Algorithm
Branket
괄호 풀기
문제 설명
괄호가 바르게 짝지어졌다는 것은 '(' 문자로 열렸으면 반드시 짝지어서 ')' 문자로 닫혀야 한다는 뜻입니다. 예를 들어
- "()()" 또는 "(())()" 는 올바른 괄호입니다.
- ")()(" 또는 "(()(" 는 올바르지 않은 괄호입니다.
'(' 또는 ')' 로만 이루어진 문자열 s가 주어졌을 때, 문자열 s가 올바른 괄호이면 true를 return 하고, 올바르지 않은 괄호이면 false를 return 하는 solution 함수를 완성해 주세요.
제한사항
- 문자열 s의 길이 : 100,000 이하의 자연수
- 문자열 s는 '(' 또는 ')' 로만 이루어져 있습니다.
입출력 예
| s | answer |
|---|---|
| "()()" | true |
| "(())()" | true |
| ")()(" | false |
| "(()(" | false |
Branket - Solving
()로 하나씩 짝지어진 괄호가 있을 때 이를 공백 문자로 바꾸는 일을 반복하는 방식으로 문제를 풀 수 있다. () 괄호가 있을 때까지 이를 반복하고, 주어진 문자열의 길이가 0인지 아닌지를 체크함으로 문제를 풀 수 있다.
public class BracketWithoutStack {
public static void main(String[] args) {
String brackets = "((((()))))";
while(brackets.indexOf("()") != -1) {
brackets = brackets.replace("()", "");
}
System.out.println(brackets.length() == 0);
}
}하지만 이 경우 반복문이 있기 때문에 시간이 많이 소요된다. 한 반복을 돌 때마다 () 쌍으로 있는 모든 괄호를 대체하는 방식으로 코드를 다시 짤 수 있다. 괄호는 이스케이프 처리가 필요하여 \(, \)로 표기한다.
public class BracketWithoutStack2 {
