JAVA IDE
기계어와 어셈블리어
컴퓨터도 마찬가지로 0과 1의 조합으로 사용자의 모든 행동을 이해한다. 컴퓨터에서는 주로 CPU가 그 역할을 도맡아서 진행한다. CPU는 컴퓨터에서 특정한 전기 신호를 입력받아 연산을 한다. 이 전기 신호는 0과 1로 이뤄져 있으며, 그 조합에 따라 덧셈을 하거나, 뺄셈을 하거나, 데이터를 저장하는 등의 판단을 CPU가 내리게 된다. 이 0과 1로 이뤄진 명령어를 기계어라고 한다.
[ op | rs | rt | rd |shamt| funct]
0 1 2 6 0 32 decimal
000000 00001 00010 00110 00000 100000 binary위 예시의 binary 라고 되어 있는 부분의 내용이 CPU가 실제로 이해하는 언어의 모습(의 예시)라고 보면 된다.
일반적으로 사람이 0과 1로만 이루어진 기계어를 보면 가독성이 떨어지고 코드를 직관적으로 이해하기 어렵다. 따라서 기계어를 그나마 이해할 수 있는 형태인 어셈블리어라는 형태로 바꿔 해석하는 방법을 마련했다.
10110000 01100001
MOV AL, 61h ; Load AL with 97 decimal (61 hex)기본적으로 어셈블리어는 한줄 한줄이 기계어 명령에 대응하는 형태로 만들어지고, 거기에 더해 몇가지 기능 (주석 같은) 부분들이 더해진다. 기계어는 0과 1로 이뤄져서 해당 명령어가 정확히 어떤 의미를 가지는지 알아야 했지만, 어셈블리어가 만들어지면서 MOV, ADD 와 같은 그나마 그 형태에 의미가 담겨있는 명령어의 목록으로 컴퓨터와 소통하게 되었다. 어셈블리어는 프로그래밍 언어라고 말할 수는 있지만 인간보다는 컴퓨터가 이해하기 쉬운 언어이다.
High Level Language
컴퓨터에 가까워질수록 low level이고, 인간에게 가까울수록 high level이라고 프로그래밍 언어를 분류하게 된다.
어셈블리어든 기계어든 low level language는 가독성이 매우 떨어지고 컴퓨터 구조에 대한 지식이 해박해야지만 사용할 수 있다. 또한 사용하는 컴퓨터가 어떤 CPU에 따라 작성해야 하는 코드가 다르기 때문에, 개발 환경에 따라 코드가 변경된다는 치명적인 단점이 있다. 따라서 사람에게 더욱 이해하기 쉬운 언어인 high level language를 만들게 되었다.
그래서 레지스터, 메모리 주소, 콜 스택 등 복잡한 컴퓨터 지식을 필요로 하지 않고도 컴퓨터 프로그램을 작성할 수 있도록, 높은 추상화가 적용된 언어를 만들게 된다. 이것이 고급 프로그래밍 언어이다. 고급 프로그래밍 언어의 등장은 저희가 변수, 배열, 객체, 함수 등의 개념을 익혀 컴퓨터가 실행하도록 프로그램을 작성할 수 있게 해 준다.
public class HelloWorldApp {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}하지만 기본적으로 High Level Language는 인간의 입장에서 이해하기 편한 언어이며, 결국 컴퓨터가 실행하는 어느 시점에서는 기계어로 번역되어야 한다. C, JAVA 처럼 실행 전에 기계어로 번역해 주는 컴파일 언어가 있고, Python, JavaScript 등 실행과 동시에 그때그때 기계어로 번역되는 인터프리터 언어도 있다.
Java와 JVM
Java언어의 모토가 있다. 바로 Write Once Run Anywhere이다. 한 번 쓰면 어디서든 실행 가능하도록 하자는 것이다. CPU마다 받아들이는 기계어가 다른데 이를 Java는 어떻게 해결했을까? 바로 JVM인 Java Virtual Machine이다. Java 언어도 분류로는 컴파일 언어이다. 바로 실행 전에 기계어로 해석해 주는 언어인 것이다. 하지만 자바는 컴파일하면 순수한 기계어가 아닌 Java Bytecode라는 게 나온다. 이는 JVM을 위한 어셈블리어이다. 이후 JVM은 Java Bytecode를 CPU가 이해할 수 있는 기계어로 번역해 준다.
JVM은 컴퓨터는 아니고 프로그램의 일종이다. JVM은 Java Bytecode를 번역해 주는 번역기이다. 즉 각자의 컴퓨터마다 써야 하는 기계어가 다른데, 이 환경에 맞춘 기계어로 바꿔 주는 것이다.
Java만 Java Bytecode로 바꾸지 말고 C++이나 다른 언어도 Java Bytecode로 번역해서 실행할 수 있지 않을까 싶어서 나온 언어들이 있다. 예를 들어 Kotlin이 있다. 이런 언어로 만든 프로그램은 JVM으로 실행이 가능하다.
JDK와 JRE
JVM이 컴퓨터와 소통을 하고 Java Bytecode를 번역해 준다. 이때 우리가 작성한 Java 코드를 Java Bytecode로 번역해 주는 것이 JDK (Java Development Kit)이다. JDK는 자바를 개발하기 위한 도구 모음집이고, Java 언어를 java Bytecode로 변환해 주는 컴파일러 (javac)이고 Jaba Bytecode를 실행해 보기 위한 JVM이다.
JDK는 만들어진 자바 프로그램을 실행하는 데에는 필요하지 않다. 만들어진 프로그램을 쓰기만 하는데 개발 도구를 다 갖추지는 않기 때문이다. 따라서 프로그램의 실행을 위한 것만 따로 모은 것이 JRE (Java Runtime Environment)이다. JRE는 JVM과 JVM이 사용할 기타 라이브러리를 포함한 자바로 작성된 프로그램의 실행 환경이다.
Java를 CLI에서 실행하기
JDK를 다운로드할 수 있는 사이트로 이동한다. 보통 회사에서 자바 버전을 지정해 주지만, 개발 환경을 스스로 정해야 한다면 LTS(Long Term Supprt)인 장기 지원 서포트가 되는 버전을 사용해 주는 것이 좋다.
사이트 뒤에 /{사용할 자바 버전}을 누르면 해당 버전의 JDK 다운로드 화면으로 갈 수 있다.
