
Algorithm
Stack
Stack
Stack은 후입선출(LIFO, Last-In-First-Out) 원칙에 따라 동작하는 선형 자료구조다. 스택은 데이터의 삽입과 삭제가 한쪽 끝에서만 이루어지는 제한적인 구조를 갖고 있다. 스택은 일상 생활에서 쌓인 책 더미나 접시를 생각할 수 있다. 가장 마지막에 쌓은 책을 가장 먼저 꺼내는 것과 같이, 스택에서는 가장 최근에 삽입한 요소를 가장 먼저 삭제한다.
스택은 주로 다음과 같은 두 가지 기본 연산을 지원한다.
- Push: 스택에 새로운 요소를 삽입하는 연산이다. 요소는 스택의 맨 위에 추가된다.
- Pop: 스택에서 맨 위의 요소를 삭제하고 반환하는 연산이다.
스택은 컴퓨터 과학 및 알고리즘에서 다양한 응용 분야에서 활용된다. 예를 들어, 함수 호출의 임시 데이터 저장, 괄호 검사, 웹 브라우저의 방문 기록 등에서 스택이 사용된다. 또한 스택은 깊이 우선 탐색(DFS) 알고리즘에서도 주요한 역할을 한다.
스택은 크기가 제한되어 있으며, 스택이 가득 차 있는 상태에서의 삽입 연산은 스택 오버플로우(Stack Overflow)로 인해 실패할 수 있다. 반대로, 스택이 비어있는 상태에서의 삭제 연산은 스택 언더플로우(Stack Underflow)로 인해 실패할 수 있다.
일반적으로 배열 또는 연결 리스트를 이용하여 스택을 구현할 수 있습니다. 배열 기반 스택은 고정된 크기를 가지며 메모리 상에 연속적으로 저장되어 있다. 연결 리스트 기반 스택은 동적으로 크기를 조정할 수 있으며, 각 요소가 노드로 구성되어 링크로 연결되어 있다.
import java.util.Arrays;
import java.util.EmptyStackException;
public class Stack01 {
private int[] arr;
private int pointer = 0;
public Stack01(int size) {
this.arr = new int[size];
}
public void push(int value) {
this.arr[pointer++] = value;
}
public int pop() {
if(isEmpty()) throw new EmptyStackException();
return this.arr[--pointer];
}
public void print() {
System.out.println(Arrays.toString(this.arr));
}
public boolean isEmpty() {
return (this.pointer == 0);
}
public int peek() {
return this.arr[pointer - 1];
}
public static void main(String[] args) {
Stack01 stack = new Stack01(10);
stack.push(10);
stack.push(2);
stack.push(4);
stack.print();
stack.pop();
System.out.println(stack.peek());
System.out.println(stack.isEmpty());
}
}Database
Database
Database
데이터베이스는 체계화된 데이터의 모임이다. 데이터베이스는 여러 사용자 또는 응용 프로그램이 공유하여 접근할 수 있는 데이터의 집합이며, 이를 효율적으로 저장, 관리, 검색, 갱신할 수 있는 기능을 제공한다. 데이터베이스는 일반적으로 구조화된 데이터를 저장하고 관리하기 위해 사용된다. 구조화된 데이터란 테이블, 열, 행으로 구성된 데이터를 의미한다. 이러한 데이터는 관계형 데이터베이스 시스템(RDBMS)을 사용하여 표 형태로 저장되며, SQL(Structured Query Language)을 사용하여 조회 및 조작할 수 있다.
데이터베이스는 일반적으로 구조화된 데이터를 저장하고 관리하기 위해 사용됩니다. 구조화된 데이터란 테이블, 열(column), 행(row)으로 구성된 데이터를 의미합니다. 이러한 데이터는 관계형 데이터베이스 시스템(RDBMS)을 사용하여 표 형태로 저장되며, SQL(Structured Query Language)을 사용하여 조회 및 조작할 수 있습니다.
데이터베이스의 주요 특징은 다음과 같다:
- 데이터 중복 최소화: 데이터베이스는 중복된 데이터를 최소화하여 데이터 일관성과 정확성을 유지한다. 데이터 중복이 최소화되면 저장 공간을 절약하고 데이터 일관성을 유지할 수 있다.
- 데이터 무결성: 데이터베이스는 데이터의 무결성을 유지하기 위해 제약 조건(Constraints)을 설정할 수 있다. 이를 통해 데이터의 논리적인 일관성과 정확성을 보장한다.
