
Algorithm
국회의원 선거
문제
다솜이는 사람의 마음을 읽을 수 있는 기계를 가지고 있다. 다솜이는 이 기계를 이용해서 2008년 4월 9일 국회의원 선거를 조작하려고 한다.
다솜이의 기계는 각 사람들이 누구를 찍을 지 미리 읽을 수 있다. 어떤 사람이 누구를 찍을 지 정했으면, 반드시 선거때 그 사람을 찍는다.
현재 형택구에 나온 국회의원 후보는 N명이다. 다솜이는 이 기계를 이용해서 그 마을의 주민 M명의 마음을 모두 읽었다.
다솜이는 기호 1번이다. 다솜이는 사람들의 마음을 읽어서 자신을 찍지 않으려는 사람을 돈으로 매수해서 국회의원에 당선이 되게 하려고 한다. 다른 모든 사람의 득표수 보다 많은 득표수를 가질 때, 그 사람이 국회의원에 당선된다.
예를 들어서, 마음을 읽은 결과 기호 1번이 5표, 기호 2번이 7표, 기호 3번이 7표 라고 한다면, 다솜이는 2번 후보를 찍으려고 하던 사람 1명과, 3번 후보를 찍으려고 하던 사람 1명을 돈으로 매수하면, 국회의원에 당선이 된다.
돈으로 매수한 사람은 반드시 다솜이를 찍는다고 가정한다.
다솜이가 매수해야하는 사람의 최솟값을 출력하는 프로그램을 작성하시오.
입력
첫째 줄에 후보의 수 N이 주어진다. 둘째 줄부터 차례대로 기호 1번을 찍으려고 하는 사람의 수, 기호 2번을 찍으려고 하는 수, 이렇게 총 N개의 줄에 걸쳐 입력이 들어온다. N은 50보다 작거나 같은 자연수이고, 득표수는 100보다 작거나 같은 자연수이다.
출력
첫째 줄에 다솜이가 매수해야 하는 사람의 최솟값을 출력한다.
예제 입력 1
3
5
7
7
예제 입력 2
4
10
10
10
10
예제 입력 3
1
1
예제 입력 4
5
5
10
7
3
8
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Collections;
import java.util.PriorityQueue;
// https://www.acmicpc.net/problem/1417
public class five1417 {
public int solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
// 입력부
int candidates = Integer.parseInt(reader.readLine());
// 내 득표수
int myVote = Integer.parseInt(reader.readLine());
// 제알 많은 득표자의 표를 먼저 빼야 하니까
PriorityQueue<Integer> otherVotes = new PriorityQueue<>(Collections.reverseOrder()); // or (Comparator.comparingInt(o -> o)
// 다솜이 거 빼고 나머지
for (int i = 0; i < candidates - 1; i++) {
otherVotes.offer(Integer.parseInt(reader.readLine()));
}
// 정답
int answer = 0;
// 알고리즘
// 단독 후보가 아닐 떄
if (!otherVotes.isEmpty()) {
// 나머지 후보들 득표 중 최대가 나보다 작아질 때까지
while (otherVotes.peek() >= myVote) {
// 최다 득표자의 득표수
int votes = otherVotes.poll();
// 그 사람의 지지자를 한 명 매수
otherVotes.offer(votes - 1);
// 빼앗은 표는 내 거
myVote++;
// 매수 진행 횟수
answer++;
}
}
return answer;
}
public static void main(String[] args) throws IOException {
System.out.println(new five1417().solution());
}
}Moo 게임
문제
Moo는 술자리에서 즐겁게 할 수 있는 게임이다. 이 게임은 Moo수열을 각 사람이 하나씩 순서대로 외치면 되는 게임이다.
Moo 수열은 길이가 무한대이며, 다음과 같이 생겼다.
m o o m o o o m o o m o o o o m o o m o o o m o o m o o o o oMoo 수열은 다음과 같은 방법으로 재귀적으로 만들 수 있다. 먼저, S(0)을 길이가 3인 수열 "m o o"이라고 하자. 1보다 크거나 같은 모든 k에 대해서, S(k)는 S(k-1)과 o가 k+2개인 수열 "m o ... o" 와 S(k-1)을 합쳐서 만들 수 있다.
S(0) = "m o o"
S(1) = "m o o m o o o m o o"
S(2) = "m o o m o o o m o o m o o o o m o o m o o o m o o"위와 같은 식으로 만들면, 길이가 무한대인 문자열을 만들 수 있으며, 그 수열을 Moo 수열이라고 한다.
N이 주어졌을 때, Moo 수열의 N번째 글자를 구하는 프로그램을 작성하시오.
입력
첫째 줄에 N (1 ≤ N ≤ 109)이 주어진다.
출력
N번째 글자를 출력한다.
예제 입력 1
11
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
// https://www.acmicpc.net/problem/5904
public class gold5904 {
public char solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(reader.readLine());
// 최초의 수열의 길이는 3
int length = 3;
// 목표는 반복해서 수열을 만들어 length 가 n 보다 커지게 만들면서
// length 가 moo 수열의 길이 만한 값으로 유지되기
// reps == k
int reps = 0;
// while 문의 조건도 동일하게 가져간다.
while (length < n) {
// 처음 만드는 수열은 S(1)이니
// 증가시키고 시작
reps++;
// len(S(k - 1)) * 2 + ((k + 2) * 'o' + 'm')
length = length * 2 + (reps + 3);
// System.out.println(length);
}
// reps(k)와 length 의 정보가 있다면,
// moo 수열의 구역을 3단위로 나눌 수 있다.
