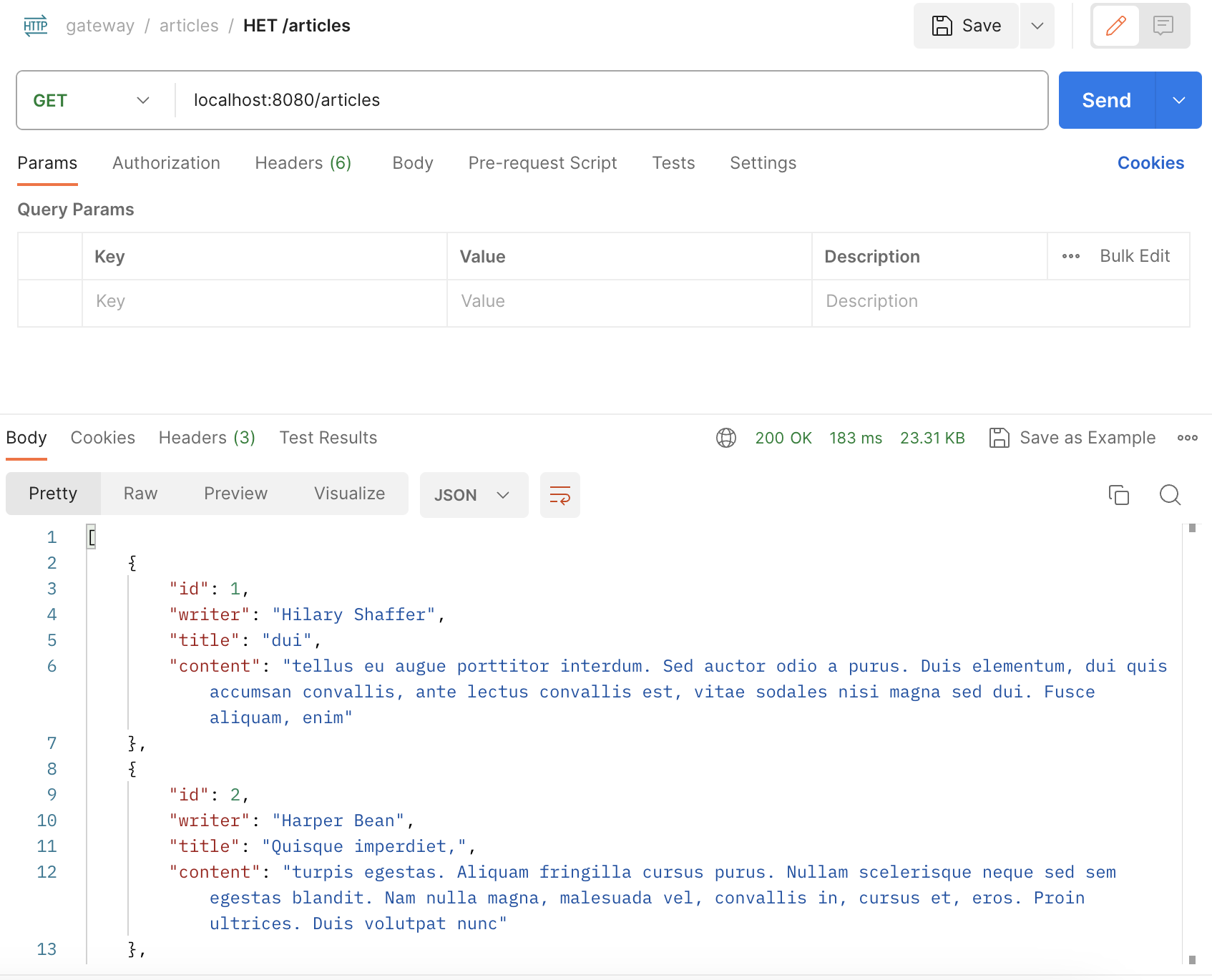
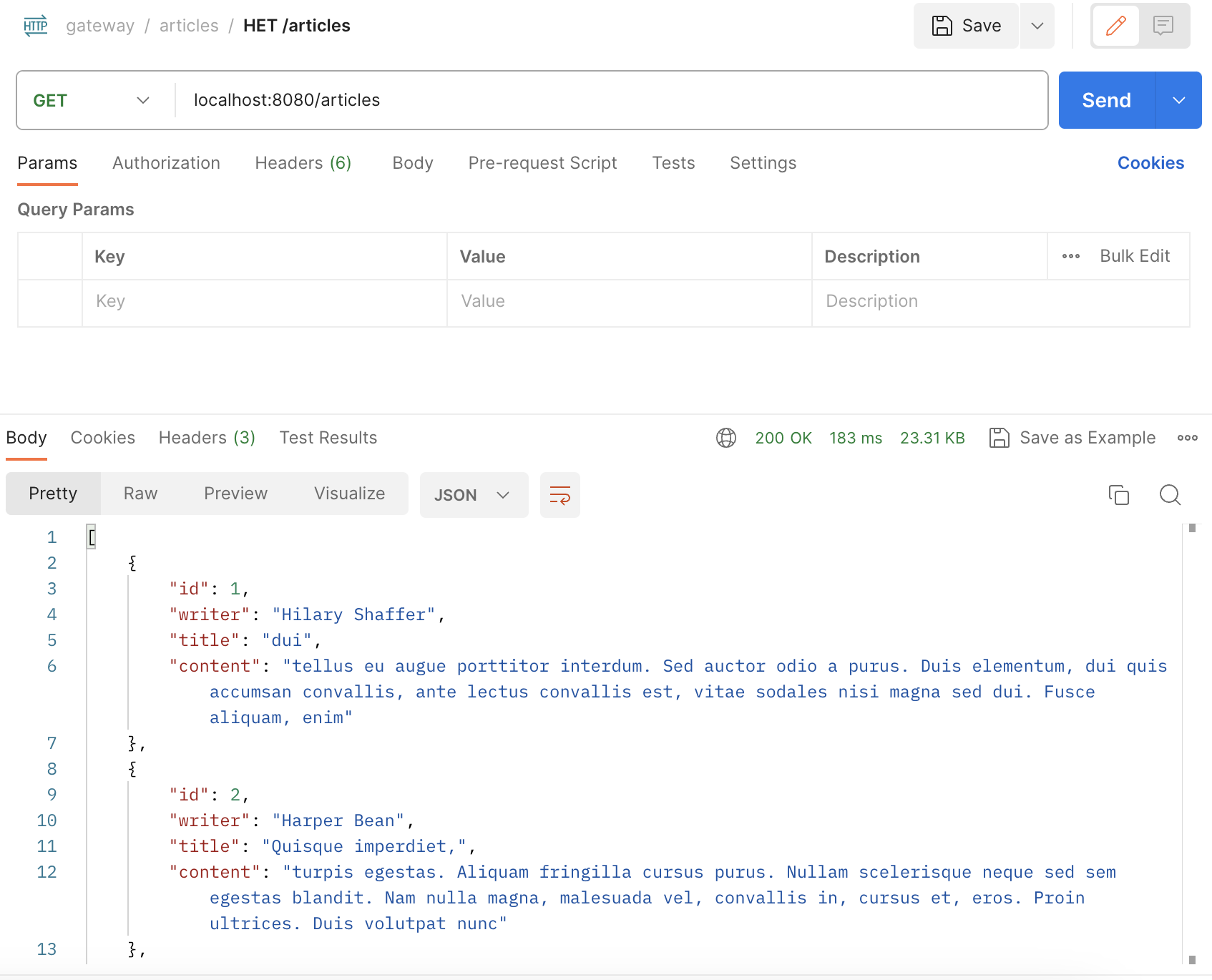
포스트맨을 실행해 보면 현재 article 서버는 8082번 포트에서 열리고 있지만 gateway 서버의 기능에 의해 8080 포트로 접속해도 잘 동작하는 것을 확인할 수 있다.
같은 방식으로 auth도 생성할 수 있다. auth는 / /user /token 등의 url을 가지고 있다. 이 경우 루트 경로는 많은 서버가 사용할 수 있다. 따라서 :8080/auth/** 의 사용자 요청을 :8081/**로 보내는 작업을 하고자 한다. 구분할 수 있도록 gateway에서 /auth를 붙여 구분하는 방법은 아래와 같다.