맞는 버전을 다운로드받은 파일을 압축 해제시킨다.
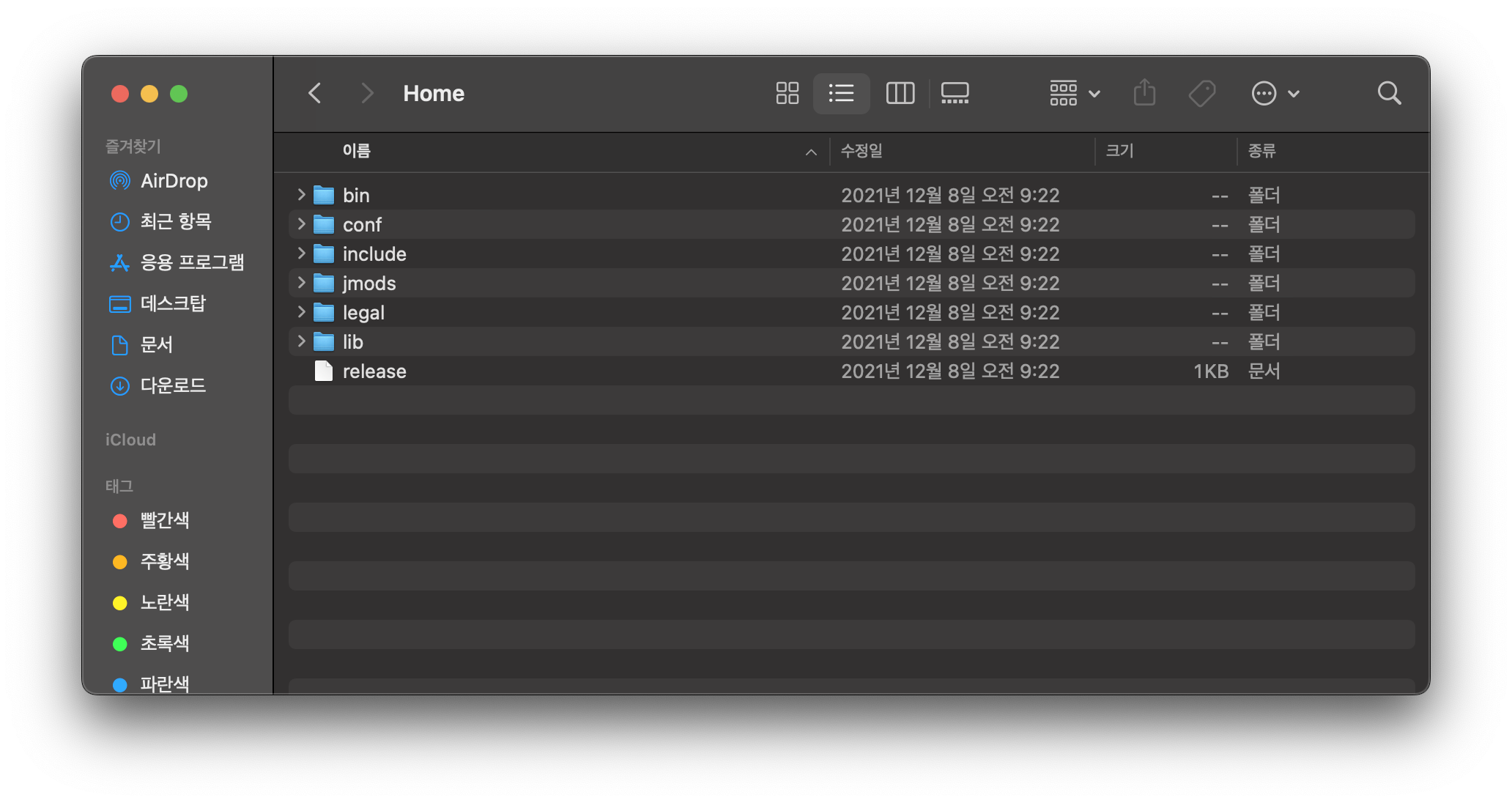
Home 파일에 가면 다음과 같은 구성을 볼 수 있다. 이 모든 파일을 다 합쳐서 JDK라고 하고, bin 폴더 안 파일들을 JVM을 실행하기 위한 파일들의 집합이라고 볼 수 있다.
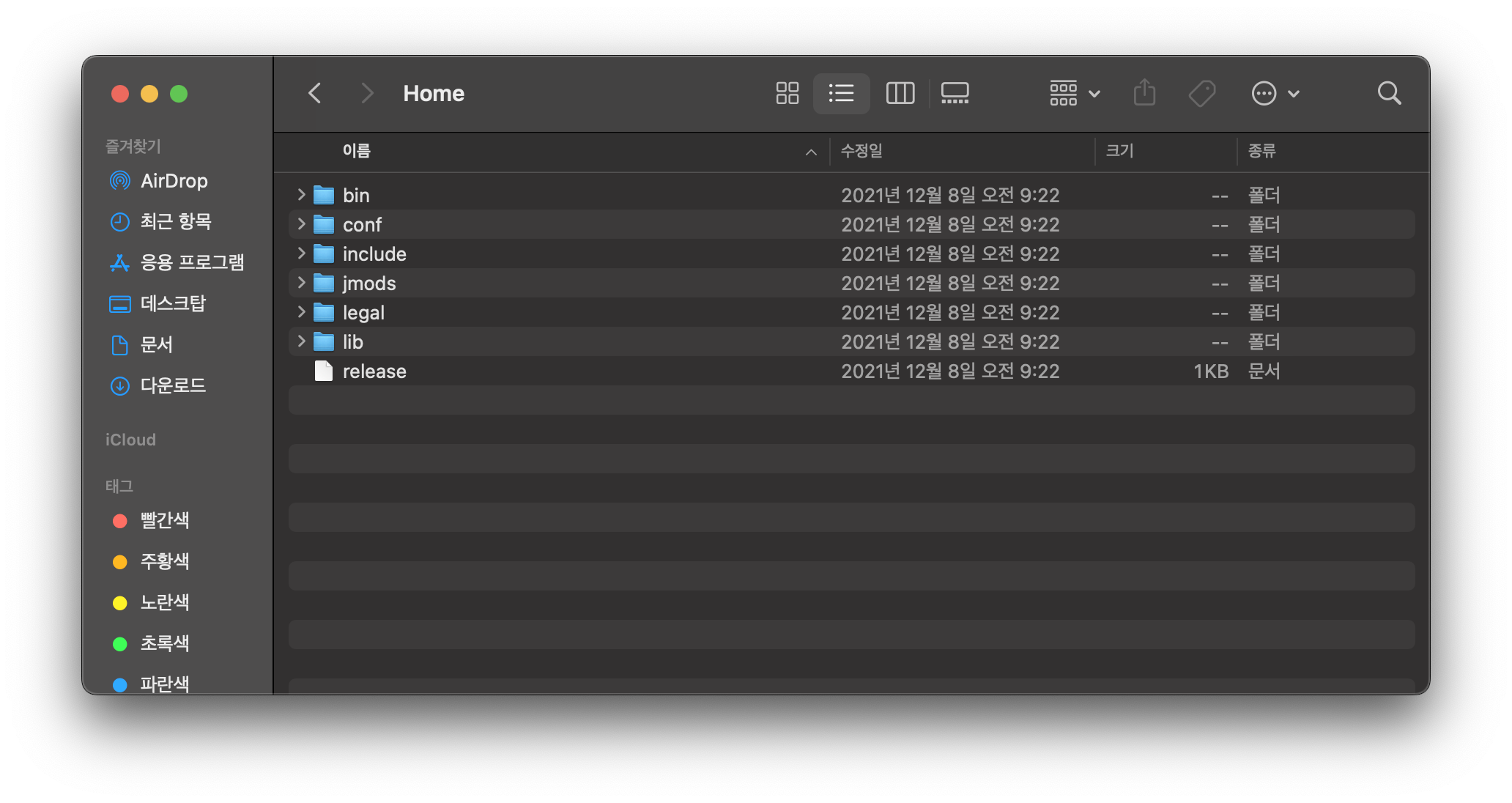
JVM을 실행시키기 위한 java, java 언어를 java Bytecode로 변환해 주는 컴파일러 (javac)가 보인다.
이후에 환경 변수를 설정해 주면 된다. 터미널에 java 명령어를 입력했을 때 컴퓨터는 환경 변수를 돌면서 java 명령에 해당하는 프로그램을 어떤 경로를 찾아서 실행하면 되는지 순회하고, 찾은 경우 그 명령어를 실행한다. 이것이 CLI에서 명령어가 처리되는 과정이다. 환경 변수를 제대로 설정했다면 java -version 을 입력했을 때 자바의 버전이 뜬다.
IDE
IDE Code Editor를 사용한다고 해도 실제 파일을 실행시켜 주는 것은 JDK이다. 메모장을 이용해서 java 파일을 만든 뒤에 아래 터미널 명령어를 이용하면 실행이 가능하지만, 이렇게 개발하는 경우는 드물다. 좋은 도구가 있으면 활용하는 것이 좋다.
./bin/javac HelloWorld.java
./bin/java HelloWorld문법과 맞춤법을 확인해 주고 완성된 코드를 실행시켜 주는 도구들을 활용하면 좋다. 이 도구들에는 쉽게 Code Editor과 IDE가 있다.
Code Editor
코드를 작성하는 데 도움을 주는 도구들이다. 문법 검사, 글자 색 조정 등을 해 준다. 비교적 빠르고 인터페이스가 단순하다. subline, notepad, visual studio code 등이 있다. Visual Studio Code 경우는 plugin 을 통해 거의 IDE처럼 사용하지만 아직은 Code Editor로 분류한다.
IDE (Intergrated Development Envirionment)