// 좌우대칭 앞과 뒤, + reps + 3 으로 이뤄진 moo...o
// 가운데 구간에 n이 위치한다면 정확하게 어떤 글자인지 판단할 수 있다.
// 앞쪽 또는 뒤쪽이라면, 구간을 줄여서 다시 3등분,
// 반복해서 가운데에 위치할 때까지 진행한다.
// 인덱스 기준으로 찾을거니, n의 값을 사전 조정 해준다.
n--;
while (true) {
// 먼저 가운데 인덱스의 위치를 찾는다.
int midIndex = (length - (reps + 3)) / 2;
// 그리고 끝 구간의 시작 인덱스를 찾는다.
// 가운데 시작 인덱스 부터 가운데 구간 길이 합
int lastIndex = (length - (reps + 3)) / 2 + (reps + 3);
// 만약 n == midIndex 라면, 가운데 구간의 시작
// 구간의 시작이면 m 이다
if (n == midIndex) return 'm';
// 시작은 아니지만, 가운데 구간이면 o 다
else if (midIndex < n && n < lastIndex) return 'o';
// 아니라면, 길이를 줄여서 다시 풀어본다.
else if (n >= lastIndex) {
// 버리는 길이만큼 n 과 length 조정
n -= lastIndex;
length -= lastIndex;
} else {
// 가운데 구간의 길이와
length -= reps + 3;
// 가운데 구간까지의 길이를 둘다 뺀다.
length -= midIndex;
// n은 조정 불필요
}
reps--;
}
}
public static void main(String[] args) throws IOException {
System.out.println(new gold5904().solution());
}
}Topological Sort
순서가 존재하는 그래프에서 모든 정점들을 선형인 일렬로 나열하는 것을 목표로 하는 정렬이다. 일렬로 나열하되 원래 진행되던 방향성을 잃지 않도록 나열하는 것이다. 즉 유형 그래프의 정점들을 선형으로 나열하는 문제인데 모든 정점들의 나열 순서가 간선들이 가진 방향의 순서를 지키도록 하는 것이다. 대학의 선수과목 체계나 라이브러리 의존성들을 생각해 볼 때 유용하게 사용할 수 있다.
위상 정렬은 사이클이 존재하지 않는 유향 그래프인 Directed Acyclic Graph일 때만 가능하다. 사이클이 존재하면 누가 먼저 존재해야 하는지에 대한 Cicular Dependency 문제가 발생하기 때문이다. 또한 조건을 만족한다면 여러 위상 정렬의 결과가 나올 수 있다.
BFS는 이동할 수 있다면 이동한다의 개념이지만 위상 정렬은 나에게 오려면 이전 경로를 필수적으로 선택하고 와야 한다의 개념과 가깝다.
Kahn’s Algorithm
모든 정접의 진입 차수 (해당 정점으로 도착할 수 있는 간선의 개수)를 기준으로 경로를 구하는 알고리즘이다.
- 모든 정점의 진입 차수를 기록한다.
- 진입 차수가 0인 정점을 Queue에 삽입한다.
- Queue에서 정점을 꺼내면서
- 위상 정렬의 결과로 기록한다.
- 인접 정점의 기록된 진입 차수를 하나로 감소한다.
- 진입 차수가 0이 된 정점을 Queue에 삽입한다.
- Queue가 비면 위상 정렬이 종료된다.
만약 결과의 정점 갯수가 실제 정점 갯수보다 적다면 순환 구조가 있어서 모든 정점을 나열하지 못한 것이다.
public class TopologicalSort {
private List<List<Integer>> adjList;
private int nodes;
public void topologicalSort() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer infoToken = new StringTokenizer(reader.readLine());
// 정점 갯수 기록
nodes = Integer.parseInt(infoToken.nextToken());
// 간선 갯수 기록
int edges = Integer.parseInt(infoToken.nextToken());
adjList = new ArrayList<>();
// 인접 리스트 초기화
for (int i = 0; i < nodes; i++) {
adjList.add(new ArrayList<>());
}
// 그래프 입력받기
for (int i = 0; i < edges; i++) {
StringTokenizer edgeToken = new StringTokenizer(reader.readLine());
int start = Integer.parseInt(edgeToken.nextToken());
int end = Integer.parseInt(edgeToken.nextToken());
adjList.get(start).add(end);
}
kahn();
}
// nodes: 정점의 개수, adjList: 인접 리스트
private void kahn() {
// 1. 진입 차수를 구한다
int[] inDegrees = new int[nodes];
// neighbors: 각 정점에서 도달할 수 있는 정점들 리스트
for(List<Integer> neighbors: adjList) {
// neighbor: 그 정점에서 도달 가능한 정점들
for(int neighbor: neighbors) {
inDegrees[neighbor]++;
}
}
// 2. 진입 차수가 0인 정점을 Queue에 삽입
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < nodes; i++) {
if (inDegrees[i] == 0) queue.offer(i);
}
List<Integer> result = new ArrayList<>();
// 3. Queue가 비어 있지 않은 동안
while (!queue.isEmpty()) {
// 이번 정점 기록
int node = queue.poll();
result.add(node);
// 3-2 현재 정점의 인접 정점들의 진입 차수를 줄인다
for (int neighbor: adjList.get(node)) {
inDegrees[neighbor]--;
// 3-3 진입 차수가 0이 되면 진입 가능
if(inDegrees[neighbor] == 0) queue.offer(neighbor);
}
}
// 4. 실제 정점 갯수보다 위상정렬 정점 갯수가 적으면 불가능
if(result.size() < nodes) {
System.out.println(new ArrayList<>());
}
else System.out.println(result.toString());
}
public static void main(String[] args) throws IOException {
new TopologicalSort().topologicalSort();
}
}DFS Topological Sort
- 각 정점을 시작 정점으로 DFS을 진행한다.