@Configuration
public class RoutingConfig {
@Bean
public RouteLocator gatewayRoutes(RouteLocatorBuilder builder) {
return builder.routes()
.route("articles", predicate -> predicate
.path("/articles/**")
.uri("http://localhost:8082"))
**.route("auth", predicate -> predicate
// localhost:8080/auth/**
// localhost:8081/**
.path("/auth/**")
.filters(filter -> filter
// 정규표현식을 사용해서 경로의 일부분 추출
.rewritePath("/auth/(?<path>.*)", "/${path}"))**
.uri("http://localhost:8081"))
.build();
}
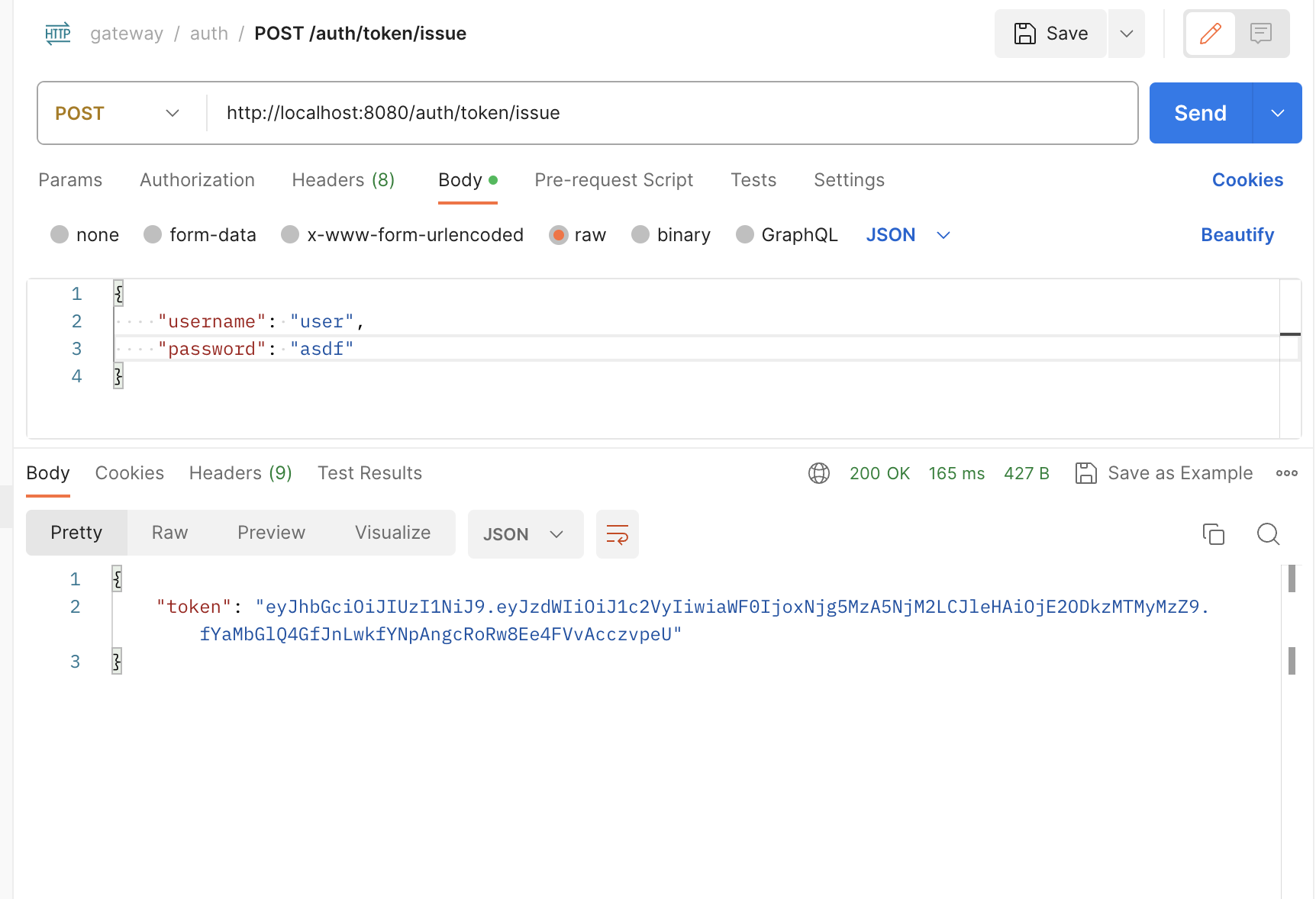
}이후 8080 서버로 /auth를 붙여 요청을 보내면 8081 포트에서 실행 중인 auth 서버의 응답을 받을 수 있다.