public static void main(String[] args) {
String brackets = "((()()))()";
while(brackets.indexOf("()") != -1) {
String[] split = brackets.split("\\(\\)");
brackets = String.join("", split);
}
System.out.println(brackets.length() == 0);
}
}Database
Course Student
course student 데이터 베이스를 생성해 준다.
users 테이블을 생성해 준다.
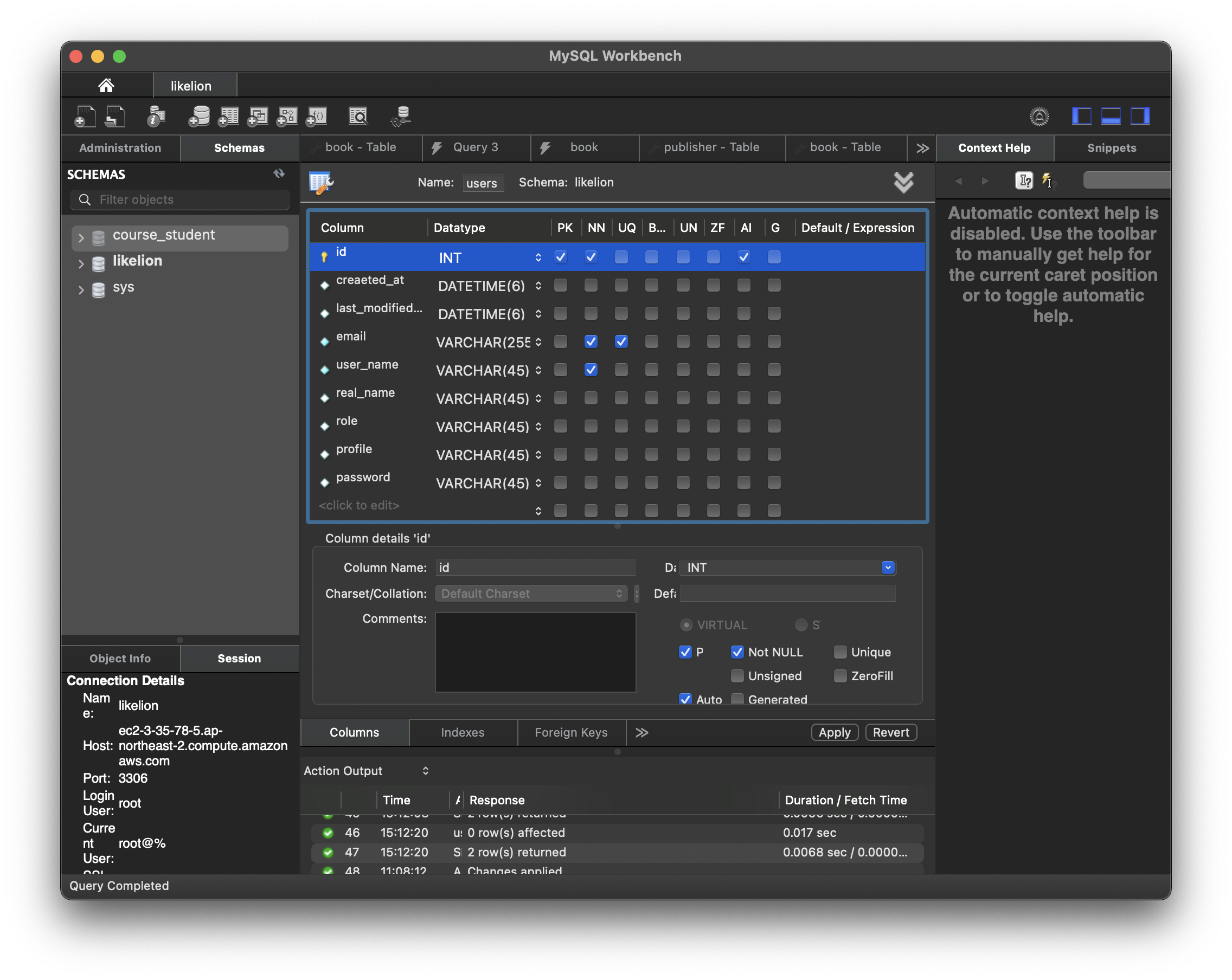
CREATE TABLE `course_student`.`users` (
`id` int NOT NULL AUTO_INCREMENT,
`creaeted_at` datetime(6) DEFAULT NULL,
`last_modified_at` datetime(6) DEFAULT NULL,
`email` varchar(255) NOT NULL,
`user_name` varchar(45) NOT NULL,
`real_name` varchar(45) DEFAULT NULL,
`role` varchar(45) DEFAULT NULL,
`profile` varchar(45) DEFAULT NULL,
`password` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `email_UNIQUE` (`email`)
);task 테이블을 생성해 준다.
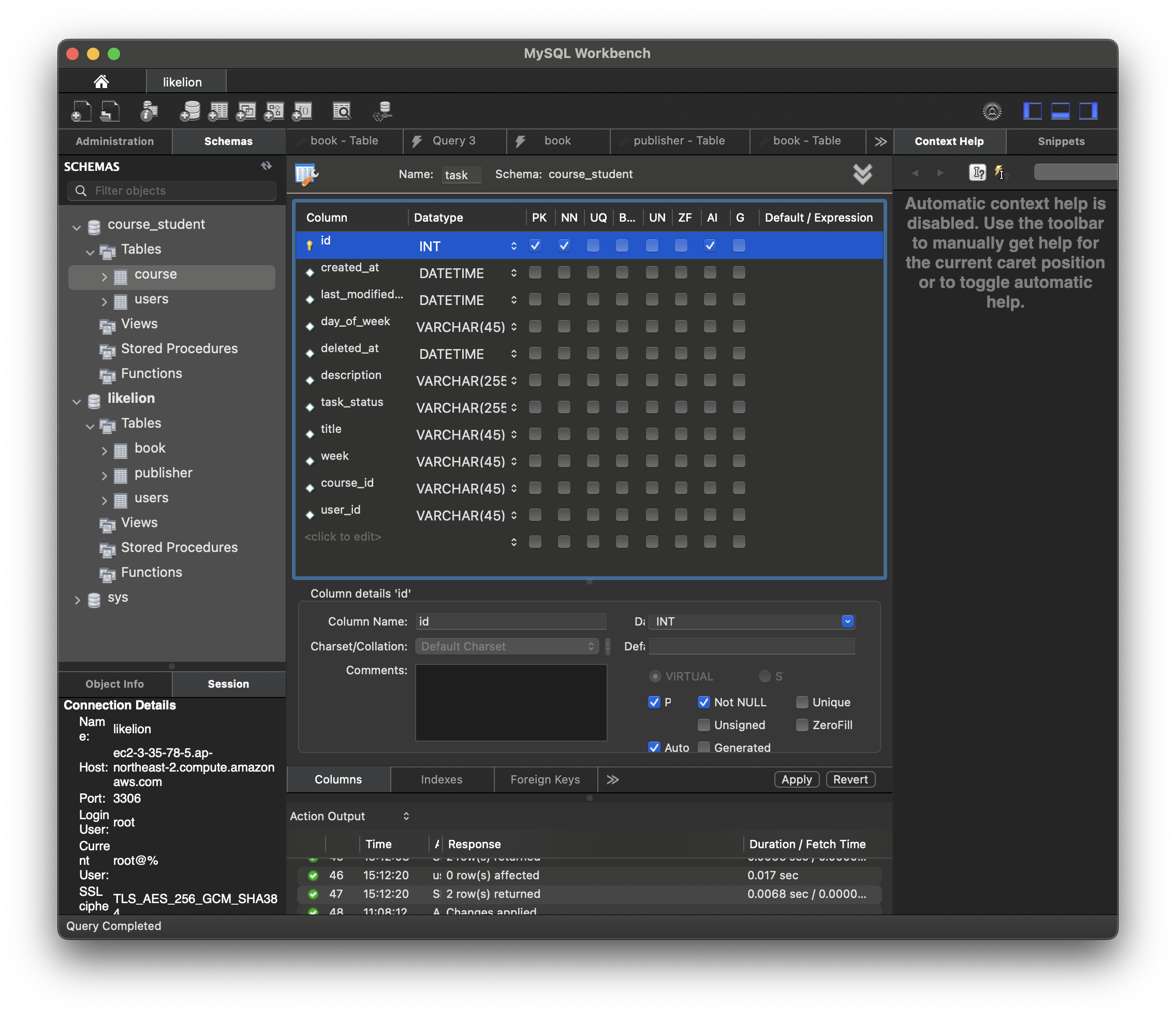
CREATE TABLE `course_student`.`task` (
`id` INT NOT NULL AUTO_INCREMENT,
`created_at` DATETIME NULL,
`last_modified_at` DATETIME NULL,