- DFS를 진행하면서 한 정점에 도착할 때, 해당 정점을 방문했다고 기록한다.
- 재귀적으로 방문하지 않은 모든 인접 정점을 방문한다. (DFS)
- 더 이상 방문하지 않은 인접 정점이 없을 경우, 해당 정점을 기록한다.
- 모든 정점을 다 검사한 뒤. 기록된 정점을 뒤집으면 위상 정렬의 결과가 나온다.
이때 DFS 탐색 중 아직 인접 정점이 남은, 이미 방문했던 정점을 다시 만난다면 순환 구조가 존재하기 때문에 위상 정렬이 불가능하다는 의미이다.
private List<List<Integer>> adjList;
private int nodes;
private void dfs() {
boolean[] visited = new boolean[nodes];
boolean[] inProcess = new boolean[nodes];
Stack<Integer> resultReversed = new Stack<>();
boolean success = true;
for (int i = 0; i < nodes; i++) {
if (!visited[i])
success = dfsRecursive(i, visited, inProcess, resultReversed);
if (!success) break;
}
List<Integer> result = new ArrayList<>();
if (success)
while (!resultReversed.empty())
result.add(resultReversed.pop());
System.out.println(result);
}
private boolean dfsRecursive(
int next,
boolean[] visited,
boolean[] inProcess,
Stack<Integer> resultReversed
) {
// 일단 방문 정점을 방문 및 처리 중으로 표시
visited[next] = true;
inProcess[next] = true;
for (int neighbor: adjList.get(next)) {
// 처리 중 (인접 정점이 남은 정점)인 정점을 만나면 이는 싸이클이다.
if (inProcess[neighbor]) return false;
// 미방문 정점을 만나면 다음 재귀
else if (!visited[neighbor])
// 재귀 중 false 는 싸이클의 존재를 의미