Filter Create
Gateway가 모든 요청을 받아주는 만큼, 모든 요청에 대해 공통적으로 넣고싶은 기능이 있다면, Spring Boot와 마찬가지로 필터를 추가해볼 수 있다. 이때 구현하는 인터페이스는 GlobalFilter 이다. GlobalFilter 인터페이스를 구현하고 Bean 객체로 등록하면 Gateway에 자동으로 등록된다.
@Component
public class LoggingFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
return null;
}
}PreLoggingFilter에서 요청을 식별할 수 있는 HTTP Header를 작성해서 나중에 PostLoggingFilter를 만들 때 해당 Header를 바탕으로 실행에 걸린 시간 측정하는 기능을 필터에 추가헤 보자.
@Slf4j
@Component
public class LoggingFilter implements GlobalFilter {
@Override
public Mono<Void> filter(
// HttpServletRequest & Response 대신
// exchange
ServerWebExchange exchange,
// FilterChain
GatewayFilterChain chain) {
// 사용자가 보낸 HTTP 요청을 받음
ServerHttpRequest httpRequest = exchange.getRequest();
// PreLoggingFilter에서 요청을 식별할 수 있는 HTTP Header를 작성
// 나중에 PostLoggingFilter를 만들 때 해당 Header를 바탕으로
// 실행에 걸린 시간 측정
// 사용자가 보낸 요청을 커스텀
httpRequest.mutate()
// 헤더 추가 및 변형
.headers(httpHeaders -> {
httpHeaders.add(
"x-gateway-request-id",
UUID.randomUUID().toString()
);
httpHeaders.add(
"x-gateway-request-time",
String.valueOf(Instant.now().toEpochMilli())
);
});
// filterChain.doFilter() 대신
return chain.filter(exchange);
}
}log를 찍어 확인하고 요청 응답의 헤더를 확인해 보면 필터가 잘 작동하고 있음을 확인할 수 있다.
Post Filter
사용자에게 응답이 돌아가고 난 뒤에 실행하는 필터를 만들어 보자. Mono 객체는 자바스크립트에서 async 같은 역할을 하는 비동기 역할을 한다. 따라서 then을 자바스크립트처럼 쓸 수 있다. then의 역할은 말 그대로 그리고 나서 실행하는 역할이다.
@Slf4j
@Component
public class PostLoggingFilter implements GlobalFilter {
@Override
public Mono<Void> filter(
ServerWebExchange exchange,
GatewayFilterChain chain) {
return chain.filter(exchange)
.then(Mono.fromRunnable(() -> {
ServerHttpRequest httpRequest = exchange.getRequest();
// 요청의 UUID 수거
String requestId = httpRequest.getHeaders()
.getFirst("x-gateway-request-id");
String requestTimeString = httpRequest.getHeaders()
.getFirst("x-gateway-request-time");
// 문자열을 다른 타입으로 해석
long timeEnd = Instant.now().toEpochMilli();
long timeStart = Long.parseLong(requestTimeString);
log.info("Excution Time id: {}, timediff(ms): {}", requestId, timeEnd - timeStart);
}));
}
}이후 요청을 넣으면 요청 처리 전 필터와 요청 처리 후 필터가 모두 작동하는 것을 볼 수 있다.