- 동시성 제어: 데이터베이스는 여러 사용자가 동시에 데이터에 접근하고 수정하는 경우에도 데이터의 일관성과 무결성을 유지할 수 있도록 동시성 제어 기능을 제공한다.
- 데이터 보안: 데이터베이스는 데이터의 안전성과 보안을 위해 액세스 제어와 권한 관리를 제공한다. 데이터에 대한 접근 권한을 제한하고 보안 정책을 적용할 수 있다.
- 데이터 백업 및 복원: 데이터베이스는 데이터의 백업과 복원을 지원하여 데이터 손실을 방지하고 데이터를 복구할 수 있도록 한다.
데이터베이스는 다양한 업무 분야에서 사용되며, 웹 애플리케이션, 은행 시스템, 주문 관리 시스템 등 다양한 응용 프로그램에서 중요한 역할을 한다.
likelion schema 생성한다. schema는 하나의 database라고 생각하면 된다.
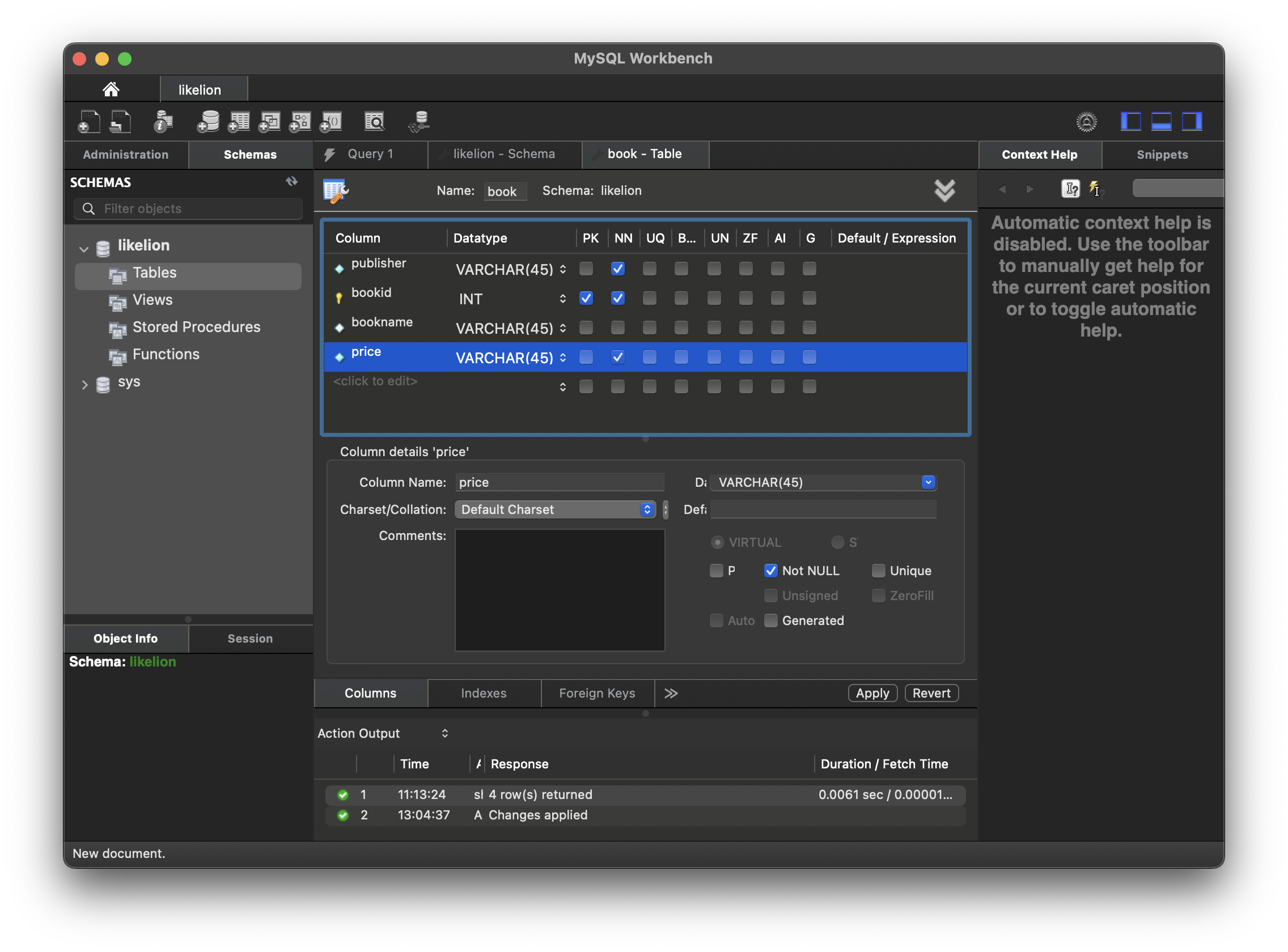
book 테이블을 생성한다. PK를 무조건 지정해 줘야 한다.