if(!dfsRecursive(neighbor, visited, inProcess, resultReversed))
return false;
}
// for의 종료는 모든 인접 정점의 방문을 의미, 기록한다.
resultReversed.push(next);
// 처리가 끝났으니 처리 중 배열은 false 로
inProcess[next] = false;
return true;
}Database
RDBMS
여태까지 사용한 SQLite는 실제 RDBMS와는 성질이 많이 다르고 현업에서는 매우 한정적으로 사용된다. 주로 애플리케이션 내부의 가벼운 데이터 저장을 위해 사용하고 데이터를 읽고 쓰는 방식으로 인해 동시에 실행 가능한 작업이 딱 하나뿐이라서 제약점이 있다. 실제 서비스 중에는 더 많은 데이터를 안정적으로 다루는 RDBMS가 필수이다. 기본적으로 시중의 RDBMS는 서버 클라이언트 방식으로 작동한다. 따라서 AWS의 RDS를 사용해 MySQL을 사용해 보자.
먼저 AWS에 RDS로 접속한다.
Create Database를 눌러 새로운 인스턴스를 시작한다. 이후 MySQL을 설정해 준다.
이후 마스터 이름과 비밀번호를 설정해 준다.
이 설정이 켜져 있으면 리소스 한계를 초과했을 때 요금이 발생한다. 용량을 동적으로 늘리기 때문이다.
생성할 때 공개 접근을 허용해야지만 접근이 가능해진다.

주로 데이터베이스 포트는 3306을 사용한다.

백업을 꺼 둬야 요금이 적게 발생한다.

이후 데이터베이스 생성 완료를 누르면 인스턴스가 만들어진다.

이후 아래 정보를 활용해서 연결하면 된다.
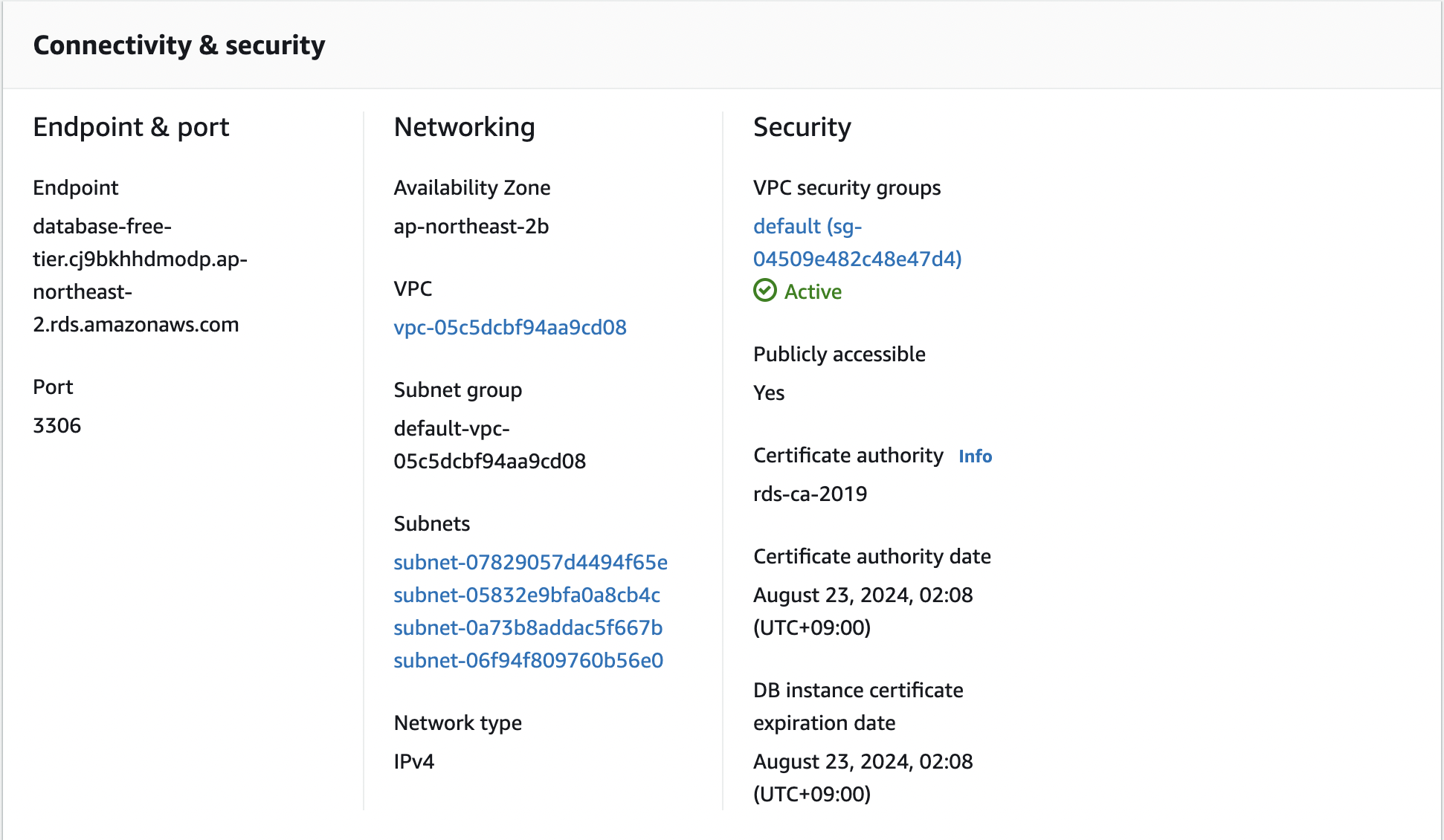
이때 연결이 되지 않는다면 인바운드 규칙을 편집해서 포트를 열어 줘야 한다.

이후 IDE에서 Endpoint를 사용해 연결해 준다.
이후 비밀번호를 넣어 주면 성공적으로 접근이 완료된다.
Schema Editor를 통해 새로운 Schema를 생성할 수도 있다.
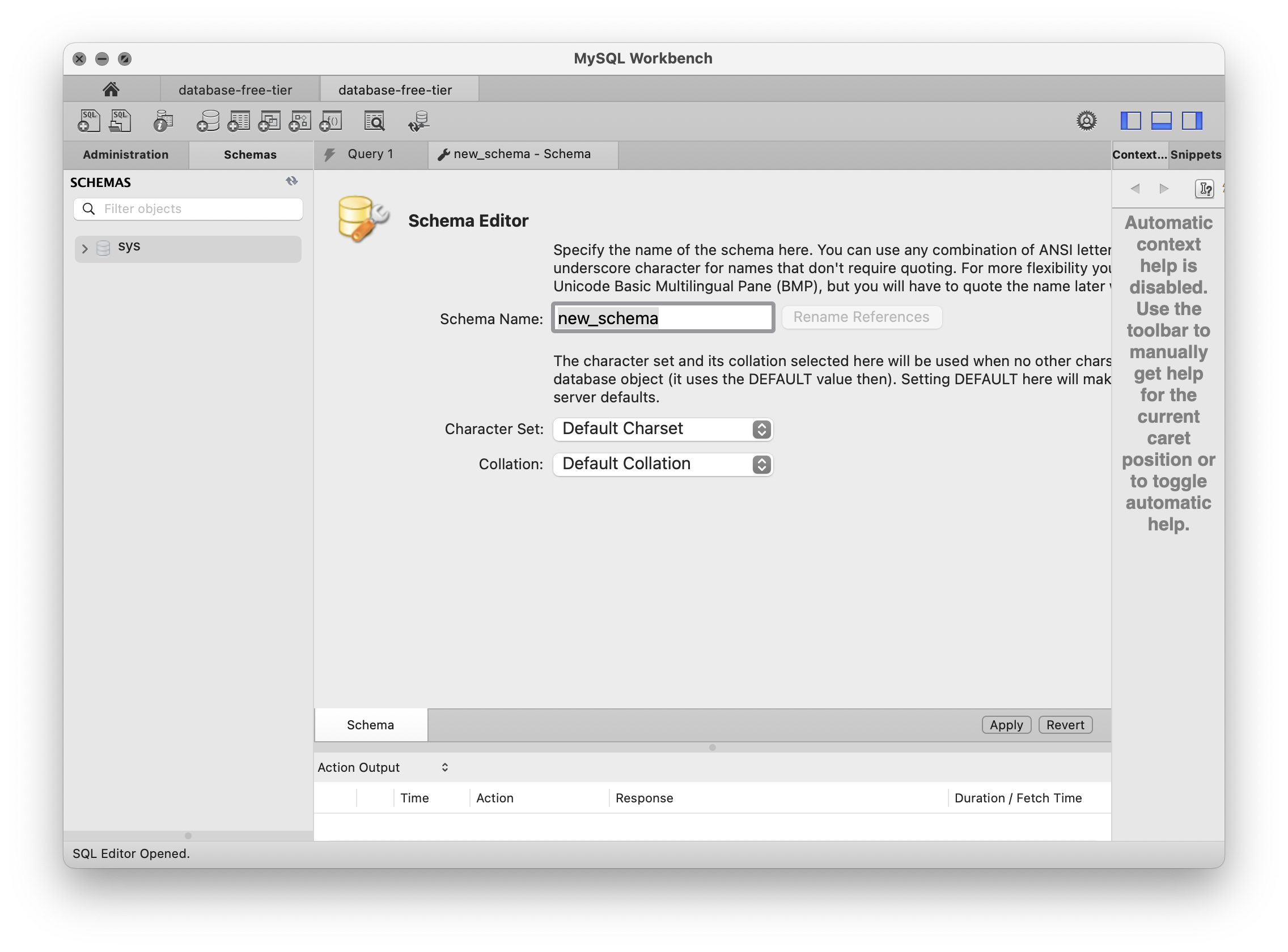
RDMS에서 인원을 관리할 수 있다. %의미는 어디서든 접속이 가능하다는 뜻이다. 그러나 다른 계정들을 보면 localhost라고 되어 있다. 즉 mysql의 localhost에서만 접속이 가능하며 mysql에서 우리에게 기능을 제공해 주기 위해 사용하는 계정일 것이다. 마지막 계정은 amazon에서 만든 계정임을 예상할 수 있다.