단순하게 코드 문법 검사를 넘어서 프로젝트의 시작부터 완성까지 도움을 주는 도구를 갖춘 통합 개발 환경이다. 사용하는 언어의 기능을 간소화하는 기능들이 많다. 상대적으로 무거운 느낌이 있지만 좀 더 정교한 기능을 갖춘 경우가 많다. 예를 들어 java 명령어를 통해 파일을 시행한 위의 경우를 ▶︎ 버튼 하나를 통해 진행할 수 있기 때문이다.
| Code Editor | Integrated Development Environment |
|---|---|
| 소스코드의 작성 편집에 중점을 둠 | 소스코드의 작성 뿐만 아니라 컴파일, 실행, 프로젝트의 관리 등 다양한 기능을 제공함 |
| 비교적 가볍고 빠름 | 프로젝트를 전반적으로 관리하기 때문에 많은 메모리를 필요 |
| 규모가 작은 어플리케이션 개발에 비교적 유리
(HTML, Python Script, Javascript) | 규모가 큰 어플리케이션 개발에 비교적 유리
(Spring, Django, Mobile Application 등) |
하지만 결국 IDE는 보조 역할만 하는 것이다. 자신이 사용하고자 하는 언어나 프레임워크를 보조하기 위해 사용하는 것이지, 언어나 프레임워크를 대체하지 않는다. IntelliJ를 사용해서 java 코드를 짜고 실행시켜도 이를 실행하는 원래는 JVM을 통해서 하는 것이다.
Client - Server Model
인터넷과 웹 개발
인터넷이란 TCP/IP 통신을 기반으로 연결된 수많은 컴퓨터가 이루는 연결망이다. 연결된 컴퓨터들이 서로 정해진 칙을 바탕으로 데이터를 주고받으며 인터넷을 구성하고 있다. 인터넷 상에서 제공되는 서비스를 웹 서비스라고 하고, 우리는 이런 서비스를 개발하는 웹 개발을 하는 과정 중에 있다. 그렇다면 어떻게 데이터를 주고받을까? 바로 Client - Server Model을 통해서이다.
Client - Server Model
인터넷 브라우저에서 보게 되는 페이지는 인터넷을 통해 페이지를 달라고 요청을 보내면, 인터넷의 어떤 컴퓨터가 해당 페이지를 응답해 준다. 이때 요청을 보내는 컴퓨터를 Client, 응답을 보내 주는 컴퓨터를 Server라고 한다.
쉽게 말해 클라이언트는 인터넷에 연결된 장치 혹은 소프트웨어 프로세스로 서비스를 요청하는 주체이며, 서버는 사용자에게 전송될 데이터 혹은 기능이 저장된 컴퓨터나 프로세스로 요청에 대한 적당한 응답을 하는 주체이다.