Primary Key
사람은 주민등록증, 자동차는 번호판, 계좌는 계좌번호, 사이트는 도메인이 있는 것처럼 특정한 instance를 고유하게 구분해 주는 Attribute이다. 원하는 대상을 정확하게 타겟팅하는 용도로 사용되며, 식별자가 될 속성이 마땅하지 않다면 index 행을 추가해서 식별자를 만들어 줄 수도 있다. 식별자로 사용 가능한 attribute를 cadidate key라고 한다. 이 중 식별자로 채택된 key가 primary key이다.
INSERT
테이블에 데이터 행들을 추가하는 동작을 INSERT Query를 통해 실행할 수 있다. INSERT 구문은 다음과 같이 작성할 수 있다.
INSERT INTO DB_name.table_name
(column1, column2, ...) VALUES (value1, value2 ...)이때 DB명을 계속해서 붙이는 것이 번거롭다면 use 키워드를 사용하면 된다.
use db_name;
INSERT INTO table_name
(column1, column2, ...) VALUES (value1, value2 ...)SELECT
데이터베이스에서 데이트를 조회하는 구문이다.
SELECT column1, column2, ...
FROM table_name
WHERE condition;SELECT로 조회하고 싶은 칼럼을 선택하고 FROM으로 해당 칼럼을 조회할 테이블을 선택한다. WHERE뒤에 조건을 붙여 해당 조건에 알맞은 데이터들만 조회할 수 있다.
LIKE 검색을 통해 해당 단어가 포함되어 있는 데이터들만 조회할 수도 있다. % 기호는 0개 이상의 임의의 문자열을 의미하고, _기호는 임이의 한 문자를 의미한다.
LIKE "_구%" // 축구나무, 농구있네
LIKE "%구%" // 어쩌라구나무IN 연산자는 WHERE 절에서 사용하고 지정된 값 목록 중에 하나와 일치하는 경에 레코드를 반환한다. 아래의 쿼리에서 In 연산자는 괄호 안에서 지정된 값들 중 하나라도 publisher에 있으면 해당 레코드를 반환한다.
SELECT * FROM table_name
WHERE column_name IN ('굿스포츠', '대한미디어');DELETE
데이터베이스에서 특정 레코드를 삭제하기 위한 SQL 구문이다. DELETE 명령어를 사용해서 테이블에서 레코드를 제거할 수 있고, 조건을 설정해서 제거할 수도 있다. 실무에서는 데이터를 삭제하는 일이 거의 없기도 하고, 데이터를 삭제했을 때 발생하는 위험이 어마무시하기 때문에 조심해서 사용해야 하는 구문이다.
DELETE FROM table_name;
DELETE FROM table_name
WHERE condition;UPDATE
데이터베이스에서 특정 레코드의 값을 업데이트하는 구문이다. UPDATE 명령어를 사용하여 테이블의 레코드에 대해 업데이트할 값을 지정할 수 있고, WHERE절을 사용해서 업데이트할 레코드를 조건으로 지정할 수 있다.
UPDATE table_name
SET column_name = value
WHERE condition;JOIN
데이터베이스에서 두 개 이상의 테이블을 연결하여 하나의 테이블로 합칠 때 JOIN 구문을 사용한다. JOIN을 사용해서 두 테이블 간의 공통된 값을 연결하고, 이를 기반으로 새로운 결과 테이블을 생성할 수 있다. JOIN에는 INNER JOIN , LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN 등 여러 종류가 있다. 목적에 따라 JOIN 구문의 종류를 활용해서 다양한 종류의 데이터를 조합해서 원하는 결과를 얻을 수 있다.