`day_of_week` VARCHAR(45) NULL,
`deleted_at` DATETIME NULL,
`description` VARCHAR(255) NULL,
`task_status` VARCHAR(255) NULL,
`title` VARCHAR(45) NULL,
`week` VARCHAR(45) NULL,
`course_id` VARCHAR(45) NULL,
`user_id` VARCHAR(45) NULL,
PRIMARY KEY (`id`));사용자가 속한 기수의 정보를 담을 수 있는 테이블 “course”를 생성합니다. IO가 빈번하게 사용되지는 않지만 기수를 표시하기 위해 사용되고, 항상 사용되는 값이다.

CREATE TABLE `course_student`.`course` (
`id` INT NOT NULL AUTO_INCREMENT,
`created_at` DATETIME NULL,
`last_modified_at` DATETIME NULL,
`course_status` VARCHAR(45) NULL,
`description` VARCHAR(255) NULL,
`end_date` DATE NULL,
`name` VARCHAR(255) NULL,
`star_date` DATE NULL,
`user_id` VARCHAR(45) NULL,
PRIMARY KEY (`id`));users 테이블에 레코드를 추가합니다.
INSERT INTO `course_student`.users
(`created_at`,`last_modified_at`,`email`,`password`,`real_name`,`role`,`user_name`) VALUES
('2023-03-12 20:31:58.841752','2023-03-29
15:24:49.345051','aaaa-test@aaaaa.com','1234','테스트학생','ROLE_STUDENT','student1234');task 테이블에 레코드를 추가합니다.