인터넷에서는 브라우저 주소창에 주소를 입력하면 인터넷 어딘가에 있는 주소에 해당하는 컴퓨터에게 요청을 보내고, 그에 대한 응답을 돌려받은 다음에 응답을 해석해서 우리에게 보여 주는 과정이다.
URL
브라우저의 주소창은 말 그래도 어디에 요청을 보낼지 입력하는 창이다. 주소창에 들어가는 것은 URL (Uniform Resource Locator) 자원이 어디있는지 나타내는 기준이다.
https://www.google.com/search?q=techit
https://techit.education/school/kdt-backend-5th
<scheme>://<authority>/<path>?<query>#<anchor>scheme: 어떤 방식으로 요청을 하는지
authority: 어떤 컴퓨터에 요청을 하는지 (컴퓨터 찾기)
path: 그 컴퓨터이 어디에 있는 자원인지 (컴퓨터 속 자원의 위치 찾기)
query: 그 자원에 대한 추가 요구 사항
개발을 할 때 주로 신경 쓰는 부분은 path와 query이다. authority 같은 경우는 개발 후 사용자들에게 여기로 접속하세요 하는 용도로만 사용된다. 즉 path와 query를 기준으로 어떤 응답을 할지에 집중해야 한다.
Framework
프레임워크는 1. 서버 프로세스 실행 2. 특정 포트에서 들어오는 신호 듣기 3. 해당 신호를 데이터의 형태로 해석 4. 다시 요청을 보낸 컴퓨터로 응답을 보내는 기능을 처리한다. 이런 기본적인 기능들을 계속해서 다시 만드는 것이 번거롭기 때문에 웹 서비스에서 흔히 발생하는 기능들을 미리 구현해 놓은 것이다. 즉 개발자의 일을 간소화하기 위해 어떤 URL에서 어떤 요청을 들을 것인지, 그 요청에 대한 응답 형태가 어떤 것일지 반복된 기능은 미리 구현해 놓은 것이다.
Spring Boot
Spring Initialzr
웃기지만 프레임워크를 쓰기 위한 코드 준비도 나름 복잡하다. 추가해야 하는 의존성, 자바 버전, 소스코드 폴더 구조나 .gitignore등 기초 코드인 boiler project를 알아서 짜 주는 사이트이다.

앞쪽 버전은 major update로 3 버전에 추가된 기능인 2 버전에서 사용할 수 없다. 중간에 있는 번호는 주요 기능이 추가되기는 했지만 상위와 하위 호환이 가능한 것이고, 제일 작은 번호는 작은 패치나 오류 수정 등 패치 버전이 변형된다.

Project Metadata는 프로젝트에 대한 부수적인 설명을 기입하는 란이다.

spring boot의 의존성을 추가하는 부분이다. 오늘의 실습을 위해 두 의존성을 추가해 준다. 이후 Generate 버튼을 누르면 압축 파일이 하나 다운로드되는데, 압축을 해제하면 자바 프로젝트와 비슷한 파일들이 존재한다.
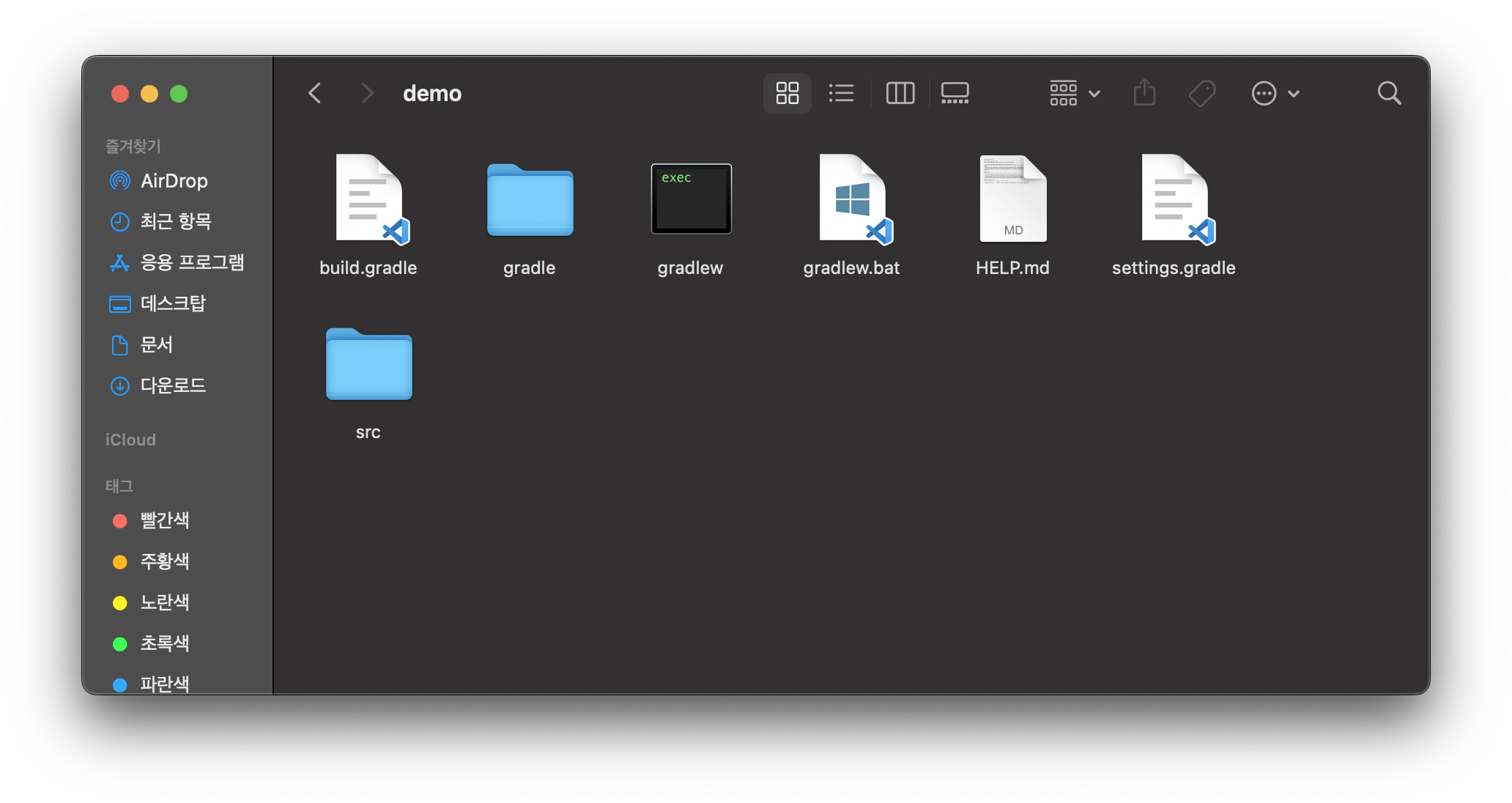
이후 해당 파일을 IDE로 열면 스프링부트 프로젝트가 시작된다.