이후 기능 관리자마다 다른 목적으로 설정하여 사용자를 추가할 수 있다.
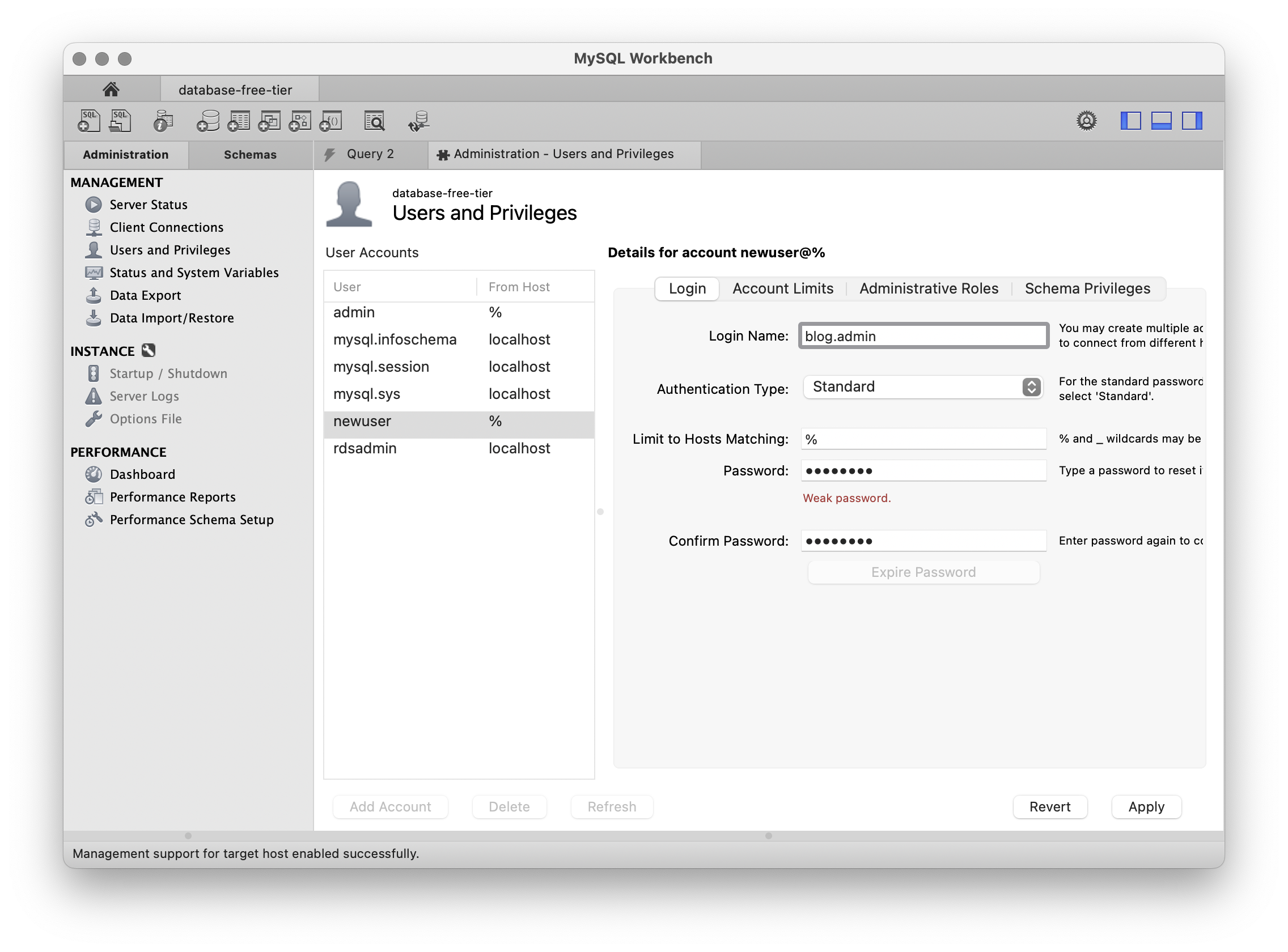
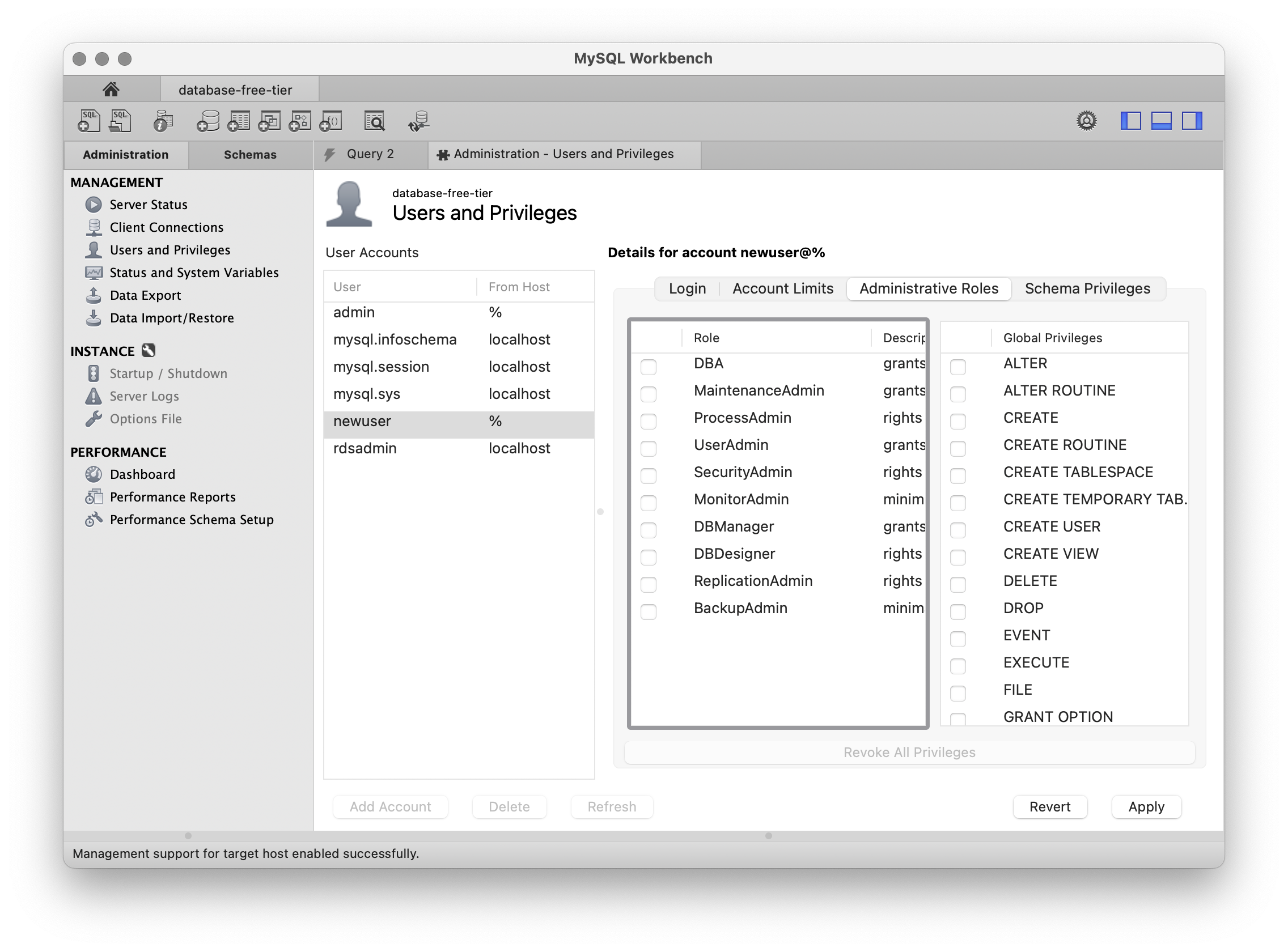