INSERT INTO `course_student`.task
(`created_at`,`last_modified_at`,`day_of_week`,`deleted_at`,`description`,`task_status`,`title`,`week`,`course_id`,`user_id`) VALUES
('2023-04-02 00:14:51.586722','2023-04-02
00:14:51.586722', 4, NULL, 'description', 'IN_PROGRESS', 'user, task 테이블 만들기', 5, 1, 1);course 테이블에 레코드를 추가합니다.
INSERT INTO course_student.course (name) VALUES ('멋사 백엔드 5기'); users와 course를 연결해야 하는데, 이때 두 개의 방법이 존재한다. user table에 course_id를 추가해서 join을 거는 방법과 연관 관계를 나타내는 테이블인 course_user table을 추가해 주는 것이다. 보통 N:M 관계에서는 두 번째 방법을 사용한다. 그림으로 나타내면 아래와 같다. 아래 DB 기준 course와 user는 관계가 없다. 다만 course와 course_user과의 관계, 그리고 user와 course_user과의 관계만 존재할 뿐이다.
| user_id | real_name |
|---|---|
| 1 | 김경록 |
| 2 | 김미미 |
| course_user_id | course_id | user_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 3 |
| 4 | 2 | 4 |
만약 한 사람은 하나의 course만 들을 수 있다면 다음과 같은 설계가 가능하고, 이는 1:1 관계에서만 해야 중복이 제거된다.
| user_id | real_name | course |
|---|---|---|
| 1 | 김경록 | 1 |
| 2 | 김미미 | 1 |
따라서 course_user 테이블을 만들어 준다.
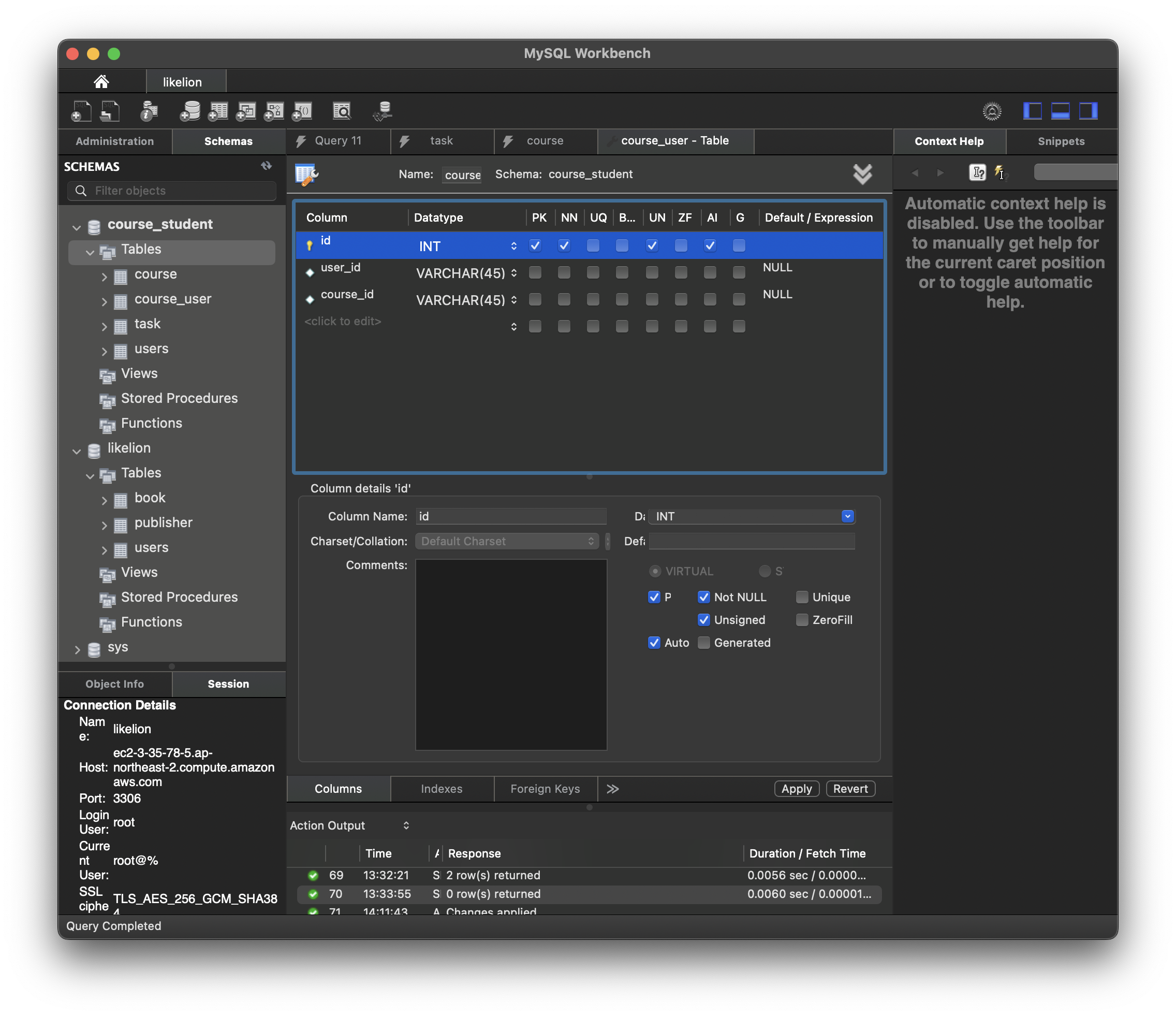
CREATE TABLE `course_student`.`course_user` (
`id` INT NOT NULL AUTO_INCREMENT,
`user_id` VARCHAR(45) NULL,
`course_id` VARCHAR(45) NULL,
PRIMARY KEY (`id`));이후 course_user 테이블에 데이터를 추가해서 관계를 설정해 준다.
INSERT INTO `course_student`.`course_user` (`id`, `user_id`, `course_id`) VALUES ('1', '1', '1');
INSERT INTO `course_student`.`course_user` (`user_id`, `course_id`) VALUES ('1', '2');같은 맥락으로 user와 task를 연결하는 user_task 테이블도 생성한다. 이 경우 특정 유저의 특정 태스크가 완료되었는지 진행 중인지 에러인지를 나타내는 status 칼럼이 하나 추가된다.