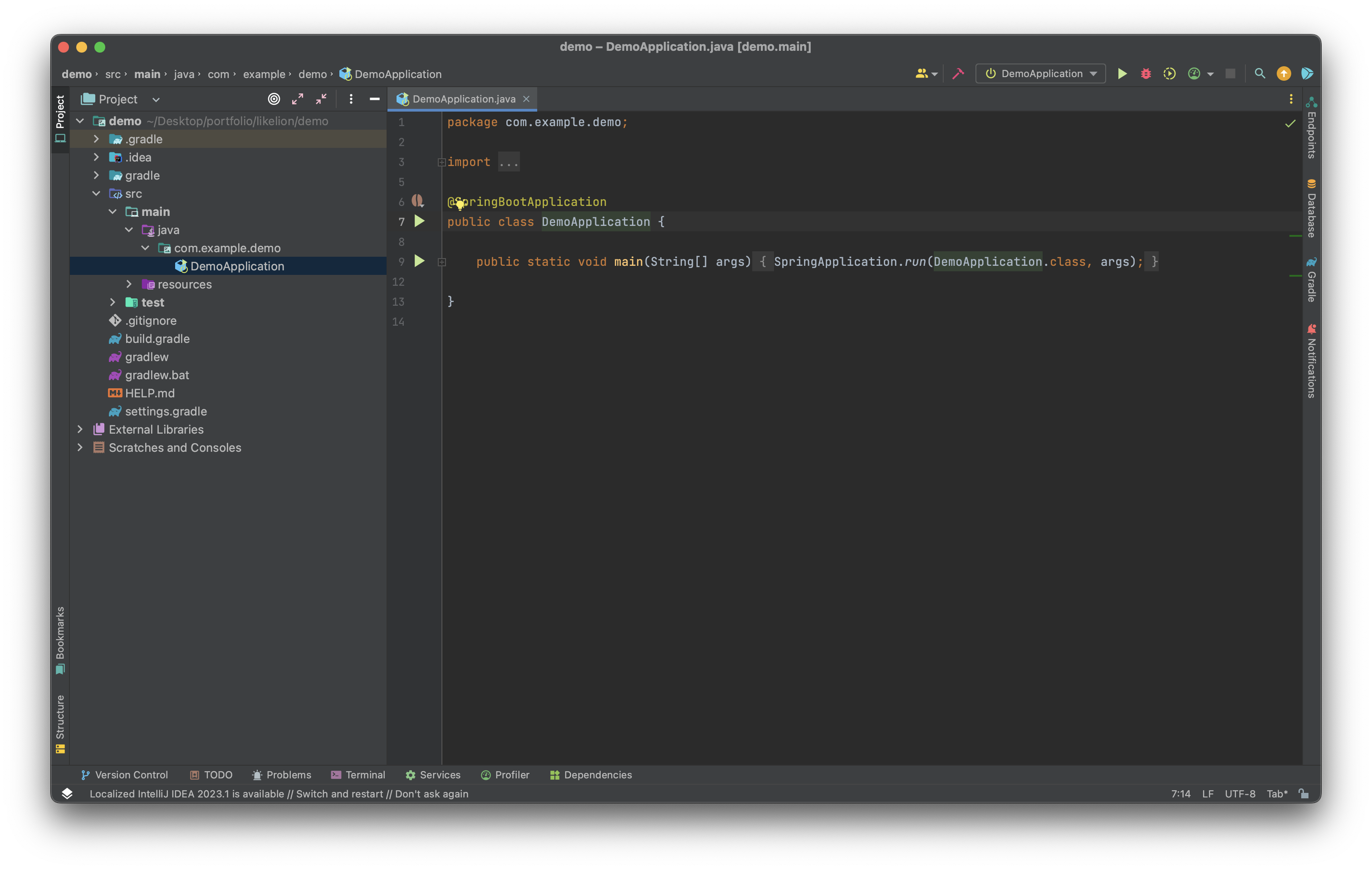
HTML 띄우기
http://localhost:8080/home 주소를 주소창에 입력했을 때 우리가 만든 html이 보이게 해 보도록 하겠다. 즉 home이라는 요청이 오면 요청에 알맞는 응답인 html을 반환해 주는 것이다.
먼저 html을 src/main/resource/templete에 만들어 준다.