해당 사용자가 사용할 수 있는 쿼리문도 지정할 수 있다.
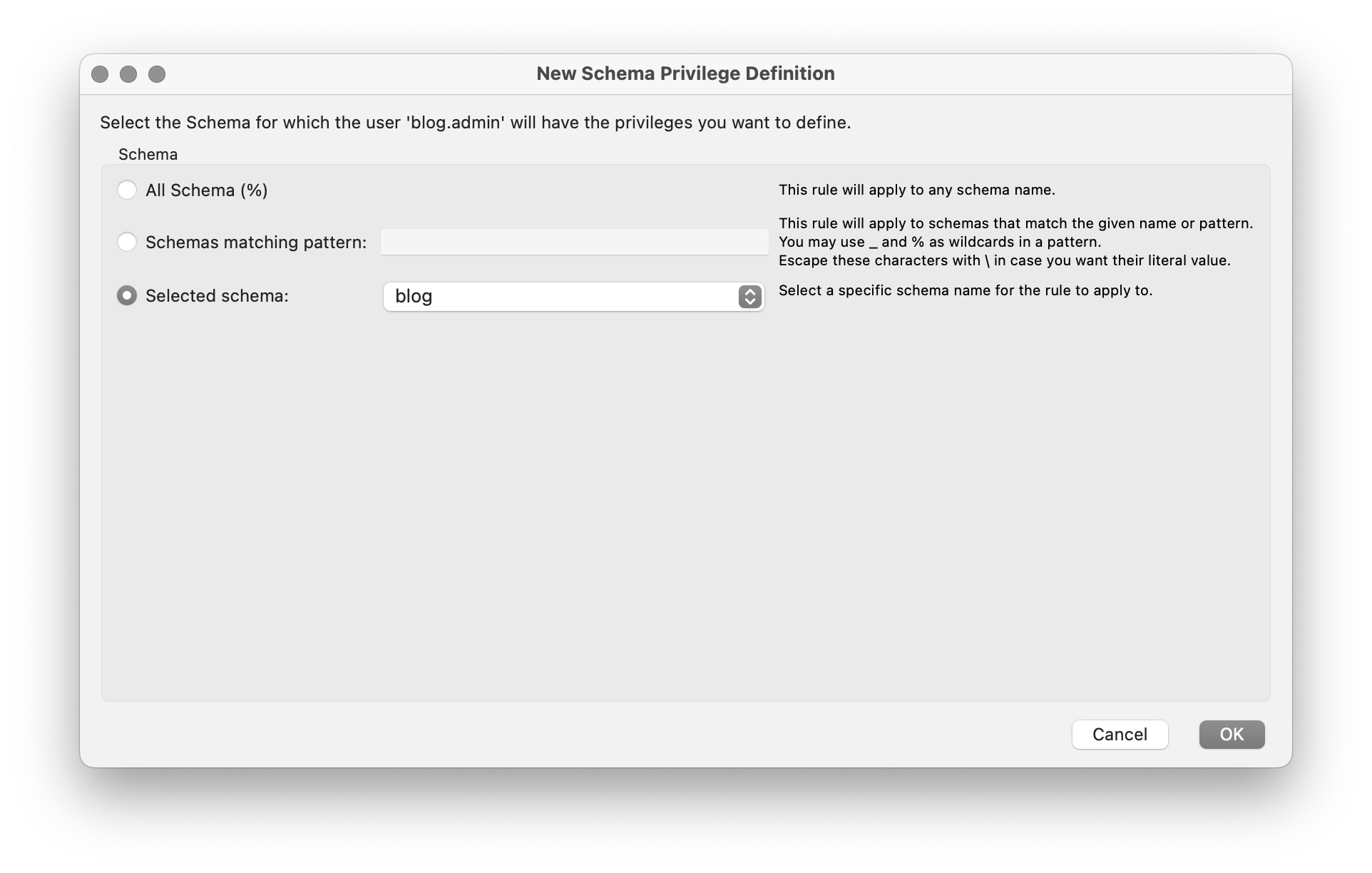
Schema Privileges에 가서 add Entry를 