| user_id | real_name |
|---|---|
| 1 | 김경록 |
| 2 | 김미미 |
| user_task_id | task_id | user_id | status |
|---|---|---|---|
| 1 | 1 | 1 | 진행 중 |
| 2 | 1 | 2 | 완료 |
| 3 | 2 | 1 | 완료 |
| 4 | 2 | 2 | 에러 |
따라서 user_task 테이블을 생성해 준다.
CREATE TABLE `course_student`.`user_task` (
`id` bigint NOT NULL AUTO_INCREMENT,
`task_id` bigint DEFAULT NULL,
`user_id` bigint DEFAULT NULL,
`status` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
);해당 테이블에 데이터를 하나 넣어 준다.
USE course_student;
INSERT INTO `user_task` (`user_id`, `task_id`, `status`)
VALUES ('1', '2', 'DONE');태스크의 상태를 수정하는 건 다음과 같은 쿼리문으로 실행한다.
UPDATE `course_student`.`user_task`
SET `status` = 'DONE' WHERE (`id` = '1');SQL 연습을 위해 DUMP된 병원 데이터 하나를 import해 온다.
https://drive.google.com/file/d/1h593YbkQ08_nUDr6u2H2a40FxTU4DmVJ/view
잘 불러와진 것을 다음과 같이 확인할 수 있다.

병원 종류 별로 가장 많은 순서에 따라 정렬한 리스트를 출력하는 쿼리는 다음과 같다.
SELECT business_type_name, count(*)
FROM `likelion_two`.nation_wide_hospitals
GROUP BY business_type_name
ORDER BY count(*) desc;
Query
5주차 4일차의 모든 task를 Task id, title만 출력

USE course_student;
SELECT id, title FROM task
WHERE week = 5 AND day_of_week = 4;멋사 5기의 모든 학생의 real_name과 id 출력

USE course_student;
SELECT users.id, users.real_name
FROM users, course, course_user
WHERE users.id = course_user.user_id
AND course_user.course_id = course.id
AND course.id = 1;User별 Task 진행 상황: 하루에 10개의 task가 있다고 했을 때 100명의 학생 각각의 진행 상황이 필요히다.
