
Abstract and Interface
Abstract
Abstract Class
추상 클래스는 하나 이상의 추상 메소드를 포함하는 클래스이다. 추상 메소드란 메소드 선언만 있고 구현이 없는 메소드로, 구현은 상속받은 클래스에서 진행한다. 추상 클래스는 직접적으로 인스턴스화할 수 없고 상속을 통해서만 사용한다. 추상 클래스는 추상 메소드 외에도 일반적인 메소드와 인스턴스 변수도 포함시킬 수 있다.
추상 클래스의 주요 목적은 공통된 기능과 속성을 가진 클래스들을 모델링하고 코드 재사용성과 확장성을 높이기 위해서이다. 자식 클래스들이 공통적으로 가지고 있는 메소드와 변수를 묶은 개념이라고 생각하면 된다.
추상 메소드 vs 일반 메소드
추상메소드는 메소드 선언만 있고 구현이 없다. 즉, 행위에만 집중돼 있다. 반면 일반 메소드는 자세하고 구체적인 구현이 포함되어 있다. 따라서 추상 메소드는 하위 클래스에서 반드시 구현되어 있어야 사용이 가능하지만, 일반 메소드는 이미 구현되어 있어서 특별한 구현이 더 필요하지 않다. 하나의 클래스는 추상 클래스와 함께 인터페이스까지 동시에 상속받을 수 있다.
예를 들어 동물이라는 추상 클래스를 가지고 각각 강아지 고양이라는 하위 클래스가 울음소리를 내는 것을 구현해 본다면 다음과 같다. 먼저 추상 클래스를 정의한다.
public abstract class Animal {
public abstract void makeSound();
}이후 Animal을 상속받은 강아지, 고양이 클래스에서 해당 메소드를 구체적으로 구현한다.
public class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("야옹야옹");
}
}public class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("멍멍");
}
}Interface
Interface
인터페이스는 추상 메소드, 상수 및 디폴트 메소드로 이루어진 참조 타입이다. 추상 클래스와 다르게 추상 메소드만 가지고 있으며 일반 메소드의 구현은 포함하지 않는다. 인터페이스는 어떤 골격을 정의하는 것이다.
인터페이스의 주요 목적은 클래스 사이의 명세를 정의하는 것이다. 인터페이스는 코드의 유연성과 재사용성을 높여 준다. 클래스가 여러 개의 인터페이스를 구현할 수 있으므로 다양한 기능을 가진 객체를 생성할 수 있다. 인터페이스는 클래스 간의 결합도를 낮추고 코드의 의존성을 관리하기 쉽게 해 준다.
결합도를 낮춘다는 것은 클래스로 구현해 놓으면 수정 사항이 생길 때마다 클래스를 다 고쳐야 하지만 인터페이스로 구현해 놓으면 수정 사항이 생겼을 때 클래스마다 하나하나 코드를 수정하지 않아도 된다.
JAVA에서 클래스는 다중 상속을 지원하지 않지만 인터페이스는 지원해 준다. 클래스는 단일 클래스로부터만 상속을 받을 수 있지만 인터페이스는 여러 개의 인터페이스를 상속받을 수 있다. 인터페이스 간의 다중 상속으로 인해 충돌하는 메서드 구현이 있을 경우 해당 클래스에서 그 메소드를 재정의해야 한다.
인터페이스를 상속받은 클래스에서는 인터페이스에서 정의한 모든 추상 메서드를 구현해야 한다. 인터페이스에서 선언된 모든 상수는 구현 클래스에 상속되어 사용할 수 있다. 같은 인터페이스를 사용하는 클래스들은 동일한 행위를 한다는 것을 보장한다.
의존 역전 원칙 (Dependency Inversion Principle)
의존 관계를 맺을 때 변화하기 쉬운 것 또는 자주 변화하는 것보다는 변화하기 어려운 것, 거의 변화가 없는 것에 의존해야 한다. 한마디로 구체적인 클래스보다 인터페이스나 추상 클래스와 관계를 맺어야 한다.