클릭하면 접근 가능한 Schema만 설정해 줄 수 있다.
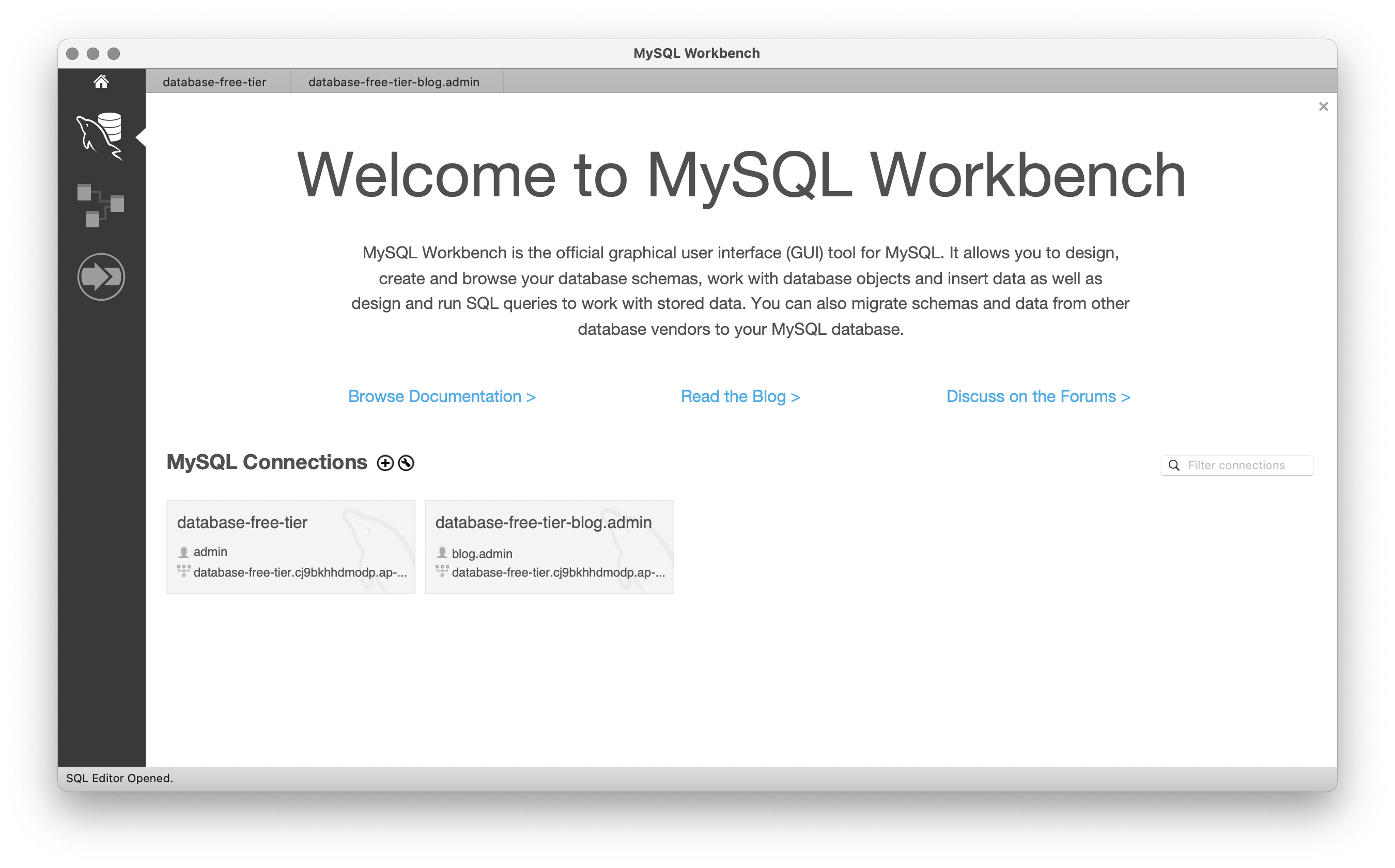
이후 로그인을 하면 내가 지정한 Schema에만 지정할 수 있다.