NAVER CLOUDE PLATFORM
Naver Map API
네이버에서 제공하는 API를 다음 사이트에서 이용할 수 있다. 이후 아래 사이트에서 앱을 등록해 준다.

아래와 같이 설정을 해 준다.
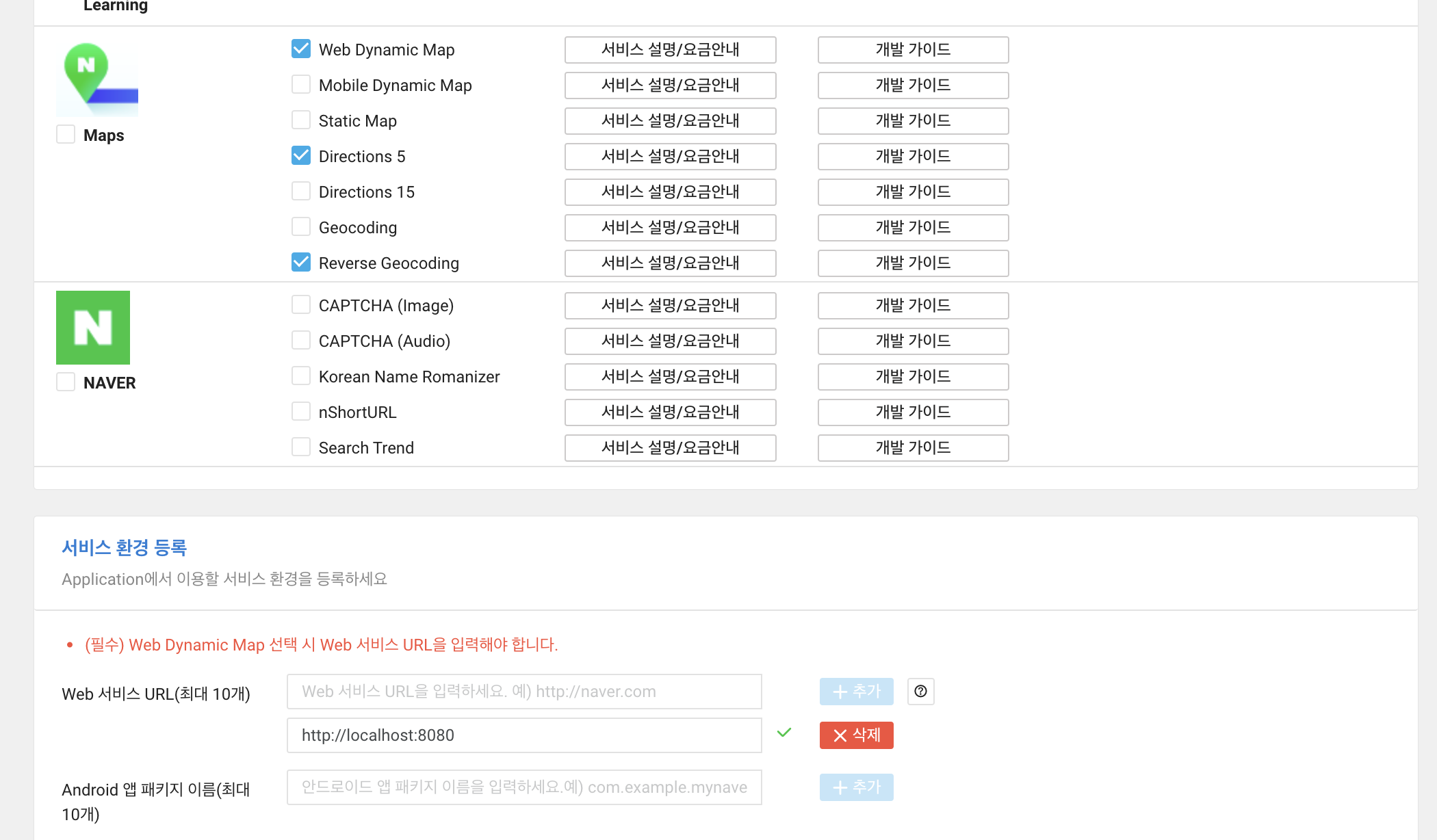
이후 application마다 사용량을 확인할 수 있다.