하나의 인터페이스는 여러 개의 인터페이스를 extends 키워드를 통해 상속받을 수 있다. 이때 상속받은 인터페이스의 메소드들을 선택적으로 구현할 수 있다. 예를 들어 Shape이라는 인터페이스를 상속받은 Circle 클래스를 만든다고 가정해 보자. 먼저 인터페이스를 정의한다.
public interface Shape {
public double calculateArea();
}이후 Shape을 상속받은 클래스 Circle에서 해당 메소드를 구체화시킨다.
public class Circle implements Shape{
private double radius;
public Circle(double radius) {
this.radius = radius;
}
@Override
public double calculateArea() {
return (radius * radius * 3.14);
}
}이를 확장시켜서 둘레를 구하는 calculaterPerimeter 함수도 인터페이스에 정의한 뒤, Circle과 Rectangel 클래스를 나누어서 작성하면 다음과 같다. 먼저 인터페이스 코드에 함수를 추가해 준다.
public interface Shape {
public double calculateArea();
public double calculaterPerimeter();
}이후 Circle과 Rectangle 클래스에서 구현해 준다.
public class Circle implements Shape{
private double radius;
public Circle(double radius) {
this.radius = radius;
}
@Override
public double calculateArea() {
return (radius * radius * 3.14);
}
@Override
public double calculaterPerimeter() {
return (2 * radius * 3.14);
}
}public class Rectangle implements Shape {
private double height;
private double width;
public Rectangle(double height, double width) {
this.height = height;
this.width = width;
}
@Override
public double calculateArea() {
return (height * width);
}
@Override
public double calculaterPerimeter() {
return (2 * (height + width));
}
}Abstract Class vs Interface
추상 클래스와 인터페이스 공통점
둘 모두 추상 메서드를 포함할 수 있고 기능 확장에 용이하며 다형성을 지원한다. 클래스 간의 관련성을 나타내는 용도로 사용할 수 있다.
추상 클래스와 인터페이스 차이점
추상 클래스는 추상 메소드 외에도 일반 메소드와 인스턴스 변수를 가질 수 있지만, 인터페이스는 추상 메소드, 디폴트 메소드, 정적 메소드, 상수만을 가질 수 있다. 또한 추상 클래스는 단일 상속을 가지지만 인터페이스는 다중 상속을 지원한다. 추상 클래스는 상속에 가깝고 인터페이스는 구현에 가깝다. 추상 클래스의 상속은 is-a 관계지만 인터페이스의 구현은 has-a 관계를 가진다.
Is a Relationship
notebook is a computer (O)
laptop is a desktop (X)
Is a Relationship
Is-a 관계는 객체 지향 프로그래밍에서 사용되는 상속 관계를 의미한다. 이 관계는 클래스 간의 계층 구조를 형성하며, 한 클래스가 다른 클래스의 하위 클래스인 경우를 나타낸다.
Is-a 관계는 "A는 B이다"라는 문장으로 표현될 수 있다. 예를 들어, "사람은 동물이다"라는 문장에서 사람 클래스는 동물 클래스의 하위 클래스로서 Is-a 관계를 가지고 있다.
Is-a 관계는 상속을 통해 구현됩니다. 하위 클래스는 상위 클래스의 특성과 동작을 상속받아 사용할 수 있습니다. 이를 통해 코드의 재사용성을 높일 수 있고, 객체 지향의 다형성 개념을 활용할 수 있습니다.
Has a Relationship
Has-a 관계는 객체 지향 프로그래밍에서 사용되는 연관 관계를 의미한다. 이 관계는 한 클래스가 다른 클래스를 포함하고 있는 경우를 나타낸다.
Has-a 관계는 "A는 B를 가지고 있다"라는 문장으로 표현될 수 있다. 예를 들어, "자동차는 엔진을 가지고 있다"라는 문장에서 자동차 클래스는 엔진 클래스를 포함하고 있어 Has-a 관계를 가지고 있다.