Normalization
관계형 데이터베이스는 테이블을 나누고 다른 테이블의 PK를 가리키는 Fireign Key 제약사항을 만들어 관계 형성을 할 수 있게 해 준다. 그런데 이게 꼭 필요할까? 한 테이블에 모든 정보를 넣어 주면 안 되는 것일까? 테이블 하나에 모든 정보를 넣는다면 중복되는 데이터가 많고 이를 수정할 때 엄청난 시간적 낭비가 발생하게 된다. 굳이 반복될 필요가 없는 똑같은 데이터가 존재하기 때문에 테이블을 나누는 것을 당연하게 여기는 것이다.
따라서 데이터베이스의 테이블에 담기는 데이터를 적절하게 나누어 구조화하는 방법론을 정규화, 정규형이라고 한다.
우선 상품 데이터를 관리하는 테이블을 만들었다고 생각해 보자.
| id | 상품명 | 상품 설명 | 제조사 | 제조사 국적 | 옵션 | 가격 | 수령 방식 |
|---|---|---|---|---|---|---|---|
| 1 | 마우스_A | DPS 조절 잘되는 마우스 | M사 | 미국 | 무선 | 100 | 택배,방문 |
| 2 | 헤드셋_B | 가성비 좋은 헤드셋 | A사 | 스위스 | 유선 | 80 | 택배 |
| 3 | 키보드_C | 키감 좋은 기계식 키보드 | L사 | 대한민국 | 무선 | 200 | 방문 |
이는 그저 각 레코드가 중복되지 않으면 갖추는, 정규화를 진행하지 않은 상태의 테이블이다.
제1 정규형
제1정규형의 조건은 하나의 컬럼이 복수의 데이터를 가지고 있지 않아야 한다는 것이다. 즉 지금 수령 방식 컬럼은 하나의 레코드에 대해서 복수의 속성을 정의하고 있기 때문에, 이를 별도로 분리해 주어야 마땅합니다.
| id | 상품명 | 상품 설명 | 제조사 | 제조사 국적 | 옵션 | 가격 |
|---|---|---|---|---|---|---|
| 1 | 마우스_A | DPS 조절 잘되는 마우스 | M사 | 미국 | 무선 | 100 |
| 2 | 헤드셋_B | 가성비 좋은 헤드셋 | A사 | 스위스 | 유선 | 80 |
| 3 | 키보드_C | 키감 좋은 기계식 키보드 | L사 | 대한민국 | 무선 | 200 |
| id | 상품 id | 수령 방식 |
|---|---|---|
| 1 | 1 | 택배 |
| 2 | 1 | 방문 |
| … | … | … |
이 형태로 전환 되었을 때 비정규화 테이블 하나가 제1정규형 테이블 둘로 나뉘게 된다.
제2 정규형
하나의 상품을 정의하는 데 주가 되는 정보는 상품명과 상품 설명인데 반해, 옵션과 가격은 이와 연관성이 적다. 제2정규형의 핵심은 기본키에 종속되지 않는 컬럼은 테이블에서 분리되어야 한다는 점이다. 즉 지금처럼 상품 자체에 연관이 적은 옵션과 가격을 별도의 테이블로 분리해야 한다.
| id | 상품명 | 상품 설명 | 제조사 | 제조사 국적 |
|---|---|---|---|---|
| 1 | 마우스_A | DPS 조절 잘되는 마우스 | M사 | 미국 |
| 2 | 키보드_C | 키감 좋은 기계식 키보드 | L사 | 대한민국 |
| … | … | … | … | … |
| id | 상품 id | 옵션 | 가격 |
|---|---|---|---|
| 1 | 1 | 무선 | 100 |
| 2 | 1 | 유선 | 80 |
| 3 | 2 | 무선 | 200 |
| 4 | 2 | 유선 | 180 |
| … | … | … | … |
3 정규형
데이터를 더 추가해 보자.
| id | 상품명 | 상품 설명 | 제조사 | 제조사 국적 |
|---|---|---|---|---|
| 1 | 마우스_A | DPS 조절 잘되는 마우스 | M사 | 미국 |
| 2 | 헤드셋_B | 가성비 좋은 헤드셋 | A사 | 스위스 |
| 3 | 키보드_C | 키감 좋은 기계식 키보드 | L사 | 대한민국 |
| 4 | 헤드셋_D | 가성비 떨어지지만 왠지 인기 있는 헤드셋 | M사 | 미국 |
| … | … | … | … | … |
데이터가 추가되니까 보이는 문제점이 있는데, 제조사 자체는 상품과 종속적인 관계이지만 제조사 국적은 상품 자체가 아닌 제조사의 정보와 종속적인 관계다. 제3정규형은 기본키가 아닌 다른 속성(컬럼)에 종속성을 갖는 컬럼들을 별도로 분리하는 것을 요구한다. (Transitive Dependency)
| id | 상품명 | 상품 설명 | 제조사 Id |
|---|---|---|---|
| 1 | 마우스_A | DPS 조절 잘되는 마우스 | 1 |
| 2 | 헤드셋_B | 가성비 좋은 헤드셋 | 2 |
| 3 | 키보드_C | 키감 좋은 기계식 키보드 | 3 |
| 4 | 헤드셋_D | 가성비 떨어지지만 왠지 인기 있는 헤드셋 | 1 |
| id | 제조사 | 제조사 국적 |
|---|---|---|
| 1 | M사 | 미국 |
| 2 | A사 | 스위스 |
| 3 | L사 | 대한민국 |