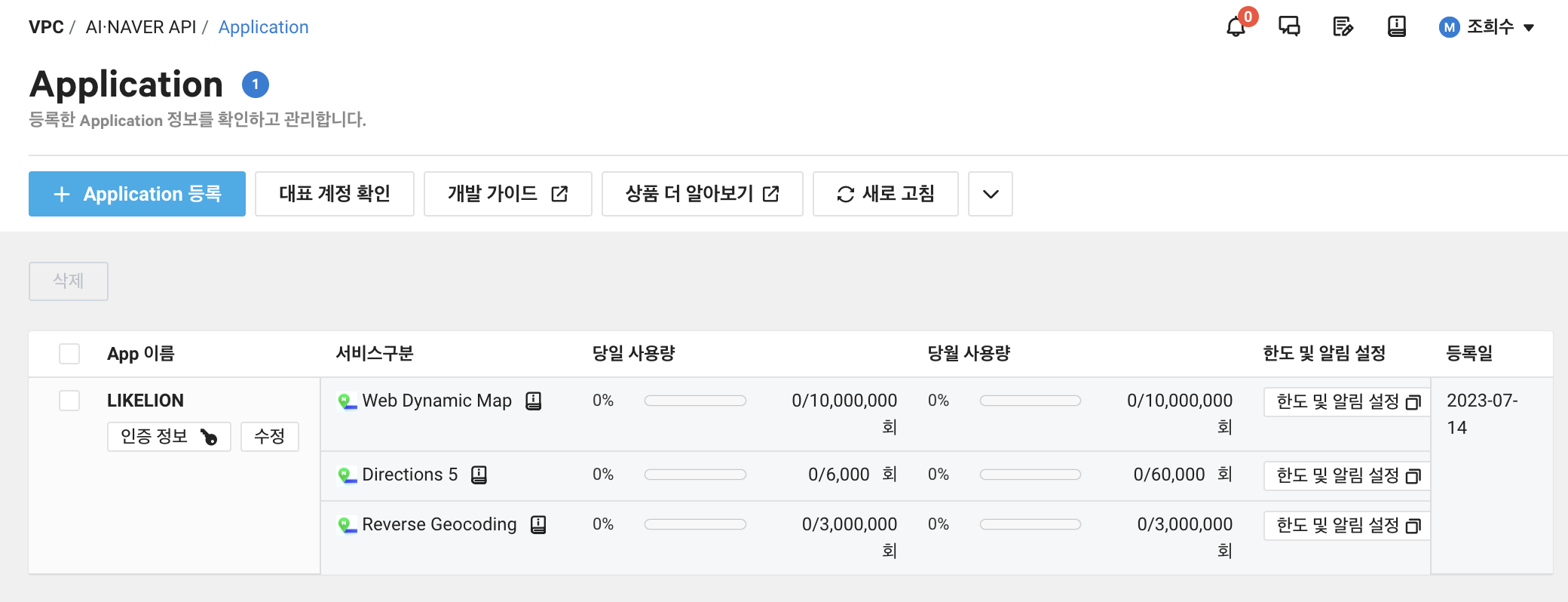
인증 정보 버튼에 있는 Client Id와 Client Secret을 사용해 주면 된다. 네이버 API는 요청 시에 헤더를 통해 Client ID와 Client Secret을 보낸다.