Has-a 관계는 클래스 간의 구성(composition) 또는 집합(aggregation) 관계로 구현될 수 있다. 구성 관계는 한 클래스가 다른 클래스의 부분으로서 완전히 종속되는 관계를 나타내며, 부분 객체의 생명 주기와 전체 객체의 생명 주기가 밀접하게 연관된다. 집합 관계는 한 클래스가 다른 클래스의 일부를 포함하지만, 포함된 객체의 생명 주기와 전체 객체의 생명 주기가 독립적이다.
Collection, Generic, Exception
Collection
Collection
컬렉션 프레임워크는 자바에서 데이터를 저장, 관리 및 조작하는 데 사용되는 API 집합이다. 이 프레임워크는 데이터 구현과 관련된 클래스와 인터페이스를 제공하여 데이터를 효율적으로 저장되고 조작할 수 있도록 도와준다.
컬렉션과 배열은 모두 여러 개의 요소를 저장하는 데 사용되지만, 고정적 크기를 가지는 배열과 다르게 컬렉션은 동적으로 크기가 조정될 수 있다. 동일한 데이터 타입의 요소만 저장되는 배열에 비해 컬렉션은 다양한 데이터가 들어갈 수 있다. 만약 배열처럼 같은 데이터 타입만 넣고 싶다면 제네릭을 통해 타입을 지정할 수도 있다. 컬렉션은 배열에 비해 검색, 정렬, 필터링, 반복 등 다양한 연산도 지원한다.
Collection: 컬렉션의 일반적인 동작을 정의한다.
List: 순서가 있는 컬렉션을 정의하며, 중복된 요소를 허용한다. 요소에 대한 인덱스를 사용하여 접근이 가능하다.
Set: 중복된 요소를 허용하지 않는 순서가 없는 컬렉션이다.
Queue: FIFO(First-In-First-Out) 순서를 따르는 자료 구조이다.
Stack: LIFO(Last in First Out) 순서를 따르는 자료 구조이다.
Map: 키와 값으로 구성된 요소의 집합을 정의한다. 각 요소는 유일한 키를 가지며, 키를 사용하여 값을 검색하고 조작할 수 있다.
List
순서가 있는 컬렉션으로, 중복된 요소를 허용한다.다. 인덱스를 사용하여 요소에 접근할 수 있다. List를 구현한 클래스로 ArrayList, LinkedList 등이 있다. add, get, remove 등의 메서드를 사용하여 요소를 추가, 조회, 삭제할 수 있다.
List<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
names.add("Charlie");
System.out.println(names.get(0)); // Alice
System.out.println(names.size()); // 3
names.remove("Bob");
System.out.println(names); // [Alice, Charlie]Set
중복된 요소를 허용하지 않는 순서가 없는 컬렉션입니다. Set을 구현한 클래스로 HashSet, TreeSet 등이 있다. add, contains, remove 등의 메서드를 사용하여 요소를 추가, 포함 여부 확인, 삭제할 수 있다.
Set<String> fruits = new HashSet<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Apple"); // 중복된 요소이므로 추가되지 않음
System.out.println(fruits.contains("Banana")); // true
System.out.println(fruits.size()); // 2
fruits.remove("Apple");
System.out.println(fruits); // [Banana]Map
키와 값으로 구성된 요소의 집합이다. 각 요소는 유일한 키를 가지며, 키를 사용하여 값을 검색하고 조작할 수 있다. Map을 구현한 클래스로 HashMap, TreeMap 등이 있다. put, get, remove 등의 메서드를 사용하여 키-값 쌍을 추가, 조회, 삭제할 수 있다.