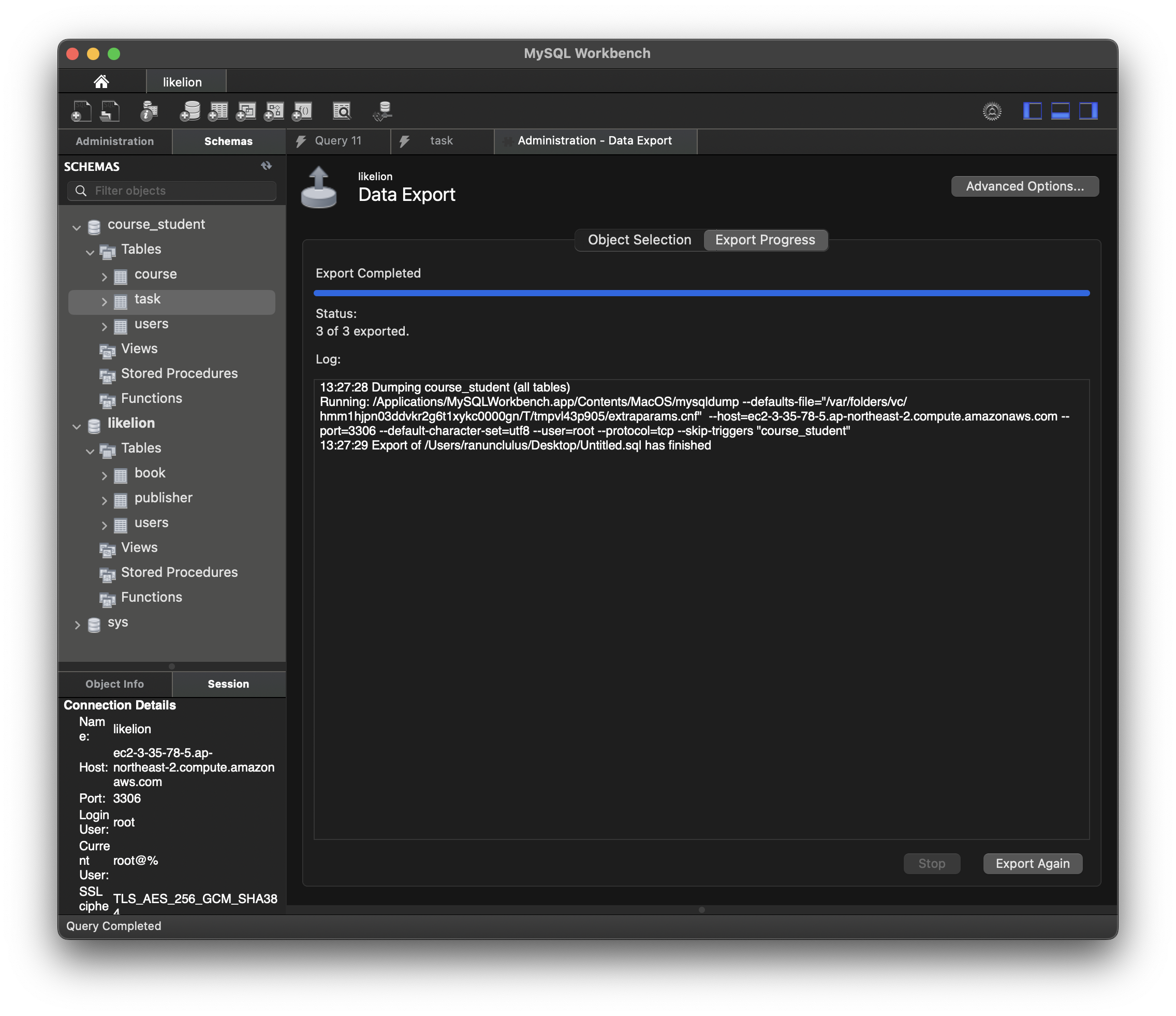
Database Dump
Database를 나중에 복구하기 위한 용도로 Dump를 떠서 보관하기도 한다.