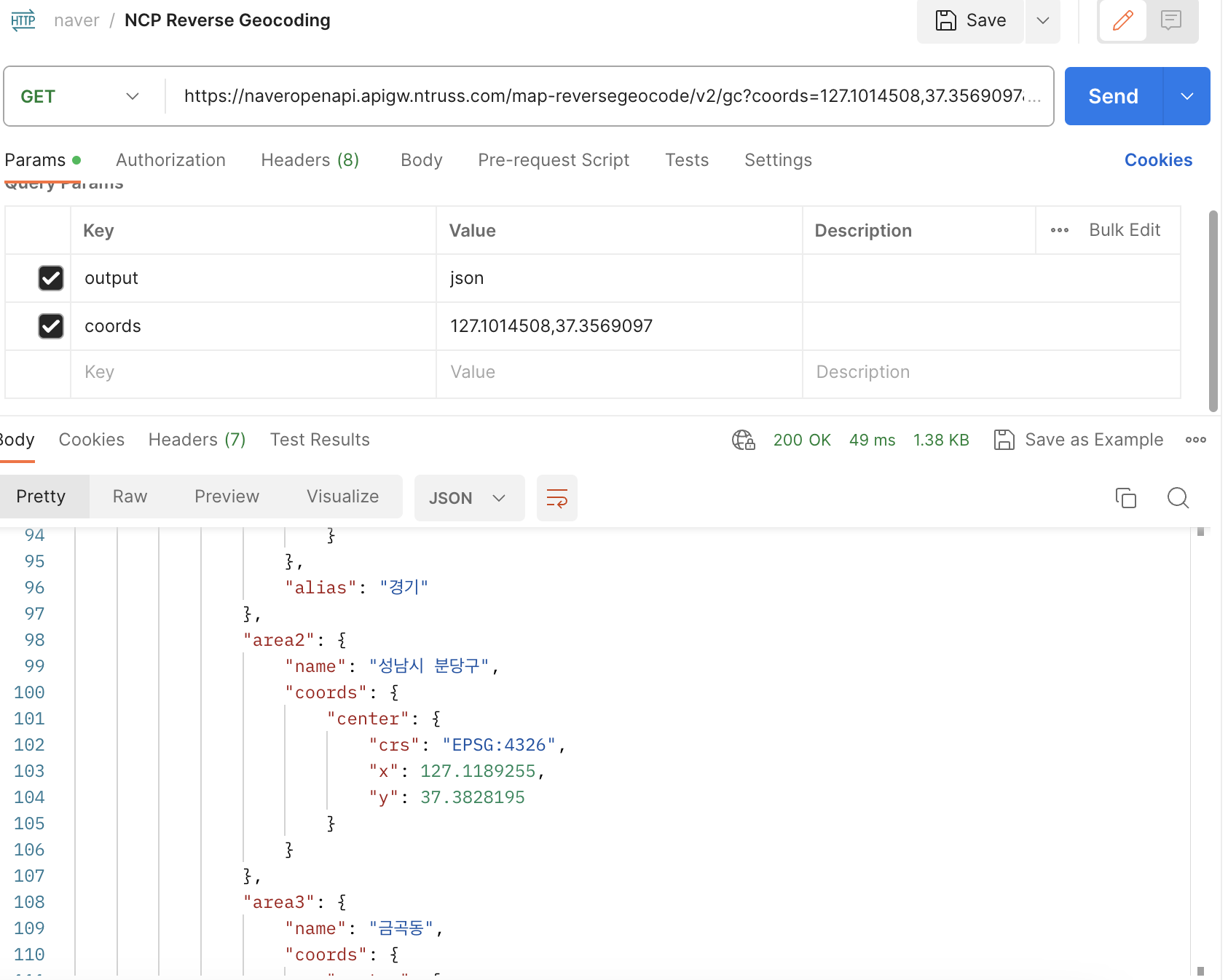
Reverse Geocoding부터 실행해 보자.
포스트맨을 통해 API 주소인
https://naveropenapi.apigw.ntruss.com/map-direction/v1/driving?start=127.1014508,37.3569097&goal=127.1075877,37.3561592 로 요청을 보내면서 헤더에 X-NCP-APIGW-API-KEY-ID (Client ID), X-NCP-APIGW-API-KEY (Client Secret) 값을 넣어 요청을 보낸다. 이후 파라미터 coords에 위도, 경도를 넣어 주면 다음과 같은 응답이 나온다.
이번에는 길 찾기 기능인 Direction 5를 사용해 보자. 이 API는 추천 경로를 나타내 주는 API이다.
헤더 설정은 똑같고 url만 다르다.
https://naveropenapi.apigw.ntruss.com/map-direction/v1/driving이후 start와 goal 좌표를 찍어서 보내면 다음과 같이 길찾기가 잘 나오는 것을 확인할 수 있다.