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 80);
scores.put("Bob", 90);
scores.put("Charlie", 75);
System.out.println(scores.get("Bob")); // 90
System.out.println(scores.containsKey("Charlie")); // true
scores.remove("Alice");
System.out.println(scores); // {Bob=90, Charlie=75}Queue 인터페이스
요소를 추가하거나 제거할 때 특정 순서를 따르는 컬렉션을 정의한다. 일반적으로 FIFO(First-In-First-Out) 순서를 따릅니다. Queue를 구현한 클래스로 LinkedList, PriorityQueue 등이 있다. offer, poll, peek 등의 메서드를 사용하여 요소를 추가, 제거, 조회할 수 있다.
Queue<String> queue = new LinkedList<>();
queue.offer("A");
queue.offer("B");
queue.offer("C");
System.out.println(queue.poll()); // A
System.out.println(queue.peek()); // B
System.out.println(queue.size()); // 2Stack 인터페이스
요소를 추가하거나 제거할 때 LIFO(Last-In-First-Out) 순서를 따르는 컬렉션이다. Stack을 구현한 클래스로 Stack 클래스가 있다. push, pop, peek 등의 메서드를 사용하여 요소를 추가, 제거, 조회할 수 있다.
Stack<String> stack = new Stack<>();
stack.push("A");
stack.push("B");
stack.push("C");
System.out.println(stack.pop()); // C
System.out.println(stack.pop()); // BGeneric
Generic
컴파일하는 시점 (소스 코드 작성 시점)에 타입을 안정하게 지정하기 위한 기능이다.
컴파일 시점에서 타입 안정성을 검사하기 때문에 런타임 오류를 방지한다. 또한 일반화된 타입을 사용하여 여러 종류의 객체를 처리하기 때문에 코드의 재사용성을 높일 수 있다. 제네릭을 사용하면 타입 정보가 명시되어 가독성이 좋아진다는 장점이 있다.
Exception
Error vs Exception
자바에서는 애플리케이션 실행 시 발생할 수 있는 오류를 '에러(error)'와 '예외(exception)' 두 가지로 구분한다. 에러는 메모리 부족, 스택오버플로우와 같이 발생하게 되면 복구할 수 없는 심각한 오류이고, 예외는 발생하더라도 수습할 수 있을 정도의 비교적 덜 심각한 오류이다. 에러는 발생 시 막을 방도가 없지만, 예외는 프로그래머가 예외처리를 통해서 비정상종료를 사전에 방지할 수 있다. 아래는 예외 클래스의 구조이다.
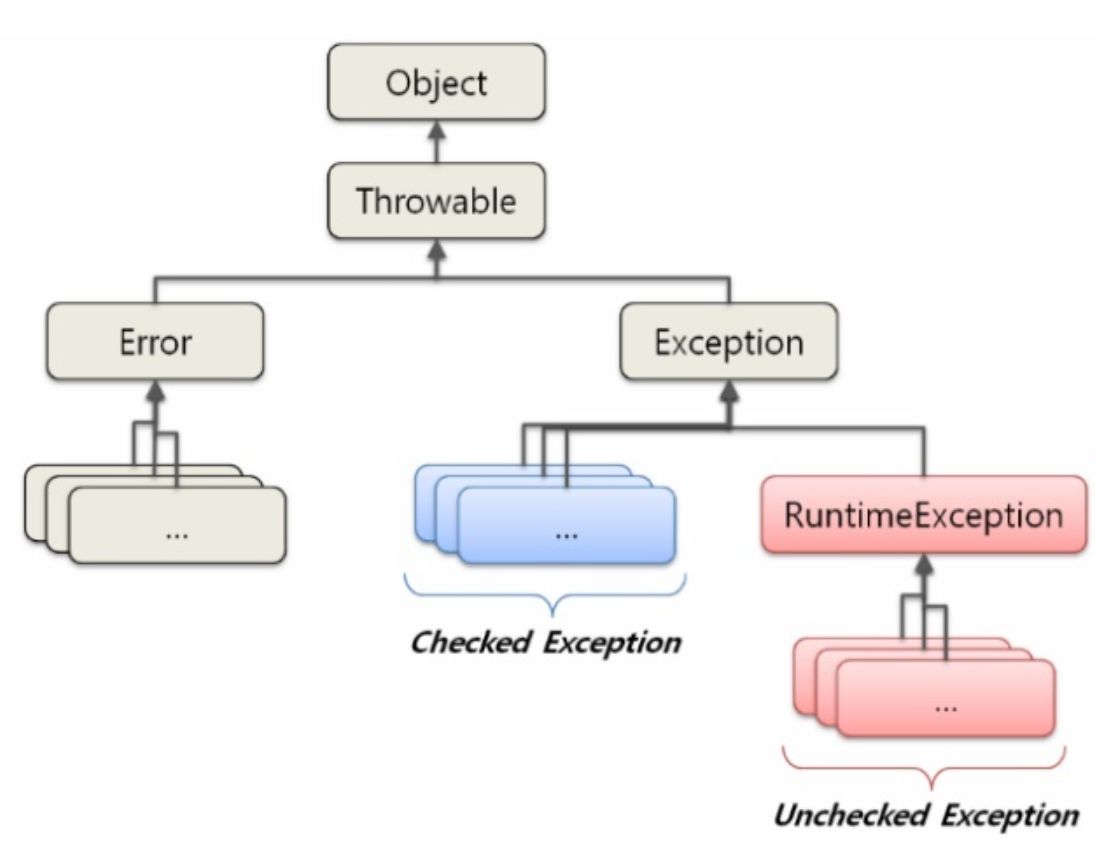