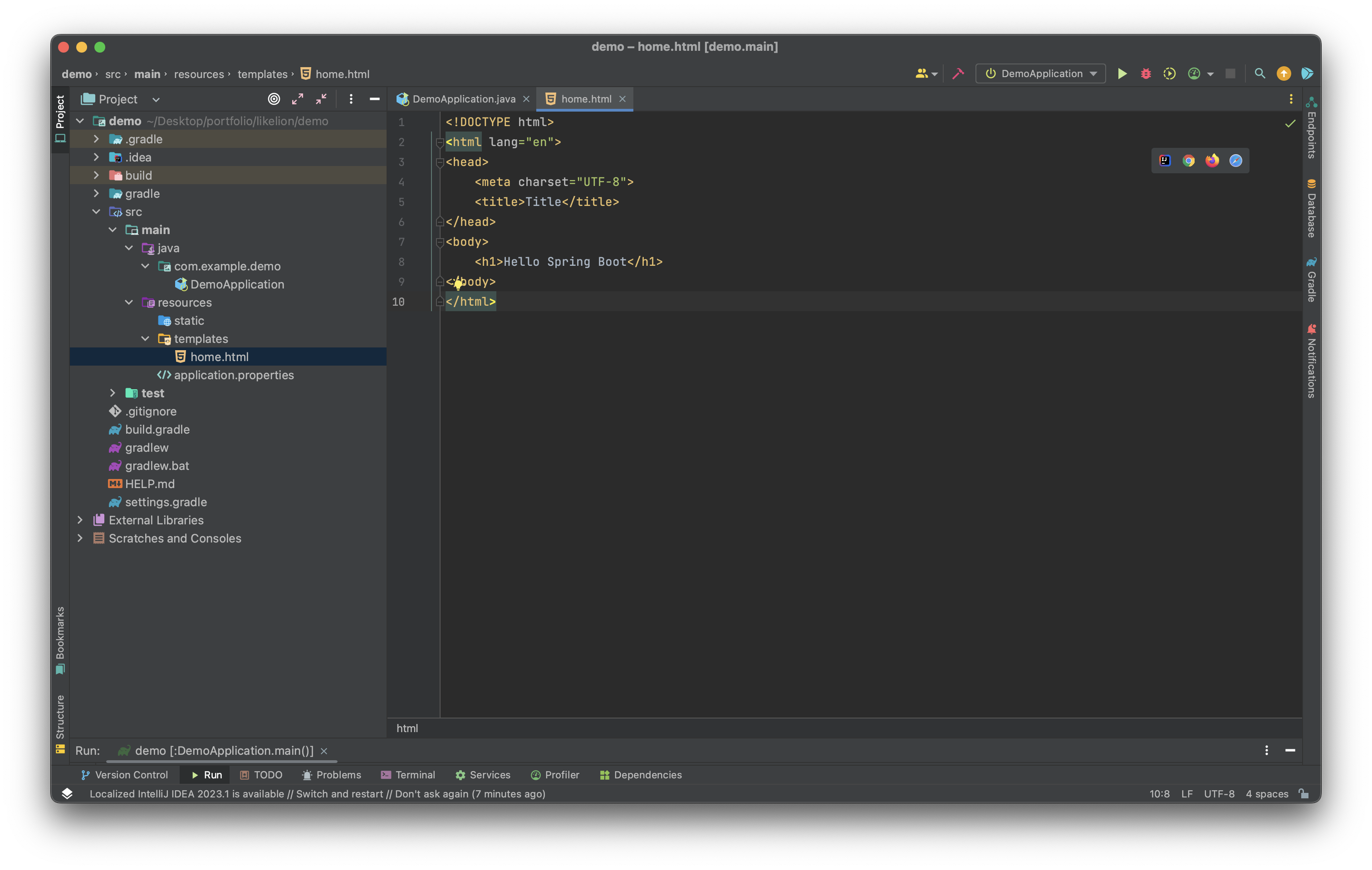
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>Hello Spring Boot</h1>
</body>
</html>이후 DemoController라는 새로운 java class를 만들어 준다. 이후 클래스 위에 @Controller 를 추가한다.
package com.example.demo;
import org.springframework.stereotype.Controller;
@Controller
public class DemoController {
}이후 String을 반환하는 home이라는 함수를 정의해 준 뒤 다음과 같이 코드를 짜고 앱을 실행시킨다. ㄱ
@Controller
public class DemoController {
@RequestMapping("home")
public String home() {
return "home.html";
}
}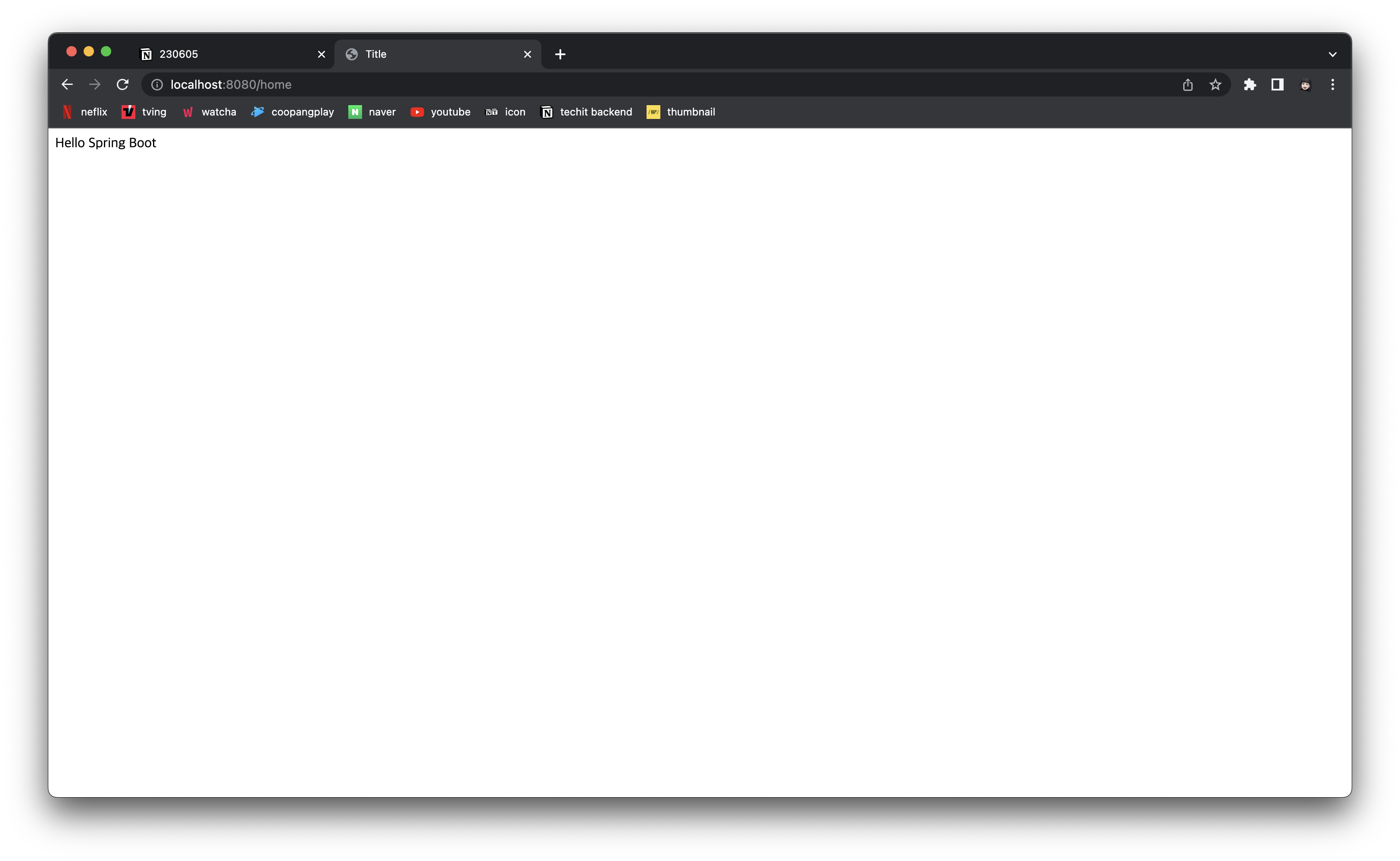
@Controller 이 클래스는 Controller임을 나타내는 어노테이션이고, @RequestMapping 은 특정 요청이 발생했을 때 실행이 되는 메소드임을 나타내는 어노테이션이다. 이때의 Controller는 Spring MVC에서의 Controller를 의미한다. 백엔드 개발에서는 어떤 URL에 대해 어떤 정보를 반환해 줄 것인지를 항시 중점으로 둬야 한다.