메뉴의 Server에서 Data export 창을 선택한다.
원하는 schema를 선택한다.
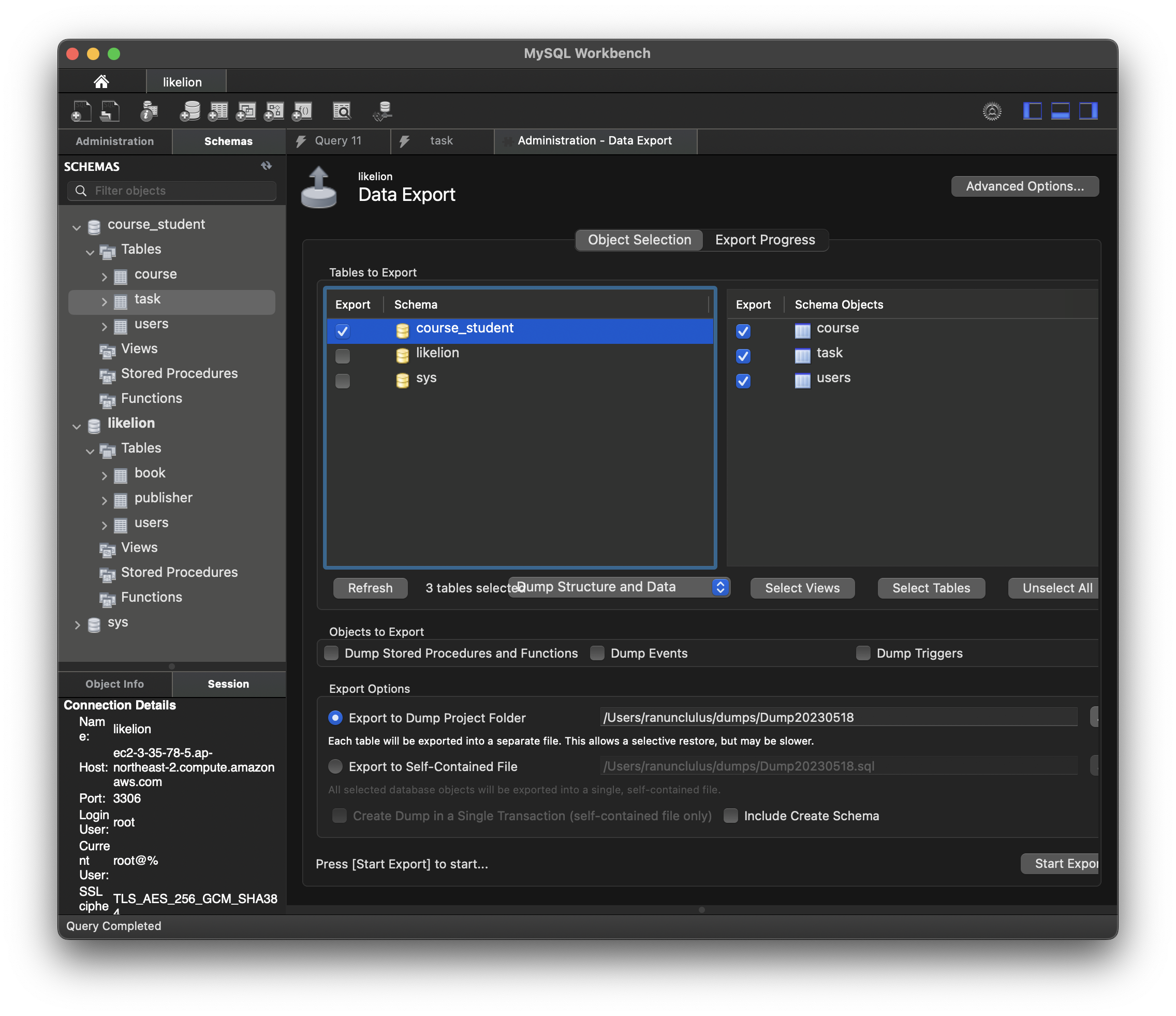
self-contained file을 선택한다.

저장될 파일을 선택하고 start export를 누르면 덤프가 완료된다.