Checked Exception vs Unchecked Exception
위 그림 처럼 두 개 예외의 차이점은 처리여부이다.Checked Exception은 반드시 소스 코드내에서 예외를 처리해야만 실행단계로 넘어간다. 즉, 컴파일 단계에서 확인을 하기 때문에 반드시 예외 처리를 구현해야 하는 경우이다. 아래 코드는 자바 파일 자체가 실행되지 않는다. Checked Exception인 Exception 처리를 추가해 주지 않았기 때문이다.
public class CheckedException {
public static void main(String[] args) {
try{
throw new Exception();
}
}
}아래와 같이 예외 처리를 해 주어야 코드가 실행된다.
public class CheckedException {
public static void main(String[] args) {
try{
throw new Exception();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}| Checked | Unchecked |
|---|---|
| IOExceptiont | NullPointerException |
| SqlException | llegalArgumentException |
| IndexOutOfBoundException |
Exception handling
Try Catch
try 블록 안에서 예외가 발생할 수 있는 코드를 작성한다. catch 블록은 try 블록에서 발생한 예외를 처리하는 부분이다. catch 블록은 예외 타입에 따라 여러 개를 작성할 수 있으며, 발생한 예외와 일치하는 catch 블록이 실행된다. finally 블록은 선택적으로 작성할 수 있으며, 예외 발생 여부와 상관없이 항상 실행된다.
try {
// 예외가 발생할 수 있는 코드
} catch (예외 타입1 변수명1) {
// 예외 처리 코드
} catch (예외 타입2 변수명2) {
// 예외 처리 코드
} finally {
// 항상 실행되는 코드 (선택적)
}throws
메서드 선언부에 throws 키워드를 사용하여 메서드에서 발생할 수 있는 예외를 명시한다. 메서드를 호출하는 곳에서 예외를 처리하도록 할 수 있다.
void 메서드명() throws 예외타입1, 예외타입2 {
// 예외가 발생할 수 있는 코드
}User Define Exception Class
아래 예제에서 MyException 클래스는 Exception 클래스를 상속받아 사용자 정의 예외 클래스를 만들었다. 생성자를 통해 예외 메시지를 설정할 수 있다.
class MyException extends Exception {
public MyException() {
super("사용자 정의 예외가 발생했습니다.");
}
public MyException(String message) {
super(message);
}
}아래 예제에서 throwException 메서드에서 MyException을 발생시키고, main 메서드에서 해당 예외를 처리한다. 실행 결과는 "사용자 정의 예외를 발생시킵니다."라는 메시지가 출력한다.