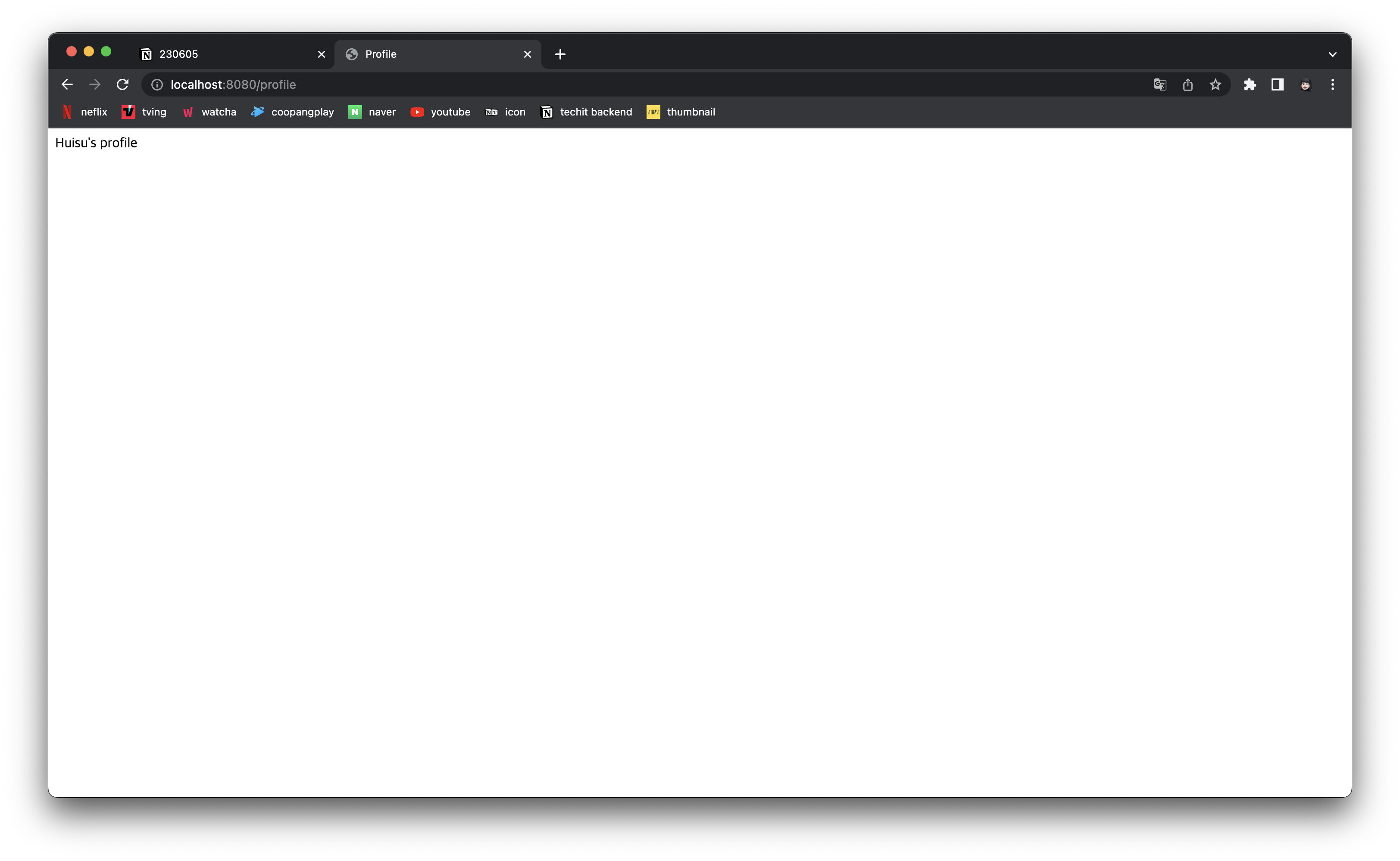
시험을 위해 profile이라는 html을 하나 더 만들어 보자.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Profile</title>
</head>
<body>
Huisu's profile
</body>
</html>이후 Controller에 매핑 하나를 더 넣어 준 뒤 localhost:8080/profile로 요청을 보내면 다음과 같은 화면이 뜬다.
@RequestMapping("profile")
public String profile() {
return "profile.html"l
}
home.html 을 다음과 같이 수정해 다른 요청을 넣도록 연결할 수도 있다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
Hello Spring Boot
<a href="http://localhost:8080/profile">프로필</a>
<a href="http://localhost:8080/blog">블로그</a>
</body>
</html>보통 알고리즘 코딩을 할 때 new 키워드를 통해 객체를 만들어서 실행하곤 했는데, 위에 짠 코드는 new 키워드 코드가 실행된다. 즉 new 키워드를 통해 새로운 인스턴스를 만들어 주고, 해당 객체를 통해 메소드나 멤버에 접근하곤 했었다. 하지만 Controller는 그렇지 않다. 이는 Spring IOC Container가 작동하고 있기 때문이다.
Spring IOC Container
@Controller @RequestMapping 을 추가했더니 클래스를 참조하지 않아도 기능 사용이 가능했다. 아래 자바 코드에서 어떤 작업을 했기에 이것이 가능할까?
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}일반적인 객체 지향 프로그래밍에서 개발자는 클래스를 정의하고 클래스 인스턴스는 서로 상호작용하면서 기능을 제공한다. 개발자는 new 키워드를 통해 객체를 생성하고 배치하고 사용하는 방식으로 개발을 진행한다.