public class Main {
public static void main(String[] args) {
try {
throwException();
} catch (MyException e) {
System.out.println(e.getMessage());
}
}
public static void throwException() throws MyException {
throw new MyException("사용자 정의 예외를 발생시킵니다.");
}
}이와 같이 사용자 정의 예외 클래스를 만들어 예외 상황에 대한 적절한 처리를 할 수 있다. 사용자 정의 예외 클래스를 만들 때는 예외의 특정 상황을 잘 표현하고 처리하기 위한 메시지와 추가적인 기능을 구현하는 것이 좋다.
Java Virtual Machine
Process
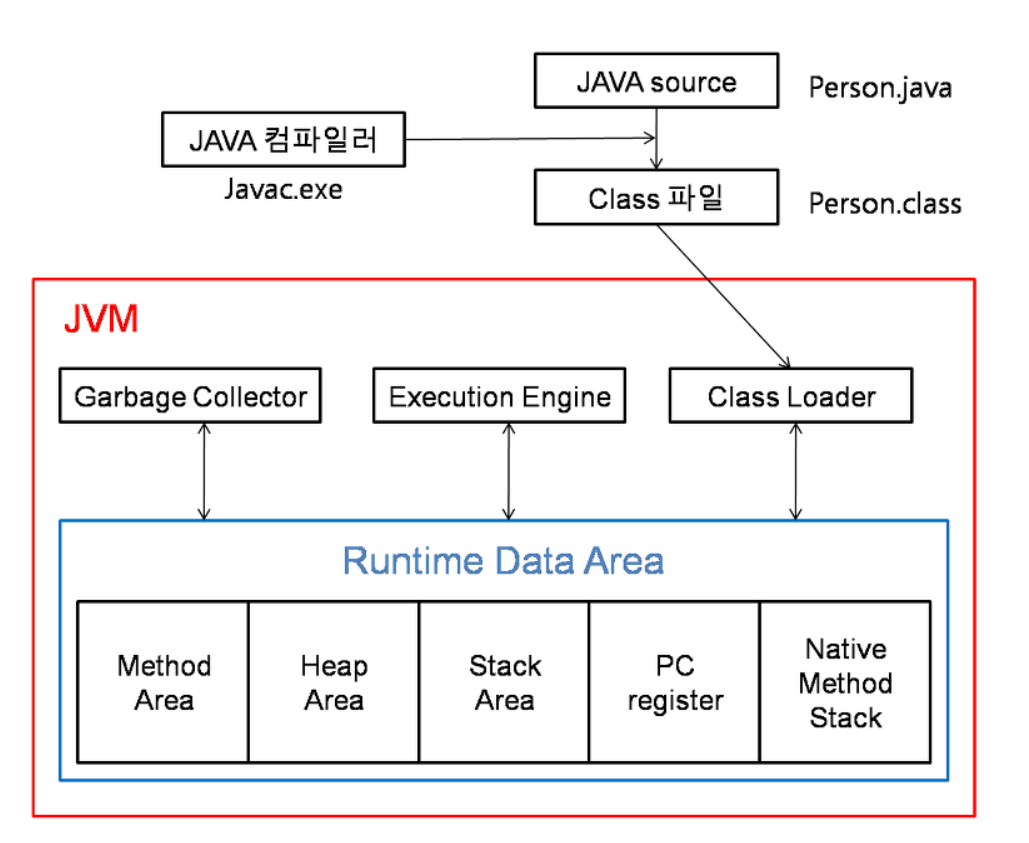
-
자바 언어로 작성된 애플리케이션을 실행하면 JVM은 OS로부터 메모리를 할당한다.
-
자바 컴파일러(javac)가 자바 소스코드(.java)를 자바 바이트코드(.class)로 컴파일한다.
-
Class Loader를 통해 JVM Runtime Data Area로 로딩한다.
JVM 안에서 사용할 준비를 마치는 과정이다.
-
Runtime Data Area에 로딩 된 .class들은 Execution Engine을 통해 해석한다.
-
해석된 바이트 코드는 Runtime Data Area의 각 영역에 배치되어 수행하며 이 과정에서 Execution Engine에 의해 GC의 작동과 스레드 동기화가 이루어진다.
RunTime Data Area
자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역입니다.
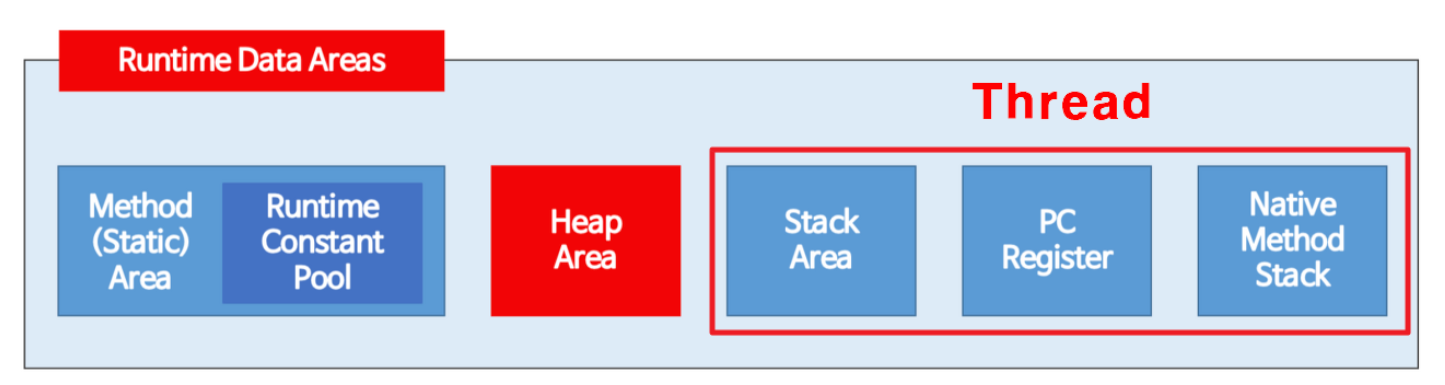
Thread
스레드(Thread)는 프로세스 내에서 실행되는 독립적인 실행 흐름이다. 각 스레드는 프로세스 내에서 자체적으로 코드를 실행하고 메모리 공간을 공유한다. 프로세스는 하나 이상의 스레드를 가질 수 있으며, 각각의 스레드는 동시에 실행될 수 있다.
모든 스레드가 공유해서 사용하는 메모리 (GC의 대상)
- 힙 영역 (Heap Area)
new키워드로 생성된 객체와 배열이 생성되는 영역이다.- 주기적으로 GC가 제거하는 영역이다.
- 메서드 영역(Method Area)
- 클래스 멤버 변수의 이름, 데이터 타입, 접근 제어자 정보와 같은 각종 필드 정보들과 메서드 정보 등이 생성되는 영역이다.
스레드(Thread) 마다 하나씩 생성하는 메모리
- 스택 영역(Stack Area)
- 지역변수, 파라미터, 리턴 값, 연산에 사용되는 임시 값 등이 생성되는 영역이다.
- PC 레지스터 (PC Register)
Thread가 생성될 때마다 현재 스레드가 실행되는 부분의 주소와 명령을 저장하고 있는 영역이다.
- 네이티브 메서드 스택(Native Method Stack)
- 자바 이외의 언어(C, C++, 어셈블리 등)로 작성된 네이티브 코드를 실행할 때 사용되는 메모리 영역이다.
Reference
[Java] 가비지 컬렉션(GC, Garbage Collection) 총정리
Interview_Question_for_Beginner
백엔드가 이정도는 해줘야 함 - 1. 컨텐츠의 동기와 개요