하지만 지금 한 일은 어노테이션을 추가해 우리가 작성한 코드가 어느 시점에 자동으로 시행되는 것처럼 보인다. 즉 객체를 직접 추가하지 않는 느낌이다. 클래스를 만드는 주체는 개발자지만 클래스 인스턴스가 언제 만들어지는지를 결정하는 주체는 Spring Framework가 된다. 이것이 제어의 반전 (Inversion of Control)이다.
이는 Library와 Framework의 차이기도 하다. 예를 들어 BufferedReader는 자바 라이브러리에서 클래스를 사용하겠다며 인스턴스를 참조한다. 즉 제어의 권한이 개발자에게 있다. 하지만 Framework 같은 경우는 클래스를 정의만 하지 이 클래스가 언제 만들어지고 삭제되는지 신경을 안 쓰고 제어를 framework에 맡기게 된다. 이럴 경우 개발자가 객체 관리에 신경 쓰지 않고 로직 개발에만 신경 쓸 수 있게 된다.
Spring IoC Container
개발자가 작성한 클래스와 몇 가지 설정 정보 (xml, java, application.properties) 등을 바탕으로 해당 클래스의 객체의 lifecycle을 관리하는 Spring의 IoC 패턴 구현체이다. Spring Container, ApplicationContext로 지칭되기도 하며, 이때 IoC Container가 관리하는 객체를 Bean이라고 부른다.
@Controller 요청이 왔을 때 어떻게 처리해야 할지에 대한 정보를 가지고 왔으니 이 클래스는 IoC Container에서 관리해 달라고 권한을 부여하는 어노테이션이다.
@SpringBootApplication 이 클래스를 기준으로 Bean 객체를 찾아서 관리해 달라는 어노테이션이다.
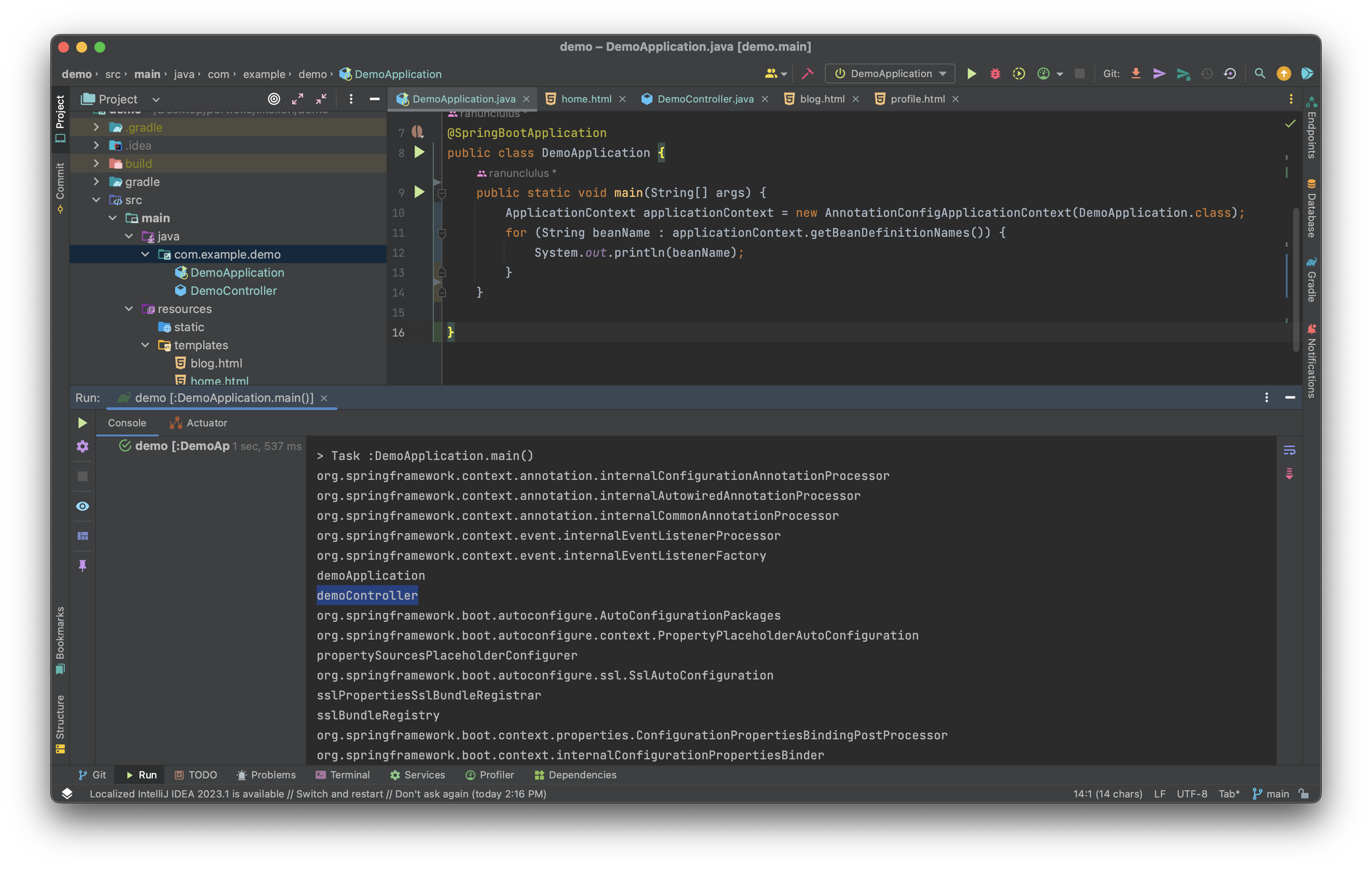
따라서 위의 java App을 실행시키면 현재 실행 중인 IoC Container를 반환해 준다. 그리고 IoC Containe는 Class를 객체로 만들어서 내부에서 관리한다. 따라서 아래 코드를 입력하면 그 Container가 어떤 Bean 객체를 가지고 있는지 알게 된다.
package com.example.demo;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(DemoApplication.class);
for (String beanName : applicationContext.getBeanDefinitionNames()) {
System.out.println(beanName);
}
}
}bean 객체를 모두 출력해 봤을 때 DemoController도 Bean 객체로 생성되어 있는 것을 볼 수 있다. 이는 우리가 만든 클래스들이 Bean 객체로 정상적으로 등록되었다는 뜻이다.